关于批量导入的一些想法
背景
业务系统中经常有批量导入的功能。
导入的数据里面,因为不清楚这些数据是新增的或是更新的,所以默认的一种做法是,先查一下,然后分出哪些是新增的数据,哪些是更新的数据,
然后再分新增和更新。
理论是这样子,但总感觉每次都要查询一下,也不是很舒服。
有一个想法
如果一个批次,100条数据,
如果先不管它有多少是需要insert的,先把这100条都按update 去做,然后如果update 的总数小于100,再去查询一次,找出需要 insert的,再去insert, 这次,会不会稍为好一点点呢。
如果update 的条目总数等于100,那说明不需要做insert,也不需要再去查一次。
并发的情况
如果是先查询,再去做 insert,也是会存在一种可能性,
A,B两个用户都去做导入,并且数据存在重复,
A,B都先查询出来,发现其中有10个Id 不存在,然后都选择对这10条数据进行 insert, 刚好 A用户先提交并且insert成功,commit了。这个时候B用户再按预期操作去insert,会发现报错(主键重复,如果不是主键,那数据也会重复了)。
这种情况是很可能存在的,如果是100个用户去同时导入,那这种可能性就更高好。
嗯,感觉都不是特别好。
先记录一下吧。
怎样做批量导入性能比较高呢?
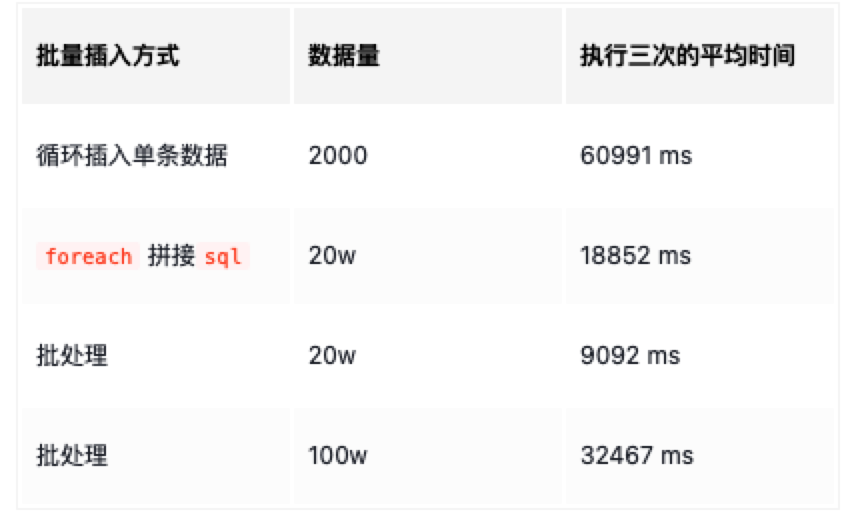
参考转载于这篇文章: https://juejin.cn/post/7007608714093920286
个人是还没有试验过,不过这个结果也比较有参考价值了的。
private StopWatch sw = new StopWatch();
@Test
public void processInsert() {
sw.start("批处理执行 插入");
// 打开批处理
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
UserInfoBatchMapper mapper = session.getMapper(UserInfoBatchMapper.class);
for (int i = 0,length = list.size(); i < length; i++) {
mapper.insert(list.get(i));
//每20000条提交一次防止内存溢出
if(i%20000==19999){
session.commit();
session.clearCache();
}
}
session.commit();
session.clearCache();
sw.stop();
log.info("all cost info:{}",sw.prettyPrint());
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号