Redis集群节点扩容及其 Redis 哈希槽
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value
时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大
致均等的将哈希槽映射到不同的节点。
Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念。
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽。这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。
使用哈希槽的好处就在于可以方便的添加或移除节点。
当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了;
在这一点上,我们以后新增或移除节点的时候不用先停掉所有的 redis 服务。
"用了哈希槽的概念,而没有用一致性哈希算法,不都是哈希么?这样做的原因是为什么呢?"
Redis Cluster是自己做的crc16的简单hash算法,没有用一致性hash。Redis的作者认为它的crc16(key) mod 16384的效果已经不错了,虽然没有一致性hash灵活,但实现很简单,节点增删时处理起来也很方便。
"为了动态增删节点的时候,不至于丢失数据么?"
节点增删时不丢失数据和hash算法没什么关系,不丢失数据要求的是一份数据有多个副本。
“还有集群总共有2的14次方,16384个哈希槽,那么每一个哈希槽中存的key 和 value是什么?”
当你往Redis Cluster中加入一个Key时,会根据crc16(key) mod 16384计算这个key应该分布到哪个hash slot中,一个hash slot中会有很多key和value。你可以理解成表的分区,使用单节点时的redis时只有一个表,所有的key都放在这个表里;
改用Redis Cluster以后会自动为你生成16384个分区表,你insert数据时会根据上面的简单算法来决定你的key应该存在哪个分区,每个分区里有很多key。
redis
组件版本:
redis:5.0.8
节点架构:
3主3从、6主机
扩容后架构:
6主6从、12主机
[问题描述]
Redis(RemoteDictionary Server ),即远程字典服务,是一个开源的使用ANSIC语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis是一个key-value存储系统,支持存储的value类型包括string(字符串)、list(链表)、set(集合)、zset(sortedset--有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
某业务系统采用rediscluster架构,由于数据量的增长导致部分数据还未过期时就被redis最大内存限制给删除掉,所以业务在当前三柱三从架构无法满足业务数据量持续增长的情况,需要扩容节点至六主六从。
[结构及详细说明]
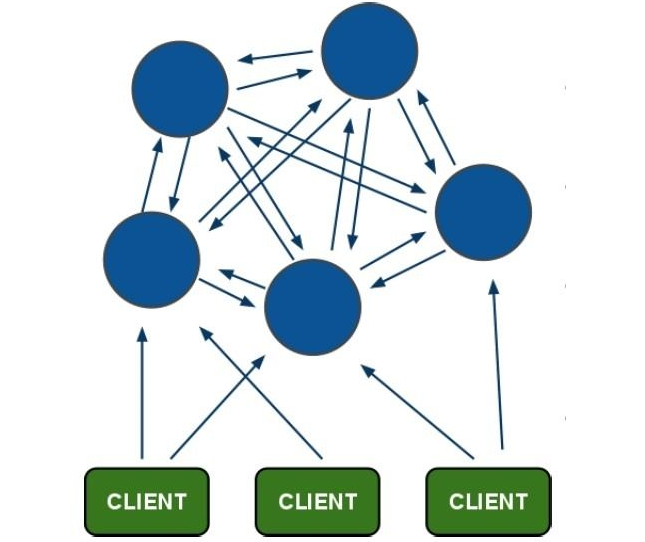
Redis集群大致架构图:
一组RedisCluster是由多个Redis实例组成,官方推荐使用6实例,其中3个为主节点,3个为从结点。一旦有主节点发生故障的时候,RedisCluster可以选举出对应的从结点成为新的主节点,继续对外服务,从而保证服务的高可用性。那么对于客户端来说,知道知道对应的key是要路由到哪一个节点呢?原来,RedisCluster把所有的数据划分为16384个不同的槽位,可以根据机器的性能把不同的槽位分配给不同的Redis实例,对于Redis实例来说,他们只会存储部门的Redis数据,当然,槽的数据是可以迁移的,不同的实例之间,可以通过一定的协议,进行数据迁移。
需要把3主3从扩容为6主6从,就需要增加6个节点,依次添加3个主节点hash槽,再添加3个从节点手动分配给主节点。
[操作过程]
1、创建节点
复制原有集群节点的配置文件更改端口目录等然后再启动redis,要添加6个节点需创建6个节点并启动:
./redis-server../6001/redis.conf
./redis-server../6002/redis.conf
./redis-server../6003/redis.conf
./redis-server../6004/redis.conf
./redis-server../6005/redis.conf
./redis-server../6006/redis.conf
2、添加主节点
第一个ip:port为需要添加的节点ip和端口,第二个ip:port为当前集群中的节点和端口;先后执行以下命令:
./redis-cli--cluster add-node 192.168.8.20:6001 192.168.8.10:7001 -a 123456
./redis-cli--cluster add-node 192.168.8.21:7002 192.168.8.10:7001 -a 123456
……

3、分配hash槽
新添加的节点没有哈希槽,并不能正常存储数据,需要给新添加的节点分配哈希槽。
-
重新分配哈希槽
./redis-cli--cluster reshard ip:port -a passwd
-
输入要分配多少个哈希槽(数量)

-
输入指定要分配哈希槽的节点ID

-
选择需要分配的哈希槽来源
输入all需要分配给目标节点的哈希槽来着当前集群的其他主节点(每个节点拿出的数量为集群自动决定)

分配哈希槽有两种方式
(1)将所有节点用作哈希槽的源节点。
(2)在指定的节点拿出指定数量的哈希槽分配到目标节点:
4、添加从节点
添加6004节点(slave的添加方法,master为7004)
#节点ID是主节点的ID
#192.168.8.20:6004 是新加的从节点
#192.168.8.10:7004 作为从节点的主节点
./redis-cli--cluster add-node --cluster-slave --cluster-master-idxxxxxxxxxxxxxxxxxxx 192.168.8.20:6004 192.168.8.10:7004
[总结]
1、redis扩容一般有两种方法,一种是在线扩容,一种是离线扩容,从业务的角度来说,在线扩容是最方便的方法,但在线扩容有个问题是,过程中如果某个槽正在操作会导致迁移槽是发送错误,需要人工干预。
2、离线扩容是比较快速的方法,人工干预比较少由集群自动分配哈希槽,缺点是需停掉业务。
3、一般来说业务上线前会对redis缓存数据量有一个预估,从而对架构的硬件配置有个预估,就不会产生扩容这个操作,但往往业务数据量是一个动态的,无法预估的,所以需要通过扩容节点的操作慢在业务的需求,需要保证扩容过程正保证数据的正确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号