JDK8新特性关于Stream流
在Java1.8之前还没有stream流式算法的时候,我们要是在一个放有多个User对象的list集合中,将每个User对象的主键ID取出,组合成一个新的集合,首先想到的肯定是遍历,如下:
|
1
2
3
4
|
List<Long> userIdList = new ArrayList<>();for (User user: list) { userIdList.add(user.id);} |
或者在1.8有了lambda表达式以后,我们会这样写:
|
1
2
|
List<Long> userIdList = new ArrayList<>();list.forEach(user -> list.add(user.id)); |
在有了stream之后,我们还可以这样写:
|
1
|
List<Long> userIdList = list.stream().map(User::getId).collect(Collectors.toList()); |
一行代码直接搞定,是不是很方便呢。那么接下来。我们就一起看一下stream这个流式算法的新特性吧。
由上面的例子可以看出,java8的流式处理极大的简化了对于集合的操作,实际上不光是集合,包括数组、文件等,只要是可以转换成流,我们都可以借助流式处理,类似于我们写SQL语句一样对其进行操作。java8通过内部迭代来实现对流的处理,一个流式处理可以分为三个部分:转换成流、中间操作、终端操作。如下图:
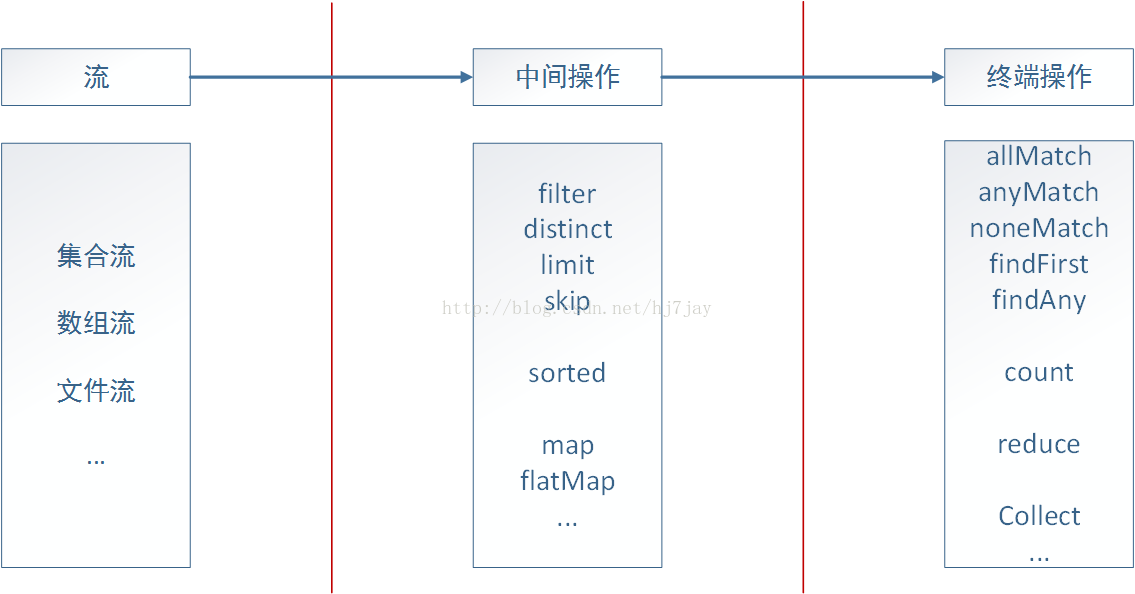
以集合为例,一个流式处理的操作我们首先需要调用stream()函数将其转换成流,然后再调用相应的中间操作达到我们需要对集合进行的操作,比如筛选、转换等,最后通过终端操作对前面的结果进行封装,返回我们需要的形式。
这里我们先创建一个User实体类:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class User{private Long id; //主键idprivate String name; //姓名private Integer age; //年龄private String school; //学校public User(Long id, String name, Integer age, String school) { this.id = id; this.name = name; this.age = age; this.school = school;}此处省略get、set方法。。。 |
初始化:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
List<User> list = new ArrayList<User>(){ { add(new User(1l,"张三",10, "清华大学")); add(new User(2l,"李四",12, "清华大学")); add(new User(3l,"王五",15, "清华大学")); add(new User(4l,"赵六",12, "清华大学")); add(new User(5l,"田七",25, "北京大学")); add(new User(6l,"小明",16, "北京大学")); add(new User(7l,"小红",14, "北京大学")); add(new User(8l,"小华",14, "浙江大学")); add(new User(9l,"小丽",17, "浙江大学")); add(new User(10l,"小何",10, "浙江大学")); }}; |
1. 过滤
1.1 filter
我们希望过滤赛选处所有学校是清华大学的user:
System.out.println("学校是清华大学的user");
List<User> userList1 = list.stream().filter(user -> "清华大学".equals(user.getSchool())).collect(Collectors.toList());
userList1.forEach(user -> System.out.print(user.name + '、'));
控制台输出结果为:
|
1
2
|
学校是清华大学的user张三、李四、王五、赵六、 |
1.2 distinct
去重,我们希望获取所有user的年龄(年龄不重复)
|
1
2
3
|
System.out.println("所有user的年龄集合");List<Integer> userAgeList = list.stream().map(User::getAge).distinct().collect(Collectors.toList());System.out.println("userAgeList = " + userAgeList); |
map在下面会讲到,现在主要是看distinct的用法,输出结果如下:
|
1
2
|
所有user的年龄集合userAgeList = [10, 12, 15, 25, 16, 14, 17] |
1.3 limit
返回前n个元素的流,当集合的长度小于n时,则返回所有集合。
如获取年龄是偶数的前2名user:
|
1
2
3
|
System.out.println("年龄是偶数的前两位user");List<User> userList3 = list.stream().filter(user -> user.getAge() % 2 == 0).limit(2).collect(Collectors.toList());userList3.forEach(user -> System.out.print(user.name + '、')); |
输出结果为:
|
1
2
|
年龄是偶数的前两位user张三、李四、 |
1.4 sorted
排序,如现在我想将所有user按照age从大到小排序:
|
1
2
3
|
System.out.println("按年龄从大到小排序");List<User> userList4 = list.stream().sorted((s1,s2) -> s2.age - s1.age).collect(Collectors.toList());userList4.forEach(user -> System.out.print(user.name + '、')); |
输出结果为:
|
1
2
|
按年龄从大到小排序田七、小丽、小明、王五、小红、小华、李四、赵六、张三、小何、 |
1.5 skip
跳过n个元素后再输出
如输出list集合跳过前两个元素后的list
|
1
2
3
|
System.out.println("跳过前面两个user的其他所有user");List<User> userList5 = list.stream().skip(2).collect(Collectors.toList());userList5.forEach(user -> System.out.print(user.name + '、')); |
输出结果为:
|
1
2
|
跳过前面两个user的其他所有user王五、赵六、田七、小明、小红、小华、小丽、小何、 |
2 映射
2.1 map
就是讲user这个几个精简为某个字段的集合
如我现在想知道学校是清华大学的所有学生的姓名:
|
1
2
3
|
System.out.println("学校是清华大学的user的名字");List<String> userList6 = list.stream().filter(user -> "清华大学".equals(user.school)).map(User::getName).collect(Collectors.toList());userList6.forEach(user -> System.out.print(user + '、')); |
输出结果如下:
|
1
2
|
学校是清华大学的user的名字张三、李四、王五、赵六、 |
除了上面这类基础的map,java8还提供了mapToDouble(ToDoubleFunction<? super T> mapper),mapToInt(ToIntFunction<? super T> mapper),mapToLong(ToLongFunction<? super T> mapper),这些映射分别返回对应类型的流,java8为这些流设定了一些特殊的操作,比如查询学校是清华大学的user的年龄总和:
|
1
2
3
|
System.out.println("学校是清华大学的user的年龄总和");int userList7 = list.stream().filter(user -> "清华大学".equals(user.school)).mapToInt(User::getAge).sum();System.out.println( "学校是清华大学的user的年龄总和为: "+userList7); |
输出结果为:
|
1
2
|
学校是清华大学的user的年龄总和学校是清华大学的user的年龄总和为: 49 |
1.2 flatMap
flatMap与map的区别在于 flatMap是将一个流中的每个值都转成一个个流,然后再将这些流扁平化成为一个流 。举例说明,假设我们有一个字符串数组String[] strs = {"hello", "world"};,我们希望输出构成这一数组的所有非重复字符,那么我们用map和flatMap 实现如下:
|
1
2
3
4
5
|
String[] strings = {"Hello", "World"};List l11 = Arrays.stream(strings).map(str -> str.split("")).map(str2->Arrays.stream(str2)).distinct().collect(Collectors.toList());List l2 = Arrays.asList(strings).stream().map(s -> s.split("")).flatMap(Arrays::stream).distinct().collect(Collectors.toList());System.out.println(l11.toString());System.out.println(l2.toString()); |
输出结果如下:
|
1
2
|
[java.util.stream.ReferencePipeline$Head@4c203ea1, java.util.stream.ReferencePipeline$Head@27f674d][H, e, l, o, W, r, d] |
由上我们可以看到使用map并不能实现我们现在想要的结果,而flatMap是可以的。这是因为在执行map操作以后,我们得到是一个包含多个字符串(构成一个字符串的字符数组)的流,此时执行distinct操作是基于在这些字符串数组之间的对比,所以达不到我们希望的目的;flatMap将由map映射得到的Stream<String[]>,转换成由各个字符串数组映射成的流Stream<String>,再将这些小的流扁平化成为一个由所有字符串构成的大流Steam<String>,从而能够达到我们的目的。
3 查找
3.1 allMatch
用于检测是否全部都满足指定的参数行为,如果全部满足则返回true,例如我们判断是否所有的user年龄都大于9岁,实现如下:
|
1
2
3
|
System.out.println("判断是否所有user的年龄都大于9岁");Boolean b = list.stream().allMatch(user -> user.age >9);System.out.println(b); |
输出结果为:
|
1
2
|
判断是否所有user的年龄都大于9岁true |
3.2 anyMatch
anyMatch则是检测是否存在一个或多个满足指定的参数行为,如果满足则返回true,例如判断是否有user的年龄大于15岁,实现如下:
|
1
2
3
|
System.out.println("判断是否有user的年龄是大于15岁");Boolean bo = list.stream().anyMatch(user -> user.age >15);System.out.println(bo); |
输出结果为:
|
1
2
|
判断是否有user的年龄是大于15岁true |
3.3 noneMatch
noneMatch用于检测是否不存在满足指定行为的元素,如果不存在则返回true,例如判断是否不存在年龄是15岁的user,实现如下:
|
1
2
3
|
System.out.println("判断是否不存在年龄是15岁的user");Boolean boo = list.stream().noneMatch(user -> user.age == 15);System.out.println(boo); |
输出结果如下:
|
1
2
|
判断是否不存在年龄是15岁的userfalse |
3.4 findFirst
findFirst用于返回满足条件的第一个元素,比如返回年龄大于12岁的user中的第一个,实现如下:
|
1
2
3
4
|
System.out.println("返回年龄大于12岁的user中的第一个");Optional<User> first = list.stream().filter(u -> u.age > 10).findFirst();User user = first.get();System.out.println(user.toString()); |
输出结果如下:
|
1
2
|
返回年龄大于12岁的user中的第一个User{id=2, name='李四', age=12, school='清华大学'} |
3.5 findAny
findAny相对于findFirst的区别在于,findAny不一定返回第一个,而是返回任意一个,比如返回年龄大于12岁的user中的任意一个:
|
1
2
3
4
|
System.out.println("返回年龄大于12岁的user中的任意一个");Optional<User> anyOne = list.stream().filter(u -> u.age > 10).findAny();User user2 = anyOne.get();System.out.println(user2.toString()); |
输出结果如下:
|
1
2
|
返回年龄大于12岁的user中的任意一个User{id=2, name='李四', age=12, school='清华大学'} |
4 归约
4.1 reduce
现在我的目标不是返回一个新的集合,而是希望对经过参数化操作后的集合进行进一步的运算,那么我们可用对集合实施归约操作。java8的流式处理提供了reduce方法来达到这一目的。
比如我现在要查出学校是清华大学的所有user的年龄之和:
//前面用到的方法
Integer ages = list.stream().filter(student -> "清华大学".equals(student.school)).mapToInt(User::getAge).sum();
System.out.println(ages);
System.out.println("归约 - - 》 start ");
Integer ages2 = list.stream().filter(student -> "清华大学".equals(student.school)).map(User::getAge).reduce(0,(a,c)->a+c);
Integer ages3 = list.stream().filter(student -> "清华大学".equals(student.school)).map(User::getAge).reduce(0,Integer::sum);
Integer ages4 = list.stream().filter(student -> "清华大学".equals(student.school)).map(User::getAge).reduce(Integer::sum).get();
System.out.println(ages2);
System.out.println(ages3);
System.out.println(ages4);
System.out.println("归约 - - 》 end ");
输出结果为:
49
归约 - - 》 start
49
49
49
归约 - - 》 end
5 收集
前面利用collect(Collectors.toList())是一个简单的收集操作,是对处理结果的封装,对应的还有toSet、toMap,以满足我们对于结果组织的需求。这些方法均来自于java.util.stream.Collectors,我们可以称之为收集器。
收集器也提供了相应的归约操作,但是与reduce在内部实现上是有区别的,收集器更加适用于可变容器上的归约操作,这些收集器广义上均基于Collectors.reducing()实现。
5.1 counting
计算个数
如我现在计算user的总人数,实现如下:
|
1
2
3
4
5
|
System.out.println("user的总人数");long COUNT = list.stream().count();//简化版本long COUNT2 = list.stream().collect(Collectors.counting());//原始版本System.out.println(COUNT);System.out.println(COUNT2); |
输出结果为:
|
1
2
3
|
user的总人数1010 |
5.2 maxBy、minBy
计算最大值和最小值
如我现在计算user的年龄最大值和最小值:
|
1
2
3
4
5
6
7
8
9
|
System.out.println("user的年龄最大值和最小值");Integer maxAge =list.stream().collect(Collectors.maxBy((s1, s2) -> s1.getAge() - s2.getAge())).get().age;Integer maxAge2 = list.stream().collect(Collectors.maxBy(Comparator.comparing(User::getAge))).get().age;Integer minAge = list.stream().collect(Collectors.minBy((S1,S2) -> S1.getAge()- S2.getAge())).get().age;Integer minAge2 = list.stream().collect(Collectors.minBy(Comparator.comparing(User::getAge))).get().age;System.out.println("maxAge = " + maxAge);System.out.println("maxAge2 = " + maxAge2);System.out.println("minAge = " + minAge);System.out.println("minAge2 = " + minAge2); |
输出结果为:
|
1
2
3
4
5
|
user的年龄最大值maxAge = 25maxAge2 = 25minAge = 10minAge2 = 10 |
5.3 summingInt、summingLong、summingDouble
总和
如计算user的年龄总和:
|
1
2
3
|
System.out.println("user的年龄总和");Integer sumAge =list.stream().collect(Collectors.summingInt(User::getAge));System.out.println("sumAge = " + sumAge); |
输出结果为:
|
1
2
|
user的年龄总和sumAge = 145 |
5.4 averageInt、averageLong、averageDouble
平均值
如计算user的年龄平均值:
|
1
2
3
|
System.out.println("user的年龄平均值");double averageAge = list.stream().collect(Collectors.averagingDouble(User::getAge));System.out.println("averageAge = " + averageAge); |
输出结果为:
|
1
2
|
user的年龄平均值averageAge = 14.5 |
5.5 summarizingInt、summarizingLong、summarizingDouble
一次性查询元素个数、总和、最大值、最小值和平均值
|
1
2
3
4
5
6
|
System.out.println("一次性得到元素个数、总和、均值、最大值、最小值");long l1 = System.currentTimeMillis();IntSummaryStatistics summaryStatistics = list.stream().collect(Collectors.summarizingInt(User::getAge));long l111 = System.currentTimeMillis();System.out.println("计算这5个值消耗时间为" + (l111-l1));System.out.println("summaryStatistics = " + summaryStatistics); |
输出结果为:
|
1
2
3
|
一次性得到元素个数、总和、均值、最大值、最小值计算这5个值消耗时间为3summaryStatistics = IntSummaryStatistics{count=10, sum=145, min=10, average=14.500000, max=25} |
5.6 joining
字符串拼接
如输出所有user的名字,用“,”隔开
|
1
2
3
|
System.out.println("字符串拼接");String names = list.stream().map(User::getName).collect(Collectors.joining(","));System.out.println("names = " + names); |
输出结果为:
|
1
2
|
字符串拼接names = 张三,李四,王五,赵六,田七,小明,小红,小华,小丽,小何 |
5.7 groupingBy
分组
如将user根据学校分组、先按学校分再按年龄分、每个大学的user人数、每个大学不同年龄的人数:
|
1
2
3
4
5
6
7
8
9
|
System.out.println("分组");Map<String, List<User>> collect1 = list.stream().collect(Collectors.groupingBy(User::getSchool));Map<String, Map<Integer, Long>> collect2 = list.stream().collect(Collectors.groupingBy(User::getSchool, Collectors.groupingBy(User::getAge, Collectors.counting())));Map<String, Map<Integer, Map<String, Long>>> collect4 = list.stream().collect(Collectors.groupingBy(User::getSchool, Collectors.groupingBy(User::getAge, Collectors.groupingBy(User::getName,Collectors.counting()))));Map<String, Long> collect3 = list.stream().collect(Collectors.groupingBy(User::getSchool, Collectors.counting()));System.out.println("collect1 = " + collect1);System.out.println("collect2 = " + collect2);System.out.println("collect3 = " + collect3);System.out.println("collect4 = " + collect4); |
输出结果为:
|
1
2
3
4
5
|
分组collect1 = {浙江大学=[User{id=8, name='小华', age=14, school='浙江大学'}, User{id=9, name='小丽', age=17, school='浙江大学'}, User{id=10, name='小何', age=10, school='浙江大学'}], 北京大学=[User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=14, school='北京大学'}], 清华大学=[User{id=1, name='张三', age=10, school='清华大学'}, User{id=2, name='李四', age=12, school='清华大学'}, User{id=3, name='王五', age=15, school='清华大学'}, User{id=4, name='赵六', age=12, school='清华大学'}]}collect2 = {浙江大学={17=1, 10=1, 14=1}, 北京大学={16=1, 25=1, 14=1}, 清华大学={10=1, 12=2, 15=1}}collect3 = {浙江大学=3, 北京大学=3, 清华大学=4}collect4 = {浙江大学={17={小丽=1}, 10={小何=1}, 14={小华=1}}, 北京大学={16={小明=1}, 25={田七=1}, 14={小红=1}}, 清华大学={10={张三=1}, 12={李四=1, 赵六=1}, 15={王五=1}}} |
5.8 partitioningBy
分区,分区可以看做是分组的一种特殊情况,在分区中key只有两种情况:true或false,目的是将待分区集合按照条件一分为二,java8的流式处理利用ollectors.partitioningBy()方法实现分区。
如按照是否是清华大学的user将左右user分为两个部分:
|
1
2
3
|
System.out.println("分区");Map<Boolean, List<User>> collect5 = list.stream().collect(Collectors.partitioningBy(user1 -> "清华大学".equals(user1.school)));System.out.println("collect5 = " + collect5); |
输出结果为:
|
1
2
|
分区collect5 = {false=[User{id=5, name='田七', age=25, school='北京大学'}, User{id=6, name='小明', age=16, school='北京大学'}, User{id=7, name='小红', age=14, school='北京大学'}, User{id=8, name='小华', age=14, school='浙江大学'}, User{id=9, name='小丽', age=17, school='浙江大学'}, User{id=10, name='小何', age=10, school='浙江大学'}], true=[User{id=1, name='张三', age=10, school='清华大学'}, User{id=2, name='李四', age=12, school='清华大学'}, User{id=3, name='王五', age=15, school='清华大学'}, User{id=4, name='赵六', age=12, school='清华大学'}]} |
关于Java1.8新特性之stream暂时只说这些,希望对你能有所帮助,谢谢!
参考博客:https://blog.csdn.net/papima/article/details/81808445
什么式Stream
流(Stream)是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
集合讲的是数据,流讲的是计算
注意:
- Stream自己不会存储元素
- Stream不会改变源对象。相反,他会返回一个持有结果的新Stream
- Stream操作是延迟执行的。意味着他会等到需要结果的时候才执行
Stream操作的三个步骤
- 创建Stream
一个数据源(如:集合、数组),获取一个流 - 中间操作
一个中间操作链,对数据源的数据进行处理 - 终止操作(终端操作)
一个终止操作,执行中间操作链。并产生结果
示意图如下:
创建Stream
- default Stream<E> stream():返回一个顺序流
- default Stream<E> parallelStream():返回一个并行流
有数组创建流
static <T> Stream<T> stream(T[] array):返回一个流
由值创建流
public static<T> Stream<T> of(T… values):返回一个流
由函数创建流:创建无限流
- 迭代
public static<T> Stream<T> iterate(final T seed,final UnaryOperator<T> f)
- 生成
public static<T> Stream<T> generate(Supplier<T> s)
Stream的中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何处理!而在终止操作时一次性全部处理,称为“惰性求值”


Stream的终止操作
终止操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如List、Integer 甚至是void。



Collector接口中方法的实现决定了如何对流执行收集操作(如收集到List、Set、Map)。但是Collector实用类提供了很多静态方法可以方便的收集常见实例
 JDK8新特性关于Stream流
JDK8新特性关于Stream流

 浙公网安备 33010602011771号
浙公网安备 33010602011771号