HashMap扩容
HashMap扩容后,元素是如何重新分布的
https://blog.csdn.net/leisure_life/article/details/108489393
总结
到此目标完成,总结一下要点
1、HashMap的初始化是在插入第一个元素时调用resize完成的(源码629行)
2、不指定容量,默认容量为16(源码694)
3、指定容量不一定按照你的值来,会经过tableSizeFor转成不小于输入值的2的n次幂,源码378
这里有个小问题,tableSizeFor转换成2的n次幂不是直接赋值给capacity,而是先将值暂时保存在threshold,见源码457,然后在put第一个元素resize时,婉转的传递给newCap
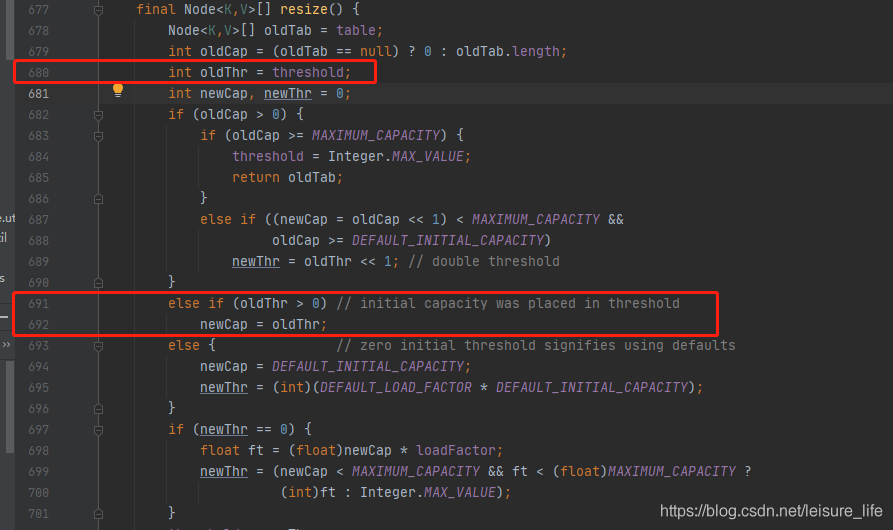
4、put元素时,元素的位置取决于数组的长度和key的hash值按位与的结果i = (n - 1) & hash源码630
4.1 如果这里没有元素,直接放这
4.2 如果有,判断是不是键冲突(源码634),直接新值覆盖旧值*(源码657)
4.3 如果有且不是键冲突,则将其放在原元素的next位置(源码642)
5、只有当size大于了扩容阈值size > threshold,才会触发扩容,源码662,扩容前,当前元素已经放好了
6、扩容时,容量和扩容阈值都翻番(源码687),但要小于MAXIMUM_CAPACITY
7、扩容时,元素在新表中的位置分情况
7.1 当元素只是孤家寡人即元素的next==null(源码)711时,位置为e.hash & (newCap - 1)(源码712)
7.2 当元素有next节点时,该链表上的元素分两类
7.21 e.hash & oldCap = 0的,在新表中与旧表中的位置一样(源码738)
7.22 e.hash & oldCap != 0的,位置为旧表位置+旧表容量,源码742
展望:
调了一天,还只是调了其中的一部分,初始化、初始扩容,和增量扩容,类似树化、拆树还没研究呢
构造树化的思路,也是从源码上找,主要是以下几行
只要你能让不同的key的hash值相同,并且key不相同,就可以制造出hash冲突,就能将多个元素放在同一个位置上
————————————————
版权声明:本文为CSDN博主「浪丶荡」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/leisure_life/article/details/108489393
Java8 HashMap扩容时为什么不需要重新hash
table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }
可以看到它是通过将数据的hash与扩容前的长度进行与操作,根据结果为0还是不为0来做对应的处理e.hash & oldCap。
举个例子
比如数据 A它经过hash之后的值为 0111(二进制),一开始map中数组的长度是 8,根据定位的逻辑 (n-1)&hash,那么数据A的位置是:
(n-1)&hash = (8-1) & 0111 = 111 & 0111 = 0111
1
扩容之后数组长度是原来的2倍,即16,假设我们重新算一遍A的位置,那么应该是:
(n-1)&hash =(16-1) & 0111 = 1111 & 0111 = 0111
1
可以看到数据A扩容之后,如果重新计算hash的话,它的位置是没有发生变化的,来看一下 e.hash & oldCap的结果
e.hash & oldCap = 0111 & 8 = 0111 & 1000 = 0
1
比如数据B它经过hash之后的值为 1111,在扩容之前数组长度是8,数据B的位置是:
(n-1)&hash = (8-1) & 1111 = 111 & 1111 = 0111
1
扩容之后,数组长度是16,重新计算hash位置是:
(n-1)&hash = (16-1) & 1111 = 1111 & 1111 = 1111
1
可见数据B的位置发生了变化,同时新的位置和原来的位置关系是:
新的位置(1111)= 1000+原来的位置(0111)=原来的长度(8)+原来的位置(0111)
继续看一下e.hash & oldCap的结果
e.hash & oldCap = 1111 & 8 = 1111 & 1000 = 1000 (!=0)
1
那么有没有看出规律呢,因为每次扩容都是2的倍数,计算位置的时候是和数组的长度-1做与操作,那么影响位置的数据只有最高的一位,比如 8-1 =7= 0111 ,16-1=15=1111 ,对于每个数据来说只有从右边数第四位的值会影响结果,当数据的hash的右边第四位为1的时候位置会发生变化,如上面的数据B,如果第四位为0,那么数据不会发生变化,如上面的数据A,而这个第四位 1000 恰好又是扩容前的数组长度,因此可以根据e.hash & oldCap的结果来判断,如果是0,说明位置没有发生变化,如果不为0,说明位置发生了变化,而且新的位置=老的位置+老的数组长度。
不过为什么当某个bin只有一个数据的时候要重新hash呢?
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
1
2
理论上也可以采用e.hash & oldCap这种方式?
————————————————
版权声明:本文为CSDN博主「zlp1992」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zlp1992/article/details/104376309
HashMap扩容后,元素是如何重新分布的
浪丶荡 2020-09-10 11:39:08 1359 收藏 10分类专栏: java框架 面试题 Java基础 文章标签: java 后端 hashmap 链表 面试版权上文回顾在上文深入源码分析HashMap到底是怎样将元素put进去的
我们着重分析了无参构造函数是如何创建map对象和HashMap是如何将第一个元素put进table的。
此篇重点这篇我们将逐行代码分析
1、有参构造函数是如何创建map对象的2、当元素增多导致扩容之后,元素是如何重新分布的同样,为了方便读者复盘,我截取源码是尽量将行号带上。
jdk版本还是1.8结构图再重复一遍,HashMap的底层数据结构为数组+链表+红黑树的结构,放一个HashMap的结构示意图,有个大致印象。
解剖思路创建一个有参构造函数,并往其中添加若干元素,直至触发扩容机制
为了方便方便计算hash值,key和value都选用比较小的字符串
关于调试键的使用请参照:IDEA调试键的说明,在此不再赘诉
调试代码public static void main(String[] args) {
System.out.println("★★★★★★解剖开始★★★★★★");
HashMap<String, String> map = new HashMap<>(12);
map.put("1", "1"); map.put("2", "2"); map.put("3", "3"); map.put("4", "4");
// 实验key相同的情况 map.put("4", "D");
map.put("5", "5"); map.put("6", "6"); map.put("7", "7"); map.put("8", "8"); map.put("9", "9"); map.put("10", "10"); map.put("11", "11"); map.put("12", "12");
// 第一个扩容点 map.put("13", "13"); map.put("14", "14"); map.put("15", "15"); map.put("16", "16");
map.put("17", "17"); map.put("18", "18"); map.put("19", "19"); map.put("20", "20");
map.put("21", "21"); map.put("22", "22"); map.put("23", "23"); map.put("24", "24");
//第二个扩容点 map.put("25", "25");
}
123456789101112131415161718192021222324252627282930313233343536373839404142434445断点打在第一行
以debug模式启动,开始解剖之旅点击Step Over到HashMap<String, String> map = new HashMap<>(12);所在行
点击Force Step Into,会发现先调用的是类加载器
这不是今天的重点,我们直接Step Out,然后再次点击Force Step Into,进入源码
调用的是双参构造函数DEFAULT_LOAD_FACTOR为0.75,initialCapacity为12,继续Force Step Into
上图来到双参构造函数,继续Force Step Into会发现依旧调用了父类的构造函数
掉完父类构造函数,继续双参构造函数,经过参数校验,源码456行之后,loadFactor=0.75,我们重点看看this.threshold = tableSizeFor(initialCapacity)
在457行Force Step Into,会发现跳转到tableSizeFor(int cap)
关于tableSizeFor(int cap),在以前的文章详细分析过,有兴趣的可以去看看 读HashMap源码之tableSizeFor,这里直接说结论,就是你给一个初始容量值,经过这个方法后,返回一个最接近该值的、且不小于该值本身的2^n的那个值,当然,最大不能超过static final int MAXIMUM_CAPACITY = 1 << 30即2的30次方
所以这里传入12返回的应该是16,n = 15 ,n+1 = 16
所以看到这应该明白,管你传9 10 11 12 13 14 15 16,经过tableSizeFor后都是返回16,这样就确保了threshold总是2的n次方,后面就会发现,其实这个值不是给扩容阈值的,而是给map的初始容量
继续Force Step Into回到双参函数,将tableSizeFor的结果赋值给threshold扩容阈值=16
开始 put到此初始化map完成,其实到了这一步,table还没建立,继续往下Force Step Into开始put
继续Force Step Into进入map.put("1", "1");,来到源码的put(K key, V value)
源码的put(K key, V value)又是调用的putVal,调用之前会计算一下key的hash值,进去看看
key.hashCode()调用的是String的hashCode
然后返回put方法进入putVal,继续Force Step Into,此时hash值为49
因为在初始化时,并没有看到有初始化table,所以此处的table肯定是null
那顺理成章的就要执行resize()了,继续Force Step Into,进入resize()
这个我们在上文 **深入源码分析HashMap到底是怎样将元素put进去的**已经分析了一次,鉴于比较复杂,就再分析一次,还是一样,代码执行路径用红框标记出来
直接返回newTab
通过对上面源码的走读,发现带参构造函数创建的map,
初始容量就取决于源码692行的newCap = oldThr;,
而oldThr又取决于源码680行的int oldThr = threshold;
还记得threshold怎么来的吗,源码457行的tableSizeFor(int initialCapacity),你说狗不狗,在这等你呢,所以tableSizeFor的真实目的是为了确保所有map初始化时容量均为2的n次幂
扯远了,回来,拉回来,继续Force Step Into,刚刚走到table创建完,即首次resize完成
有了数组了,长度也知道了,该考虑元素位置了,上文也详细讲解了,
决定元素位置的是(n - 1) & hash表达式的结果,自己想动手算的参照上文的方法去算
这里直接看结果,计算出i=1
因为是刚刚创建的,所以tab[1]自然为null,顺理成章的就执行tab[i] = newNode(hash, key, value, null);,构建一个链表的节点放入1号位
继续调试,执行完放入元素之后modCount自增,size自增,并和扩容阈值(当前是12)比较,1小于12不用扩容,
执行完毕,关于modCount见上文
自己画个示意图,大概就是这样的,只有1号位置有元素,其他的均为null
继续Force Step Into,继续map.put("2", "2");,这次算的hash值为50,但此时table不再为null,直接计算位置,1等于2,且该位置为null,直接构造一个Node放进去
依次类推,我们就不一一看了,直接Step Over到map.put("4", "D");,看看key值相同,value不同时怎么处理
一路Force Step Into,来到putVal,发现hash还是52,定位的i也是4,个位置已经有元素了,所以走了源码634行
仔细研究一下这行代码
p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))1p.hash == hash为ture,(k = p.key) == key也为真so执行e = p;,然后暂时还没有树化,所以源码656行直接将新的value覆盖旧的的value
至此,覆盖问题解决,继续Force Step Into,后面没有值重复的,经过一路Force Step Into,1-9位置示意图如下
一直put、put、put直到map.put("10", "10");,为什么到了这里停下来看呢,因为此时hash只不同了,位置大概率也会不同,进去看看
果然,此时hash已经变成了1567,比之前的递增大了很多,位置也变成了15,与此类似,11的位置为0
截止到目前已经放了11个元素,位置示意图如下
理论上,再放一个就触及到了我们的扩容阈值threshold = 16*0.75 = 12,但看一下源码662行
其实12的时候还不会,是要大于12才会,那就继续Force Step Into走进map.put("12", "12")
事情开始起变化,这hash值不同,但计算的位置i=1上却已经有了元素
上面红色框就是代码执行路径,源码642表明12节点被放在p节点即1号位置的next,而e在源码641赋值时p.next此时还是null,所以下面的代码路径是正确的
所以此时的key=1就有了next,此时示意图如下:
继续Force Step Into,发现前半段map.put("13", "13");还是和map.put("12", "12");一样本来按照剧本,key=13应该被放到2号位置key=2的next示意图应该如下
但是,万事就怕但是,在这里if (++size > threshold)不满足了
增量扩容他要再次执行resize()了进去瞧瞧,先不管元素移动,先看扩容
对比第一次的resize来看
元素迁移第二次的容量和阈值都比第一次大了2倍,且oldTab不再为null,需要将oldTab迁移到newTab
所以接下来我们就要品读这段代码了,你先品品
if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } }123456789101112131415161718192021222324252627282930313233343536373839404142回到正题,继续Force Step Into,看源码707行,for (int j = 0; j < oldCap; ++j)就是要循环整个旧表
上面的代码分三种情况来读
一是位置上只有一个Node元素,即next为null的,类似上面的3-9号位置上都只有一个元素第二种一个位置上有多个元素的,类似上面的1、2号位置,目前都有两个元素第三种就是此位置上的元素为TreeNode类型的,目前没有,今天先不考虑对于第一种情况,核心操作就是源码712行的newTab[e.hash & (newCap - 1)] = e;
计算该元素在新表中的位置,e.hash & (newCap - 1)
所以0号元素经过e.hash & (newCap - 1)即1568 & 31后,工具计算结果在新表的位置是0
然后第二个元素即1号元素,正好是第二种情况,示意图再看一下
源码709行oldTab[1]不为null,711行e.next也不为null
且e instanceof TreeNode也是false,所以核心流程来到了719行的do……while
把do……while这段单独拎出来看,先定义两个链表的头和尾,一个链表用来装与旧表元素位置相同的元素,一个用来装需要重新分配位置的元素
Node<K,V> loHead = null, loTail = null;// 位置相同的链表的头尾 Node<K,V> hiHead = null, hiTail = null;// 位置要移动的链表头尾 Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; }12345678910111213141516171819202122232425262728当key=1元素开始执行时,源码721行e.hash & oldCap即46 & 16 != 0,跳转至源码729
继续循环1号位置,此时e.hash & oldCap为1569 & 16结果为0,所以将e赋值给loHead,同时链表尾部loTail也指向e
由于只有两个元素,循环到此结束了
最后将loHead放在newTab[1]即在新数组中与旧数组位置相同的地方
而hiHead则被放在新的数组newTab[1 + 16]即在旧数组位置基础上再加上旧数组的容量
以此类推,2号位上的两个元素分别被放置在新表的2号和2+16号位置上
最后操作下来,位置关系如示意图
总结到此目标完成,总结一下要点
1、HashMap的初始化是在插入第一个元素时调用resize完成的(源码629行)2、不指定容量,默认容量为16(源码694)3、指定容量不一定按照你的值来,会经过tableSizeFor转成不小于输入值的2的n次幂,源码378这里有个小问题,tableSizeFor转换成2的n次幂不是直接赋值给capacity,而是先将值暂时保存在threshold,见源码457,然后在put第一个元素resize时,婉转的传递给newCap
4、put元素时,元素的位置取决于数组的长度和key的hash值按位与的结果i = (n - 1) & hash源码6304.1 如果这里没有元素,直接放这4.2 如果有,判断是不是键冲突(源码634),直接新值覆盖旧值*(源码657)4.3 如果有且不是键冲突,则将其放在原元素的next位置(源码642)5、只有当size大于了扩容阈值size > threshold,才会触发扩容,源码662,扩容前,当前元素已经放好了6、扩容时,容量和扩容阈值都翻番(源码687),但要小于MAXIMUM_CAPACITY7、扩容时,元素在新表中的位置分情况7.1 当元素只是孤家寡人即元素的next==null(源码)711时,位置为e.hash & (newCap - 1)(源码712)7.2 当元素有next节点时,该链表上的元素分两类7.21 e.hash & oldCap = 0的,在新表中与旧表中的位置一样(源码738)
7.22 e.hash & oldCap != 0的,位置为旧表位置+旧表容量,源码742
展望:调了一天,还只是调了其中的一部分,初始化、初始扩容,和增量扩容,类似树化、拆树还没研究呢
构造树化的思路,也是从源码上找,主要是以下几行只要你能让不同的key的hash值相同,并且key不相同,就可以制造出hash冲突,就能将多个元素放在同一个位置上,然后直至触发树化,具体情况我们下回分解。
为了写这玩意,死了我多少脑细胞
喝瓶八二年的矿泉水,不过分吧?我自己去买,你买单就行了————————————————版权声明:本文为CSDN博主「浪丶荡」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/leisure_life/article/details/108489393

 浙公网安备 33010602011771号
浙公网安备 33010602011771号