java面试--360
1题
执行以下程序后的输出结果是()
public class Test {
public static void main(String[] args) {
StringBuffer a = new StringBuffer(“A”);
StringBuffer b = new StringBuffer(“B”);
operator(a, b);
System.out.println(a + “,” + b);
}
public static void operator(StringBuffer x, StringBuffer y) {
x.append(y); y = x;
}
}
答案:AB,B
解析:a,b是对象的引用,指向堆内存,将a,b两个引用传给x,y,执行x.append(y),改变了x引用指向的堆内存的存储内容,变为AB, y = x,表示引用y,指向引用x指向的存储区域,没有改变引用b,指向的存储空间的内容。一句话解决:string是值传递,stringbuffer是引用传递。。所以就这样了。
2题
结构型模式中最体现扩展性的几种模式是()
答案:装饰模式
解析:A 装饰模式
定义:动态给一个对象添加一些额外的职责,就象在墙上刷油漆.使用Decorator模式相比用生成子类方式达到功能的扩充显得更为灵活。
设计初衷:通常可以使用继承来实现功能的拓展,如果这些需要拓展的功能的种类很繁多,那么势必生成很多子类,增加系统的复杂性,同时,使用继承实现功能拓展,我们必须可预见这些拓展功能,这些功能是编译时就确定了,是静态的。装饰模式的作用就是为了:
1.扩展功能
2.不用继承
从这点来说可以算“最能体现”扩展性吧。
3题
在Linux中,对file.sh文件执行#chmod 645 file.sh中,该文件的权限是()
答案:-rw-r–r-x
解析:Linux下权限对应的数字为:
r =4, w =2, x =1
所以,6就是rw-
4就是r–
5就是r-x
所以,选D
4题
TCP建立连接的过程采用三次握手,已知第三次握手报文的发送序列号为1000,确认序列号为2000,请问第二次握手报文的发送序列号和确认序列号分别为
答案:1999,1000
解析:发送序列是自己发送报文的序列号,当前发送序列号是上一次发送序列号+1
确认序列号是从对方接收到的发送序列号+1
第三次握手发送的序列号是1000,那说明第一次握手发送的序列号是999,注意:这里是握手
,因此,第二次握手的确认序列号是1000,即确认序列号是从对方接收到的发送序列号+1。
第三次握手发送的确认号是2000,说明第二次握手的发送序列号是1999。
所以,选B
5题
下列TCP连接建立过程描述正确的是:
答案:当客户端处于ESTABLISHED状态时,服务端可能仍然处于SYN_RCVD状态
解析:此题主要考察TCP三次握手,四次挥手的状态变化,对着图看吧,加深印象。
三次握手如下:
6题
属于网络112.10.200.0/21的地址是()
答案:112.10.206.0
解析:前21位为网络地址,后12位为主机地址。
110 对应前8位,10对应第二个8位,因此200对应第3个8位
又200的二进制表示为1100 1000
前面已经有了16位,因此11001 是属于网络地址的。000是属于主机地址 那么,最大的地址为
【110(十进制)】【10(十进制)】【11001 111】【 11111111】转换为十进制为110.10.207.255
故网络的地址范围为
110.10.200.0~110.10.207.255
故A为正确答案
7题
以下java程序代码,执行后的结果是()
java.util.HashMap map=new java.util.HashMap();
map.put(“name”,null);
map.put(“name”,”Jack”);
System.out.println(map.size());
答案:1
解析:HashMap可以插入null的key或value,插入的时候,检查是否已经存在相同的key,如果不存在,则直接插入,如果存在,则用新的value替换旧的value,在本题中,第一条put语句,会将key/value对插入HashMap,而第二条put,因为已经存在一个key为name的项,所以会用新的value替换旧的vaue,因此,两条put之后,HashMap中只有一个key/value键值对。那就是(name,jack)。所以,size为1.
8题
以下java程序代码,执行后的结果是()
public class Test {
public static void main(String[] args) {
Object o = new Object() {
public boolean equals(Object obj) {
return true;
}
};
System.out.println(o.equals(“Fred”));
}
}
答案:true
解析:1.建立了一个匿名内部类,并重写了Object的equals方法。
2.通过o调用了equals方法,方法返回true。
9题
代码片段:
byte b1=1,b2=2,b3,b6;
final byte b4=4,b5=6;
b6=b4+b5;
b3=(b1+b2);
System.out.println(b3+b6);
关于上面代码片段叙述正确的是()
答案:语句:b3=b1+b2编译出错
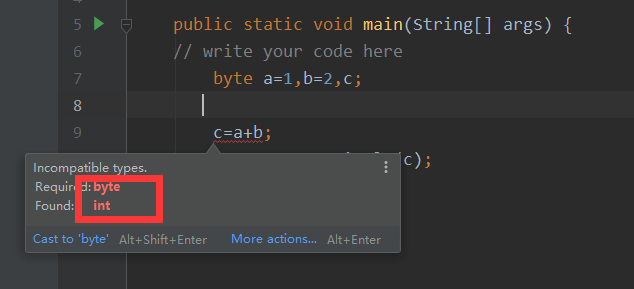
解析:表达式的数据类型自动提升, 关于类型的自动提升,注意下面的规则。
①所有的byte,short,char型的值将被提升为int型;
②如果有一个操作数是long型,计算结果是long型;
③如果有一个操作数是float型,计算结果是float型;
④如果有一个操作数是double型,计算结果是double型;
而声明为final的变量会被JVM优化,第6行相当于 b6 = 10
若有不对,请指正
10题
下面代码运行结果是()
public class Test{
public int add(int a,int b){
try {
return a+b;
}
catch (Exception e) {
System.out.println(“catch语句块”);
}
finally{
System.out.println(“finally语句块”);
}
return 0;
}
public static void main(String argv[]){
Test test =new Test();
System.out.println(“和是:”+test.add(9, 34));
}
}
答案:finally语句块,和是:43
解析: 程序先执行try块中return之前(包括return语句中的表达式运算)的代码; 再执行finally块,最后执行try块中的return; 而 finally块之后的return语句,因为程序在try块中已经return了,所以不再执行。
11题
以下情况下不一定出现TCP分节RST的情况是:
答案:服务器主机崩溃后重启
解析:四种情况会发送RST包:
1、端口未打开
2、请求超时
3、提前关闭
4、在一个已关闭的socket上收到数据
12题
一个数据库中现有A,B,C,D,E,F六个语句但目前这个数据库是不协调的,必须删除某些语句才能恢复数据库的协调性。已知:(1)如果保留语句A,那么必须保留语句B和C。(2)如果保留语句E,则必须同时删除语句D和语句C。(3)只有保留语句E,才能保留语句F。(4)语句A是重要的信息,不能删除以上各项如果为真,则以下哪项一定为真?
答案:同时删除语句E和语句F
解析:根据(4),A必须有;
再根据(1),B,C必须有,此时一定有ABC
根据(2),因为有C,所以一定没有E
根据(3),因为没有E,所以一定没有F
综上,ABC一定有,EF一定没有,D不确定
13题
下列关于静态工厂和工厂方法表述错误的是:()
答案:二者都满足开闭原则:静态工厂以if else方式创建对象,增加需求的时候会修改源代码
解析:选D,开闭原则:对扩展开放,对修改封闭。静态工厂增加需要是修改源代码,对修改不封闭,不符合开闭原则。
14题
设有一个用数组Q[1..m]表示的环形队列,约定f为当前队头元素在数组中的位置,r为队尾元素的后一位置(按顺时针方向),若队列非空,则计算队列中元素个数的公式应为()
答案:(m+r-f)mod m
解析:(1)当尾大于头长度为 尾 - 头当尾小于头 例如尾巴在2号位置,而头在4号位置。表的长度为4 1 2,而这段长度为 总长度 - (尾 -头 ) = 总长度 - ( 尾 -头 ) 而 ( 尾 -头 ) < 0所以 得到 总长度+ ( 尾 -头 ) 。
因此合并两个表达式 得到 (总长度+ ( 尾 -头 ))%总长度 ,% 防止(1)情况发生溢出。
1
4 2
3
15题
以下程序是用辗转相除法来计算两个非负数之间的最大公约数:
long long gcd(long long x,long long y){
if(y==0)
return x;
else return gcd(y,x%y);
}
我们假设x,y中最大的那个数的长度为n,基本基本运算时间复杂度是O(1),那么该程序的时间复杂度为()
答案:O(logn)
解析:快速的思路是排除法,不是与固定几个值计算,所以不是O(1)的,当然也不会把每个数都遍历个遍来确定,不是O(n)和O(n^2)的,于是选择A。
当然如果感兴趣的话,可以做一个实验:在10000以内两两辗转相除法,运算次数最多的是哪两个数呢?
6765和 4181
如果把上界再缩小或扩大,你会发现,出现的数都是斐波那契数列中的数,都是相邻的两项。
因为斐波那契数列相邻两项在做gcd的时候,每次mod只相当于做了一次a-b,退化成更相减损术了,而没有起到mod的加速效果。
而斐波那契数列有通项公式,第n项的值是与某两个无理数的n次相关的。所以,是logn了
(当然这个证明还是很不科学的)
16题
计算斐波那契数列第n项的函数定义如下:
int fib(int n){
if(n==0)
return 1;
else if(n==1)
return 2;
else
return fib(n-1)+fib(n-2);
}
若执行函数调用表达式fib(10),函数fib被调用的次数是:
答案:177
解析:f(10)=f(9)+f(8)+1
= 2f(8)+f(7)+2
=3f(7)+2f(6)+4
=5f(6)+3f(5)+7
…
=55f(1)+34f(0)+88
55+34+88=177
17题
设图G的相邻矩阵如下图:则G的顶点数和边数分别为:
0 1 1 1 1
1 0 1 0 0
1 1 0 1 1
1 0 1 0 1
1 0 1 1 0
答案:5,8
解析:笨方法:把图按照相邻矩阵画出来;
简单方法:只计算主对角线的上三角或下三角有多少个 1 即可。矩阵为5*5,则有五个顶点;关于主对角线对称,则为无向图;无向图中,边数目等于上/下三角矩阵中的非零元素数目。
————————————————
版权声明:本文为CSDN博主「quentain」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/quentain/article/details/47830853
1.Math.round
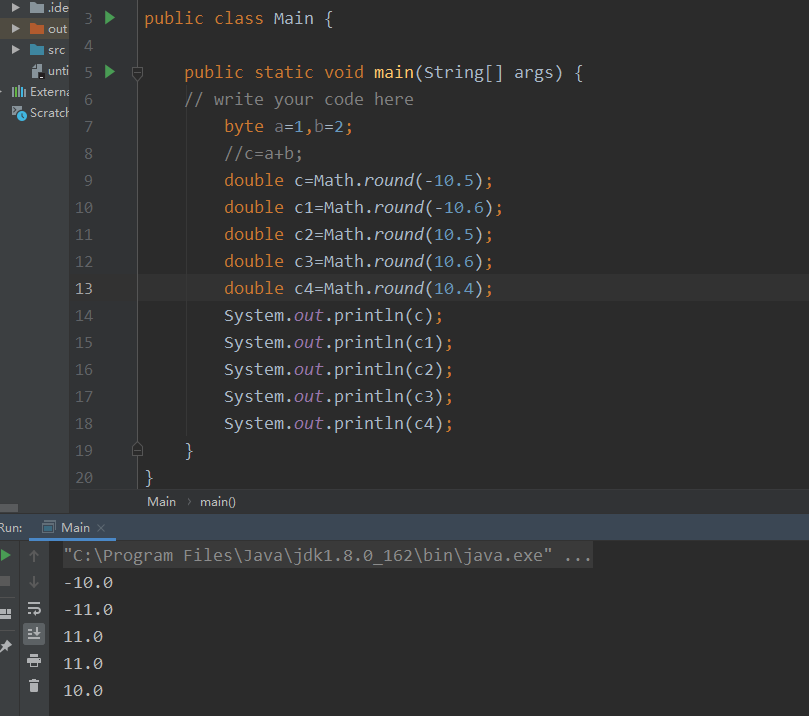
1.
double a = 0.001;
double b = 0.0011;
BigDecimal data1 = new BigDecimal(a);
BigDecimal data2 = new BigDecimal(b);
data1.compareTo(data2)
非整型数,运算由于精度问题,可能会有误差,建议使用BigDecimal类型!
public int compareTo(BigDecimal val)
- 将此 BigDecimal 与指定的 BigDecimal 比较。根据此方法,值相等但具有不同标度的两个 BigDecimal 对象(如,2.0 和 2.00)被认为是相等的。相对六个 boolean 比较运算符 (<, ==, >, >=, !=, <=) 中每一个运算符的各个方法,优先提供此方法。建议使用以下语句执行上述比较: (x.compareTo(y) < op> 0),其中 < op> 是六个比较运算符之一。
- 指定者:
- 接口
Comparable<BigDecimal>中的compareTo
- 接口
- 参数:
val- 将此 BigDecimal 与之比较的 BigDecimal。 返回:- 当此 BigDecimal 在数字上小于、等于或大于 val 时,返回 -1、0 或 1。
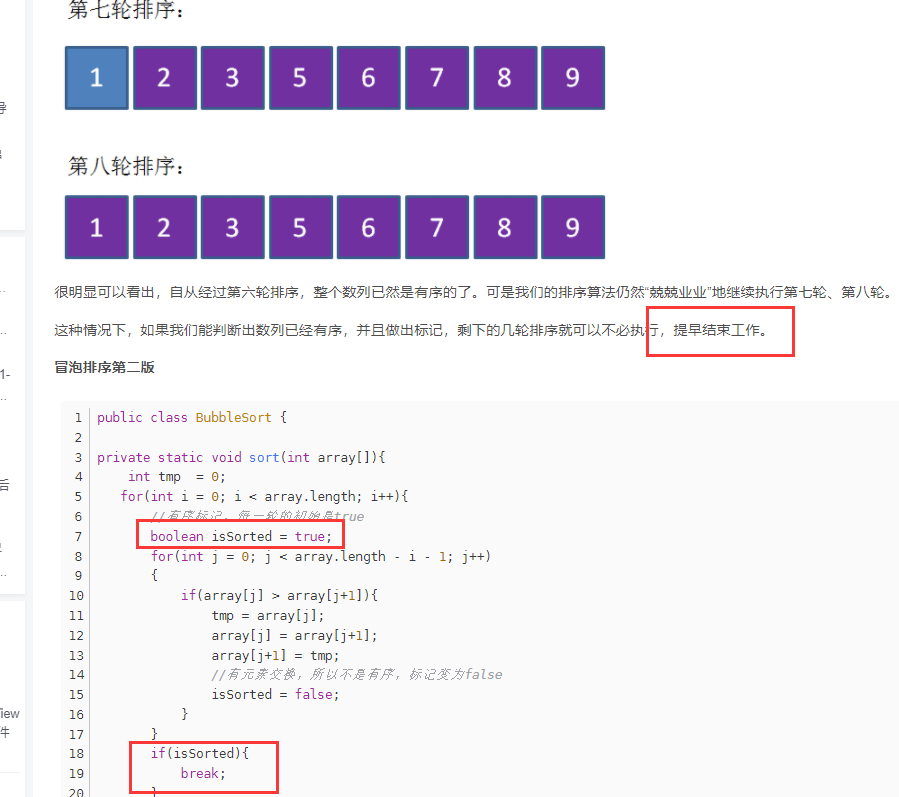
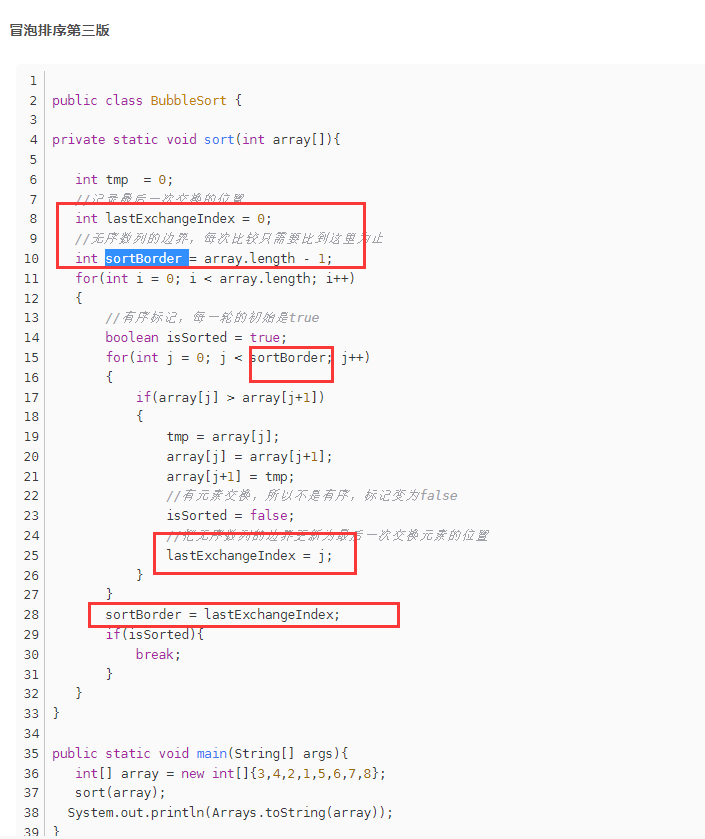
2. 冒泡排序优化
https://blog.csdn.net/wubingju93123/article/details/81215984
- 3.二分查找优化 (需要有序,首先排序)
- https://blog.csdn.net/interesting_code/article/details/104321864
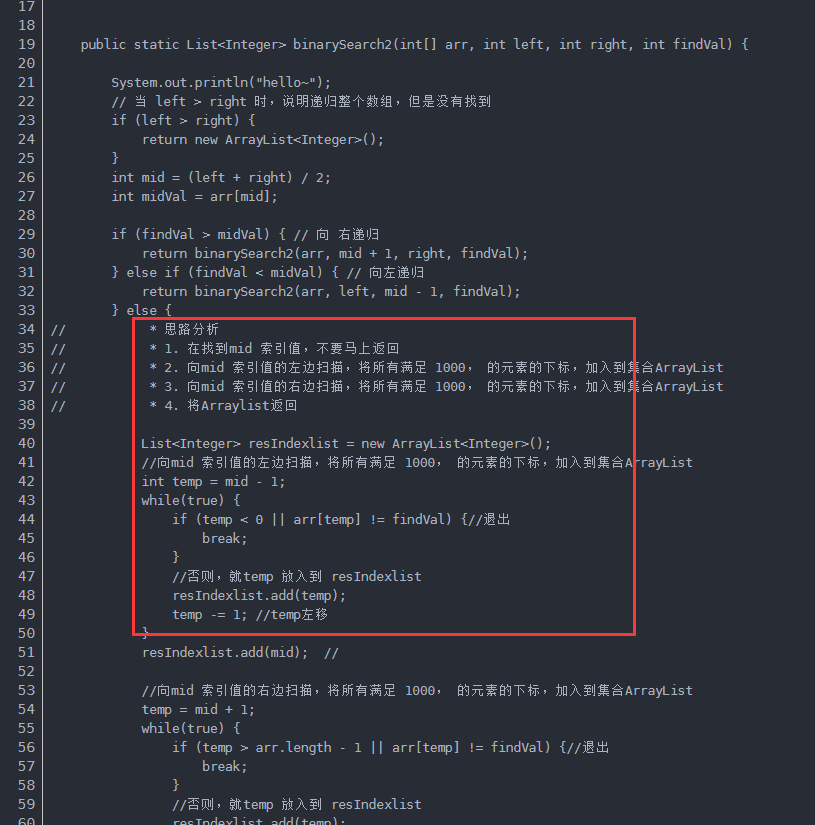
4.Shell脚本 https://www.jb51.net/article/135168.htm

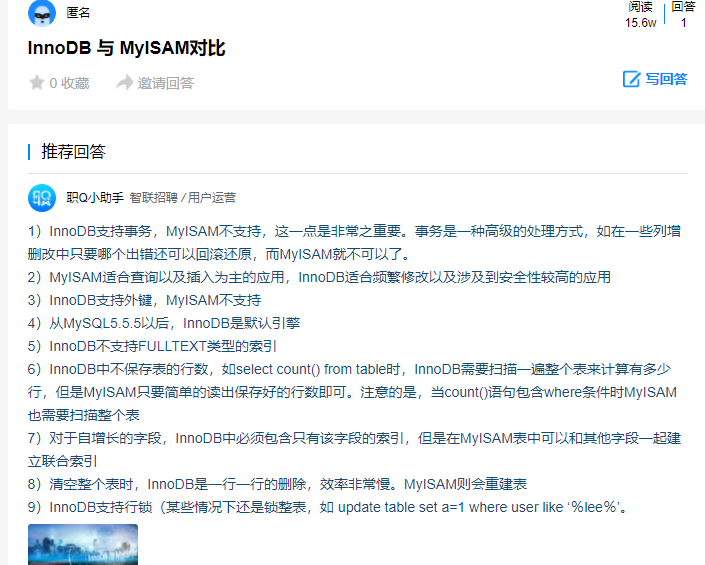
4.myisam和innodb的区别 区别
5.职业规划

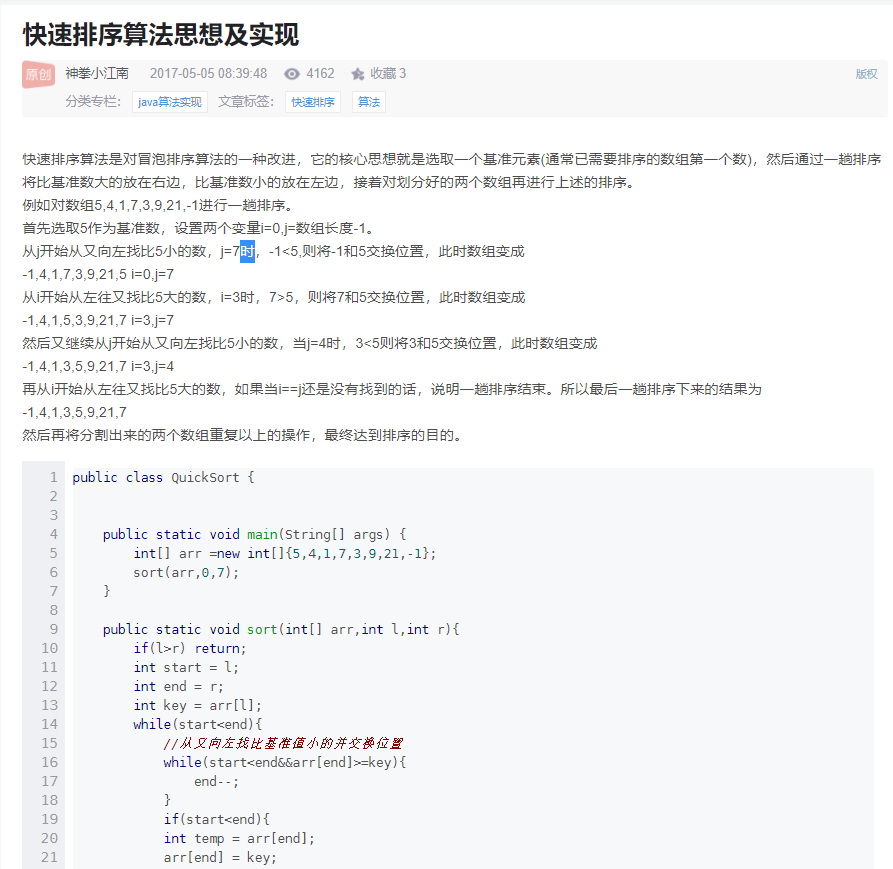
6.快速排序算法思想及实现 https://blog.csdn.net/u014507784/article/details/71190825
7.mybatis 缓存和延迟加载 https://blog.csdn.net/weixin_46731640/article/details/105331423
java mybaits工作原理_MyBatis工作原理
不会唱歌了 2021-02-16 23:28:16 64 收藏
文章标签: java mybaits工作原理
版权
在学习MyBatis程序之前,需要了解一下MyBatis工作原理,以便于理解程序。MyBat数据库在学习 MyBatis 程序之前,需要了解一下 MyBatis 工作原理,以便于理解程序。MyBatis 的工作原理如下图
1)读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
2)加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
3)构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
4)创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
5)Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
6)MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
7)输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
8)输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
本文由来源 ThinkWon的博客,由 system_mush 整理编辑,其版权均为 ThinkWon的博客 所有,文章内容系作者个人观点,不代表 Java架构师必看 对观点赞同或支持。如需转载,请注明文章来源。
————————————————
版权声明:本文为CSDN博主「不会唱歌了」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_33323907/article/details/1142534898 面试经验

首先,我们分别对这三者进行阐述。
JVM :英文名称(Java Virtual Machine),就是我们耳熟能详的 Java 虚拟机。它只认识 xxx.class 这种类型的文件,它能够将 class 文件中的字节码指令进行识别并调用操作系统向上的 API 完成动作。所以说,jvm 是 Java 能够跨平台的核心,具体的下文会详细说明。
JRE :英文名称(Java Runtime Environment),我们叫它:Java 运行时环境。它主要包含两个部分,jvm 的标准实现和 Java 的一些基本类库。它相对于 jvm 来说,多出来的是一部分的 Java 类库。
JDK :英文名称(Java Development Kit),Java 开发工具包。jdk 是整个 Java 开发的核心,它集成了 jre 和一些好用的小工具。例如:javac.exe,java.exe,jar.exe 等。
显然,这三者的关系是:一层层的嵌套关系。JDK>JRE>JVM。
 10 面试——final 在 java 中有什么作用?
10 面试——final 在 java 中有什么作用?final作为Java中的关键字可以用于三个地方。用于修饰类、类属性和类方法。
特征:凡是引用final关键字的地方皆不可修改!
(1)修饰类:表示该类不能被继承;
(2)修饰方法:表示方法不能被重写;
(3)修饰变量:表示变量只能一次赋值以后值不能被修改(常量)。
“final修饰的类不能被继承,没有子类。如果类中有抽象的方法也是没有意义的。abstract类为抽象类。即该类只关心子类具有的功能,而不是功能的具体实现。如果 用final修饰方法,那么该方法则不能再被重写。final 是不能修饰abstract所修饰的方法的。”
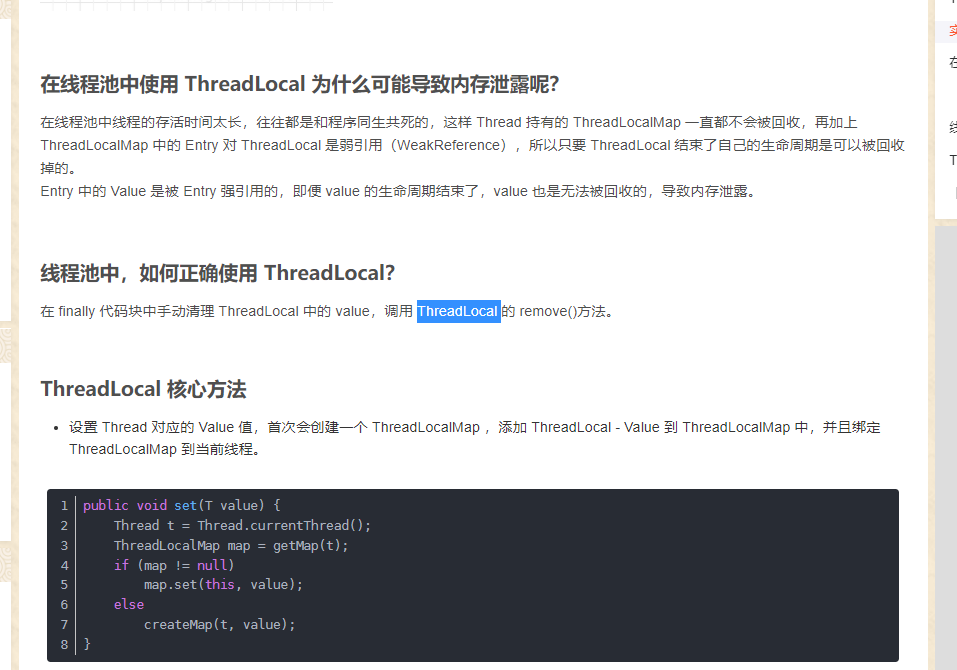
11 ,ThreadLocal
https://blog.csdn.net/meism5/article/details/90413860
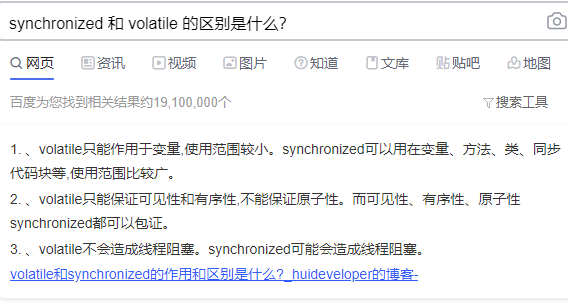
12 synchronized和lock的用法区别
在分布式开发中,锁是线程控制的重要途径。Java为此也提供了2种锁机制,synchronized和lock。做为Java爱好者,自然少不了对比一下这2种机制,也能从中学到些分布式开发需要注意的地方。
我们先从最简单的入手,逐步分析这2种的区别。
一、synchronized和lock的用法区别
synchronized:在需要同步的对象中加入此控制,synchronized可以加在方法上,也可以加在特定代码块中,括号中表示需要锁的对象。
lock:需要显示指定起始位置和终止位置。一般使用ReentrantLock类做为锁,多个线程中必须要使用一个ReentrantLock类做为对象才能保证锁的生效。且在加锁和解锁处需要通过lock()和unlock()显示指出。所以一般会在finally块中写unlock()以防死锁。
用法区别比较简单,这里不赘述了,如果不懂的可以看看Java基本语法。
二、synchronized和lock性能区别
synchronized是托管给JVM执行的,而lock是java写的控制锁的代码。在Java1.5中,synchronize是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用Java提供的Lock对象,性能更高一些。但是到了Java1.6,发生了变化。synchronize在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在Java1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronize,在未来的版本中还有优化余地。
说到这里,还是想提一下这2中机制的具体区别。据我所知,synchronized原始采用的是CPU悲观锁机制,即线程获得的是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。而在CPU转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起CPU频繁的上下文切换导致效率很低。
而Lock用的是乐观锁方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁实现的机制就是CAS操作(Compare and Swap)。我们可以进一步研究ReentrantLock的源代码,会发现其中比较重要的获得锁的一个方法是compareAndSetState。这里其实就是调用的CPU提供的特殊指令。
现代的CPU提供了指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。这个算法称作非阻塞算法,意思是一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法。
我也只是了解到这一步,具体到CPU的算法如果感兴趣的读者还可以在查阅下,如果有更好的解释也可以给我留言,我也学习下。
三、synchronized和lock用途区别
synchronized原语和ReentrantLock在一般情况下没有什么区别,但是在非常复杂的同步应用中,请考虑使用ReentrantLock,特别是遇到下面2种需求的时候。
1.某个线程在等待一个锁的控制权的这段时间需要中断
2.需要分开处理一些wait-notify,ReentrantLock里面的Condition应用,能够控制notify哪个线程
3.具有公平锁功能,每个到来的线程都将排队等候
下面细细道来……
https://www.cnblogs.com/aeolian/p/9229149.html
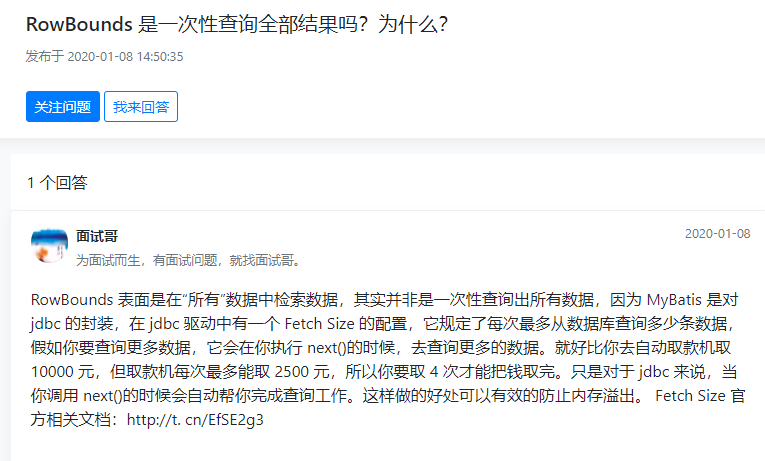
相关问题
https://blog.csdn.net/weixin_41847891/article/details/100623375
14 JVM
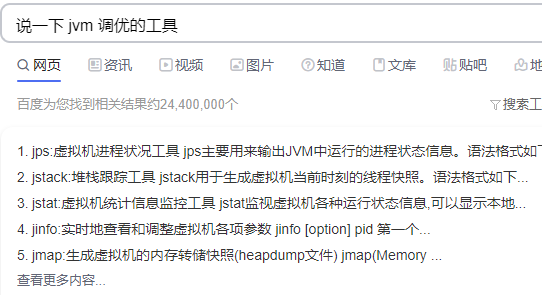

15
Java程序员从360、字节跳动面试回来,这些面试题刷到你懵逼
https://blog.csdn.net/uxiAD7442KMy1X86DtM3/article/details/106232794
16 奇虎360Java笔试题
https://www.cnblogs.com/zhchoutai/p/8296142.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号