重写hashcode和equals方法
重写hashcode和equals方法
简乐君 2019-05-07 21:55:43 35481 收藏 191
分类专栏: Java 文章标签: equals() hashcode()
版权
一。前言
我们都知道,要比较两个对象是否相等时需要调用对象的equals()方法,即判断对象引用所指向的对象地址是否相等,对象地址相等时,那么与对象相关的对象句柄、对象头、对象实例数据、对象类型数据等也是完全一致的,所以我们可以通过比较对象的地址来判断是否相等。
二。Object源码理解
对象在不重写的情况下使用的是Object的equals方法和hashcode方法,从Object类的源码我们知道,默认的equals 判断的是两个对象的引用指向的是不是同一个对象;而hashcode也是根据对象地址生成一个整数数值;
另外我们可以看到Object的hashcode()方法的修饰符为native,表明该方法是否操作系统实现,java调用操作系统底层代码获取哈希值。
public class Object {
public native int hashCode();
/**
* Indicates whether some other object is "equal to" this one.
* <p>
* The {@code equals} method implements an equivalence relation
* on non-null object references:
* <ul>
* <li>It is <i>reflexive</i>: for any non-null reference value
* {@code x}, {@code x.equals(x)} should return
* {@code true}.
* <li>It is <i>symmetric</i>: for any non-null reference values
* {@code x} and {@code y}, {@code x.equals(y)}
* should return {@code true} if and only if
* {@code y.equals(x)} returns {@code true}.
* <li>It is <i>transitive</i>: for any non-null reference values
* {@code x}, {@code y}, and {@code z}, if
* {@code x.equals(y)} returns {@code true} and
* {@code y.equals(z)} returns {@code true}, then
* {@code x.equals(z)} should return {@code true}.
* <li>It is <i>consistent</i>: for any non-null reference values
* {@code x} and {@code y}, multiple invocations of
* {@code x.equals(y)} consistently return {@code true}
* or consistently return {@code false}, provided no
* information used in {@code equals} comparisons on the
* objects is modified.
* <li>For any non-null reference value {@code x},
* {@code x.equals(null)} should return {@code false}.
* </ul>
* <p>
* The {@code equals} method for class {@code Object} implements
* the most discriminating possible equivalence relation on objects;
* that is, for any non-null reference values {@code x} and
* {@code y}, this method returns {@code true} if and only
* if {@code x} and {@code y} refer to the same object
* ({@code x == y} has the value {@code true}).
* <p>
* Note that it is generally necessary to override the {@code hashCode}
* method whenever this method is overridden, so as to maintain the
* general contract for the {@code hashCode} method, which states
* that equal objects must have equal hash codes.
*
* @param obj the reference object with which to compare.
* @return {@code true} if this object is the same as the obj
* argument; {@code false} otherwise.
* @see #hashCode()
* @see java.util.HashMap
*/
public boolean equals(Object obj) {
return (this == obj);
}
}
三。需要重写equals()的场景
假设现在有很多学生对象,默认情况下,要判断多个学生对象是否相等,需要根据地址判断,若对象地址相等,那么对象的实例数据一定是一样的,但现在我们规定:当学生的姓名、年龄、性别相等时,认为学生对象是相等的,不一定需要对象地址完全相同,例如学生A对象所在地址为100,学生A的个人信息为(姓名:A,性别:女,年龄:18,住址:北京软件路999号,体重:48),学生A对象所在地址为388,学生A的个人信息为(姓名:A,性别:女,年龄:18,住址:广州暴富路888号,体重:55),这时候如果不重写Object的equals方法,那么返回的一定是false不相等,这个时候就需要我们根据自己的需求重写equals()方法了。
package jianlejun.study; public class Student { private String name;// 姓名 private String sex;// 性别 private String age;// 年龄 private float weight;// 体重 private String addr;// 地址 // 重写hashcode方法 @Override public int hashCode() { int result = name.hashCode(); result = 17 * result + sex.hashCode(); result = 17 * result + age.hashCode(); return result; } // 重写equals方法 @Override public boolean equals(Object obj) { if(!(obj instanceof Student)) { // instanceof 已经处理了obj = null的情况 return false; } Student stuObj = (Student) obj; // 地址相等 if (this == stuObj) { return true; } // 如果两个对象姓名、年龄、性别相等,我们认为两个对象相等 if (stuObj.name.equals(this.name) && stuObj.sex.equals(this.sex) && stuObj.age.equals(this.age)) { return true; } else { return false; } } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public String getAge() { return age; } public void setAge(String age) { this.age = age; } public float getWeight() { return weight; } public void setWeight(float weight) { this.weight = weight; } public String getAddr() { return addr; } public void setAddr(String addr) { this.addr = addr; } }
现在我们写个例子测试下结果:
public static void main(String[] args) { Student s1 =new Student(); s1.setAddr("1111"); s1.setAge("20"); s1.setName("allan"); s1.setSex("male"); s1.setWeight(60f); Student s2 =new Student(); s2.setAddr("222"); s2.setAge("20"); s2.setName("allan"); s2.setSex("male"); s2.setWeight(70f); if(s1.equals(s2)) { System.out.println("s1==s2"); }else { System.out.println("s1 != s2"); }
}
在重写了student的equals方法后,这里会输出s1 == s2,实现了我们的需求,如果没有重写equals方法,那么上段代码必定输出s1!=s2。
通过上面的例子,你是不是会想,不是说要同时重写Object的equals方法和hashcode方法吗?那上面的例子怎么才只用到equals方法呢,hashcode方法没有体现出来,不要着急,我们往下看。
四。需要重写hashcode()的场景
以上面例子为基础,即student1和student2在重写equals方法后被认为是相等的。
在两个对象equals的情况下进行把他们分别放入Map和Set中
在上面的代码基础上追加如下代码:
Set set = new HashSet();
set.add(s1);
set.add(s2);
System.out.println(set);
如果没有重写Object的hashcode()方法(即去掉上面student类中hashcode方法块),这里会输出
[jianlejun.study.Student@7852e922, jianlejun.study.Student@4e25154f]
说明该Set容器类有2个元素。.........等等,为什么会有2个元素????刚才经过测试,s1不是已经等于s2了吗,那按照Set容器的特性会有一个去重操作,那为什么现在会有2个元素。这就涉及到Set的底层实现问题了,这里简单介绍下就是HashSet的底层是通过HashMap实现的,最终比较set容器内元素是否相等是通过比较对象的hashcode来判断的。现在你可以试试吧刚才注释掉的hashcode方法弄回去,然后重新运行,看是不是很神奇的就只输出一个元素了
@Override
public int hashCode() {
int result = name.hashCode();
result = 17 * result + sex.hashCode();
result = 17 * result + age.hashCode();
return result;
}
或许你会有一个疑问?hashcode里的代码该怎么理解?该如何写?其实有个相对固定的写法,先整理出你判断对象相等的属性,然后取一个尽可能小的正整数(尽可能小时怕最终得到的结果超出了整型int的取数范围),这里我取了17,(好像在JDK源码中哪里看过用的是17),然后计算17*属性的hashcode+其他属性的hashcode,重复步骤。
重写hashcode方法后输出的结果为:
[jianlejun.study.Student@43c2ce69]
同理,可以测试下放入HashMap中,key为<s1,s1>,<s2,s2>,Map也把两个同样的对象当成了不同的Key(Map的Key是不允许重复的,相同Key会覆盖)那么没有重写的情况下map中也会有2个元素,重写的情况会最后put进的元素会覆盖前面的value
Map m = new HashMap();
m.put(s1, s1);
m.put(s2, s2);
System.out.println(m);
System.out.println(((Student)m.get(s1)).getAddr());
输出结果:
{jianlejun.study.Student@43c2ce69=jianlejun.study.Student@43c2ce69}
222
s1 和 s2调用hsahCode 计算hashCode 值,相等
可以看到最终输出的地址信息为222,222是s2成员变量addr的值,很明天,s2已经替换了map中key为s1的value值,最终的结果是map<s1,s2>。即key为s1value为s2.
五。原理分析
因为我们没有重写父类(Object)的hashcode方法,Object的hashcode方法会根据两个对象的地址生成对相应的hashcode;
s1和s2是分别new出来的,那么他们的地址肯定是不一样的,自然hashcode值也会不一样。
Set区别对象是不是唯一的标准是,两个对象hashcode是不是一样,再判定两个对象是否equals;
Map 是先根据Key值的hashcode分配和获取对象保存数组下标的,然后再根据equals区分唯一值(详见下面的map分析)
六。补充HashMap知识
hashMap组成结构:hashMap是由数组和链表组成;
hashMap的存储:一个对象存储到hashMap中的位置是由其key 的hashcode值决定的;查hashMap查找key: 找key的时候hashMap会先根据key值的hashcode经过取余算法定位其所在数组的位置,再根据key的equals方法匹配相同key值获取对应相应的对象;
案例:
(1)hashmap存储
存值规则:把Key的hashCode 与HashMap的容量 取余得出该Key存储在数组所在位置的下标(源码定位Key存储在数组的哪个位置是以hashCode & (HashMap容量-1)算法得出)这里为方便理解使用此方式;
//为了演示方便定义一个容量大小为3的hashMap(其默认为16)
HashMap map=newHashMap(3);
map.put("a",1); 得到key 为“a” 的hashcode 值为97然后根据 该值和hashMap 容量取余97%3得到存储位到数组下标为1;
map.put("b",2); 得到key 为“b” 的hashcode 值为98,98%3到存储位到数组下标为2;
map.put("c",3); 得到key 为“c” 的hashcode 值为99,99%3到存储位到数组下标为0;
map.put("d",4); 得到key 为“d” 的hashcode 值为100,100%3到存储位到数组下标为1;
map.put("e",5); 得到key 为“e” 的hashcode 值为101,101%3到存储位到数组下标为2;
map.put("f",6); 得到key 为“f” 的hashcode 值为102,102%3到存储位到数组下标为0;
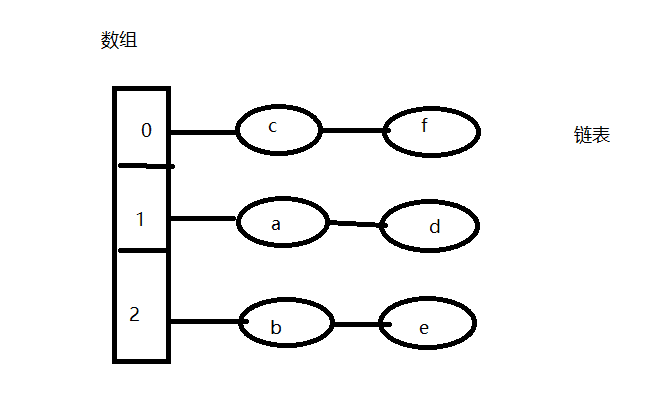
(2)hashmap的查找key
得到key在数组中的位置:根据上图,当我们获取key 为“a”的对象时,那么我们首先获得 key的hashcode97%3得到存储位到数组下标为1;
匹配得到对应key值对象:得到数组下表为1的数据“a”和“c”对象, 然后再根据 key.equals()来匹配获取对应key的数据对象;
hashcode 对于HashMapde:如果没有hashcode 就意味着HashMap存储的时候是没有规律可寻的,那么每当我们map.get()方法的时候,就要把map里面的对象一一拿出来进行equals匹配,这样效率是不是会超级慢;
5、hashcode方法文档说明
在equals方法没被修改的前提下,多次调用同一对象的hashcode方法返回的值必须是相同的整数;
如果两个对象互相equals,那么这两个对象的hashcode值必须相等;
为不同对象生成不同的hashcode可以提升哈希表的性能;
————————————————
版权声明:本文为CSDN博主「简乐君」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012557538/article/details/89861552
总结:
我们先来看一下Object.hashCode的通用约定(摘自《Effective Java》第45页)
1
在一个应用程序执行期间,如果一个对象的equals方法做比较所用到的信息没有被修改的话,那么,对该对象调用hashCode方法多次,它必须始终如一地返回 同一个整数。在同一个应用程序的多次执行过程中,这个整数可以不同,即这个应用程序这次执行返回的整数与下一次执行返回的整数可以不一致。
如果两个对象根据equals(Object)方法是相等的,那么调用这两个对象中任一个对象的hashCode方法必须产生同样的整数结果。
如果两个对象根据equals(Object)方法是不相等的,那么调用这两个对象中任一个对象的hashCode方法,不要求必须产生不同的整数结果。然而,程序员应该意识到这样的事实,对于不相等的对象产生截然不同的整数结果,有可能提高散列表(hash table)的性能。
如果只重写了equals方法而没有重写hashCode方法的话,则会违反约定的第二条:相等的对象必须具有相等的散列码(hashCode) 同时对于HashSet和HashMap这些基于散列值(hash)实现的类。HashMap的底层处理机制是以数组的方法保存放入的数据的(Node<K,V>[] table),其中的关键是数组下标的处理 数组的下标是根据传入的元素hashCode方法的返回值再和特定的值异或决定的。如果该数组位置上已经有放入的值了,且传入的键值相等则不处理,若不相等则覆盖原来的值,如果数组位置没有条目,则插入,并加入到相应的链表中。检查键是否存在也是根据hashCode值来确定的。所以如果不重写hashCode的话可能导致HashSet、HashMap不能正常的运作。
如果我们将某个自定义对象存到HashMap或者HashSet及其类似实现类中的时候,如果该对象的属性参与了hashCode的计算,那么就不能修改该对象参数hashCode计算的属性了有可能会移除不了元素,导致内存泄漏。
重写了equals方法必须重写hashCode方法的原因:
本质原因是我们要用 hashMap 这种数据结构,一是违反约定的第二条:相等的对象必须具有相等的散列码(hashCode)
二是,如果两个对象我们定义上相同(姓名,年龄,性别),如果不重写,根据obj 地址不同,但是计算出来的hashCode 不同
也就影响了hashMap 设计的原理,就没有效率了,, 为什么hashMap 快呢,因为数组,链表,红黑树,分成一块一块,效率高
so 算法效率的本质就是归类;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号