java 基础知识(三)
Arraylist与Vector的区别
这几天工作有点忙,有很多代码需要写,更新文章有点慢,说声抱歉,前几天有人反馈LinkedList的文章不太看得懂,临时准备补两篇文章。
前几篇文章我们重点说了ArrayLIst,是时候放出这张图了。
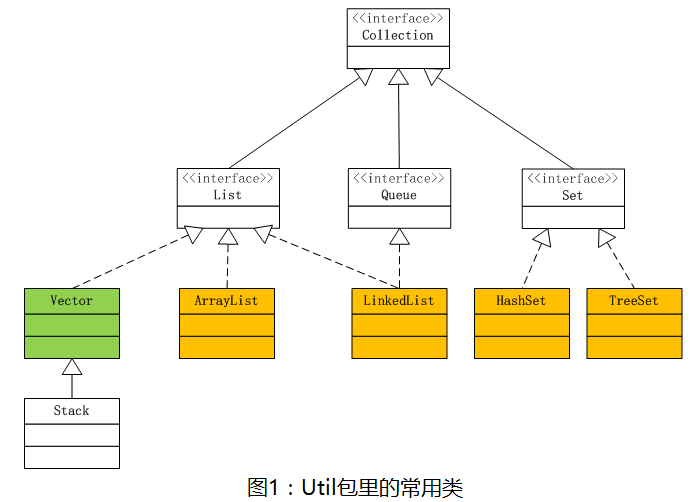
这张图里的内容对我们学习Java来说,非常的重要,白色的部分是需要去了解的,黄色部分是我们要去重点了解的,不但要知道怎么去用,至少还需要读一次源码。绿色部分内容已经很少用了,但在面试题中有可能会问到,我们来看一个经常出现的面试题:Arraylist与Vector的区别是什么?
首先我们给出标准答案:
1、Vector是线程安全的,ArrayList不是线程安全的。
2、ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
看上图Vector和ArrayList一样,都继承自List,来看一下Vector的源码

实现了List接口,底层和ArrayList一样,都是数组来实现的。分别看一下这两个类的add方法,首先来看ArrayList的add源码

再看Vector的add源码

方法实现都一样,就是加了一个synchronized的关键字,再来看看其它方法,先看ArrayList的remove方法

再看Vector的remove方法

方法实现上也一样,就是多了一个synchronized关键字,再看看ArrayList的get方法

Vector的get方法

再看看Vector的其它方法
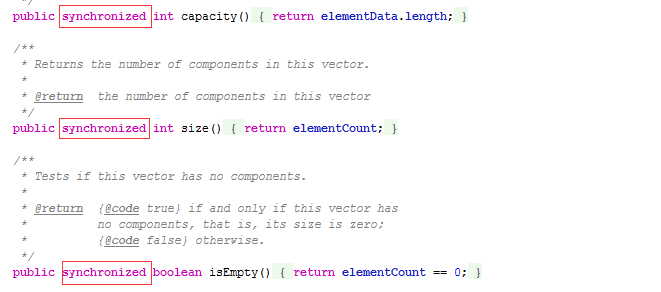
无一例外,只要是关键性的操作,方法前面都加了synchronized关键字,来保证线程的安全性。当执行synchronized修饰的方法前,系统会对该方法加一把锁,方法执行完成后释放锁,加锁和释放锁的这个过程,在系统中是有开销的,因此,在单线程的环境中,Vector效率要差很多。(多线程环境不允许用ArrayList,需要做处理)。
至于底层数组的扩容区别,这里就不带着大家读源码了,有兴趣的朋友大家自己读吧,底层代码几乎是一样的,不同的只是计算后的新数组长度不一致。
和ArrayList和Vector一样,同样的类似关系的类还有HashMap和HashTable,StringBuilder和StringBuffer,后者是前者线程安全版本的实现。希望以后大家在面试过程中,能说出个因为所以,而不是一味的去背面试题,唯有理解,无需再背。
注:关于线程安全性,后续文章会说,这里只是简单说这两个类不一样的地方。
Java数据结构之线性表
这篇文章我们来说说Java里一个很重要的数据结构——线性表,还是这张图,线性表对应着下图里的List。
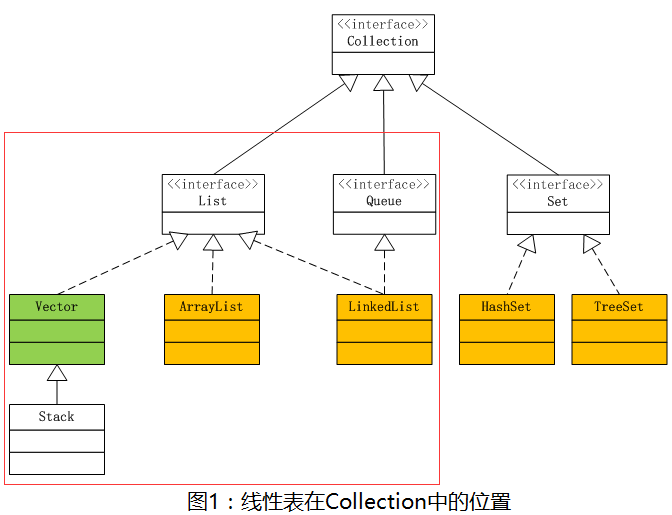
红框里的内容就是线性表的大家族了,其中黄色部分是要重点了解的,线性表里的元素是按线性排列的(这里的线性指逻辑上的) 线性表分为两大类,分别是顺序表和链表:
一、顺序表
顺序表中的数据元素存储是连续的,内存划分的区域也是连续的。存储结构如下图:
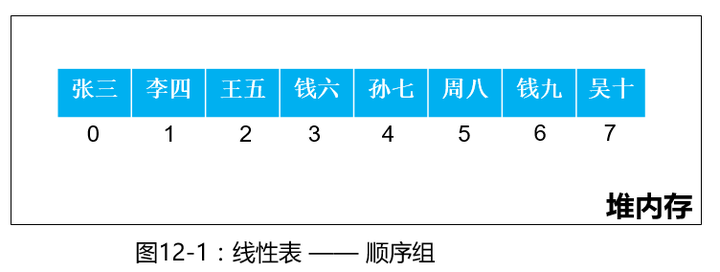
我们的ArrayList底层是数组实现的,底层元素在内存中是按顺序排列的,ArrayList是Java中顺序表的体现。
二、链表
链表在物理存储上通常是非连续、非顺序的方式存储的,数据元素的逻辑顺序是通过链表中的引用来实现的。
1、单向链表
很简单,内存中的对象是随机分布的,对象不但存储了张三、李四等数据,还持有一个next引用,指向下一个对象,来确定一组对象的逻辑顺序。
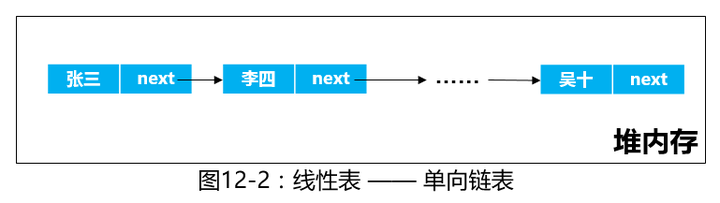
2、循环链表
也很简单,和单向链表一样,只不过最后一个对象的next又指向了第一个对象。
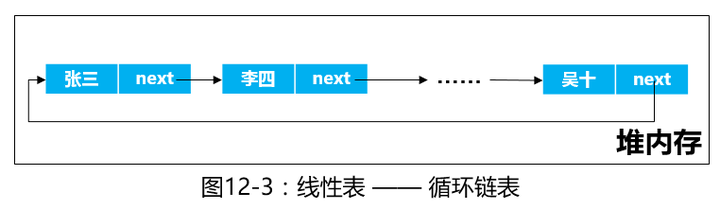
3、双向链表
不但持有next引用,指向下一个对象,还持有一个prev引用,指向上一个对象。
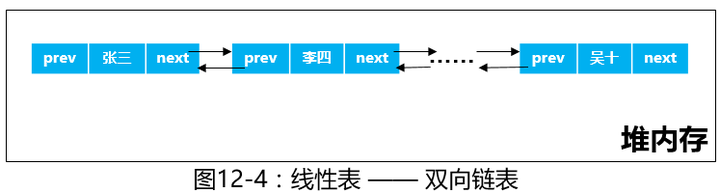
记住双向链表这个图,很重要,下一篇文章我们要讲的LinkedList就是以双向链表的方式实现的。
三、栈和队列
栈和队列是两种比较特殊的线性表。
1、栈
栈是一种操作受限制的线性表。其限制是仅允许在线性表的尾部进行添加和删除操作,这一端被称为栈顶,另一端称为栈底。向一个栈添加新元素叫压栈,删除元素又称为出栈。
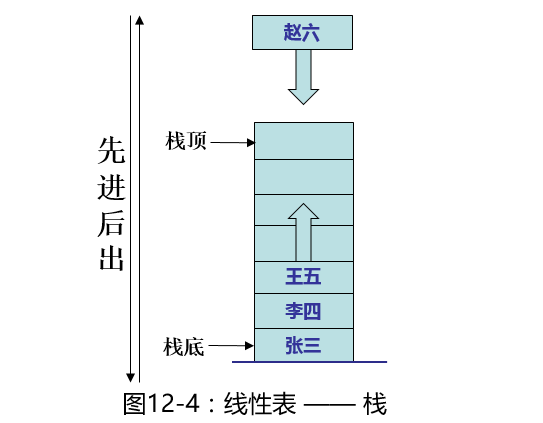
如上图,把赵六放入到栈中叫压栈,不放入赵六,直接取出(删除)王五的过程叫出栈,只能从栈顶放入和删除元素。本文第一张图里的Stack就是栈在Java中的实现。举个例子,最后洗好的盘子都是叠放在最上面的,但每次用的时候都是从最上面拿,最先洗好的盘子反而不容易用到。
2、队列
队列也是一种操作受限制的线性表。只能从头部删除(取出)元素,从队尾添加元素,进行删除操作的端称为队头。
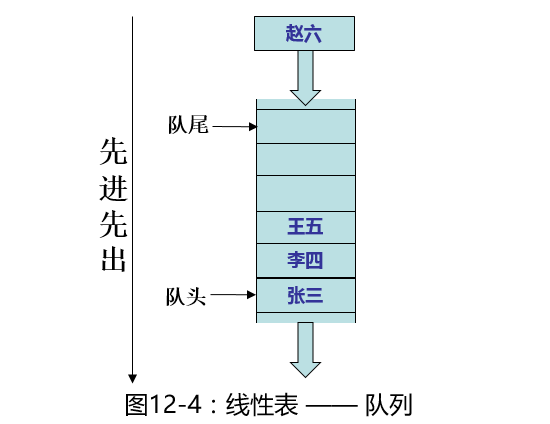
看上面的图,只能从队尾添加元素,队头取出(删除)元素。本文第一张图里的Queue就是队列的体现,Queue是基于链表来体现的。注意,Queue是一个接口,直接写如下代码是会报错的
Queue queue = new Queue();//会报错,Queue是接口,不允许实例化正确的用法是
Queue queue = new LinkedList();// 正确的用法,基于链表来实现队列的链表实现是通过子类LinkedList来实现的,Queue接口收窄了LinkedList的访问权限,只提供从队尾,队头等的操作。
为了加深大家的印象,我举一个例子,恶心了一点,但保证大家能记住,大家在喝啤酒的过程中,正常去厕所小解的,这个过程叫做队例。喝多了吐出来的过程,叫做栈。
以上就是Java线性表的介绍,面试中会经常被问起,后续文章会把重点都说一下,希望对大家能有所帮助。
LinkedList初探
在前面的文章里,我们讲了数组和ArrayList,在现实中,不管什么系统,如果不考虑性能的话,用其中的一个就可以完成所有工作,那为什么不用它们来进行所有的数据存储呢?
在数组/ArrayList中读取和存储(get/set)的性能非常高,为O(1),但插入(add(int index, E element))和删除(remove(int index))却花费了O(N)时间,效率并不高。
今天我们来看Java中的另一种List即LinkedList,LinkedList是基于双向链表来实现的,关于链表的知识我们Java数据结构之线性表 - 知乎专栏一文中有过介绍,HashMap和链表也有关系,所以我们要先讲它,话不多说,上代码。
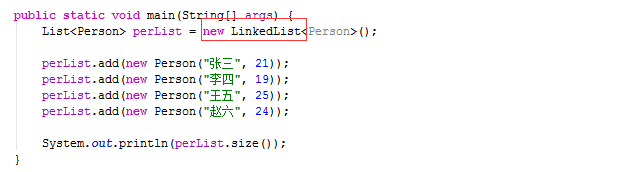
这段代码和我们之前的往ArrayList添加元素的代码基本上是一模一样的,只是修改了红框的内容为LinkedList,这时候再往里添加元素,调用的就是LinkedList里面的add方法了。在之前的 面向对象 一文中我们已经说过了,这是多态的体现,利用好多态,在编码过程中,我们可以少修改很多东西,忘记了的朋友可以回过头去看一下。一看到new这个关键字,我们脑海里应该是,这货在堆内存中开辟了一块空间,我们先从构造函数入手吧。

满怀希望的打开构造函数,好伤心,里面没有任何逻辑,只能从成员变量入手。

发现三个成员变量,size就不多说了,大家猜一下就知道是LinkedList的逻辑长度,初始化为0,并持有两个Node引用,first看名字一猜就是第一个,last看名字就是最后一个,我们先来画一画

初始化完了,在堆内存中就是这个样子,size为0。引用类型的成员变量初始化为null,再来看一看这个Node是什么东东
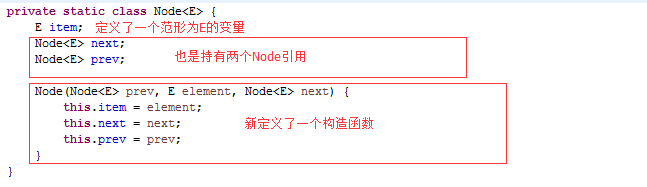
这是一个内部静态私有类,该类只能在LinkedList中访问,先记住它,debug看一下

和我们图中一致,我们继续执行码里的add方法,看源码

很普通,e是我们往里添加的Person对象“张三”,继续跟踪linkLast方法:
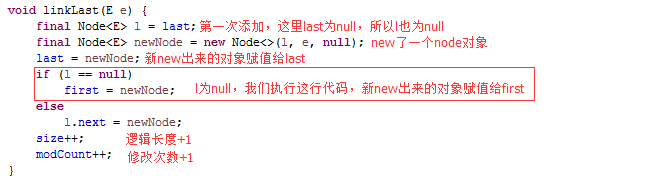
第一次往LinkedList里添加元素,我们看上图11-1就知道,first为null,last也为null,把我们的Person对象“张三”传给了Node的构造函数,再看Node的构造函数:
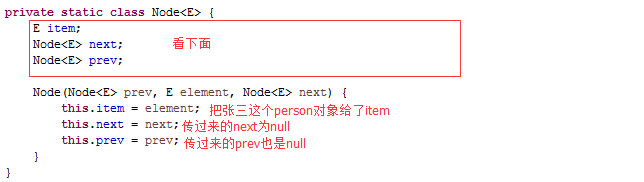
用Person张三为入参构造了一个Node对象,好了,又到了画图的时候
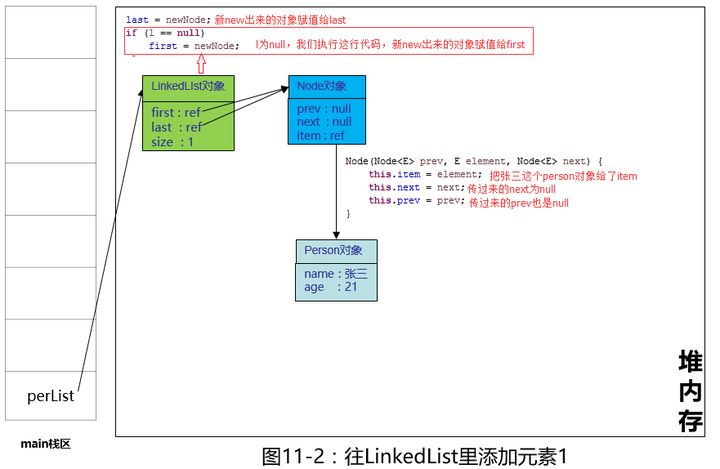
老规矩,debug一下:
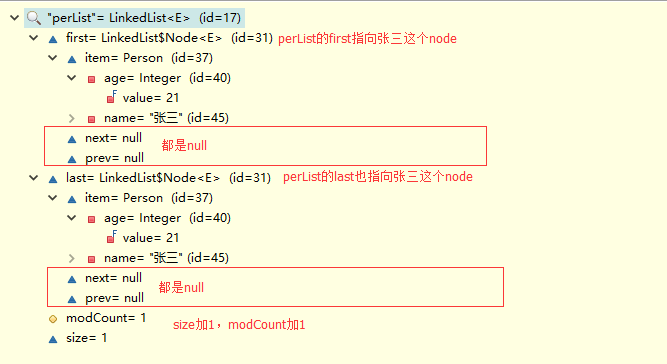
和我们图中所画的一致,我们继续添加“李四”这个Person对象,再打开源码分析一下。
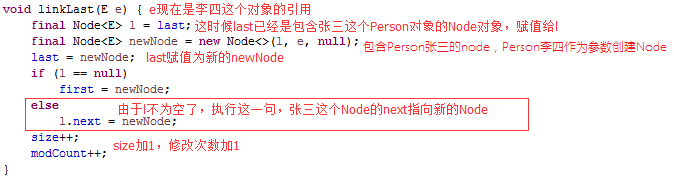
张三这个Node指向新new出来的Node对象,再看Node是怎么创建的

创建Node对象,新new出来的Node对象的prev引用指向包含Person张三的Node对象。item引用指向Person李四对象,继续画图:
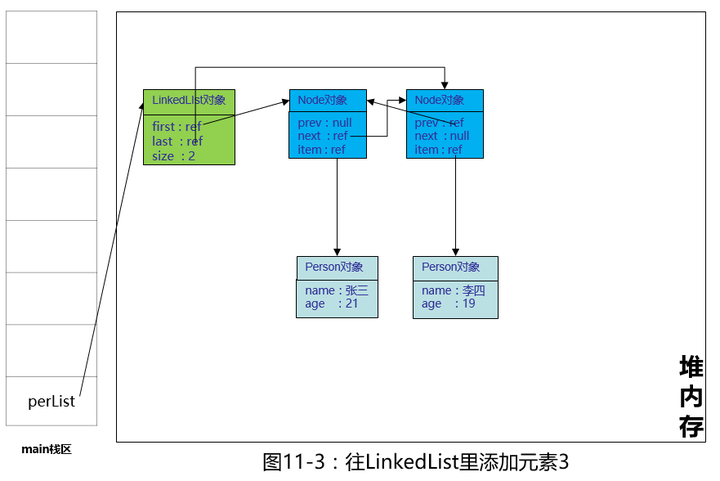
看上图,原来的next引用指向新new出来的Node,同时新new出来的Node的prev引用指向原来的Node对象,item指向新new出来的Person李四这个对象,同时perList这个LinkedList对象的last引用指向新new出来的这个Node,再debug看一下

好的,继续添加“王五”,“赵六”
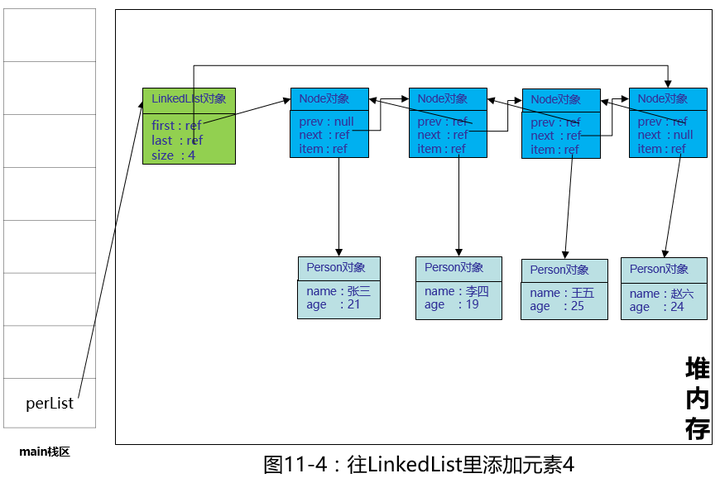
很简单,没有了底层数组,新增加了一个Node对象,记录了Person的内容,每个Node对象都持有next引用(下一个)和prev引用(上一个),其实就是之前 Java数据结构之线性表 - 知乎专栏 一文里介绍的双向链表,这个图看起来有点乱,多年前我在读这段代码的时候,差点晕过去了,又是next,prew,first,last,容易乱,因此大家在学习源码的过程中,有不明白的地方,找张纸和笔画一画,就清晰了。放张简化版的图,方便大家理解。
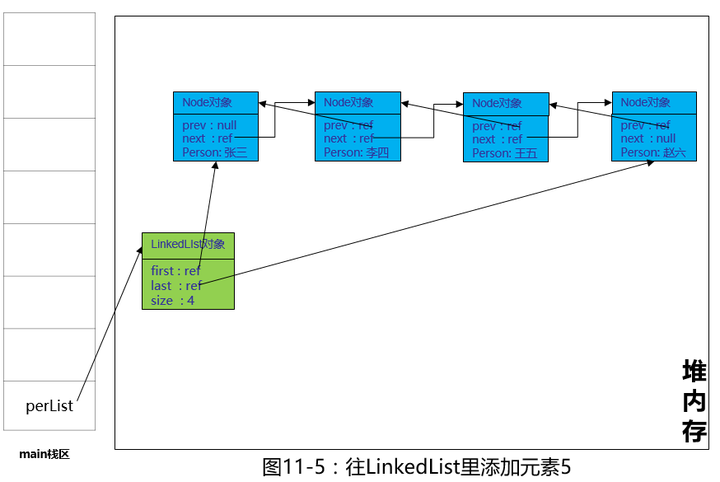
夜深了,先休息了,大家有什么看不明白的地方,可以在评论区留言,本文在写作过程中如果有什么勘误,还希望细心的读者提出来,下一篇我们研究LinkedList的查找、插入与删除,并引入时间复杂度来分析。
LinkedList元素的删除原理
上一篇文章我们说了LinkedList,并说了往里添加了元素。这篇文章我们来说说LinkedList元素的删除,话不多说,上代码,还是那个Person类
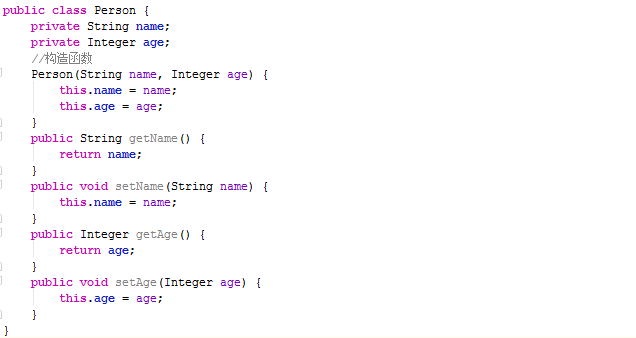
还是那两个属性,name,age,提供了一些简单的get与set方法。写我们的main方法
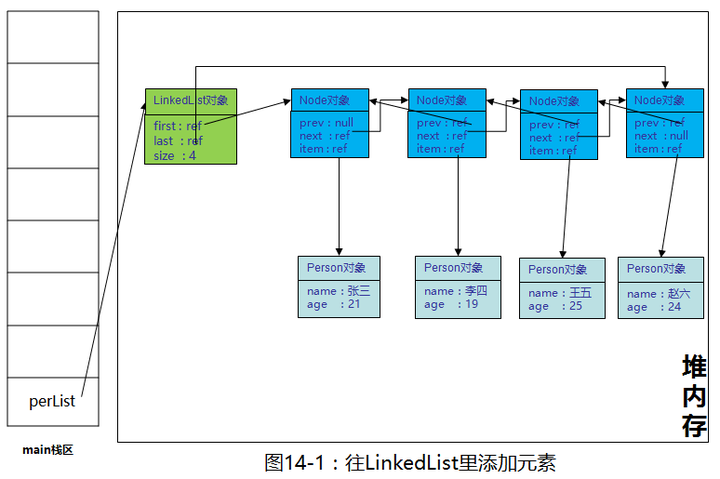
和前文一样,new了一个LinkedList,并往里添加了四个元素,看过前文的朋友都知道现在LinkedList目前在堆内存中的样子如下图:
现在我们来删除王五这个用户,运行一下
看一下结果

好奇怪,打印返回的删除状态居然是false,代码中明明删掉王五了,为什么打印的结果还是4?如果经常看本专栏文章的人,大概已经猜到了原因,这个王五是新new出来的,并不是perList里的王五,Person这个类没有重写equals方法,删除元素依赖于equals方法,到底是不是呢,我们来看一下源码:
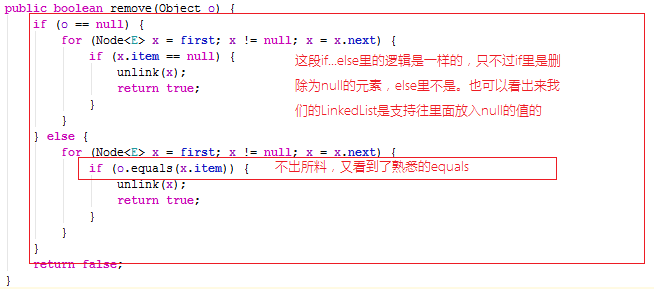
不出所料,又看到了熟悉的equals,真是无处不在,这段代码其实是从第一个Node节点(first节点)开始对比item的值,如果equals成功就执行unlink()方法,并返回删除成功的布尔值true。我们画一画查找王五的这个过程。
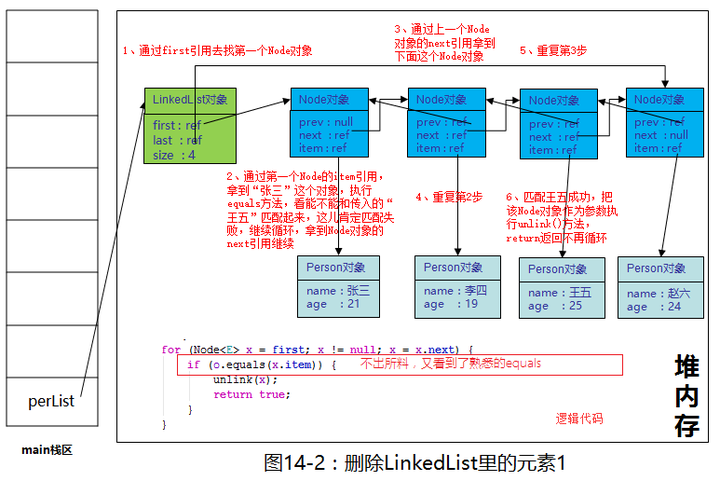
大致就是这个样子,就大家仔细看图里的文字描述,现在我们来看看unlink()方法都做了啥

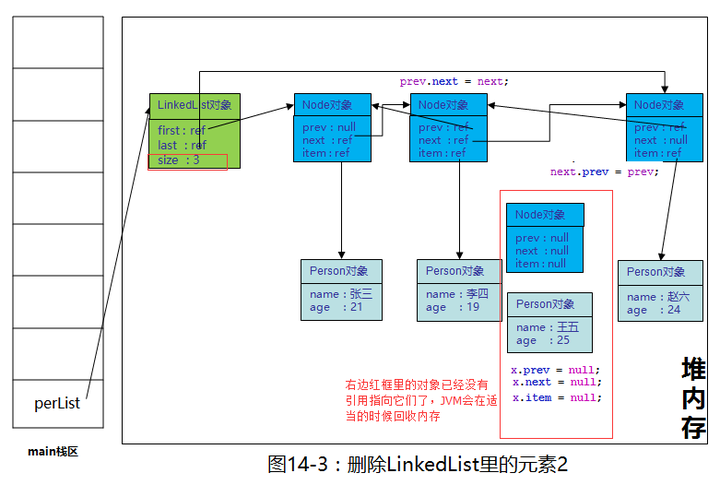
注意,在本示例中,上图的黑色字体注释部分不会执行。好吧,我承认,多年前我看这段代码被绕晕了,prev.next,next.prev都是些什么鬼啊!苍天啊!大地啊!
别怕,上面代码看似烧脑但是逻辑相当简单,就是把包含王五的这个Node从双向链表中移出来,然后把王五相邻的两个Node的next和prev重新指向一下,我们画一下图:
简单吧,debug一下看是不是和图中画的一致,测试代码前别忘了在Person里重写equals方法

debug看一下,已经删除了王五,size也更新成了3。
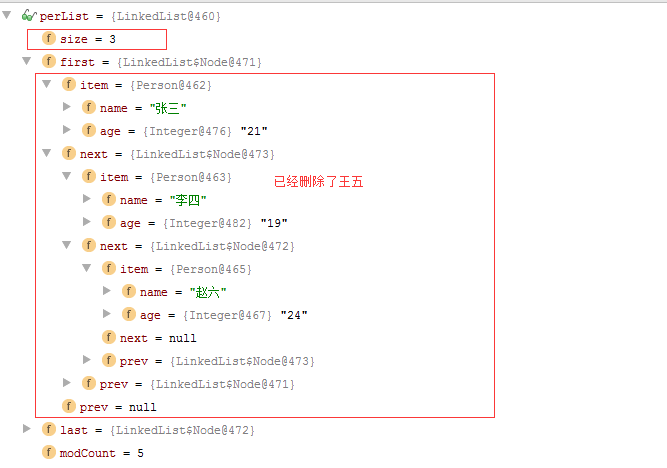
打印结果也和期待中一样,打印删除状态也为true了。

说到这儿,我们再来看一下ArrayList以对象方式删除元素的源码,来和LinkedList比较一下

再看fastRemove()方法
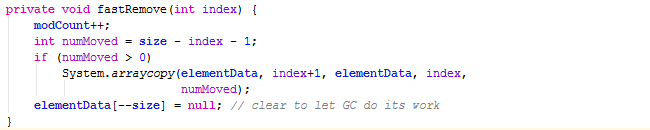
大体上一致,两者都在元素中循环查找,LinkedList是把Node(包含Person)从链表的移出(通过修改上下节点的引用来实现),ArrayList删除底层数组元素后又把底层数组都往前复制了一格内容(忘记了的朋友可以复习一下,传送门:ArrayList的元素删除),现在我们来比较一下这两者间的时间复杂度。
假设要删除的元素都在这两个List中的第n位置,由于两者都循环查找了n次,省略循环查找这个步骤,说以我们直接看删除,前面的一系列文章中我们已经讲过了,由于ArrayList删除元素后,底层数组要往前复制一格,ArrayList底层数组删除元素时间复杂度为O(n)。再来看LinkedList,LinkedList底层链表删除元素只是简单的修改了一下引用地址,时间复杂度为O(1)。
由以上推断看来,LinkedList的删除效率似乎要好很多,实际真的如此吗?答案是不一定。下一篇文章我们将写一段代码来分析一下,LinkedList和ArrayList在删除元素时的真实效率。
以上我们说的删除用的是List的如下API
public boolean remove(Object o);LinkedList还有一种删除方式,用下标方式删除,如下
public E remove(int index);下一篇文章一起讲解。
注:示例中,用对象的方式来删除元素,只是想告诉大家,这种删除方式是用equals方法来查找元素进而删除的,实际工作中很少遇到需要new一个对象去删除的情况。不建议一上来就重写equals方法,除非你有特殊的需求。如果重写了equals方法,请一并重写hashCode方法,这个问题在说说Java里的equals(中)一文中已经说过了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号