java基础知识(二)
ArrayList初始化
ArrayList部分一共五篇文章了,并且引入了时间复杂度来分析,强烈建议大家一定要按顺序阅读,相关文章分别是:
前些天的文章,反复的画图,不停的重复,就是想让大家理解,对象在内存中是什么样的。也是为今天的及以后的讲解打下基础。如果要说大家在写Java代码的时候哪个类用得最多,我想除了String,基本上就是ArrayList了吧,那今天我们说说ArrayList。
首先ArrayList是一个普通的类,我们来看一段代码:

首先:执行List<Person> list1 = new ArrayList<>();当看到new这个关键字的时候,我们脑袋里应该第一印象就是这货在堆内存开辟了一块空间,好我们再来画一画。

注:常量池位于方法区,方法区位于堆内存,前面没涉及到,所以没画方法区,现在补上
好,既然是new出来的,那我们直接从构造函数入手,看一下构造函数做了什么。

很简单,就一行代码,继续看一下,this.elementData和DEFAULTCAPACITY_EMPTY_ELEMENTDATA分别是什么

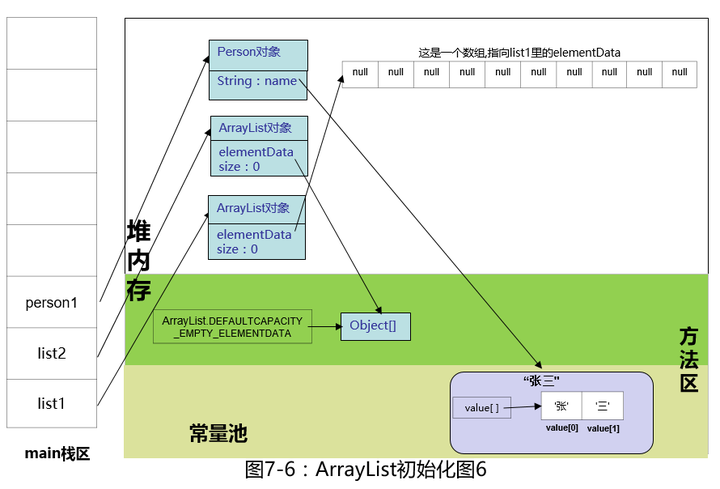
红框里的内容是不是似曾相识?是的,和String一样,底层是数组,唯一的区别是String底层是char[]数组(忘了的可以复习一下,传送门:String是一个很普通的类 - 知乎专栏),而这儿是Object[]数组,也就是说该数组可以放任何对象(所有对象都继承自父类Object),执行完构造函数后,如下图。
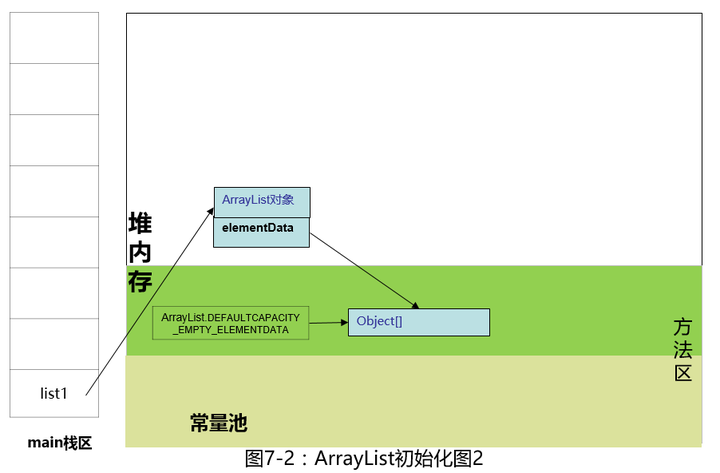
注:static修饰的变量,常驻于方法区,我们不需要new,JVM会提前给我们初始化好,这个特性在实际开发过程中,经常拿来做缓存。在让人疑惑的Java代码 - 知乎专栏 一文中,我们文中Integer的缓存就是最好的例子。static变量又叫类变量,不管该类有多少个对象,static的变量只有一份,独一无二。
fianl修饰的变量,JVM也会提前给我们初始化好。
transient这个关键字告诉我们该对象在序列化的时候请忽略这个元素,后续我们会讲序列化,这儿先跳过。
继续执行:List<Person> list2 = new ArrayList<>();
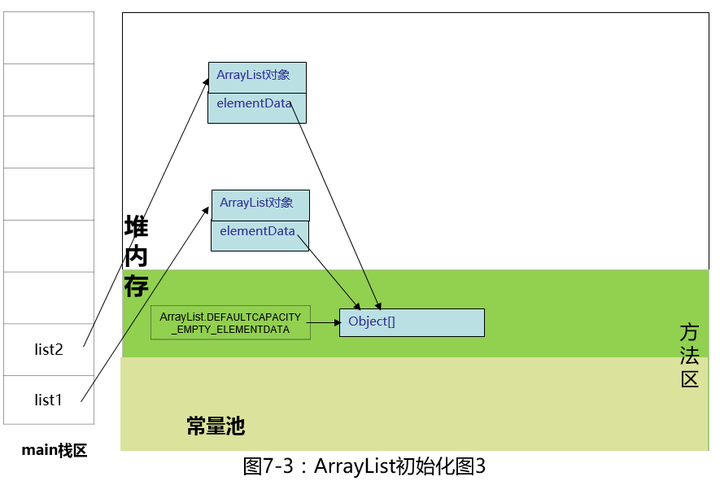
ArrayList这个类的作者真是好贴心,new的时候连缓存都考虑到了,为了避免我们反复的创建无用数组,所有新new出来的ArrayList底层数组都指向缓存在方法区里的Object[]数组。
继续执行Person person1 = new Person("张三")
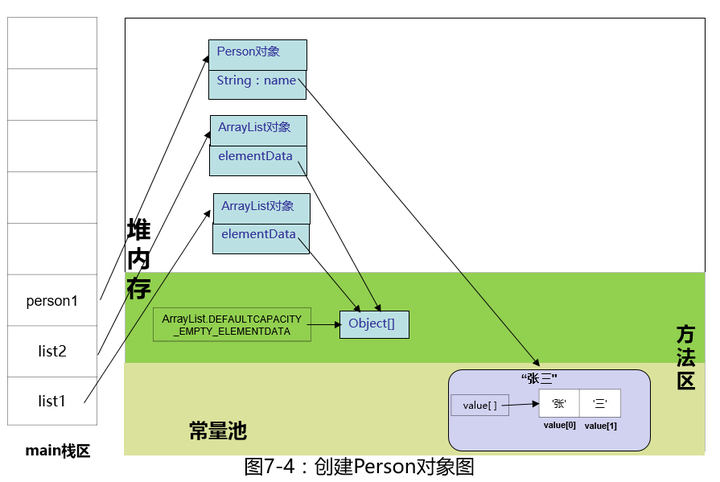
继续,执行list1.add(person1),不多说,看源码ArrayList是怎么处理add的。

我们先看ensureCapacityInternal方法,方法里有个参数是size,看们先看一下这个size从哪来的。

原来是一个成员变量,相信大家看到size一猜就知道大概是干嘛的了吧。好,我们在图里的ArrayList对象里补上它,size是int基本数据类型,成员变量初始化的为0。
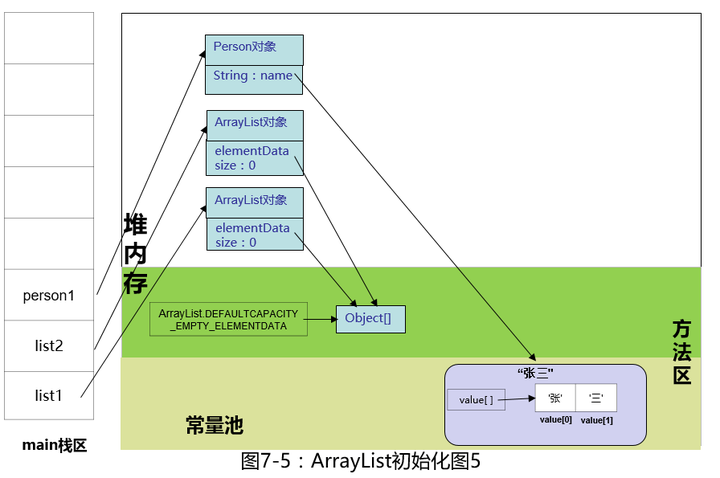
继续往下看
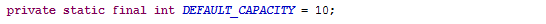
ensureCapacityInternal方法是在add里面调用的。

再看grow方法
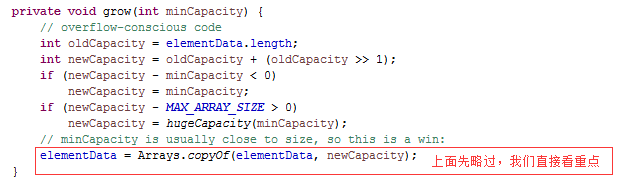
跟进到Arrays这个工具类,很简单

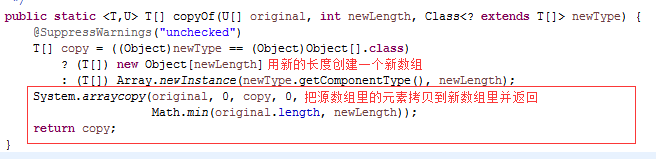
再看copyOf()方法
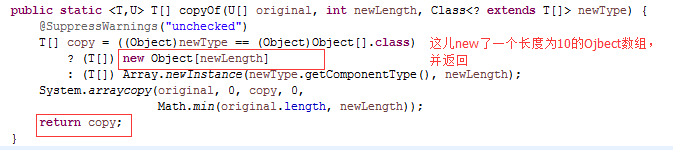
最后我们来看一下System.arraycopy()方法,好奇怪,这个方法只有定义,却没有实现,方法用了一个native来修饰。native的方法,是由其它语言来实现的,一般是(C或C++),所以这儿没有实现代码。这是一个数组拷贝方法,大家还在写for循环拷贝数组吗?以后多用这个方法吧,简单又方便还能获得得更好的性能。

注:native方法,我们会后续会讲解,我们先关注本章内容。
由于数组内容目前为空,相当于没有拷贝。折腾了这么久,原来只是为了创建一个默认长度为10的Object[]数组,有些朋友说,直接new不就行了,这么费劲,其实这里面大有文章,别急,稍后会说,继续画图。
再回过头来看,add()这个方法,继续往下执行:

很简单,size现在是0,就是把传进来的这个e(这里是person1),放到list1的elementData[]下标为0的数组里面,同时size加1,老规矩,上图。
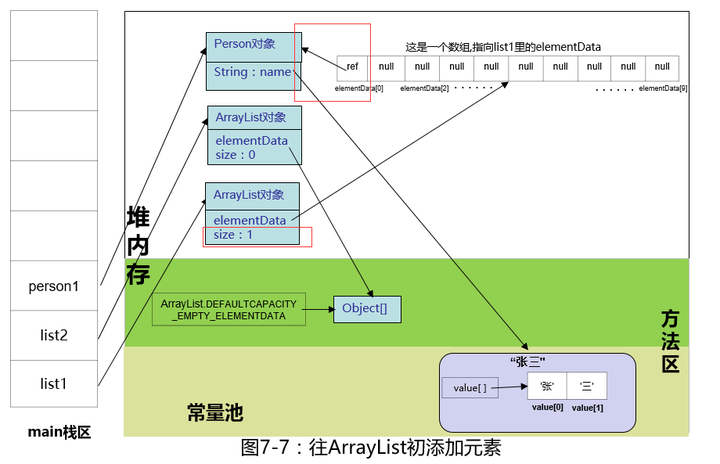
注意看红框里,虽然我们list1里的elementData数组的长度是10,但是size是1,size是逻辑长度,并不是数组长度。
现在debug一下,验证我们图里的内容:
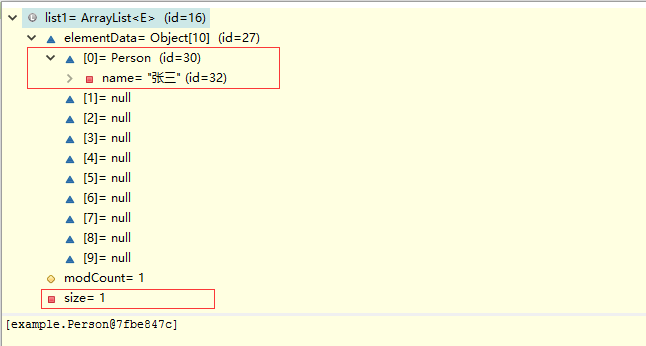
好的,执行一下本文开始那段代码,看结果:

顺便看一看size()方法的源码:

有人说,呀,就一个元素,在堆内存中占了10个位置,好浪费呀,没办法,你要享受ArrayList的便利与丰富的API,就得牺牲一下空间作为代价。
如果喜欢本系列文章,请为我点赞或顺手分享,您的支持是我继续下去的动力,您也可以在评论区留言想了解的内容,有机会本专栏会做讲解,最后别忘了关注一下我。
ArrayList底层数组扩容原理
ArrayList部分一共五篇文章了,并且引入了时间复杂度来分析,强烈建议大家一定要按顺序阅读,相关文章分别是:
再次强调,ArrayList是一个普通的类,如果我们开心,可以自己写一个。
ArrayList初探 - 知乎专栏 文章发表后,评论区有人问如下问题。

我们先回顾一下之前的所说过的数组,话不多说,上代码:
老规则,我们继续画一画,加深一下印象,上图:
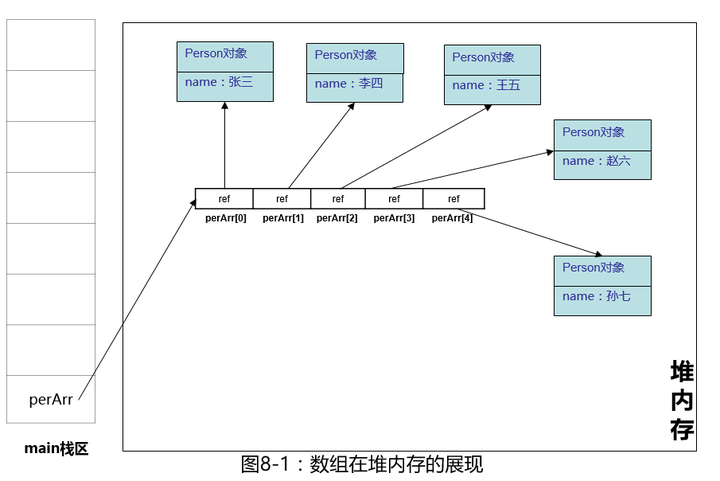
这个图我们去掉了ArrayList初探 - 知乎专栏 一文图里那些无用的细节(方法区,常量池等),方便大家看起来清晰,我们用eclipse的debug功能看一下,看是否与我们图上画的一致

再看一下执行结果,也在我们期望中。

好,我们改一下代码,再往数组里加添加一个叫“周八”的person对象

执行一下

看到了传说的中数组下标越界异常。在Java中,数组一但在堆内存中创建,长度是固定的。
既然是固定的,那我们要往数组里加一个“周八”用户怎么办?没办法,只能重新new长一点的新的数组,把原来数组的元素复制过去,好吧,开始写代码吧,相信大家都会写

把老数组的元素循环一下,赋值给新的数组,很简单也很清晰。debug看一下

“周八”已经有了。以上代码虽然简单,但还不是最优雅的,老鸟一般会这么写,该段代码执行结果和上面那段代码一样。

再画个图加深一下印象吧:
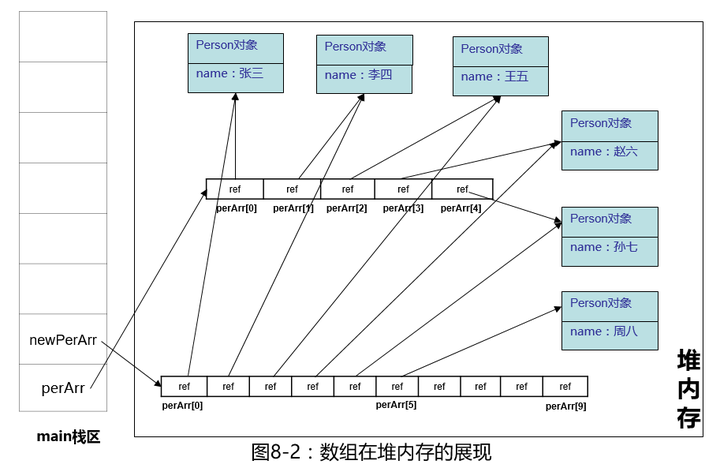
此图已用尽我洪荒之力,希望大家以后多想想对象在堆内存中的样子。不枉我一片苦心呀。
看到System.arraycopy()方法是不是似曾相识呢?我们在ArrayList初探 - 知乎专栏 一文中提了一下,相信看到这里,大家都知道ArrayList里的底层数组扩容是怎么实现的了吧。在ArrayList初探 - 知乎专栏 一文中,我们知道当ArrayList如果不指定构造个数的话,第一次往里面添加元素时底层数组会初始化一个长度为10的数组,我们再回顾一下昨天的源码,再来看一下ArrayList里的源码,当添加第11个元素时

再看grow()方法

这儿有一段代码:int newCapacity = oldCapacity + (oldCapacity >> 1),>>是移位运算符,相当于int newCapacity = oldCapacity + (oldCapacity/2),但性能会好一些。
本文开始那个问题,到这儿就解决了,这就是数组的扩容,一般是oldCapacity + (oldCapacity >> 1),相当于扩容1.5倍。
看到这里,相信在以后的面试中,面试官再问数组和ArrayLIst的区别的时候,大家应该有了自己的理解,而不是去背面试题了。
ArrayList还提供了其它构造方法,我们顺便来看一下。

我们再看一下源码,好简单:

当我们在写代码过程中,如果我们大概知道元素的个数,比如一个班级大概有40-50人,我们优先考虑List<Person> list2 = new ArrayList<>(50)以指定个数的方式去构造,这样可以避免底层数组的多次拷贝,进而提高程序性能。
如果喜欢本系列文章,请为我点赞或顺手分享,您的支持是我继续下去的动力,您也可以在评论区留言想了解的内容,有机会本专栏会做讲解,最后别忘了关注一下我。
时间复杂度
ArrayList部分一共五篇文章了,并且引入了时间复杂度来分析,强烈建议大家一定要按顺序阅读,相关文章分别是:
最近看了一下评论区里,大家都急着想要了解HashMap,先不要着急,要完整的了解HashMap的内部实现,我们还需要一些基础知识,有了这些基础知识,我们才能更好的理解HashMap,其实我们已经在不知不觉进入了数据结构的大门,为了以后让大家能更好的理解后续文章,本文我们先引入时间复杂度这个概念。

还是那个Person对象,增加了一个属性年龄

创建一个数组,并在数组里放了10个Person对象,老规矩,我们上图:
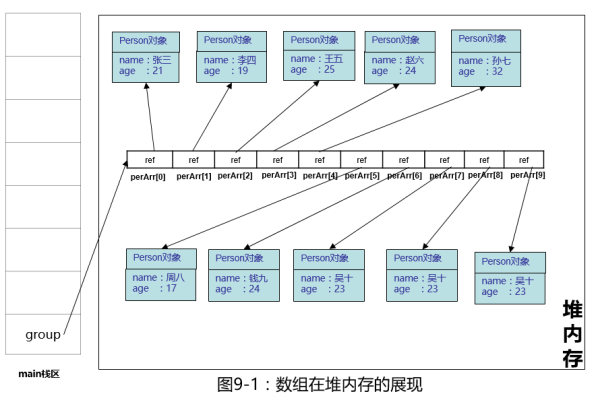
假如我们有这么一个需求,我们想知道小组里周八的年龄,相信大家都会写代码去找:

需要循环取6次从数组里获取Person对象。
这时候小明同学过来说,哎呀,我知道周八在小组的第5个位置(数组下标5),不用循环,我们直接找他就是

不需要循环,1次就取到了Person对象:

无论数组中有多少个元素,每次去读取元素和并比较的时间总是相同的,假设这个时间为K,在上面示例中在数组中循环搜索某个用户,我们循环了6次才搜索到该用户,时间为6*K,在效率上来看,前者比后者的方式快了6倍,但这种说法意义不大,因为在实际中,数组可能有100个元素,而这个“周八”有可能在数组的第1个位置,也有可能在最后一个位置。
在现实中,我们用来计算时间的长短,一般单位有小时,分钟,秒等,同样我们也需要一种度量来计算本示例中的算法的效率,在计算机科学中,这种度量方法被称为“大O”表示法。
当我们知道元素的位置,一步到位就能访问到该元素,这个时间为K,时间复杂度用大O表示法标记为O(1),省略了K。而在数组中查找某元素,我们并不知道这个元素在数组的什么位置,假设数组的长度为n,有可能该元素刚好在数组的下标为0的位置(第一个位置)循环1次就匹配到了,时间复杂度为O(1)。也有可能在数组下标为n-1的位置(最后一个位置)我们要循环n次才能匹配到该值,时间复杂度为O(n),按照概率计算下来平均是n/2,即平均时间复杂度为O(n/2),但我们不应该只考虑平均值,我们要考虑最坏的情况,即假设每次匹配的元素都在数组的最后一位,因为最坏情况是一种运行时间保证,运行时间不会再长了,如果我们没特别指定,我们提到的运行时间都是最坏情况的运行时间,即在数组中查找某元素,时间复杂度为O(n);
在长度为n数组中:
直接通过下标去访问元素,时间复杂度为O(1)。
需要循环查找元素的时候,时间复杂度为O(n)。
下一章我们将分析ArrayList的删除元素的源码,来分析一下ArrayList的时间复杂度,进而了解ArrayList的优点与不足。
三顾ArrayList
ArrayList部分一共五篇文章了,并且引入了时间复杂度来分析,强烈建议大家一定要按顺序阅读,相关文章分别是:
第三次强调,ArrayLIst是一个普通的类。
好,现在我们来讨论一下数组的删除,我们知道数组一但在堆内存中创建出来,数组长度是不可变的,看以下源码:
添加10个用户
比如我们要把“周八”这个人从数组中删除,如图:
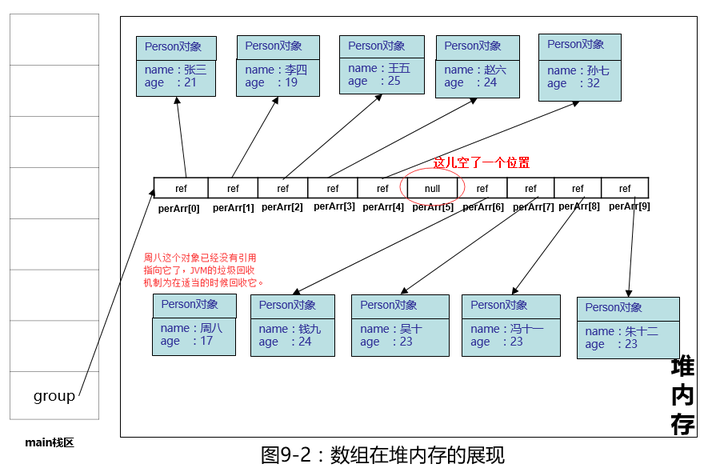
我们只能循环数组,找到“周八“的下标5,由于数组没有提供删除方法,我们只能把下标为5的位置赋值为null(造成了数组空洞),“周八”这个Person对象已经没有引用指向它了,JVM的垃圾回收机制会在适当的时候回收它。但数组的长度还是10。下次当我们再循环查找某人时,稍不注意就会报空指针异常,虽然我们可以写非空去判断,但还是不太友好,我们把null后面的所有元素引用复制一下,往前拷贝一份,把null这个空给填上,如下图
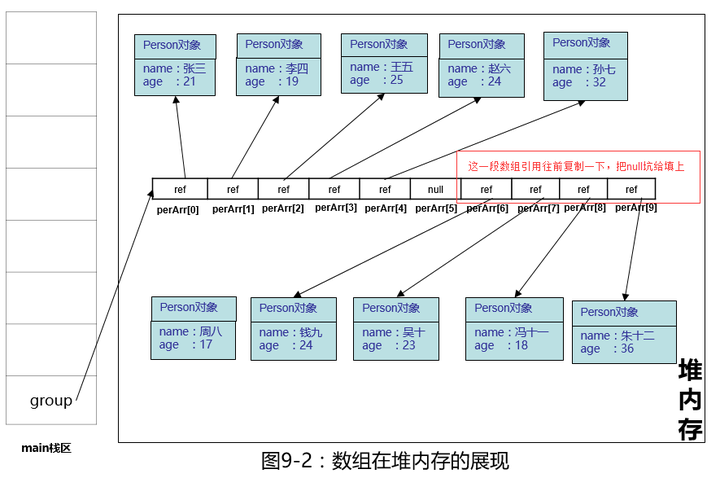
复制后:
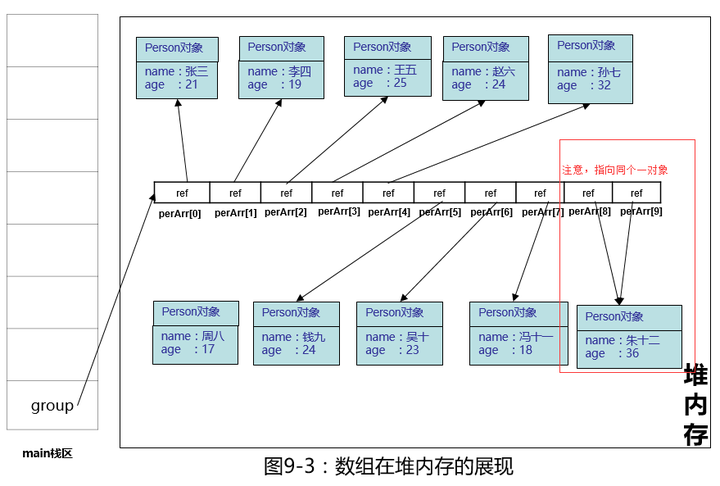
null之后的ref引用都按顺序复制了一份到原来的null的位置,原有的1引用被覆盖,但perArr[9]里的引用的指向还是不变(注意,是复制不是挪动,仔细看一下上面两个图)。
注意:perArr[8],perArr[9]指向的是同一个对象,这显然不是我们所要的结果,再处理一下,我们把perArr[9]的引用赋值为null。如下图:
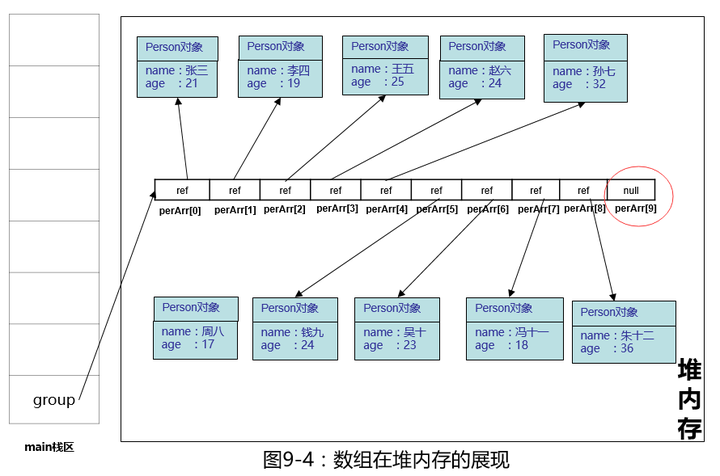
问题似乎解决了,但数组长度还是10,还需要自行维护了一个size来记录长度,以上数组复制的代码,我们都要自己去写,好在ArrayList这个类已经实现了,数组拷贝工作交给它就好,我们只需要调用ArrayList这个类提供的remove删除元素就行,至于底层数组怎么拷贝,元素怎么删除由ArrayList对象本身去搞定(面向对象的思想),我们来看一看ArrayList的两种元素删除方式,首先是按照下标删除:
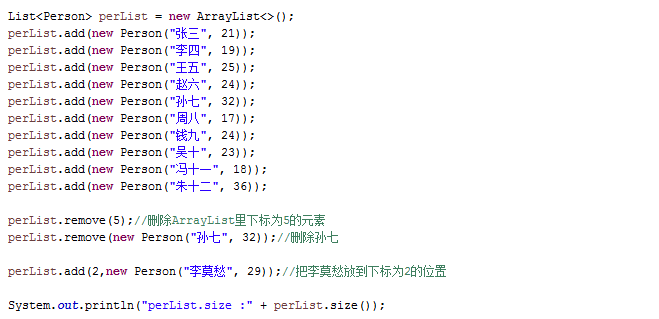
我们先看看删除前的元素,debug一下:

perList里面已经有了10个元素,执行一下这两句remove操作,再看一下debug的情况

下标为5的“周八”已经删除掉了,下标为5以后的元素也按照我们之前的猜想往前移了一位,数组最后一个位置也置为null了。奇怪!“孙七”居然没有删掉!打印出来的个数也是9

我们看一下两种删除方式的源码。
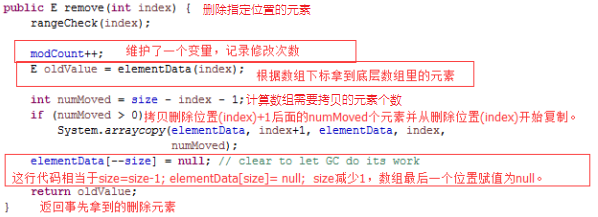
基本上和我们图中的分析一致,并采用size来记录元素的真实个数,这段代码里还调了一个方法rangeCheck()方法,我们看一下:

好简单对不对,就是检查底层数组下标是否越界。我们再看另外一种删除方式
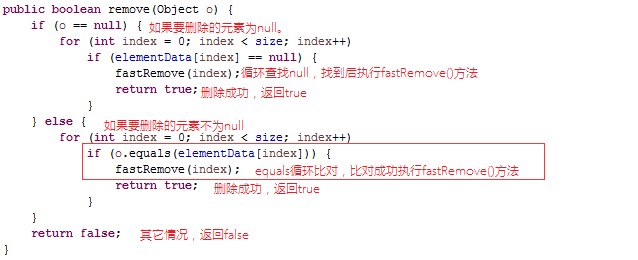
再看一下fastRemove()方法
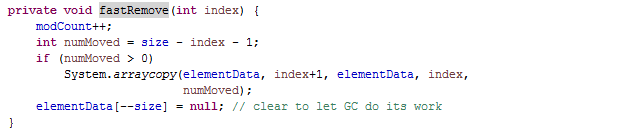
和上面用下标删除方式一致,这儿就不细说了。
相信大家看到上面熟悉的equals()方法,就大概知道“孙七”为什么没有删掉了,如果你写了一个类(Person),你需要这个类完美的支持List,你必需按照List的规范来写代码,我们在
说说Java里的equals(中) - 知乎专栏 一文中已经说得很清楚了,这儿就不细说了。

知道问题的原因就好解决了,我们重写equals()方法试一下。
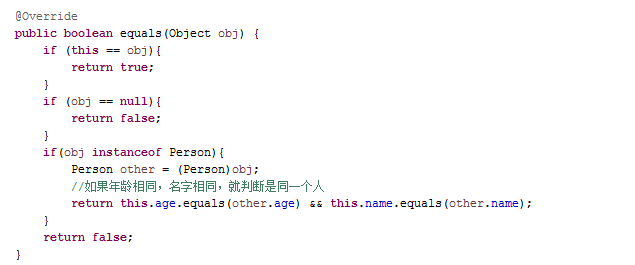
重写完equals方法,执行一下再debug看一下

孙七已经删除掉了,孙七后面的所有人也向前复制了一格,末位置为null,size也是8了,再画一画图:
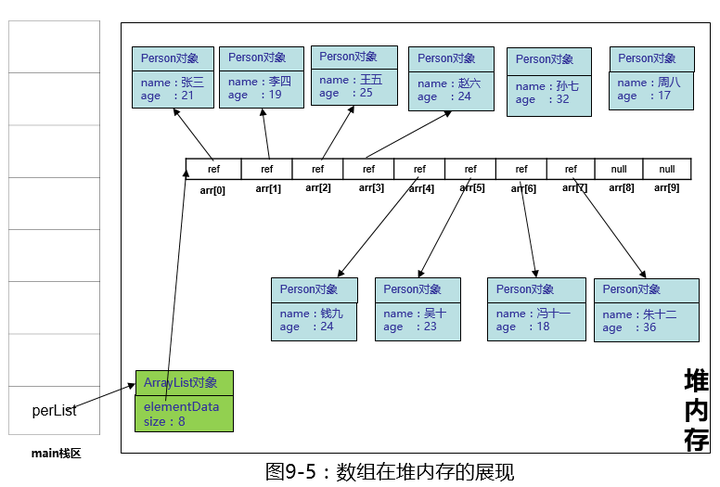
图中的“孙七”,“周八”已经没有引用指向它们,JVM虚拟机会在适当的时候进行回收。
我们说一说ArrayList中删除元素的时间复杂度。在ArrayLIst中,如果底层数组长度为n。
当我们用下标方式去删除元素时,如果删除的是最后一个元素,不会触发数组底层的复制,时间复杂度为O(1)。如果删除第i的元素,会触发底层数组复制n-i次,根据最坏情况,时间复杂度为O(n)。
由此看来,在ArrayList中删除指定元素的效率似乎不是太高,删除元素会造成底层数组复制,这个问题在LinkedList有方案解决,请关注后续专栏文章。
示例中,用对象的方式来删除元素,只是想告诉大家,这种删除方式是用equals方法来查找元素的下标进而删除的,实际工作中很少遇到需要new一个对象去删除的情况。不建议一上来就重写equals方法,除非你有特殊的需求。如果重写了equals方法,请一并重写hashCode方法,这个问题在说说Java里的equals(中)一文中已经说过了。
ArrayList的时间复杂度
第一次修正:2017年7月25日 新增加了存元素set(int index, E element)的介绍,并修改了总结。
ArrayList部分一共五篇文章了,并且引入了时间复杂度来分析,强烈建议大家一定要按顺序阅读,相关文章分别是:
在以前的文章里,我们已经看过了add方法的源码,还有一个add方法,我们看一下, public void add(int index, E element) ,从指定位置添加元素

按照下标把元素添加到指定位置,想必大家都知道,我们直接上源码。

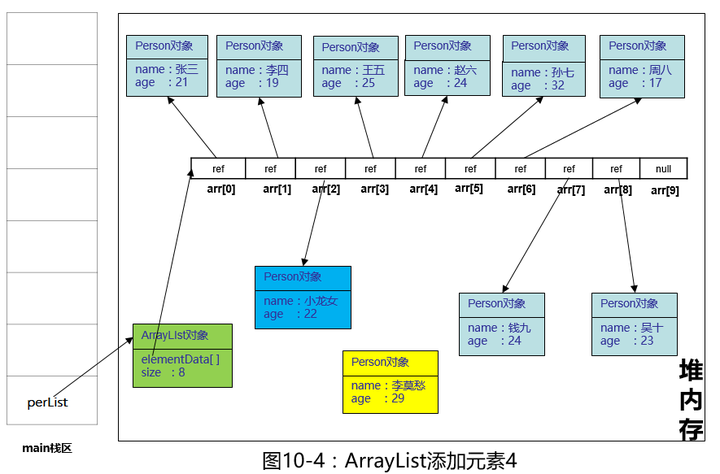
老规矩,我们还是画一画,当执行到System.arraycopy()这个方法时
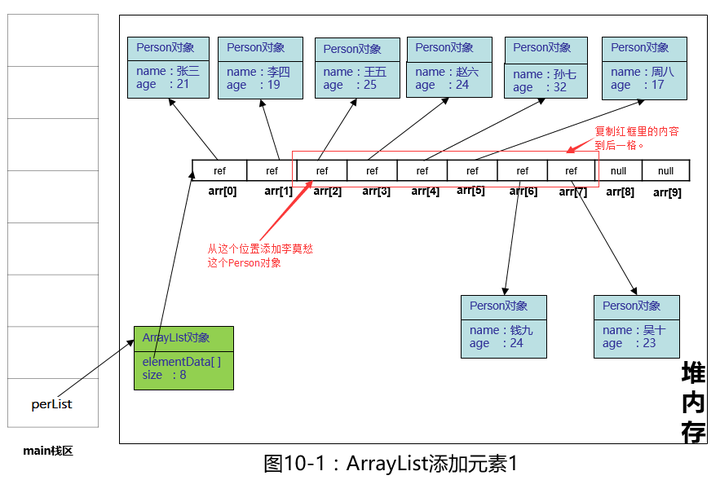
我看到有些书上写的是依次移动元素到下一格,这种说法不够严谨,所以我再强调一遍,是依次复制插入位置及后面的数组元素,到后面一格,不是移动,因此,复制完后,arr[2],arr[3]指向对一个对象。
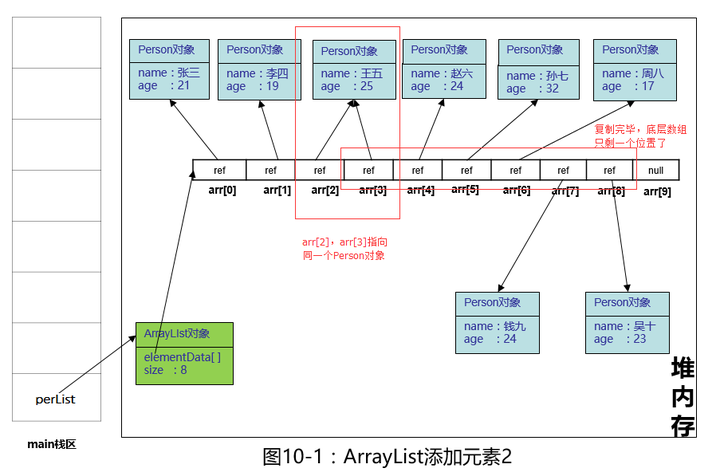
在代码执行完这一句

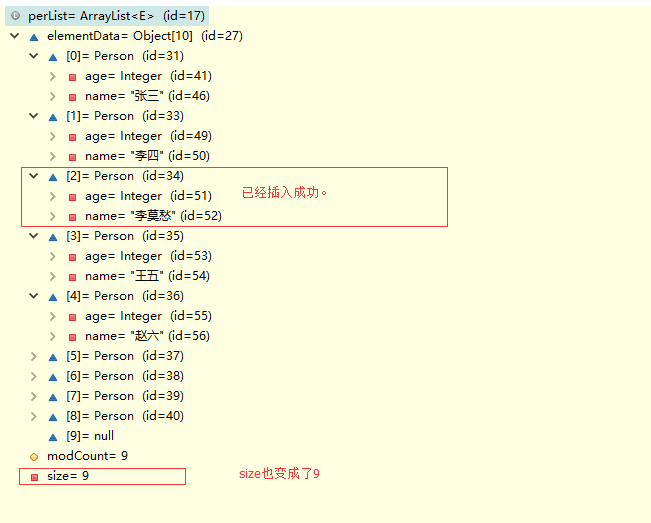
我们debug验证一下。

最后,在堆内存中创建李莫愁这个对象,把arr[2]的引用指向它。
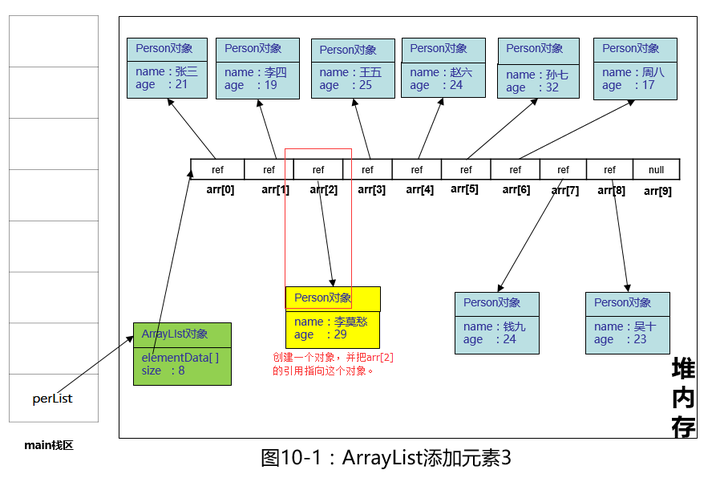
再debug一下
最后我们来说说ArrayLIst这个对象里添加的时间复杂度:
如果我们不指定位置直接添加元素时(add(E element)),元素会默认会添加在最后,不会触发底层数组的复制,不考虑底层数组自动扩容的话,时间复杂度为O(1) ,在指定位置添加元素(add(int index, E element)),需要复制底层数组,根据最坏打算,时间复杂度是O(n)。
最后我们说一说读取元素,下面代码是获取List中下标为2的元素

看一下源码:

很简单,读取元素和数组长度无关,直接从底层数组里去拿元素。
评论区有人说,为什么是“李莫愁”,看样子是不太喜欢“李莫愁”,我们可以调用 set(int index, E element)方法来替换。

我们看一看这个方法的源码

很简单,就是往指定位置放入元素,并返回原来的元素,最后我们来画一画
图中“李莫愁”已经没有引用指向它了,JVM会在合适的时候回收它,底层数组第2个位置已经换成了“小龙女”,我们debug验证一下。
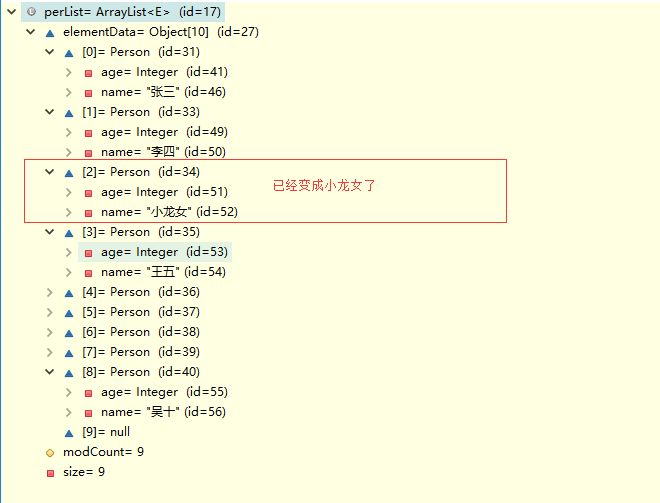
没错,已经换成小龙女了。
这是最后一期ArrayLIst源码分析,引入了时间复杂度,最后,我们来做个总结:
根据前几篇文章我们可以看出来,在ArrayList中,底层数组存/取元素效率非常的高(get/set),时间复杂度是O(1),而查找,插入和删除元素效率似乎不太高,时间复杂度为O(n)。
当我们ArrayLIst里有大量数据时,这时候去频繁插入/删除元素会触发底层数组频繁拷贝,效率不高,还会造成内存空间的浪费,这个问题在另一个类:LinkedList里有解决方案,请期待后续文章讲解。
查找元素效率不高,在HashMap里有解决方案,请关注后续文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号