HashMap底层实现原理
HashMap底层实现原理(上) https://zhuanlan.zhihu.com/p/28501879
总结:hashMap 底层实现是Node数组+链表(出现相同的hash值,新加的元素链接到已有的后边,链表长度8)+红黑树(当链表>8 ,转换为红黑树,提高效率)
修改记录:
2017年8月17日 12:00 调整了本文顺序,新增小结。
本来想先在专栏里简单的说一下二叉树,红黑树的内容后再说HashMap的,但看到评论区里不断的出现HashMap这个词,怕大家等得着急,本篇文章就先说说HashMap吧,前面讲ArrayList和LinkedList时把源码说得很细,只要理解了这两块内容,本篇内容也很好理解,先来看看HashMap在Map这个大家族中的位置。
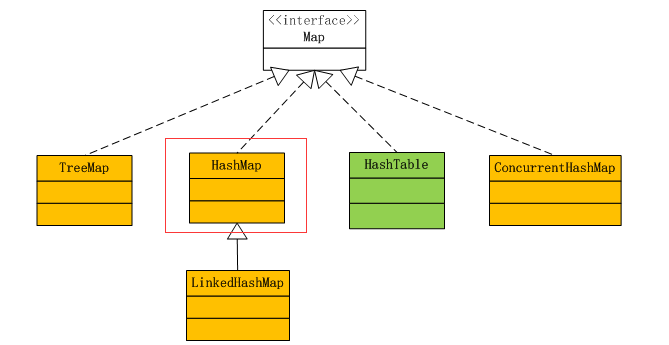
上图中,白色部分是接口,黄色部分是要重点了解的,最好是看一遍源码,绿色部分已经过时,不常用了,但是面试中可能会问到。这里先简单的说一下这几个Map,TreeMap是基于树的实现,HashMap,HashTable,ConcurrentHashMap是基于hash表的实现,下文我们会介绍hash表。HashTable和HashMap在代码实现上,基本上是一样的,和Vector与Arraylist的区别大体上差不多,一个是线程安全的,一个非线程安全,忘记了的朋友可以去看这篇文章,传送门:Arraylist与Vector的区别。ConcurrentHashMap也是线程安全的,但性能比HashTable好很多,HashTable是锁整个Map对象,而ConcurrentHashMap是锁Map的部分结构,LinkedHashMap后续会单独开文讲解。
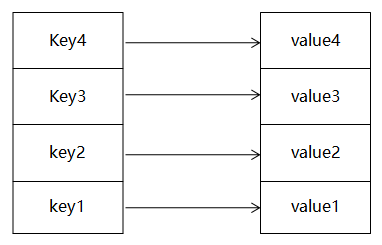
Map其实很简单,就是一个key,对应一个value。本章我们重点了解HashMap,话不多说,上代码:
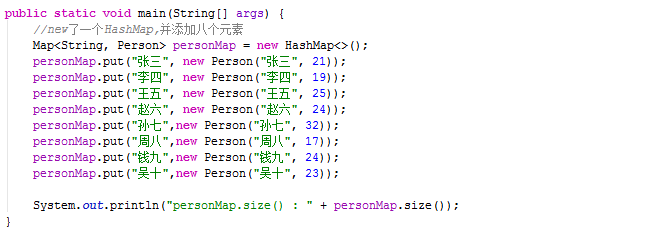
执行构造函数,当我们看到这个new,第一反应应该是这货又在堆内存里开辟了一块空间。
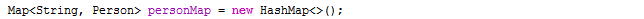
构造函数如下:

似乎简单,就是初始化了一个负载因子
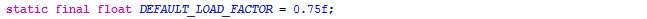
负载因子默认为0.75f,这个负载因子后续会详说。

嘿嘿,又看到了传说中的数组,数组里原对象是Node,来看一下Node是什么鬼

其实很简单,一些属性,一个key,一个value,用来保存我们往Map里放入的数据,next用来标记Node节点的下一个元素。目前还没有任何代码用到Node,我们只能从成员变量入手了

这两个就不多说了吧,一个是逻辑长度,一个是修改次数,ArrayList,LinkedList也有这两个属性,老规矩,我们来画一画
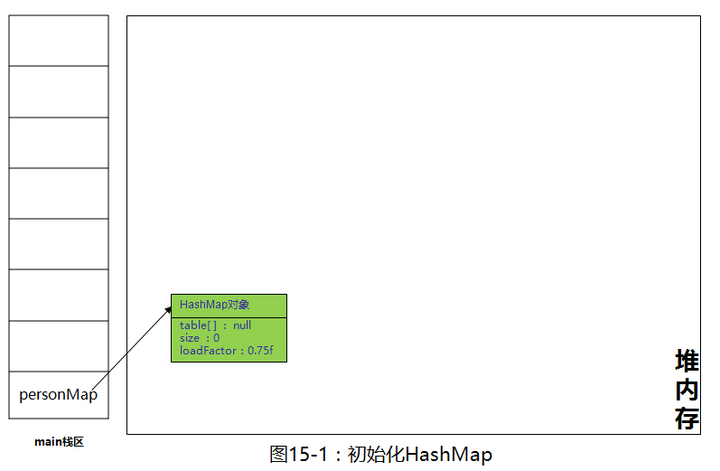
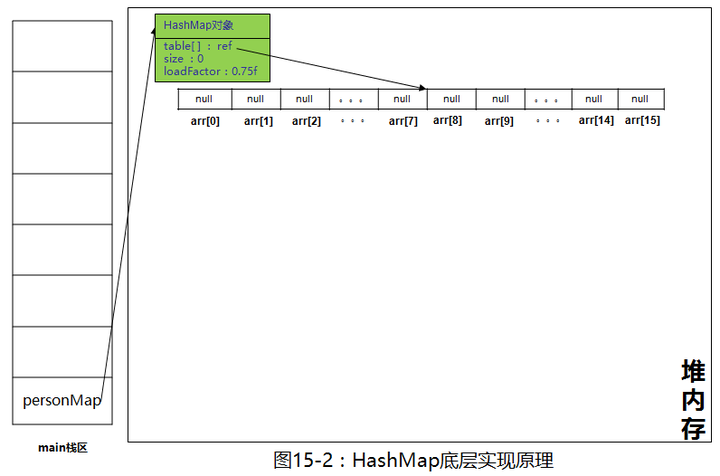
HashMap我们就初始化好了,成员变量table数组默认为null,size默认为0,负载因子为0.75f,初始化完成,往里添加元素,来看一下put的源码

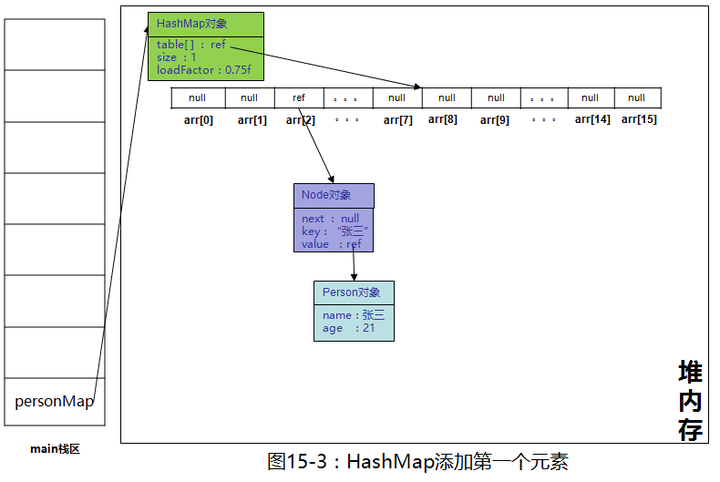
就一行代码,调用了putVal方法,其中key是传进来的“张三”这个字符串对象,value是“张三”这个Person对象,调用了一个方法hash(),再看一下

看到了熟悉的hashCode,我们在前面的文章里已经强调过很多次了,重写equals方法的时候,一定要重写hashCode方法,因为key是基于hashCode来处理的。继续看putVal方法
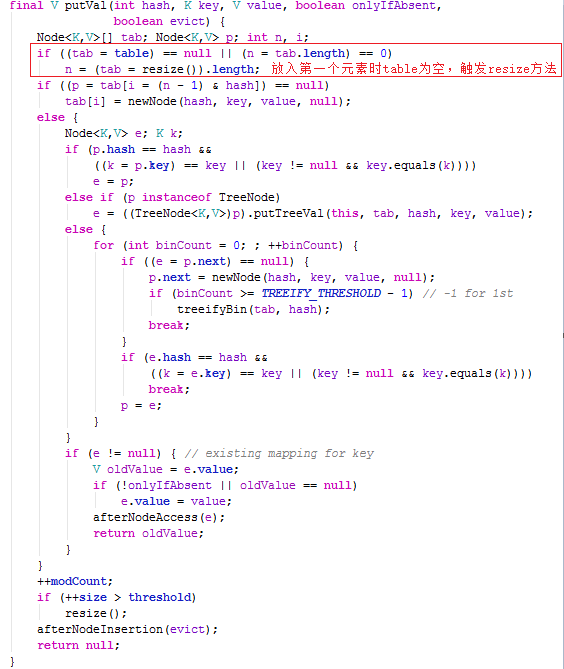
resize方法比较复杂,这儿就不完全贴出来了,当放入第一个元素时,会触发resize方法的以下关键代码

再看这个DEFAULT_INITIAL_CAPACITY是什么东东
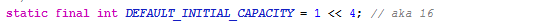
又是传说中的移位运算符,1 << 4 其实就是相当于16。
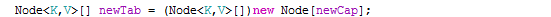
恩,这句是关键,当我们放入第一个元素时,如果底层数组还是null,系统会初始化一个长度为16的Node数组,像极了ArrayList的初始化。

最后返回new出来的数组,继续画图,由于篇幅有限,下图中省略了部分数组内容,注意,虽然数组长度为16,但逻辑长度size依然是0
继续执行下图中putVal方法里的红框内容
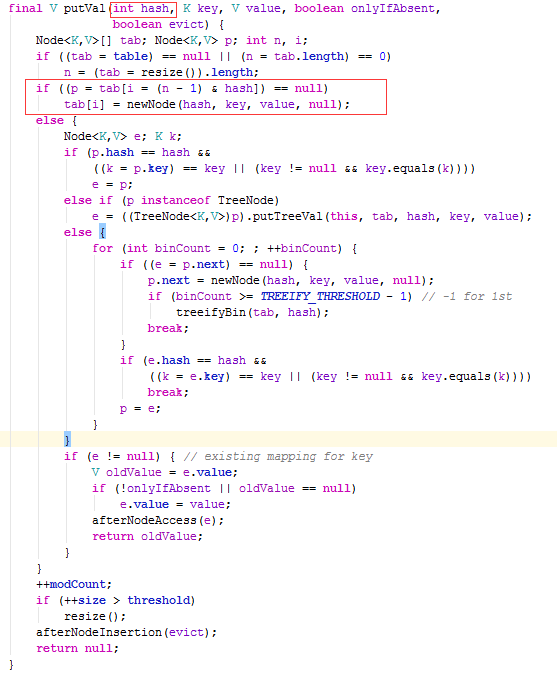
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);这段代码初学者可能看起来比较费劲,我们重写一下以便初学者能更好的理解,这两段代码等同,下面是重写后的代码,清晰了很多
i = (n - 1) & hash;//hash是传过来的,其中n是底层数组的长度,用&运算符计算出i的值
p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){//如果这个元素为null,用key,value构造一个Node对象放入数组下标为i的位置
tab[i] = newNode(hash, key, value, null);
}这个hash值是字符串“张三”这个对象的hashCode方法与hashMap提供hash()方法共同计算出来的结果,其中n是数组的长度,目前数组长度为16,不管这个hash的值是多少,经过(n - 1) & hash计算出来的i 的值一定在n-1之间。刚好是底层数组的合法下标,用i这个下标值去底层数组里去取值,如果为null,创建一个Node放到数组下标为i的位置。这里的“张三”计算出来的i的值为2,继续画图
继续添加元素“李四”,“王五”,“赵六”,一切正常,key:“李四”经过(n - 1) & hash算出来在数组下标位置为1,“王五”为7,“赵六”为9,添加完成后如下图
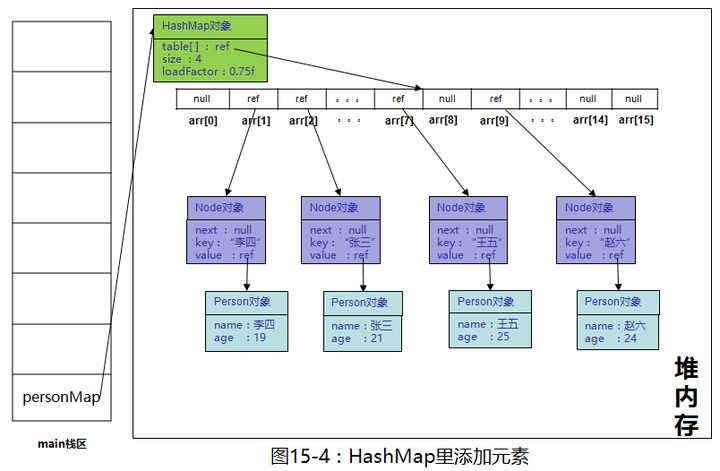
上图更趋近于堆内存中的样子,但看起来比较复杂,我们简化一下
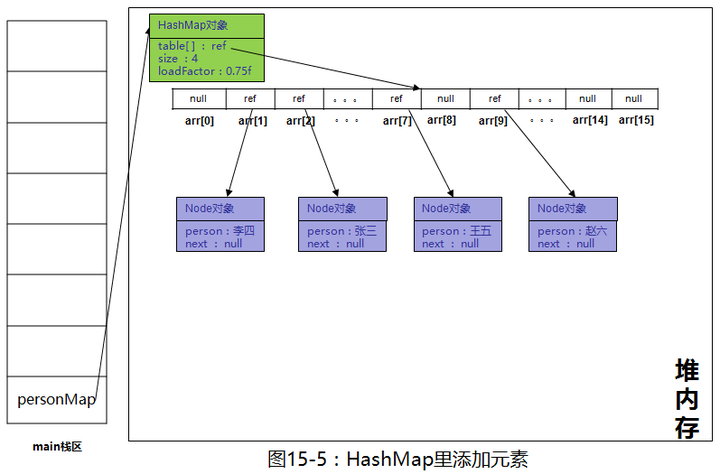
上图是简化后的堆内存图。继续往里添加“孙七”,通过(n - 1) & hash计算“孙七”这个key时计算出来的下标值是1,而数组下标1这个位置目前已经被“李四”给占了,产生了冲突。相信大家在看本文的过程中也有这样的疑惑,万一计算出来的下标值i重了怎么办?我们来看一看HashMap是怎么解决冲突的。
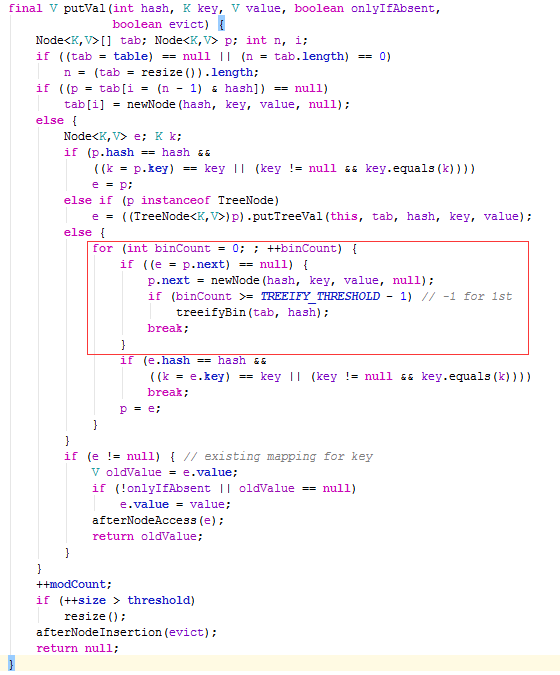
上图中红框里就是冲突的处理,这一句是关键
p.next = newNode(hash, key, value, null);也就是说new一个新的Node对象并把当前Node的next引用指向该对象,也就是说原来该位置上只有一个元素对象,现在转成了单向链表,继续画图
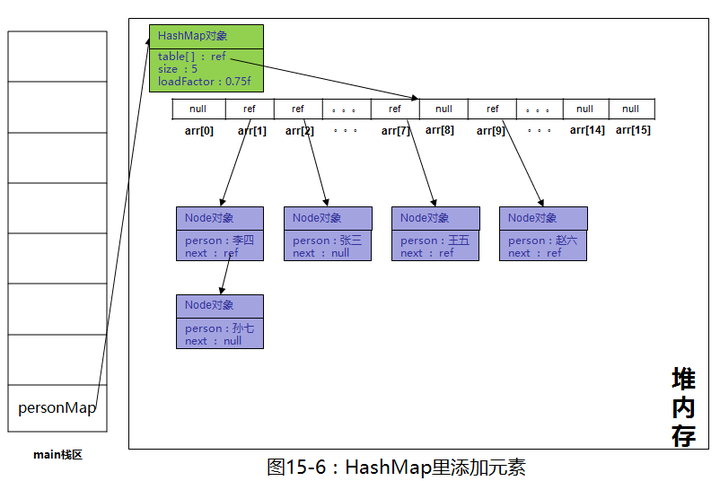
继续添加其它元素,添加完成后如下
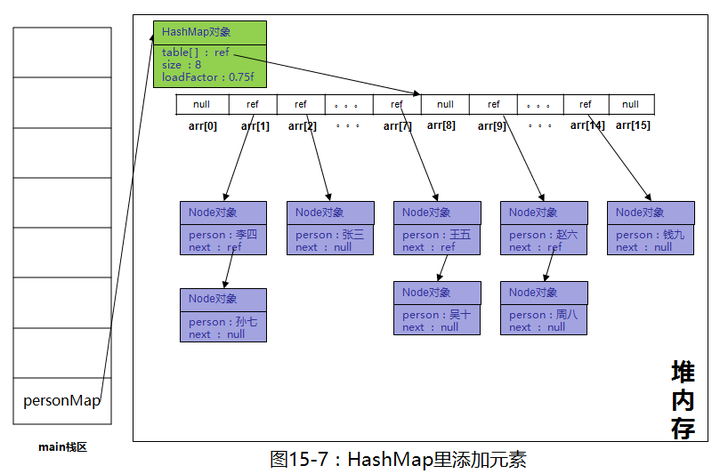
到这里,我们的元素就添加完了。我们debug看一下

大框里的内容是链表的体现,小框里的内容是单元素的体现。
红框中还有两行比较重要的代码
if (binCount >= TREEIFY_THRESHOLD - 1) //当binCount>=TREEIFY_THRESHOLD-1
treeifyBin(tab, hash);//把链表转化为红黑树再看看TREEIFY_THRESHOLD的值
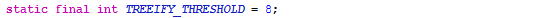
当链表长度到8时,将链表转化为红黑树来处理,由于树相关的内容本专栏还未讲解,红黑树的内容这里就不深入了。树在内存中的样子我们还是画个图简单的了解一下
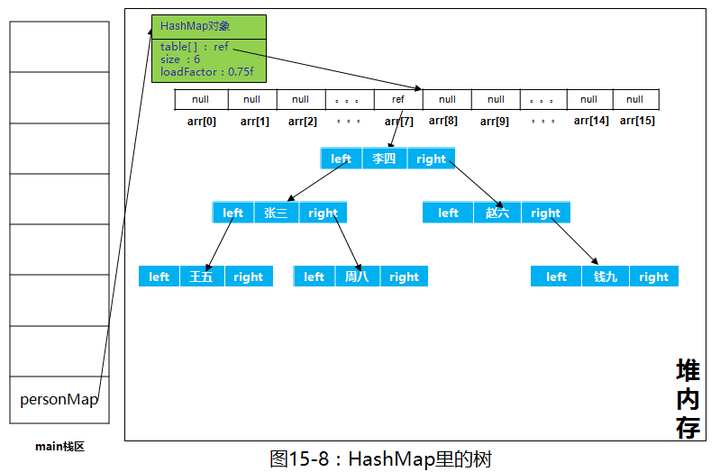
在JDK1.7及以前的版本中,HashMap里是没有红黑树的实现的,在JDK1.8中加入了红黑树是为了防止哈希表碰撞攻击,当链表链长度为8时,及时转成红黑树,提高map的效率。在面试过程中,能说出这一点,面试官会对你加分不少。
注:本章所讲的移位运算符(如:“<<”)、位运算符(如:“&”),红黑树、哈希表碰撞攻击等,这里不做详解,大家有兴趣的话请在评论区留言,响应的人多的话,会单独开文讲解。
思考下面代码:

hash方法的实现:

在put放入元素时,HashMap又自己写了一个hash方法来计算hash值,大家想想看,为什么不用key本身的hashCode方法,而是又处理了一下?
本文到这里先告一个段落,先做一个小结。
HashMap的最底层是数组来实现的,数组里的元素可能为null,也有可能是单个对象,还有可能是单向链表或是红黑树。
文中的resize在底层数组为null的时候会初始化一个数组,不为null的情况下会去扩容底层数组,并会重排底层数组里的元素。
如果喜欢本系列文章,请为我点赞或顺手分享,您的支持是我继续下去的动力,您也可以在评论区留言想了解的内容,有机会本专栏会做讲解,最后别忘了关注一下我。
HashMap底层实现原理(下)
公众号:saysayJava,敬请支持。
上一篇文章我们介绍了HashMap的底层实现,但还遗留了一点内容,我们再回顾一下上一篇文章里说的内容
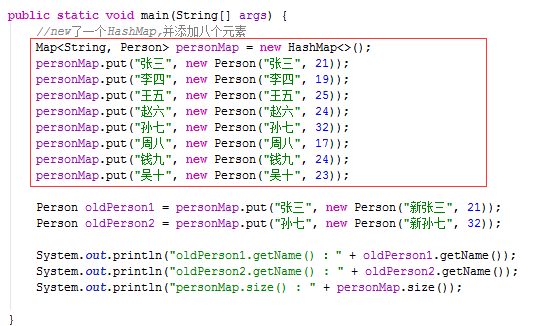
执行完红框里的代码,personMap里放入了8个元素,放置完成后在堆内存表现如下图
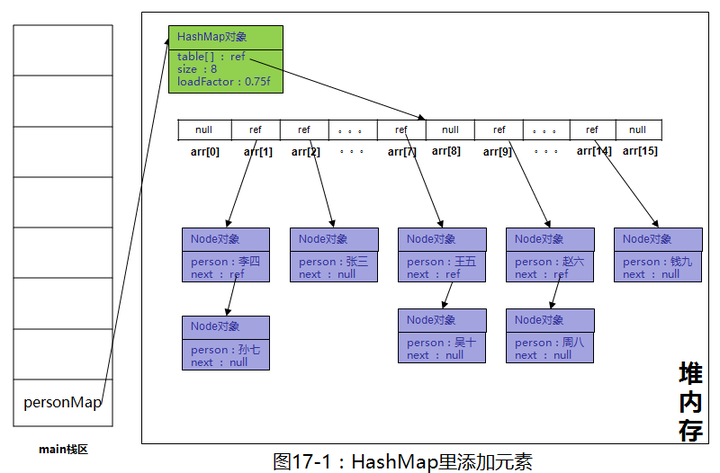
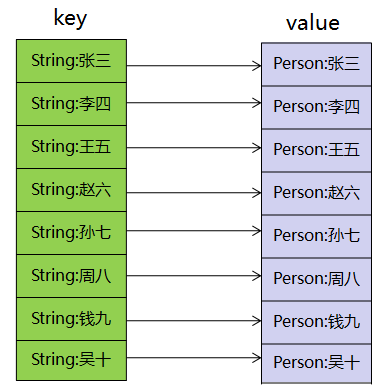
如果忽略底层实现细节,是这样的
在Map中,一个key,对应了一个value,如果key的值已经存在,Map会直接替换value的内容,来看一下源码中是怎么实现的,来看以下代码
Person oldPerson1 = personMap.put("张三", new Person("新张三", 21));
Person oldPerson2 = personMap.put("孙七", new Person("新孙七", 32));
System.out.println("oldPerson1.getName() :" + oldPerson1.getName());
System.out.println("oldPerson2.getName() : " + oldPerson2.getName());
System.out.println("personMap.size() : " + personMap.size());new了一个Person“新张三”,注意,key依然是张三,看一下源码

放入“新张三”时,会执行以上代码1、2、5
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);上面这段代码在上一篇文章已经改写过了,改写后的代码如下:
i = (n - 1) & hash;//hash是传过来的,其中n是底层数组的长度,用&运算符计算出i的值
p = tab[i];//用计算出来的i的值作为下标从数组中元素
if(p == null){//这儿P不为null,所以下面这行代码不会执行。
tab[i] = newNode(hash, key, value, null);//这行代码不会执行
}很简单,直接在底层数组里取值赋值给p,由于p不为null,执行else里的逻辑
Node<K,V> e; K k;
if (p.hash == hash && //如果hash值相等,key也相等,或者equals相等,赋值给e
((k = p.key) == key || (key != null && key.equals(k))))
e = p;//赋值给e又看到了熟悉的equals方法,这里我们hash值相等,key的值也相等,条件成立,把值赋值给e。(如果key的值不相等,就比较equals方法,也就是说,就算key是一个新new出来的对象,只要满足equals,也视为key相同)
if (e != null) { // existing mapping for key
V oldValue = e.value;//定义一个变量来存旧值
if (!onlyIfAbsent || oldValue == null)
e.value = value;//把value的值赋值为新的值
afterNodeAccess(e);
return oldValue;//返回的值
}这段代码就比较简单了,用新的value替换旧value并返回旧的value。画一下图
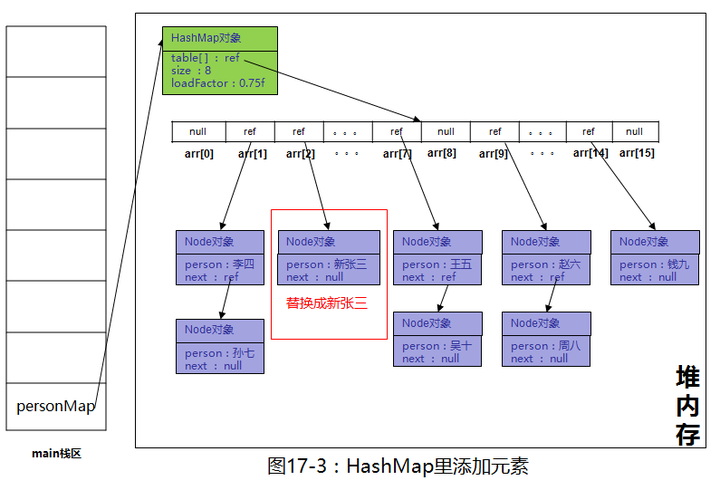
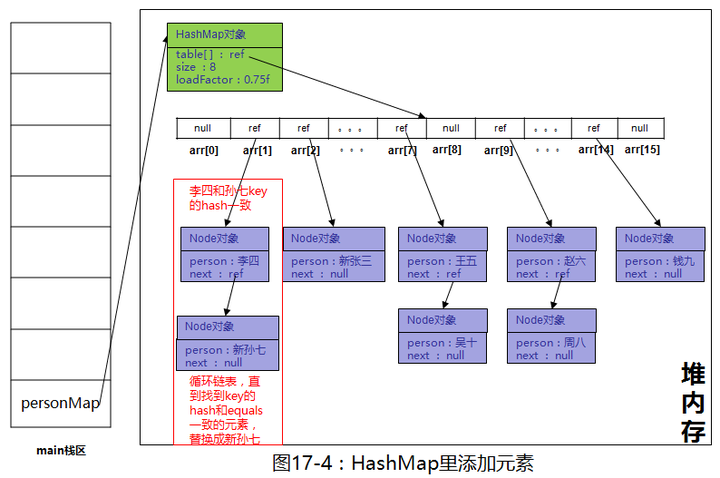
再new一个Person“新孙七”并put到personMap中,注意,key依然是“孙七”,会执行图17-2里的1、2、3、4、5,由于2、3不满足条件,实际执行的是1、4、5,1这一步已经说过了,重点说一下4这一步
for (int binCount = 0; ; ++binCount) {//循环
if ((e = p.next) == null) {//如果循环到最后也没找到,把元素放到最后
p.next = newNode(hash, key, value, null);//把元素放到最后
if (binCount >= TREEIFY_THRESHOLD - 1) //如果长度超>=8,转换成红黑树
treeifyBin(tab, hash);//转换成红黑树
break;
}
if (e.hash == hash && //这段代码和第2步一样
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;//如果hash值相等,key也相等或者equals相等,赋值给e
}
}
}其实就是循环链表的节点,直到找到"孙七"这个key,然后执行图17-2里的第5步,如果找不到,就添加到最后,这里我们key是“孙七”,在链表中找到元素替换value即可,再画一下图
最后来看看放到树里的方法putTreeVal,由于树的内容我们还没涉及到,下面只标注出了关键代码

和链表类似,循环(遍历)树的节点,如果找到节点,返回节点,执行图17-2里的第5步更新value。如果循环完整颗数都找不到相应的key,添加新节点。
最后我们看一下本文初那段示例代码的执行结果:

虽然元素已经替换成新的值,但示例中打印的是替换前的值,元素个数还是8不变,debug看一下,是不是value更新成功了
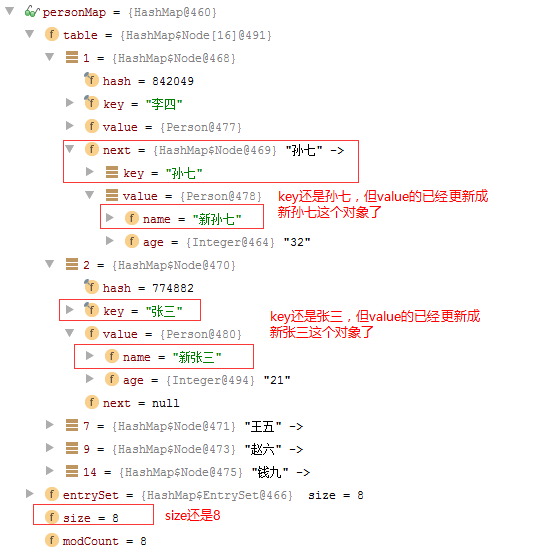
更新已经成功。
结合上一篇内容,做一个总结,在hashMap中放入(put)元素,有以下重要步骤:
1、计算key的hash值,算出元素在底层数组中的下标位置。
2、通过下标位置定位到底层数组里的元素(也有可能是链表也有可能是树)。
3、取到元素,判断放入元素的key是否==或equals当前位置的key,成立则替换value值,返回旧值。
4、如果是树,循环树中的节点,判断放入元素的key是否==或equals节点的key,成立则替换树里的value,并返回旧值,不成立就添加到树里。
5、否则就顺着元素的链表结构循环节点,判断放入元素的key是否==或equals节点的key,成立则替换链表里value,并返回旧值,找不到就添加到链表的最后。
精简一下,判断放入HashMap中的元素要不要替换当前节点的元素,key满足以下两个条件即可替换:
1、hash值相等。
2、==或equals的结果为true。
由于hash算法依赖于对象本身的hashCode方法,所以对于HashMap里的元素来说,hashCode方法与equals方法非常的重要,这也是在说说Java里的equals(中)一文中强调重写对象的equals方法一定要重写hashCode方法的原因,不重写的话,放到HashMap中可能会得不到你想要的结果!本示例中放入的key是String类型的,String这个类已经重写了hashCode方法,有兴趣的朋友可以自行查看源码。
如果喜欢本系列文章,请为我点赞或顺手分享,您的支持是我继续下去的动力,您也可以在评论区留言想了解的内容,有机会本专栏会做讲解,最后别忘了关注一下我。
本专栏所有文章请点击:专栏目录索引
转载无限欢迎,但请注明「作者」和「原文地址」。转载请在文中保留此段,感谢您对作者版权的尊重。如需商业转载或刊登,请联系作者获得授权。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号