并行执行
/**
* 并行执行
* @param ids
* @param func
* @param <T>
* @return
*/
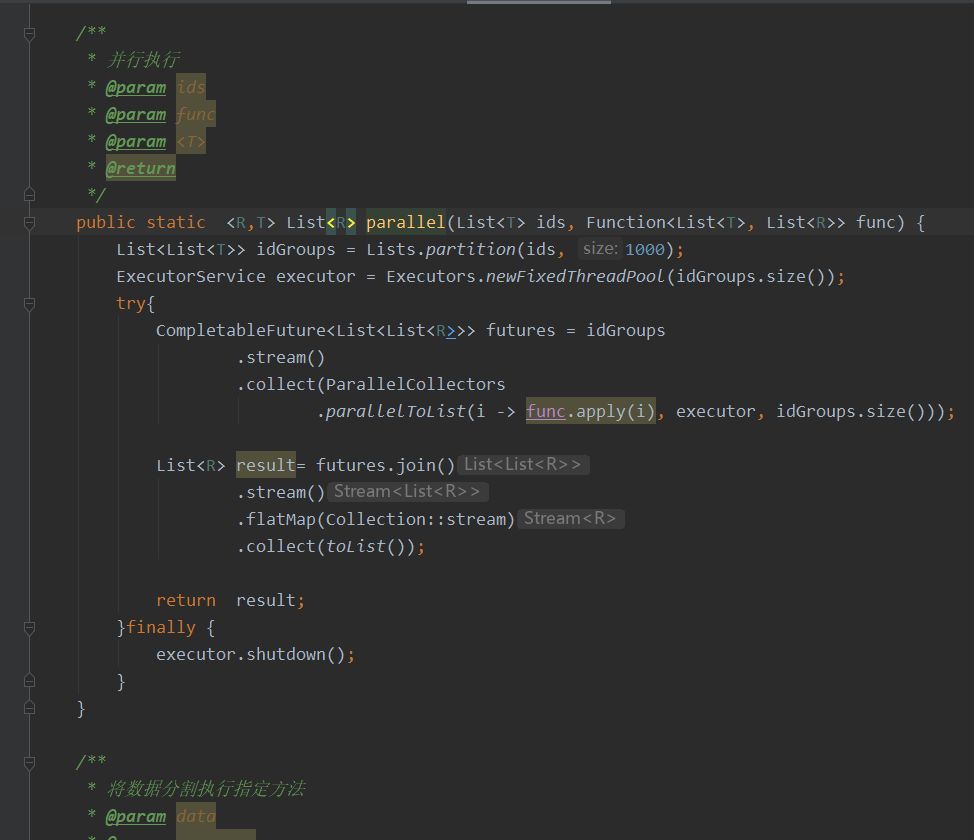
public static <R,T> List<R> parallel(List<T> ids, Function<List<T>, List<R>> func) {
List<List<T>> idGroups = Lists.partition(ids, 1000); /////将list集合按指定长度进行切分,返回新的List<List<??>>集合,如下的:List<List<Integer>> lists=Lists.partition(numList,3);
// List<Integer> numList = Lists.newArrayList(1, 2, 3, 4, 5, 6, 7, 8);
// List<List<Integer>> lists=Lists.partition(numList,3);
// System.out.println(lists);//[[1, 2, 3], [4, 5, 6], [7, 8]]
ExecutorService executor = Executors.newFixedThreadPool(idGroups.size()); //创建 idGroups.size() 个线程池
try{
CompletableFuture<List<List<R>>> futures = idGroups
.stream()
.collect(ParallelCollectors
.parallelToList(i -> func.apply(i), executor, idGroups.size()));
List<R> result= futures.join()
.stream()
.flatMap(Collection::stream)
.collect(toList());
return result;
}finally {
executor.shutdown();
}
}
/**
* 将数据分割执行指定方法
* @param data
* @param consumer
* @param <T>
*/
public static <T> void partitionInvoke(List<T> data, Consumer<List<T>> consumer) {
List<List<T>> items = Lists.partition(data, 1000);
for (List<T> item : items) {
consumer.accept(item);
}
}
java.lang.StackOverflowError解决
osc_v9ujioxy
2019/11/01 09:58
阅读数 479
在使用JPA的仓储repository进行查询时,经常用到findAllbyId的方法: repository.findAllbyId()
但如果像下面的代码,当list的size量太大的话,就会报栈溢出的的错误:java.lang.StackOverflowError
@RequestMapping("/stackOverFlow")
public Integer stackOverFlow() {
List<String> ids = new ArrayList<>();
for (int i = 0; i < 5000; i++) {
ids.add("123123123123");
}
List<BillDO> allById = dwBillRepository.findAllById(ids);
return allById.size();
}
报错信息如下:
Caused by: java.lang.StackOverflowError
at antlr.BaseAST.toString(BaseAST.java:333) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:341) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
at antlr.BaseAST.toStringList(BaseAST.java:347) ~[antlr-2.7.7.jar:?]
原因就是在拼sql时方法入栈太深,超过了jvm允许的最大深度,也就是递归调用的太深了。
public String toStringList() {
String var2 = "";
if (this.getFirstChild() != null) {
var2 = var2 + " (";
}
var2 = var2 + " " + this.toString();
if (this.getFirstChild() != null) {
var2 = var2 + ((BaseAST)this.getFirstChild()).toStringList();
}
if (this.getFirstChild() != null) {
var2 = var2 + " )";
}
if (this.getNextSibling() != null) {
var2 = var2 + ((BaseAST)this.getNextSibling()).toStringList();
}
return var2;
}
解决方法就是不要递归的太深。或者调整JVM参数栈大小默认为1m,可以调整到10m,看看不能解决问题,但这样做不推荐。会影响线程数,从而影响系统性能。
具体到上面的问题就是一次不要查太多的数据。如果in的数量有5000,我们就分开查询一次只查1000,查5次。再把结果组合在一起。
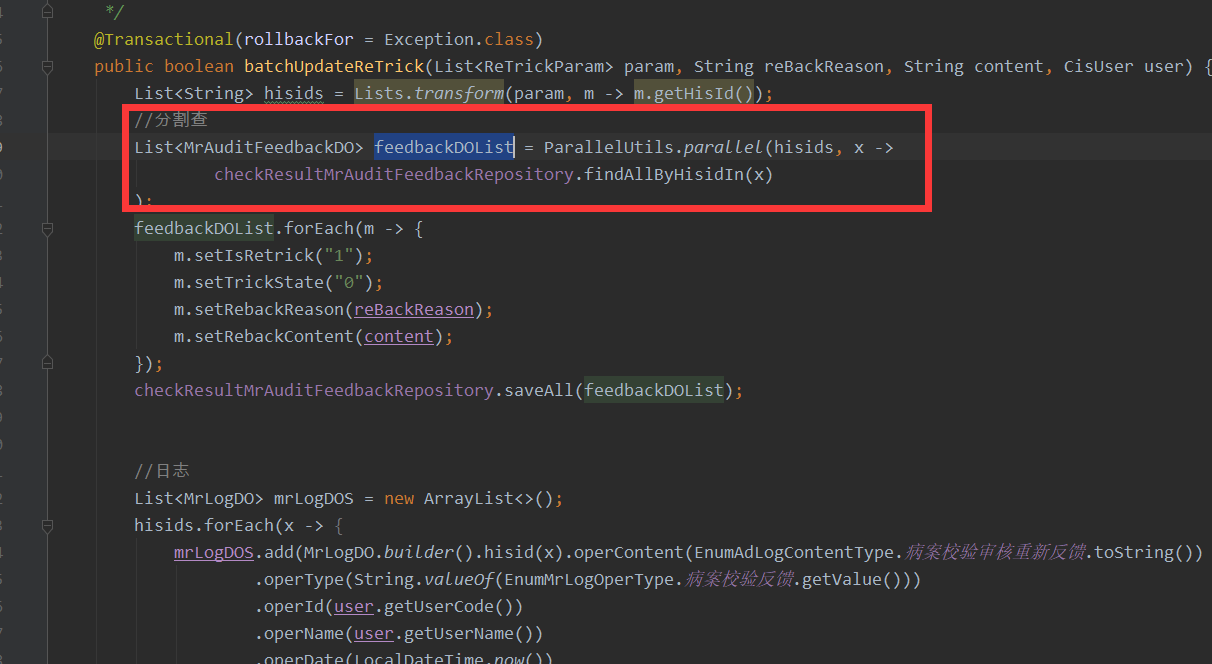
如果每个业务都单独写的话,就太麻烦了,可以写个公共的方法,如下: JPA_QUERY_LIST_MAX_SIZE是一个常量数据值,如1000个查一次。这里使用了并行查询,查询效率更高。
public <T> List<T> findAll(List<String> ids, Function<List<String>, List<T>> func) {
List<List<String>> idGroups = Lists.partition(ids, JPA_QUERY_LIST_MAX_SIZE);
ThreadPoolExecutor executor = (ThreadPoolExecutor) Executors.newFixedThreadPool(idGroups.size());
executor.setKeepAliveTime(10, TimeUnit.SECONDS);//解决线程不退出的问题
executor.allowCoreThreadTimeOut(true);
return idGroups
.stream()
.collect(ParallelCollectors
.parallelToList(i -> func.apply(i), executor, idGroups.size()))
.join()
.stream()
.flatMap(Collection::stream)
.collect(toList());
}
以上代码利用如一个第三方的库:需要引用:
<dependency>
<groupId>com.pivovarit</groupId>
<artifactId>parallel-collectors</artifactId>
<version>1.1.0</version>
</dependency>
我只是偶尔安静下来,对过去的种种思忖一番。那些曾经的旧时光里即便有过天真愚钝,也不值得谴责。毕竟,往后的日子,还很长。不断鼓励自己,
天一亮,又是崭新的起点,又是未知的征程(上校9)
逆水行舟,不进,则退!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号