对脱壳脚本的一些改进--识别出目标DEX
一、前言
通常对于加壳的程序,第一步的操作通常是脱壳,而现在脱壳一般都选择利用frida来进行hook进行脱壳,不谈其他脱壳方式,利用frida脱壳原理大致分为两种:
1、找到DexFile对象(art虚拟机下是DexFile对象,dalvik虚拟机下是DexFile结构体),获取到DEX文件的起始地址和大小,然后dump下来。常见能够找到DexFile对象的函数有LoadMethod、ResolveMethod函数等,能直接获取到DEX起始地址和大小的常见函数有openMemory、dexparse、dexFileParse、dvmDexFileOpenPartial等函数。frida_unpack便是其中的代表作。
2、利用frida的搜索内存,通过匹配DEX文件的特征,例如DEX文件的文件头中的magic---dex.035这个特征。frida-Dexdump便是这种脱壳方法的代表作。
然而不管是上述哪一种原理,在我这个有点强迫症的看来,都有一点小缺陷,这两种方法从原理上决定了经过某个函数的DEX(或者存在于内存中的DEX)都会被dump下来,所以出现了dump下来很多个DEX文件,但是只有其中一个或者几个是我们的目标DEX,为了寻找到目标DEX,只有全部反编译出后来能知道,这就比较浪费时间和精力了,对此,本人对脱壳脚本做了一些改进,通过对dump下来的DEX进行解析,从而识别出那个是我们的目标DEX!!!
二、通过类名识别出DEX
PS:通过类名识别是本人发现识别率最准确、实现代价最小的方法,所以本篇重点主要在这,后面的其他识别方法在某些特殊情况下更好用!!!
DEX文件的格式可以大致分为文件头、索引区、数据区,文件头这个区域无法找到一个DEX文件的一个唯一特征(ps:sha-1和校验码这两个能作为一个DEX文件唯一特征的前提是我们已经知道这个dex文件所有字节了,所以放在这里并不成立),索引区包括了很多数据的索引,其中便包括字符串的索引,通过这我们可以解析出整个DEX文件使用到的字符串。而我们已知的DEX文件的一些信息便包括包名。
通过解析一个DEX文件,我们可以发现在DEX中一个类被表示出如下形式--L包名/类名;,例如Lcom/example/test/ManActivity;这种形式,例如下面为使用脚本解析DEX的字符串,获取到的类名的截图:
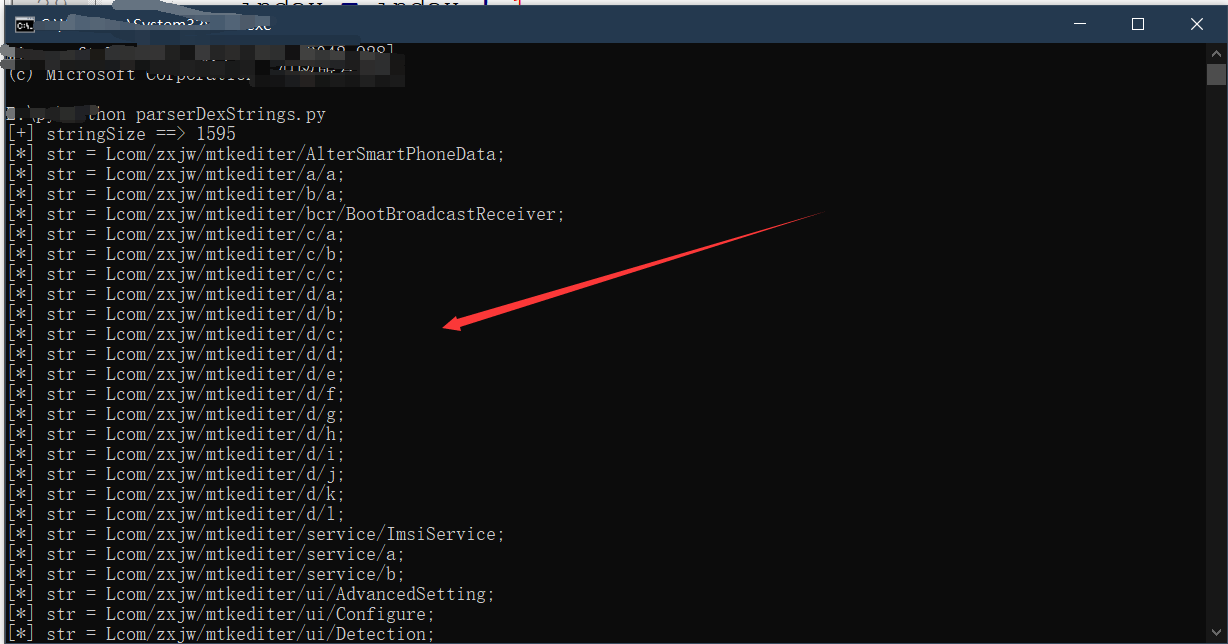
包名是唯一的,所以我们只需要构造/com/example/test这种形式的特征,便可以很轻易的锁定到目标DEX,但是,在壳程序中,也可能含有这种类型的字符串,我们的特征便不再是唯一的,这个时候,我们便需要一个新的唯一特征。
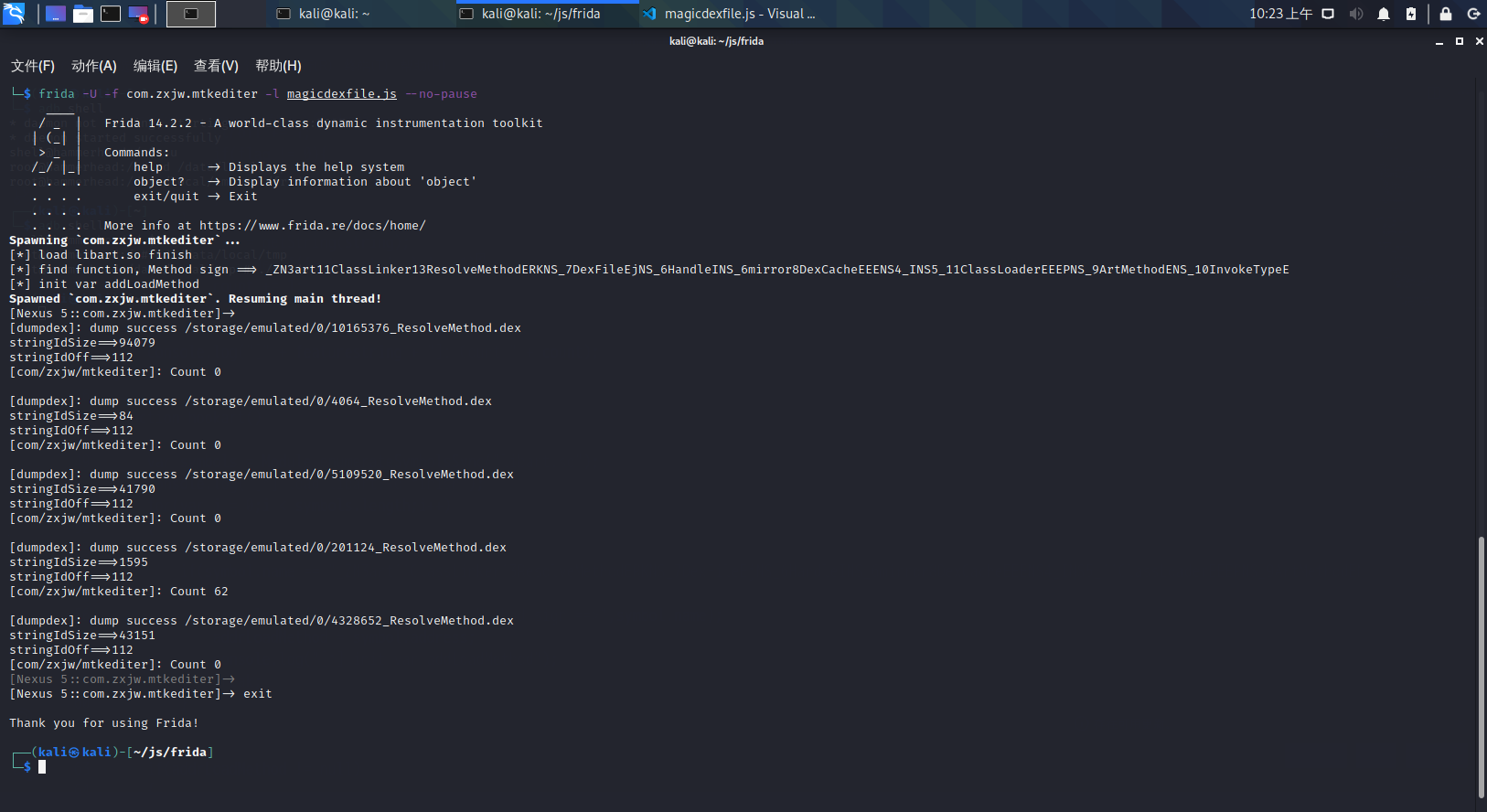
在一个APP中,我们通常所写的类不止一个,而是很多个,那么便含有很多个上述所说的特征;而写过加壳程序都应该知道,我们在加壳程序中,最多也就拉起那么一个或几个类。那么,通过这种数量上的差异同样也可以作为唯一特征,以下是脱壳改进脚本脚本运行截图:
三、其他识别方法
1、其他字符串,通过将app安装运行手动观察到的,但是这种方式有点碰运气,只有直接写入到java源码中的才能作为特征,写入到strings.xml便不得行。如下截图(ps:为直接写入到java中的,可以在字符串池中解析出来的),解析字符串池:
2、布局xml文件名、控件名(ps:这种可行性太低,在这里筹字数的,基本不能作为特征)
3、布局、控件资源ID,这些16进制搜索整个DEX文件也可以作为特征,但是有很其他DEX文件装车的可能。
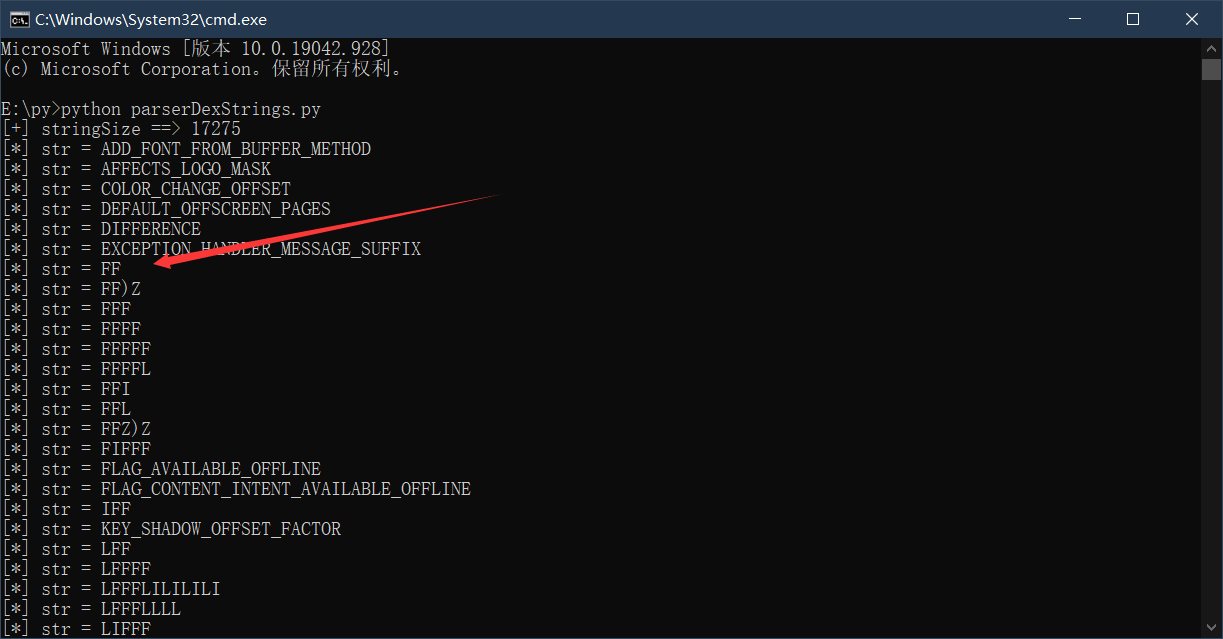
4、方法原型,例如一个方法返回值是Double,参数也是Double,那个这个方法原型便是FF,而这个方法原型一定存在于字符串池中,但是也不是很靠谱这个特征,原因如下截图所示(而且还需要知道一个方法才行):
5、对DEX做更深入解析,解析出更多特征,而不仅仅止于解析出字符串池,感兴趣的研究一下,但第一个依靠类名便够用了。

