node 写的简单爬虫(三)
异步爬取数据
先引入
var async = require('async');
然后同样上代码
var topicUrls = [];//存所有地址 http.get(url,function(res){ var html=''; res.on('data',function(data){ html +=data }) res.on('end', function() { var $=cheerio.load(html); $("#subShowContent1_news2 h2 a").each((iten,i)=>{ var href=$(i).attr('href'); topicUrls.push(href); }) console.log(topicUrls); // 控制最大并发数为5,异步执行函数 async.mapLimit(topicUrls,5,function(myurl, callback){ //console.log(myurl); fetchUrl(myurl, callback); },function (err, result) { console.log(result); }); }); }).on('error', function() { console.log("获取数据出错!") }); function fetchUrl(myurl,callback) { var fetchStart = new Date().getTime(); http.get(myurl,function(res){ var html=''; res.on('data',function(data){ html +=data }) res.on('end', function() { var $=cheerio.load(html); $("#article").each((iten,i)=>{ console.log($(i).text()); }) console.log("数据加载完毕"); }); }).on('error', function() { console.log("获取数据出错!") }); }
结果显示如下
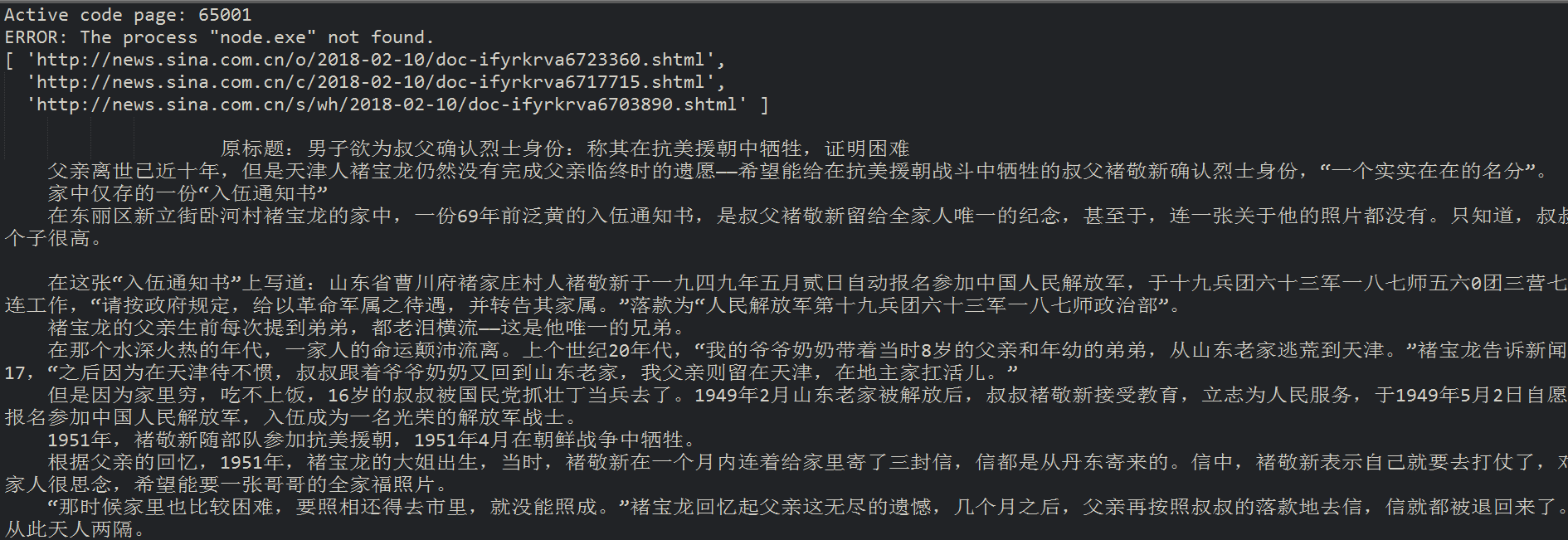
记录生活中的点点滴滴!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号