
RocketMQ 知识点
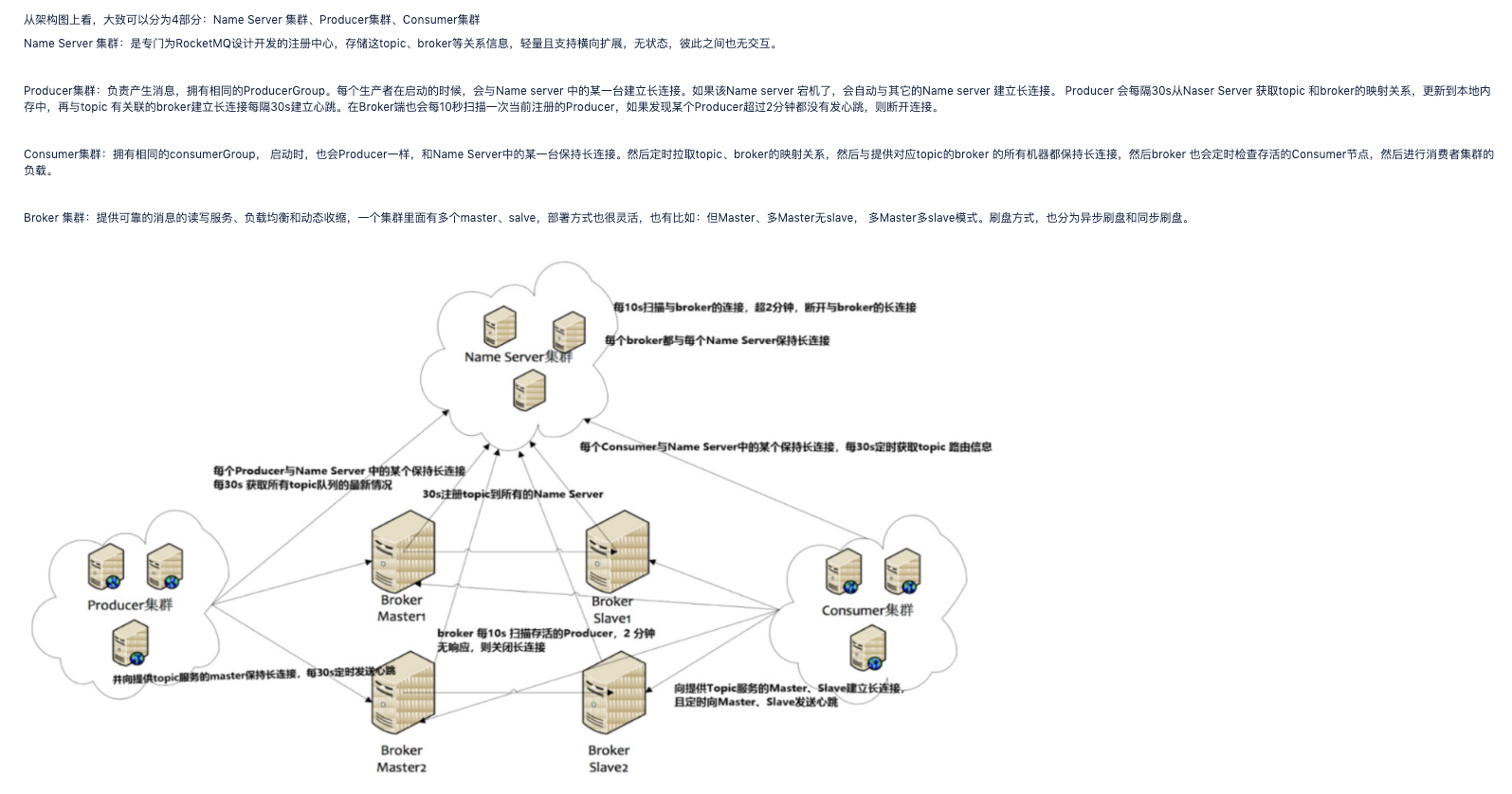
参考源码: https://github.com/apache/rocketmq/tree/master/docs/cn
3大流行MQ对比 : https://www.cnblogs.com/snow-man/p/10062394.html
1、多个mq如何选型?
选择比较流行并且有一定社区活跃度的产品,遇到Bug的几率会非常低。使用过程中的问题,网上基本都会有解决方案。
1.消息的可靠传递:确保不丢消息;
2.Cluster:支持集群,确保不会因为某个节点宕机导致服务不可用,当然也不能丢消息。
3.性能:具备足够好的性能,能满足绝大多数场景的性能要求。
| MQ | 描述 |
|---|---|
| RabbitMQ | erlang开发,对消息堆积的支持并不好,当大量消息积压的时候,会导致 RabbitMQ 的性能急剧下降。每秒钟可以处理几万到十几万条消息。编程语言是非常小众的语言而且不易学习 |
| RocketMQ | java开发,面向互联网集群化功能丰富,对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,每秒钟大概能处理几十万条消息。 |
| Kafka | Scala开发,面向日志功能丰富,性能最高。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。所以,Kafka 不太适合在线业务场景(设计上大量使用了批量和异步的思想,这种设计使得 Kafka 能做到超高的性能。但是因为这种异步批量的设计,他的同步收发消息的响应时延比较高,因为
很多地方都会使用这种“先攒一波再一起处理”的设计). |
| ActiveMQ | java开发,简单,稳定,性能不如前面三个。小型系统用也ok,但是不推荐。推荐用互联网主流的。 |
3、为什么要使用MQ?
优点: 解耦、异步、削峰,提升系统吞吐量
缺点: 系统可用性降低;系统复杂性增加
4、RocketMQ由哪些角色组成,每个角色作用和特点是什么?
| 角色 | 作用 |
|---|---|
| Nameserver | 无状态,动态列表;这也是和zookeeper的重要区别之一。zookeeper是有状态的。 |
| Producer | 消息生产者,负责发消息到Broker。 |
| Broker | 就是MQ本身,负责收发消息、持久化消息等。 |
| Consumer | 消息消费者,负责从Broker上拉取消息进行消费,消费完进行ack。 |
5、RocketMQ中的Topic和JMS的queue有什么区别?
queue就是来源于数据结构的FIFO队列。而Topic是个抽象的概念,每个Topic底层对应N个queue,而数据也真实存在queue上的。
6、RocketMQ Broker中的消息被消费后会立即删除吗?
不会,每条消息都会持久化到CommitLog中,每个Consumer连接到Broker后会维持消费进度信息,当有消息消费后只是当前Consumer的消费进度(CommitLog的offset)更新了。
追问:那么消息会堆积吗?什么时候清理过期消息?
默认72小时后会删除不再使用的CommitLog文件
- 检查这个文件最后访问时间
- 判断是否大于过期时间
- 指定时间删除,默认凌晨4点
7、RocketMQ消费模式有几种?
消费模型由Consumer决定,消费维度为Topic。
- 集群消费
1.一条消息只会被同Group中的一个Consumer消费
2.多个Group同时消费一个Topic时,每个Group都会有一个Consumer消费到数据
- 广播消费
消息将对一 个Consumer Group 下的各个 Consumer 实例都消费一遍。即即使这些 Consumer 属于同一个Consumer Group ,消息也会被 Consumer Group 中的每个 Consumer 都消费一次。
8、消费消息是push还是pull?
RocketMQ没有真正意义的push,都是pull,虽然有push类,但实际底层实现采用的是长轮询机制,即拉取方式
broker端属性 longPollingEnable 标记是否开启长轮询。默认开启
源码如下:
// {@link org.apache.rocketmq.client.impl.consumer.DefaultMQPushConsumerImpl#pullMessage()}
// 看到没,这是一只披着羊皮的狼,名字叫PushConsumerImpl,实际干的确是pull的活。
// 拉取消息,结果放到pullCallback里
this.pullAPIWrapper.pullKernelImpl(pullCallback);
追问:为什么要主动拉取消息而不使用事件监听方式?
事件驱动方式是建立好长连接,由事件(发送数据)的方式来实时推送。
如果broker主动推送消息的话有可能push速度快,消费速度慢的情况,那么就会造成消息在consumer端堆积过多,同时又不能被其他consumer消费的情况。而pull的方式可以根据当前自身情况来pull,不会造成过多的压力而造成瓶颈。所以采取了pull的方式。
9、broker如何处理拉取请求的?
Consumer首次请求Broker
- Broker中是否有符合条件的消息
- 有 ->
- 响应Consumer
- 等待下次Consumer的请求
- 没有
- DefaultMessageStore#ReputMessageService#run方法
- PullRequestHoldService 来Hold连接,每个5s执行一次检查pullRequestTable有没有消息,有的话立即推送
- 每隔1ms检查commitLog中是否有新消息,有的话写入到pullRequestTable
- 当有新消息的时候返回请求
- 挂起consumer的请求,即不断开连接,也不返回数据
- 使用consumer的offset,
10、RocketMQ如何做负载均衡?
通过Topic在多Broker中分布式存储实现。
producer端
发送端指定message queue发送消息到相应的broker,来达到写入时的负载均衡
- 提升写入吞吐量,当多个producer同时向一个broker写入数据的时候,性能会下降
- 消息分布在多broker中,为负载消费做准备
默认策略是随机选择:
- producer维护一个index
- 每次取节点会自增
- index向所有broker个数取余
- 自带容错策略
其他实现:
- SelectMessageQueueByHash
- hash的是传入的args
- SelectMessageQueueByRandom
- SelectMessageQueueByMachineRoom 没有实现
也可以自定义实现MessageQueueSelector接口中的select方法
MessageQueue select(final List<MessageQueue> mqs, final Message msg, final Object arg);
consumer端
采用的是平均分配算法来进行负载均衡。
其他负载均衡算法
平均分配策略(默认)(AllocateMessageQueueAveragely) 环形分配策略(AllocateMessageQueueAveragelyByCircle) 手动配置分配策略(AllocateMessageQueueByConfig) 机房分配策略(AllocateMessageQueueByMachineRoom) 一致性哈希分配策略(AllocateMessageQueueConsistentHash) 靠近机房策略(AllocateMachineRoomNearby)
追问:当消费负载均衡consumer和queue不对等的时候会发生什么?
Consumer和queue会优先平均分配,如果Consumer少于queue的个数,则会存在部分Consumer消费多个queue的情况,如果Consumer等于queue的个数,那就是一个Consumer消费一个queue,如果Consumer个数大于queue的个数,那么会有部分Consumer空余出来,白白的浪费了。
11、消息重复消费
影响消息正常发送和消费的重要原因是网络的不确定性。
引起重复消费的原因
- ACK
正常情况下在consumer真正消费完消息后应该发送ack,通知broker该消息已正常消费,从queue中剔除
当ack因为网络原因无法发送到broker,broker会认为词条消息没有被消费,此后会开启消息重投机制把消息再次投递到consumer
- 消费模式
在CLUSTERING模式下,消息在broker中会保证相同group的consumer消费一次,但是针对不同group的consumer会推送多次
解决方案
- 数据库表
处理消息前,使用消息主键在表中带有约束的字段中insert
- Map
单机时可以使用map ConcurrentHashMap -> putIfAbsent guava cache
- Redis
分布式锁搞起来。
12、如何让RocketMQ保证消息的顺序消费
你们线上业务用消息中间件的时候,是否需要保证消息的顺序性?
如果不需要保证消息顺序,为什么不需要?假如我有一个场景要保证消息的顺序,你们应该如何保证?
首先多个queue只能保证单个queue里的顺序,queue是典型的FIFO,天然顺序。多个queue同时消费是无法绝对保证消息的有序性的。所以总结如下:
同一topic,同一个QUEUE,发消息的时候一个线程去发送消息,消费的时候 一个线程去消费一个queue里的消息。
追问:怎么保证消息发到同一个queue?
Rocket MQ给我们提供了MessageQueueSelector接口,可以自己重写里面的接口,实现自己的算法,举个最简单的例子:判断i % 2 == 0,那就都放到queue1里,否则放到queue2里。

for (int i = 0; i < 5; i++) {
Message message = new Message("orderTopic", ("hello!" + i).getBytes());
producer.send(
// 要发的那条消息
message,
// queue 选择器 ,向 topic中的哪个queue去写消息
new MessageQueueSelector() {
// 手动 选择一个queue
@Override
public MessageQueue select(
// 当前topic 里面包含的所有queue
List<MessageQueue> mqs,
// 具体要发的那条消息
Message msg,
// 对应到 send() 里的 args,也就是2000前面的那个0
Object arg) {
// 向固定的一个queue里写消息,比如这里就是向第一个queue里写消息
if (Integer.parseInt(arg.toString()) % 2 == 0) {
return mqs.get(0);
} else {
return mqs.get(1);
}
}
},
// 自定义参数:0
// 2000代表2000毫秒超时时间
i, 2000);
}
13、RocketMQ如何保证消息不丢失
首先在如下三个部分都可能会出现丢失消息的情况:
- Producer端
- Broker端
- Consumer端
13.1、Producer端如何保证消息不丢失
- 采取send()同步发消息,发送结果是同步感知的。
- 发送失败后可以重试,设置重试次数。默认3次。
producer.setRetryTimesWhenSendFailed(10);
- 集群部署,比如发送失败了的原因可能是当前Broker宕机了,重试的时候会发送到其他Broker上。
13.2、Broker端如何保证消息不丢失
- 修改刷盘策略为同步刷盘。默认情况下是异步刷盘的。
flushDiskType = SYNC_FLUSH
- 集群部署,主从模式,高可用。
13.3、Consumer端如何保证消息不丢失
- 完全消费正常后在进行手动ack确认。
14、rocketMQ的消息堆积如何处理
下游消费系统如果宕机了,导致几百万条消息在消息中间件里积压,此时怎么处理?
你们线上是否遇到过消息积压的生产故障?如果没遇到过,你考虑一下如何应对?
首先要找到是什么原因导致的消息堆积,是Producer太多了,Consumer太少了导致的还是说其他情况,总之先定位问题。
然后看下消息消费速度是否正常,正常的话,可以通过上线更多consumer临时解决消息堆积问题。
RocketMQ 中,一个队列只会被一个消费者消费。一个消费者可以小费多个队列。一个topic默认4个队列。
1.判断堆积原因:
1.1 生产者太快:使用限流降级方案降低速度。
1.2消费者太慢:
增加consumer消费者实例(同时也要增加主题队列数量);提高consumer消费并行线程(参数 consumeThreadMin、consumeThreadMax实现);
优化消息消费流程、支持批量消费方式;
跳过非重要消息
追问:如果Consumer和Queue不对等,上线了多台也在短时间内无法消费完堆积的消息怎么办?
- 准备一个临时的topic
- queue的数量是堆积的几倍
- queue分布到多Broker中
- 上线一台Consumer做消息的搬运工,把原来Topic中的消息挪到新的Topic里,不做业务逻辑处理,只是挪过去
- 上线N台Consumer同时消费临时Topic中的数据
- 改bug
- 恢复原来的Consumer,继续消费之前的Topic
追问:堆积时间过长消息超时了?
RocketMQ中的消息只会在commitLog被删除的时候才会消失,不会超时。也就是说未被消费的消息不会存在超时删除这情况。
追问:堆积的消息会不会进死信队列?
不会,消息在消费失败后会进入重试队列(%RETRY%+ConsumerGroup),18次(默认18次,网上所有文章都说是16次,无一例外。但是我没搞懂为啥是16次,这不是18个时间吗 ?)才会进入死信队列(%DLQ%+ConsumerGroup)。
源码如下:
public class MessageStoreConfig {
// 每隔如下时间会进行重试,到最后一次时间重试失败的话就进入死信队列了。
private String messageDelayLevel = "1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h";
}
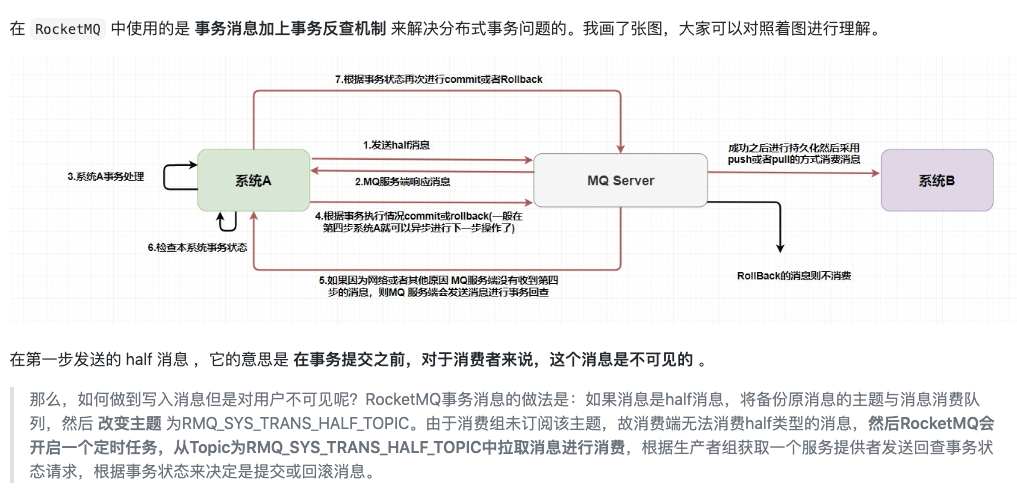
15、RocketMQ在分布式事务支持这块机制的底层原理?
你们用的是RocketMQ?RocketMQ很大的一个特点是对分布式事务的支持,你说说他在分布式事务支持这块机制的底层原理?
分布式系统中的事务可以使用TCC(Try、Confirm、Cancel)、2pc来解决分布式系统中的消息原子性
RocketMQ 4.3+提供分布事务功能,通过 RocketMQ 事务消息能达到分布式事务的最终一致
RocketMQ实现方式:
**Half Message:**预处理消息,当broker收到此类消息后,会存储到RMQ_SYS_TRANS_HALF_TOPIC的消息消费队列中
**检查事务状态:**Broker会开启一个定时任务,消费RMQ_SYS_TRANS_HALF_TOPIC队列中的消息,每次执行任务会向消息发送者确认事务执行状态(提交、回滚、未知),如果是未知,Broker会定时去回调在重新检查。
**超时:**如果超过回查次数,默认回滚消息。
也就是他并未真正进入Topic的queue,而是用了临时queue来放所谓的half message,等提交事务后才会真正的将half message转移到topic下的queue。
16、如果让你来动手实现一个分布式消息中间件,整体架构你会如何设计实现?
我个人觉得从以下几个点回答吧:
- 需要考虑能快速扩容、天然支持集群
- 持久化的姿势
- 高可用性
- 数据0丢失的考虑
- 服务端部署简单、client端使用简单
17、看过RocketMQ 的源码没有。如果看过,说说你对RocketMQ 源码的理解?
要真让我说,我会吐槽蛮烂的,首先没任何注释,可能是之前阿里巴巴写了中文注释,捐赠给apache后,apache觉得中文注释不能留,自己又懒得写英文注释,就都给删了。里面比较典型的设计模式有单例、工厂、策略、门面模式。单例工厂无处不在,策略印象深刻比如发消息和消费消息的时候queue的负载均衡就是N个策略算法类,有随机、hash等,这也是能够快速扩容天然支持集群的必要原因之一。持久化做的也比较完善,采取的CommitLog来落盘,同步异步两种方式。
18、高吞吐量下如何优化生产者和消费者的性能?
开发
- 同一group下,多机部署,并行消费
- 单个Consumer提高消费线程个数
- 批量消费
- 消息批量拉取
- 业务逻辑批量处理
运维
- 网卡调优
- jvm调优
- 多线程与cpu调优
- Page Cache
19、再说说RocketMQ 是如何保证数据的高容错性的?
- 在不开启容错的情况下,轮询队列进行发送,如果失败了,重试的时候过滤失败的Broker
- 如果开启了容错策略,会通过RocketMQ的预测机制来预测一个Broker是否可用
- 如果上次失败的Broker可用那么还是会选择该Broker的队列
- 如果上述情况失败,则随机选择一个进行发送
- 在发送消息的时候会记录一下调用的时间与是否报错,根据该时间去预测broker的可用时间
其实就是send消息的时候queue的选择。源码在如下:
org.apache.rocketmq.client.latency.MQFaultStrategy#selectOneMessageQueue()
20、任何一台Broker突然宕机了怎么办?
Broker主从架构以及多副本策略。Master收到消息后会同步给Slave,这样一条消息就不止一份了,Master宕机了还有slave中的消息可用,保证了MQ的可靠性和高可用性。而且Rocket MQ4.5.0开始就支持了Dlegder模式,基于raft的,做到了真正意义的HA。
RocketMQ HA机制(主从同步): https://cloud.tencent.com/developer/article/1458089
21、Broker把自己的信息注册到哪个NameServer上?
这么问明显在坑你,因为Broker会向所有的NameServer上注册自己的信息,而不是某一个,是每一个,全部!
22、同步落盘怎么才能快
- 使用 FileChannel + DirectBuffer 池,使用堆外内存,加快内存拷贝
- 使用数据和索引分离,当消息需要写入时,使用 commitlog 文件顺序写,当需要定位某个消息时,查询index 文件来定位,从而减少文件IO随机读写的性能损耗
23、RocketMQ 不使用 ZooKeeper 作为注册中心的原因,以及自制的 NameServer 优缺点?
- ZooKeeper 作为支持顺序一致性的中间件,在某些情况下,它为了满足一致性,会丢失一定时间内的可用性,RocketMQ 需要注册中心只是为了发现组件地址,在某些情况下,RocketMQ 的注册中心可以出现数据不一致性,这同时也是 NameServer 的缺点,因为 NameServer 集群间互不通信,它们之间的注册信息可能会不一致
- 另外,当有新的服务器加入时,NameServer 并不会立马通知到 Produer,而是由 Produer 定时去请求 NameServer 获取最新的 Broker/Consumer 信息(这种情况是通过 Producer 发送消息时,负载均衡解决)

