数据挖掘之关联规则Apriori算法
一、Aoriori原始算法:
频繁挖掘模式与关联规则
关联规则两个基本的指标(假设有事务A和事务B)
1、支持度(suport):计算公式如下

2、置信度(confidence):
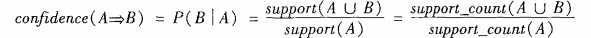
关联规则的挖掘过程:
1、设定最小支持度阈值,找出所有的频繁项集且每个出现的次数要大于等于最小支持度阈值。
2、由频繁项集产生强关联规则:这些规则必须满足最小支持度和最小置信度。
先验性质:频繁项集的所有非空子集也一定是频繁的
Apriori算法的两大步骤:连接步,剪枝步。

举个例子:数据集具有9条事务数据

先设置最小支持度阈值为2;然后我们逐层找出有效的频繁项集
首先扫描整个数据集共有5个独立的项集分别为[I1, I2, I3, I4, I5],然后对齐进行计数,查看是否满足阈值。
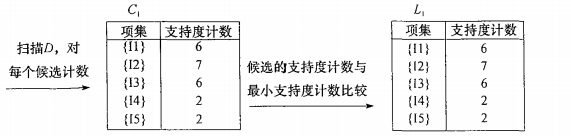
在集合L1 中过滤掉无效项集后,由 L1进行组合产生L2,在对L2 中的每个项集进行计数,过滤掉无效项集
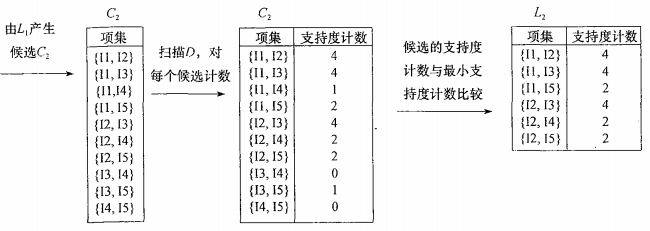
有L2进行组合产生L3,再进行计数(此步骤以及后面的步骤(如果有的话))要考虑先验性质,降低运算消耗

备注:频繁项集L2 的组合按理说应该是 [[I1,I2,I3], [I1,I2,I5], [I1, I3,I5], [I2, I3, I4], [I2,I3,I5], [I2,I4,I5]],但是根据先验性质,后面四个项集存在子集不是频繁项集,也就是说子集计数小于2,具体如下

迭代到L(n-1) 就停止了。
二、提高 Aprioir算法的效率
未完待续......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号