java学习-字符流、转换流、io流中的异常处理、多线程
字符流
字节流读取中文文本问题
问题 : 使用字节输入流,读取了带有中文的文本文件, 且边读边查看文件内容, 最终导致读取中文,出现了乱码问题, 读出的不是完整中文
问题的发生原因 : 每次从文件中读取出一个字节, 而在默认的GBK编码表中, 一个中文占有2个字节, 于是读取文件时, 就将中文两字节拆分读取, 拆分后的字节数据导致了中文无法完整显示问题
解决方案 : 不要按照字节进行读取,需要按照字符进行文件的读取,如此可以解决中文文件边读边看乱码问题
代码
public class Demo01_字节流读中文乱码 { public static void main(String[] args) throws IOException{ // 1. 创建出一个字节输入流 : 绑定一个数据源 FileInputStream fis = new FileInputStream("chinese.txt"); // len表示每次读取到的字节结果 /*int len; while((len = fis.read()) != -1) { System.out.print((char)len); }*/ int len; byte[] b = new byte[2]; while((len = fis.read(b)) != -1) { System.out.print(new String(b,0,len)); } fis.close(); } }
文件内容
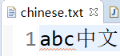
乱码效果:
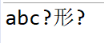
字符流读取文件的原理
通过字符流进行文件读取: 动态读取方式
- 所有文件都是由字节组成
- 当使用字符流读取文件时, 先从文件中读取出一个字节, 判断一下,这一个字节如果是正数, 证明这个字符来自于ASCII编码表中, 直接对应编码表转换成字符; 如果从文件中读取出的一个字节是负数, 就动态向下读取出另外一个字节, 将两个
字符流的使用
- 字符输入流: Reader 字符输入流顶层抽象父类, 需要子类 : FileReader
1) FileReader的构造方法:
FileReader(String path) : 将表示文件路径的path封装在一个字符输入流中, 通过字符输入流可以读取path所表示文件内容
FileReader(File path) : 将表示文件路径的path封装在一个字符输入流中, 通过字符输入流可以读取path所表示文件内容
2) read读取文件功能:
a : read() : 表示每次从文件中读取出一个字符, 返回值类型为int表示这个字符在编码表中对应的整数结果, 如果读取-1,证明文件读取完毕
b : read(char[] ch) : 每次最多能从文件中读取出ch.length个字符, 将读取到的字符内容同步到参数ch数组中, 通过查看ch数组内容, 变相查看文件内容, 返回值类型int, 表示读取到的字符个数, 如果读取-1,证明文件读取完毕
2.字符输出流 : Writer 字符输出流顶层抽象父类, 需要子类 : FileWriter
1) FileWriter的构造方法:
FileWriter(String path) : 将表示文件路径的path封装在一个字符输出流中, 通过字符输出流可以向path所表示文件中写入内容
FileWriter(File path) : 将表示文件路径的path封装在一个字符输出流中, 通过字符输出流可以向path所表示文件中写入内容
字符输入流解决中文乱码
public class Demo02_字符输入流解决中文读取乱码 { public static void main(String[] args) throws IOException{ FileReader fr = new FileReader("chinese.txt"); /* // 表示每次读取到的字符结果 int len; while((len = fr.read()) != -1) { System.out.print((char)len); }*/ // 表示每次读取到的字符个数 int len; char[] ch = new char[4]; while((len = fr.read(ch)) != -1) { System.out.print(new String(ch,0,len)); } fr.close(); } }
字符输出流:
public class Demo03_字符输出流 { public static void main(String[] args) throws IOException{ FileWriter fw = new FileWriter("fileWriter.txt"); // 1. 向文件中写入单个字符 fw.write('a'); // 2. 向文件中写入字符数组 char[] ch = {'A','1','家','中'}; fw.write(ch); // 3. 向文件中写入字符数组一部分 fw.write(ch, 1, 2);// '1','家' // 4. 向文件中写入字符串 String s = "今天挺热"; fw.write(s); // 5. 向文件中写入字符串一部分 fw.write(s, 0, 1);// 今 fw.close(); } }
flush 和close方法
- flush() : 功能表示刷新, 将流资源底层缓冲区中的数据通过刷新, 同步到文件中, 刷新完毕, 流资源可以继续使用
- close() : 功能表示关闭流资源, 在关闭资源之前, 先调用一次flush方法, 将所有的缓冲区数据同步到文件中, 后关闭资源, 流资源通过close关闭后,不能再继续使用
字符高效缓冲流
- 高效字符流 : BufferedReader, BufferedWriter, 两个流资源都是包装类, 就是将普通字符流包装成高效字符流
- 高效原理:
1) BufferedReader : 创建出一个BufferedReader 流资源对象时, 系统底层自动创建出一个大小为8192的字符数组, 当使用read方法从文本文件中读取内容, 一次性最多读出8192个字符,将读到的内容放置到底层字符数组中, 接下来从字符数组中继续读取内容, 数组读取效率很高, 如果8192读取完毕,下一次再使用read还是最多读取出8192,直到文件读取完毕
2) BufferedWriter : 创建出一个BufferedWriter 流资源对象时, 系统底层自动创建出一个大小为8192的字符数组, 每次向文件中写入内容,都是自动写入到底层字符数组中, 如果8129数组写满,自动将数组内容同步到文件中, 如果没有写满8192,可以使用flush或者close方法, 将缓冲区数据同步到文件中, 减少与磁盘交互, 提高IO读写效能
代码
public class Demo06_字符高效缓冲流 { public static void main(String[] args) throws IOException{ // 1. 绑定数据源 : 创建出一个字符输入流 BufferedReader br = new BufferedReader(new FileReader("fileWriter.txt")); // 2. 绑定数据目的 : 创建出一个字符输出流 BufferedWriter bw = new BufferedWriter(new FileWriter("fileWriterCopy.txt")); // 3. 边读边写 // len表示每次读取到的字符结果 int len; while((len = br.read()) != -1) { bw.write(len); } bw.close(); br.close(); } }
字符高效缓冲中的特有方法
- BufferedReader : 高效字符输入流, 有一个特有方法
readLine() : 每次从文本中读取出一行内容(以回车换标识一行文本), 返回值类型为String类型, 也能实现读取高效性, 如果读取到的结果为null, 证明文件读取完毕
2.BufferedWriter : 高效字符输出流, 有一个特有方法
newLine() : 不区分操作平台(操作系统), 生成一个换行符(回车换行)
转换流
- 编码表:
1) GBK : 中国标准码表, 兼容了ASCII编码表, 包含了所有的中文文字, 一个英文字符占有1个字节大小, 一个中文字符占有2个字节大小
2) UTF-8 : 万国编码表, 兼容了ASCII编码表, 还汇总了世界上各个国家语言文字, 一个英文字符占有1个字节大小, 一个中文字符占有3个字节大小
2.创建出一个txt文件, 修改其编码集为UTF-8
3.当有一个UTF-8.txt文件(UTF-8编码), 这个文件中有2个中文文字,每一个中文占有3字节, 使用普通字节流资源进行文件复制, 想将UTF-8.txt文件中的内容复制到GBK.txt(GBK编码)文件中, 发现遇到问题 : 字节进行完全复制之后, GBK文件将6字节通过编码表转换成3个中文, 导致复制文件与源文件内容不一致
4.为了解决不同编码集文件读写问题, 可以使用转换流
1) InputStreamReader : 是Reader的一个子类, 字节到字符的桥梁, 主要用于读取文件内容,是一个输入流
InputStreamReader(InputStream in, String charsetName) :
a : 使用in字节输入流从文件中读取出字节数据
b : 将字节数据通过给出的指定的编码集 “charsetName”, 将字节转换成字符
2) OutputStreamWriter : 是Writer的一个子类, 字符到字节的桥梁, 主要用于将数据内容写入到文件中, 是输出流
OutputStreamWriter(OutputStream out, String charsetName) :
a : 将获取到的字符先通过给出的编码集 “charsetName”, 转换成字节
b : 将字节通过out字节输出流写入到目标文件中
注意 : 使用转换流时, 给出的编码集需要与目前正在读写文件对应的编码集保持一致
代码
public class Demo09_转换流 { public static void main(String[] args) throws IOException{ // 1. 绑定一个数据源 : 创建出一个转换输入流 InputStreamReader isr = new InputStreamReader(new FileInputStream("UTF-8.txt"), "UTF-8"); // 2.绑定一个数据目的 : 创建出一个转换输出流 OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("GBK.txt"),"GBK"); int len; while((len = isr.read()) != -1) { osw.write(len); } osw.close(); isr.close(); } }
IO流中异常标准处理方式
- 因为最标准的IO流的异常处理, 比较繁琐, 因此JDK7版本, 对于流资源有全新的异常处理语法结构
- 语法结构:
try(
流资源创建;
){
可能会发生问题的代码;
}catch(异常类型 变量){
对于流资源异常的处理方式;
}
3.解释:
在try小括号中, 创建出需要使用的IO流资源
这些资源,不需要close手动关闭资源, try小括号在流资源使用完毕之后, 自动关闭资源
异常标准处理代码
ublic class Demo11_JDK7IO异常新处理方式 { public static void main(String[] args) { try( FileInputStream fis = new FileInputStream("Info.txt"); FileOutputStream fos = new FileOutputStream("Infocopy.txt"); ){ int len; while((len = fis.read()) != -1) { fos.write(len); } }catch (IOException e) { e.printStackTrace(); } } }
多线程
线程的相关概念
- 程序 : 就是数据和代码逻辑的集合, 例如每天写的.java代码,就是程序, 存储在固定路径下
- 进程 : 在内存中正在运行程序,称为进程
- 线程 : 在内存中运行的程序, 代码需要有运行通道, 而代码中每一条独立运行通道称为1个线程, 如果代码中有多条执行通道, 称这个代码是多线程代码实现方式
- 并行: 有多个程序或者代码要求同时运行, 并行概念, 硬件设备足够, 可以实现多个程序同时在运行(例如饭店, 有10个客户,点了10道菜, 有10个厨师每一个厨师做一道菜
- 并发: 有多个程序或者代码要求同时运行, 但是硬件设备不能支持同时都在运行, 于是CPU在多个应用程序之间来回切换运行, 每一个应用程序给一定时间, 因为CPU处理效率非常快, 因此外界感受不到, 多个应用来回切换运行
(例如饭店, 有10个客户,点了10道菜, 有1个厨师起10口锅, 一个人在10个菜之间来回切换去抄)
多线程实现的第一种方式
- 继承Thread类
- 实现多线程的步骤:
1) 自定义出一个类, 成为Thread类型的子
2) 自定义类中重写父类Thread中的run方法功能, 将需要独立在线程中运行的代码写在run方法中
3) 创建出一个自定义线程类对象, 准备开辟一个新线程
4) 调用Thread类中继承来的方法功能:
start() 功能表示开启一个线程
a : 为线程开辟一个独立运行通道
b : 让JVM虚拟机调用当前线程中run方法, 让run方法在独立线程通道中运行
注意 : 多线程并发运行机制, 多个线程同时竞争CPU资源, CPU对于线程的执行具有很大的随机性
代码
public class MyFirstThread extends Thread { // 2. 重写父类Thread中的run方法 public void run() { for(int i= 1; i <= 10;i++) { System.out.println("run----"+i); } } }
public class TestThread { public static void main(String[] args) { // 1. main方法本身就是一个线程, 就叫做主线程,独立的代码运行通道 // 3) 创建出一个自定义线程类对象 MyFirstThread mft = new MyFirstThread(); // 4) 开启线程, 有了第二个线程, 与main方法彼此独立运行 mft.start(); for(int i = 1; i <= 10; i++) { System.out.println("main---"+i); } } }
多线程实现的第二种方式
- 实现Runnable接口:
想成为一个线程类型, 可以作为Runnable接口的实现类, 连Thread线程类都是Runnable实现类
2.实现步骤:
1) 创建出一个自定义类, 成为Runnable 的实现类
2) 需要重写run方法, 将需要独立在线程中运行的代码写在run方法中
3) 创建出一个自定义线程类对象
4) 依靠Thread线程类, 将一个Runnable接口的实现类包装成一个线程类,使用Thread中的构造如下:
5) 依靠Thread中的start方法功能开启线程:
运行的是构造参数中的线程实现类中的run方法功能
注意 : 每一个线程只能调用start方法一次, 同一个线程多次启动, 报错 : IllegalThreadStateException 非法的线程状态异常
代码
public class MySecondThread implements Runnable { @Override public void run() { for(int i = 1; i <= 10; i++) { System.out.println("runnable---"+i); } } }
public class TestThread { public static void main(String[] args) { // 1. main方法本身就是一个线程, 就叫做主线程,独立的代码运行通道 // 3) 创建出一个自定义线程类对象 MyFirstThread mft = new MyFirstThread(); // 4) 开启线程, 有了第二个线程, 与main方法必须独立 mft.start(); mft.start(); // 使用Runnable实现类开启一个独立线程 MySecondThread mst = new MySecondThread(); // 将线程实现类封装在一个Thread类型中 Thread t = new Thread(mst); // 开启线程, 有了第三个线程, 与main, 与mft线程, 互相独立, 共同竞争CPU资源 t.start(); for(int i = 1; i <= 10; i++) { System.out.println("main---"+i); } } }
Thread线程类中的常用功能
获取和设置线程名称
- getName() : 获取当前线程名称, 返回值类型String类型
线程有默认命名 : Thread-0, Thread-1...
2.setName(String name) : 将当前线程名称设置为参数name、
3.Thread类型的构造方法可以设置线程名称
1) Thread(String name)
2) Thread(Runnable run, String name)
给线程通过构造方法设置其名称为name
守护线程
- 象棋 :
1) 守护线程 : 兵, 炮, 车, 马(守护线程), 存在都是为了守护将,帅
2) 非守护线程 : 将, 帅, 属于非守护线程, 只需要保护好自己运行即可

当使用setDaemon方法, 将参数设置为true, 那么证明将当前线程设置为守护线程
守护线程执行机制 : 如果代码中所有的非守护线程都执行完毕, 那么守护线程直接运行结束

 浙公网安备 33010602011771号
浙公网安备 33010602011771号