python 破解58字体反爬
1、选择网址58同城
2、按F12查看元素
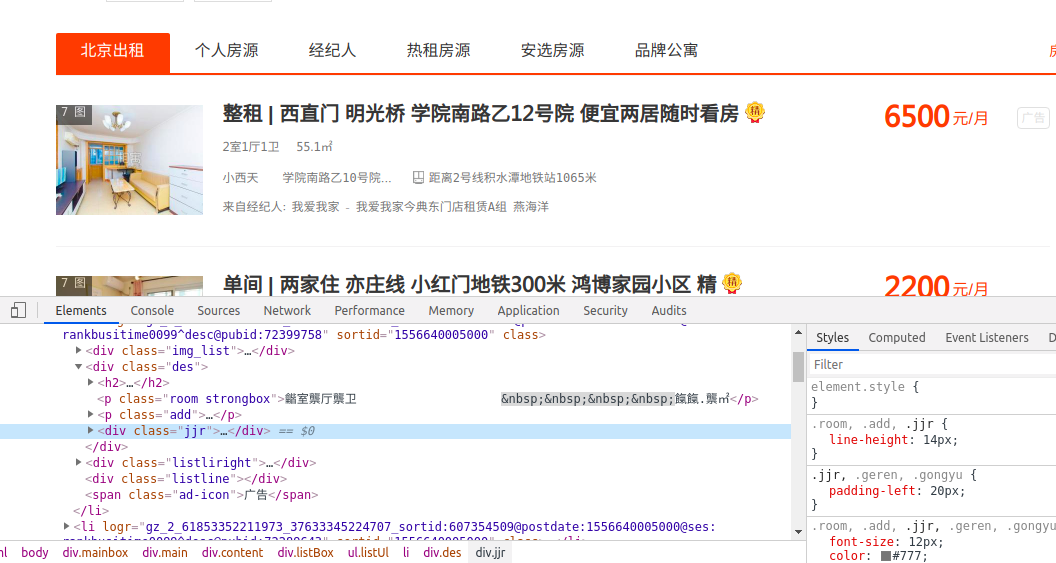
3、将鼠标指到数字上发现如下所示

数字显示乱码
4、发现乱码前的class标签和旁边style的标签一样
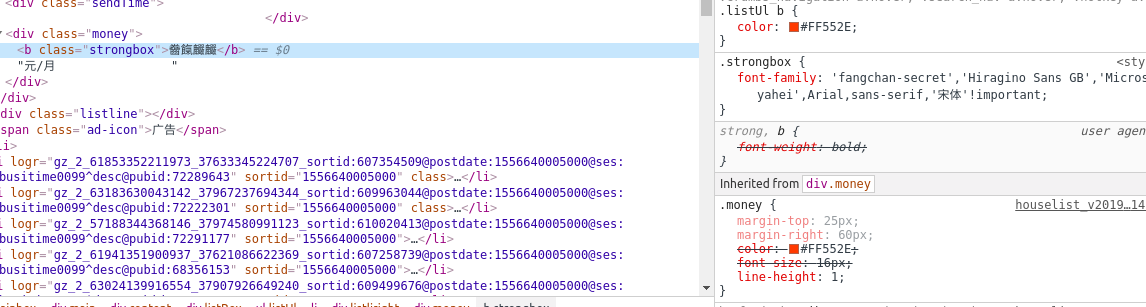
我搜索一下fangchan-secret

发现有很长的字符串前面有base64,断定这是base64加密,然后解密这段字符串就能实现反爬
代码如下:
1、获取整个页面
def get_html(self,url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36', } html = requests.get(url, headers=headers).text return html
2、解析页面获取base64加密的字符串从进.xml文件中
def get_xml(self,html): base64_str = re.search(r'base64,(.*?)\)', html, re.S).group(1) base64_str_decode = base64.b64decode(base64_str) filr_name = "58.ttf" with open(filr_name, 'wb') as f: f.write(base64_str_decode) font = TTFont('58.ttf') # 打开本地的ttf文件 font.saveXML('58.xml') # 转换成xml
3、打开xml文件
4、解析cmap中的内容得到字典
def get_dict(self,html): base64_str = re.search(r'base64,(.*?)\)', html, re.S).group(1) base64_str_decode = base64.b64decode(base64_str) filr_name = "58.ttf" with open(filr_name, 'wb') as f: f.write(base64_str_decode) font = TTFont('58.ttf') # 打开本地的ttf文件 font.saveXML('58.xml') # 转换成xml cmap = font['cmap'].getBestCmap() newdict = {} for i in cmap: pat = re.compile(r'(\d+)') values = int (re.search(pat,cmap[i])[1]) - 1 keys = hex(i) newdict[keys] = values return newdict
5、字典内容

见贤思齐焉见不贤而内自省也
