
爬虫大作业
一、目的 :
爬取博客园博问上160页每页25条帖子标题
二、python爬取数据
博问主页:https://q.cnblogs.com/list/unsolved?page=1
第二页:https://q.cnblogs.com/list/unsolved?page=2 以此类推……
可得160页bkyUrl地址
for i in range(1,161):
bkyUrl = "https://q.cnblogs.com/list/unsolved?page={}".format(i)
通过浏览器查看博问主页元素:
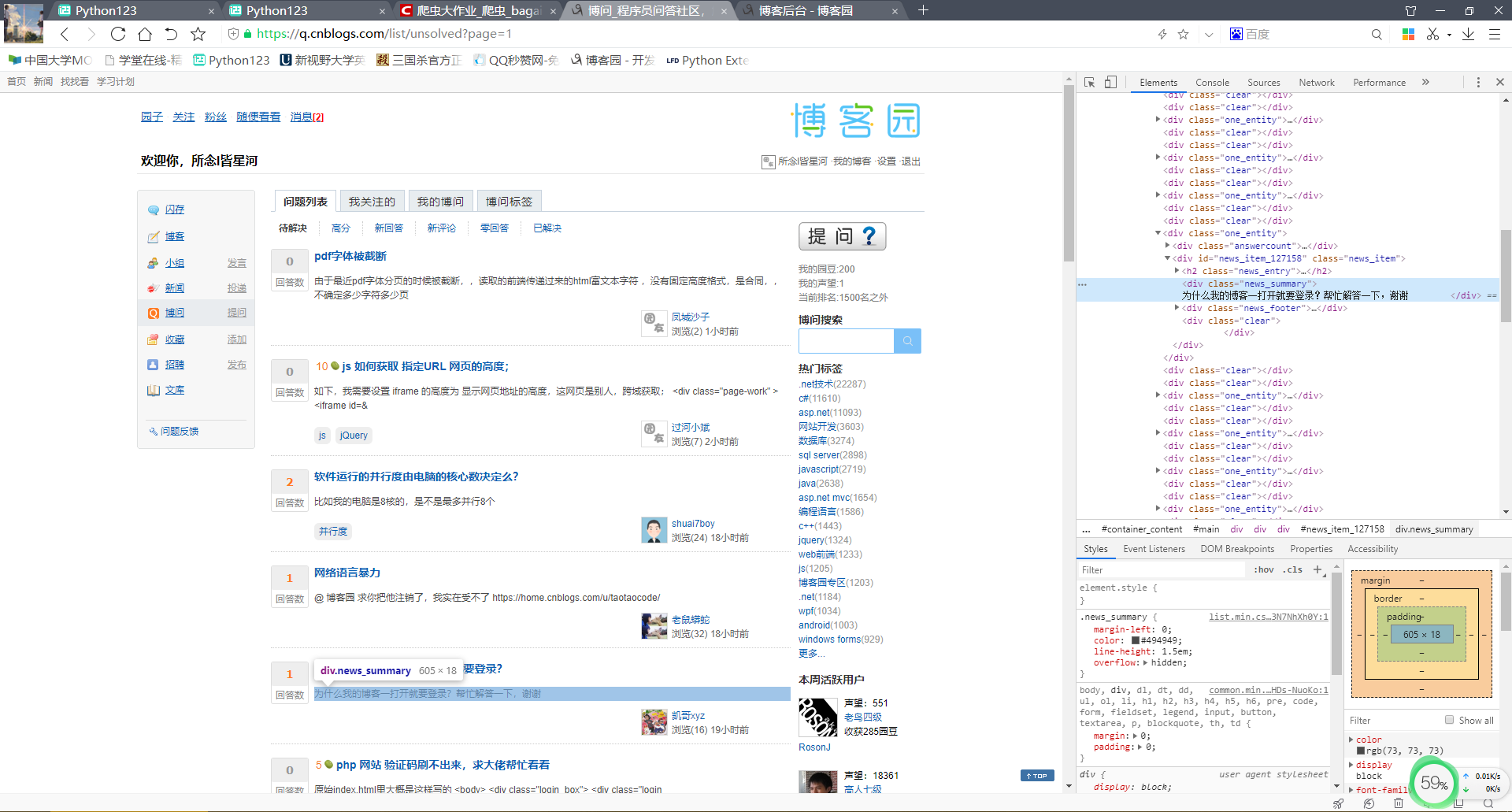
观察可得在主体div类为.left_sidebar标签下有25个标签h2、h2标签内a标签文本即为各博问贴子标题
因此可得getpagetitle函数获取每页25条博问贴子标题:
def getpagetitle(bkyUrl):
time.sleep(1)
print(bkyUrl)
res1 = requests.get(bkyUrl)
res1.encoding = 'utf-8'
soup1 = BeautifulSoup(res1.text, 'html.parser')
item_list = soup1.select(".left_sidebar")[0]
for i in item_list.select("h2"):
title = i.select("a")[0].text
将上述操作整合一起,获取160 * 25 条博文标题
import requests
import time
from bs4 import BeautifulSoup
def addtitle(title):
f = open("test.txt","a",encoding='utf-8')
f.write(title+"\n")
f.close()
def getpagetitle(bkyUrl):
time.sleep(1)
print(bkyUrl)
res1 = requests.get(bkyUrl)
res1.encoding = 'utf-8'
soup1 = BeautifulSoup(res1.text, 'html.parser')
item_list = soup1.select(".left_sidebar")[0]
for i in item_list.select("h2"):
title = i.select("a")[0].text
addtitle(title)
for i in range(160,161):
bkyUrl = "https://q.cnblogs.com/list/unsolved?page={}".format(i)
getpagetitle(bkyUrl)
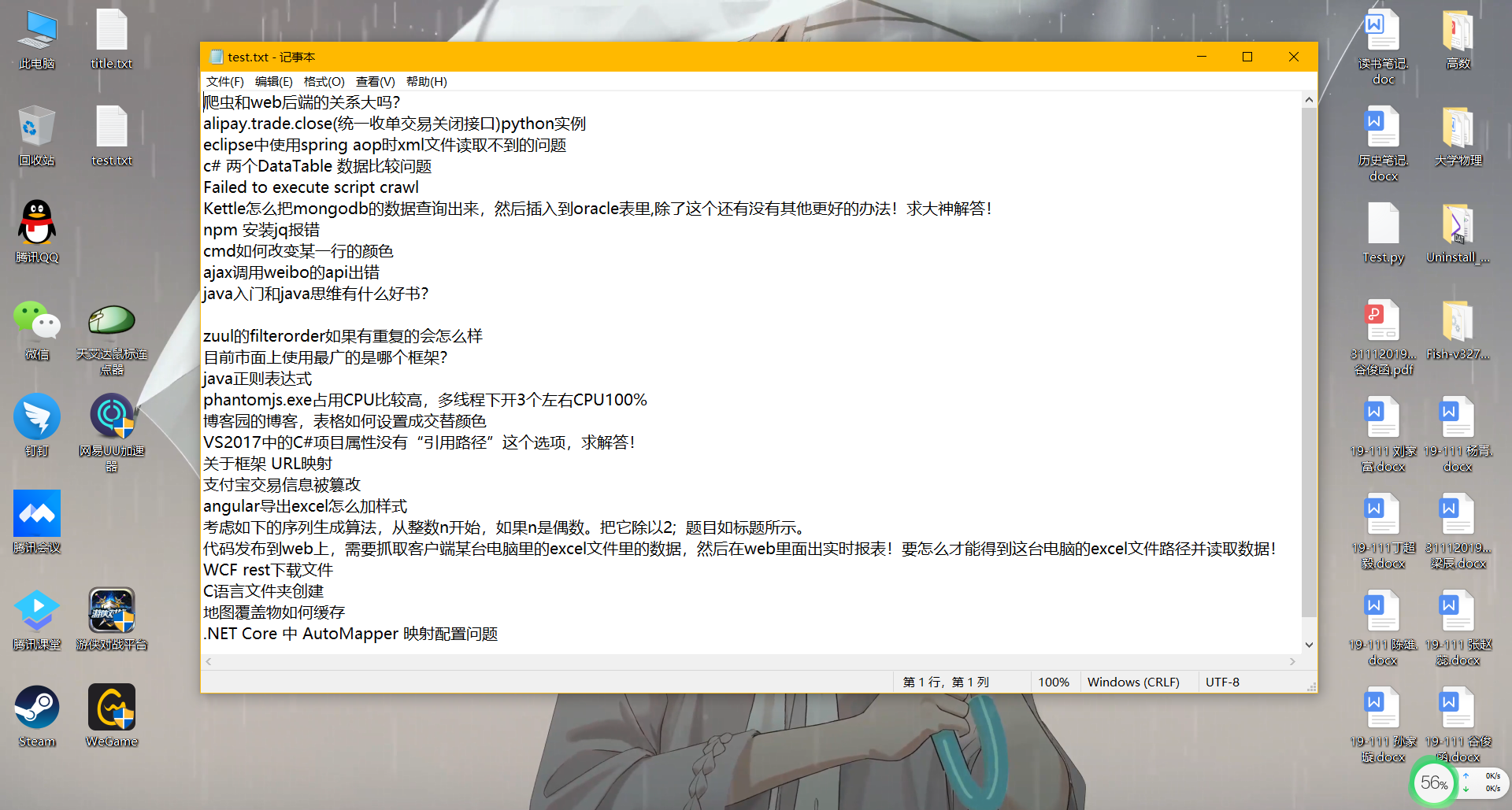
保存标题test.txt文本:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号