OO第三单元总结
OO第三单元总结
梳理JML语言的理论基础、应用工具链情况
JML(Java Modeling Language)是一种行为规范接口语言,通过使用不会被编译的注释形式,和固定关键字的语法,指定Java模块代码的行为。大体上包括以下三种要求:
前置: @requires 子句定义了需要满足的条件。
过程: @assignment 子句定义了可以改变的成员。
后置: @ensure 子句定义了方法要达到的效果。
此外,还有一些比较常用的的语法如下:
@pure 子句表明该方法无副作用,即仅具有查询功能
@constraint 子句定义了状态变化约束
@invariant 子句定义了全过程中的不变式
\nothing 关键词表明该方法对类成员属性不进行修改
\result 关键词代表该方法的返回值
\forall表达式:全称量词修饰的表达式,表示对于给定范围内的元素,每个元素都满足相应的约束。
\exists表达式: 存在量词修饰的表达式,表示对于给定范围内的元素,存在某个元素满足相应的约束。
\sum表达式:返回给定范围内的表达式的和。
\product表达式:返回给定范围内的表达式的连乘结果。
\max表达式:返回给定范围内的表达式的最大值。
\min表达式:返回给定范围内的表达式的最小值。
\num_of表达式:返回指定变量中满足相应条件的取值个数。
JML的应用工具链:
OpenJML:OpenJML可以对含有JML的代码进行编译 ,并提供不同类型的选项进行检查。-esc可以静态检查可能出现的隐藏bug,-rac是运行时检查,-check则可以检查代码是否符合JML规格要求。
JMLUnitNG:可以根据代码中所写JML规范自动生成测试框架进行自动化测试。
部署JMLUnitNG/JMLUnit,针对Graph接口的实现自动生成测试用例
测试结果如下:

三次作业架构设计
第一次作业架构设计
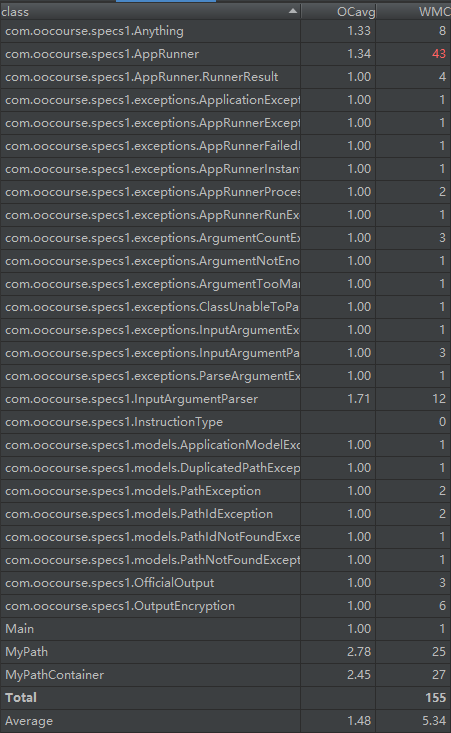
本次作业完全根据规格要求进行设计,为了减少查询的时间,采用了hashmap存放path与pathid。在distinctnode方面也采用了一个hashmap存储不同的node,在方法getDistinctNodeCount()中,只需返回该hashmap的size即可,大大节省了查询的时间。两个map设计如下:
private HashMap<Integer, Path> map = new HashMap<>();
map的key为pathid,value为Path,这样可以节省查找时的时间。在removePath()方法中,需要对map进行遍历,根据重写的equals方法找到相应path即可。
private HashMap<Integer, Integer> dismap = new HashMap<>();
dismap的key为nodeid,value为该node出现的次数,这样在删除一条path时,可以将该path所有出现的点的次数减一,当次数为零时,从dismap中移除该点即可。
类图如下:

复杂度分析:
第二次作业架构设计
本次作业按照规格设计时遇到了许多困惑,在对最短路径求解时查询了许多算法,最后使用了florid算法。本次作业并未重构,在第一次作业进行简单修改就满足了题目要求。
设计如下:
private HashMap<Integer, Path> map = new HashMap<>();
private HashMap<Integer, Integer> dismap = new HashMap<>();
这两个map沿用第一次的设计,功能也相同。
private int[][] graph = new int[250][250];
private HashMap<Integer, Integer> castmap = new HashMap<>();
private int[] nodecount = new int[250];
private int flag = 0;
private Floyd floyd;
- graph是一个二维数组,该数组是为了存储任意两点之间是否存在一条边,用于floyd算法。
- castmap是考虑到nodeid的数量不会超过250,但是nodeid本身是一个int范围的数,所以采用了一个castmap,key为该点的nodeid,value为映射的值,value的范围为[0,250)
- nodecount数组用来记录,在[0,250)之间的哪些值已经被映射,下标为映射的目标值,数组内存放标志位。在remove时要遍历dismap,如果该点出现的次数已经为0,就要删除这一映射,这样可以按照要求将nodeid个数严格控制在250以内。
- flag为标志位,每次调用remove或是add方法都需要将flag置一,这样在每次计算新的floyd最短路径时,判断路径是否有添加或删除(即flag是否为1),如果flag为1则计算新最短路径,并将flag置0;如果flag为0,则不计算,采用上一次计算的最短路径。
- floyd为存放Floyd算法的最终结果的一个对象。只有当flag置一时,才会调用他的构造方法,重新计算新的最短路径。
类图设计:
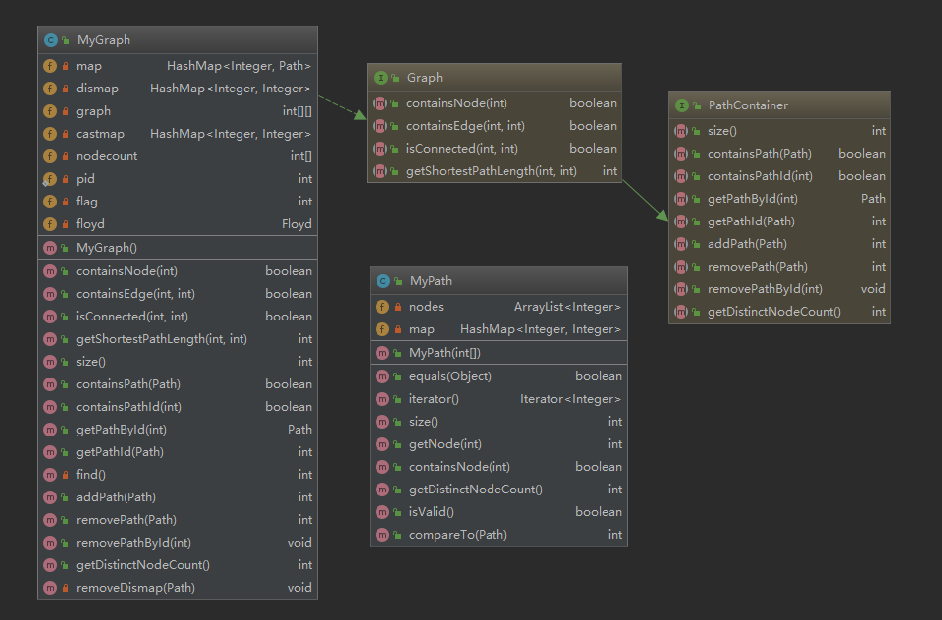
复杂度分析:

第三次作业架构设计
本次作业有点类似曾经学过数据结构课程的最后一次地铁作业,在最短路径的求解上依旧采用floyd算法。在讨论区学习到了一种算法,根据这种算法结合floyd进行了计算。本次作业最终思路是将问题转化为图内边的权值问题,然后进行求解。本次作业并未重构,大部分内容沿用第二次作业的代码,部分内容从MyRailwaySystem类中移入了Floyd类。
算法内容如下:将每条path都变成完全无向图,每条path内的每个点都有直接到达该path内任意一点的距离,同时path内的每条边都要加上切换path时的额外权值。最终求出的值再减去一次换乘的额外权值,即为所求。
MyRailwaySystem设计如下:
private HashMap<Integer, Path> map = new HashMap<>();
private int flag = 0;
private int blockNumber;
以上三个数据成员和前两次作业一直,blocknumber为连通块数量,根据并查集求解即可。
private Floyd leastOFtransfer = new Floyd(1);
private Floyd leastOFfear = new Floyd(2);
private Floyd leastOFunpleasant = new Floyd(3);
这三个数据成员即为本次作业的核心,构造函数传入构造模式(一个int型变量),以便区分额外权值。
Floyd设计如下:
private static int row = 120;
private int[][] length = new int[row][row];// 任意两点之间路径长度
private int addweight;//额外权值
private static HashMap<Path, int[][]> pathHashMap = new HashMap<>();//存储每条path的完全无向图
private static HashMap<Path, int[][]> unpleasantHashMap = new HashMap<>();//单独存储unpleasant的完全无向图
private static HashMap<Integer, Integer> castmap = new HashMap<>();//映射map
private static int[] nodecount = new int[row];//标记数组
private static HashMap<Integer, Integer> dismap = new HashMap<>();//计算distinctnode点的map
private static int[][] graph = new int[row][row];//存入floyd计算结果
private static int[][] shortestLength = new int[row][row];//最短路径数组
类图设计:
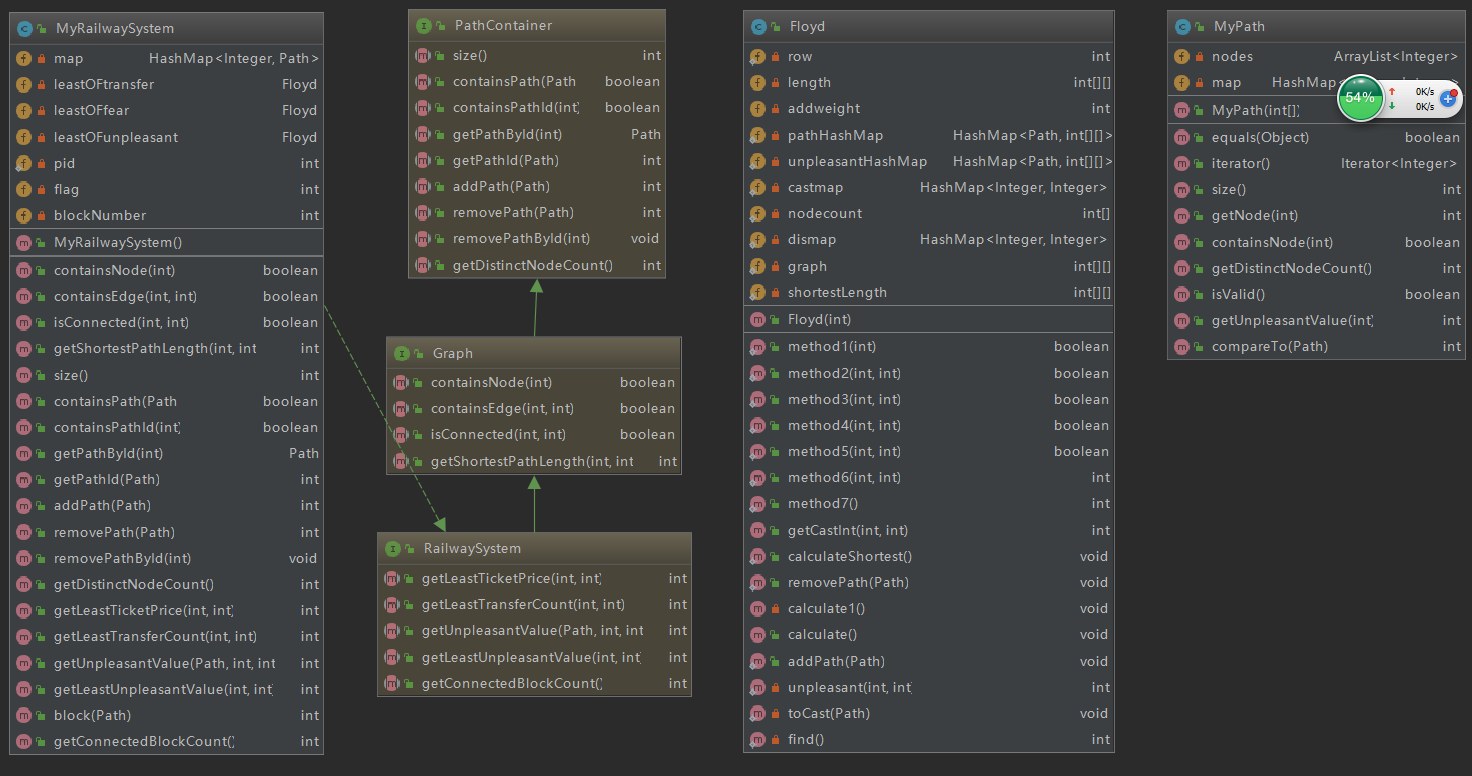
复杂度分析:
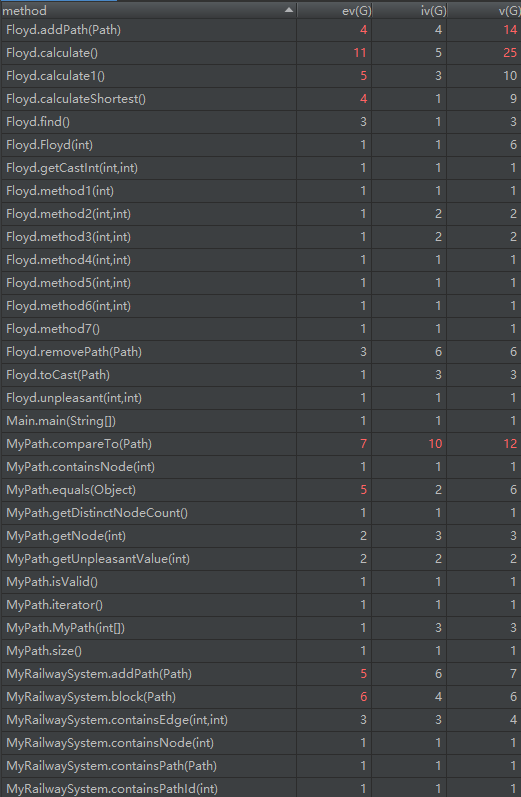
代码bug分析
第一次作业:本次作业强测只得到了80分,原因是没考虑到课程组会利用时间卡数据,在不该进行计算的地方反复进行了计算,所以事件被拖慢了,但是综合设计是没有问题的。已经成功合并修复。
第二次作业:本次作业强测45分,因为没有吸取第一次的教训,导致本次作业依然犯了不该犯的错误,查询时反复计算,导致许多点都time_limited。已经成功合并修复。
第三次作业:本次作业强测95分,bug在于数据太大时,我所设定的无限大出现在了数据里,导致数据错误。已经成功合并修复。
规格撰写和理解的心得体会
规格撰写本质上体现了从上而下的设计思路,设计好大框架然后一点一点的去构建细节。在学习了JML之后,能够通过已给出的规格实现函数或者类所要求的功能,这是一种很棒的体验。但是规格本身的学习是较为困难的,有许多语法上的规定需要记忆,以后还是要多多练习先写规格,再写代码,这样不会忘记自己设计的原始意图,别人读代码也会轻松很多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号