
c++ iterator(迭代器)分类及其使用
总所周知,c++的stl中提出了iterator的概念,这是C所没有的.在一般的使用中,iterator的行为很像c内建的指针.而在java和c#中索性就直接取消了指针,而采用类似iterator的做法来代替了指针.很多编程人员在使用iterator的时候也仅仅把他当作了指针的一个变体而没有多加注意。
不过既然是学习,那我们在使用的时候也要知道其存在的原因,其分类以及用法吧.
首先是问题的提出:
很多人会觉得,既然C++沿用了C的指针这么强大的东西了,为什么还要iterator这么一群类来工作呢?
我们知道,在我们编写模板的时候,对于使用了iterator做为参数的函数,往往该函数对于iterator有些特定的操作.比如下列2个函数
template<class P,class T>
P find(P start,P beyond,const T& x)
{
while( start != beyond && * start != x)
++start;
return start;
}
template<class P, class T>
void reverse(P start, P beyond)
{
while(start != beyond) {
--beyond;
if (start != beyond) {
T t = *start;
*start = *beyond;
*beyond = t;
++ start;
}
}
}我们可以看到,这两个函数都对模板参数P做了一定要求,在find中,我们要求P必须允许 != ,++和*(P)这三个运算符的操作,而对于reverse函数来说,其要求更多,运算符++,--,*(),!=都必须支持.问题就这么出来了,我们怎么让所有人都遵守这一要求呢?或者说,后续采用这个模板的使用者怎么能在不知道实现细节的情况下了解并遵守这些要求呢?显然,我们需要一个分类方法来知道如何界定不同种类的迭代器.
不过这里还是没有解释一个疑惑,即这两个函数改成T的指针也能完成的很好,我们还要iterator做什么?
答案很简单,不是所有数据结构都是线性的!对于一个链表来说,如果要实现上述的功能,我们必须重新写一个几乎一样仅仅是把++start变成start = start->next的函数.显然,这样重复的事情我们是不希望碰到的,尤其如果函数还非常大的情况下.而这时候,iterator的作用就出来了.对于链表,我们的链表的iterator(list_iterator)仅仅只要把operator++()重写成operator++(){now = now->next;},就能正常的使用find函数了.完全不需要重新编写.这就减少了我们算法的编写量.
现在,既然我们知道了iterator的好处了之后,接下来我们就想知道之前提到的分类法是怎么回事了.经常听说输入迭代器,输出迭代器,前向迭代器,双向迭代器,随机存取迭代器是怎么回事.
迭代器的分类:
1.输入迭代器(input iterator):只读,一次传递
是只读迭代器,在每个被遍历的位置上只能读取一次。
啥是一次传递?只需要遍历这个序列一次的算法,不需要把当前位置迭代器记存一个副本,等以后再使用。
因为该序列上同一时间可能只有一个位置的迭代器是合法的。
为输入迭代器预定义实现只有istream_iterator和istreambuf_iterator,用于从一个输入流istream中读取。一个输入迭代器仅能对 它所选择的每个元素进行一次解析,它们只能向前移动。一个专门的构造函数定义了超越末尾的值。总是,输入迭代器可以对读操作的结果进行解析(对每个值仅解析一次),然后向前移动。
input iterator就像其名字所说的,工作的就像输入流一样.我们必须能
- 取出其所指向的值
- 访问下一个元素
- 判断是否到达了最后一个元素
- 可以复制
因此其支持的操作符有 *p,++p,p++,p!=q,p == q这五个.凡是支持这五个操作的类都可以称作是输入迭代器.当然指针是符合的.
2.输出迭代器(output iterator):只写,一次传递
这是对输入迭代器的补充,不过是写操作而不是读操作。为输出迭代器的预定义实现只有ostream_iterator和ostreambuf_iterator,用于向一个输出流ostream写数据,还有一个一般较少使用的raw_storage_iterator。他们只能对每个写出的值进行一次解析,并且只能向前移动。对于输出迭代器来说,没有使用超越末尾的值来结束的概念。总之,输出迭代器可以对写操作的值进行解析(对每一个值仅解析一次),然后向前移动。
output iterator工作方式类似输出流,我们能对其指向的序列进行写操作,其与input iterator不相同的就是*p所返回的值允许修改,而不一定要读取,而input只允许读取,不允许修改.
支持的操作和上头一样,支持的操作符也是 *p,++p,p++,p!=q,p == q.
使用Input iterator和output iterator的例子:
template<class In,class Out>
void copy(In start,In beyond, Out result)
{
while(start != beyond) {
*result = *start; //result是输出迭代器,其*result返回的值允许修改
++result;
++start;
}
}
//简写
template<class In,class Out>
void copy(In start,In beyond, Out result)
{
while(start != beyond)
*result++ = *start++;//这个应该能看懂的...
}3.前向迭代器(forward iterator):多次读/写
前向迭代器结合了所有输入迭代器的功能和几乎所有输出迭代器的功能。
可变向前迭代器 (mutable ForwardIterator) 是额外满足输出迭代器 (OutputIterator) 要求的向前迭代器 (ForwardIterator) 。
4.双向迭代器(bidirectional iterator)
双向迭代器在前向迭代器上更近一步,其要求该种迭代器支持operator--,因此其支持的操作有 *p,++p,p++,p!=q,p == q,--p,p--
5. 随机存取迭代器(random access iterator)
即如其名字所显示的一样,其在双向迭代器的功能上,允许随机访问序列的任意值.显然,指针就是这样的一个迭代器.
对于随机存取迭代器来说, 其要求高了很多:
- 可以判断是否到结尾( a==b or a != b)
- 可以双向递增或递减( --a or ++a)
- 可以比较大小( a < b or a > b or a>=b ...etc)
- 支持算术运算( a + n)
- 支持随机访问( a[n] )
- 支持复合运算( a+= n)
结构图:
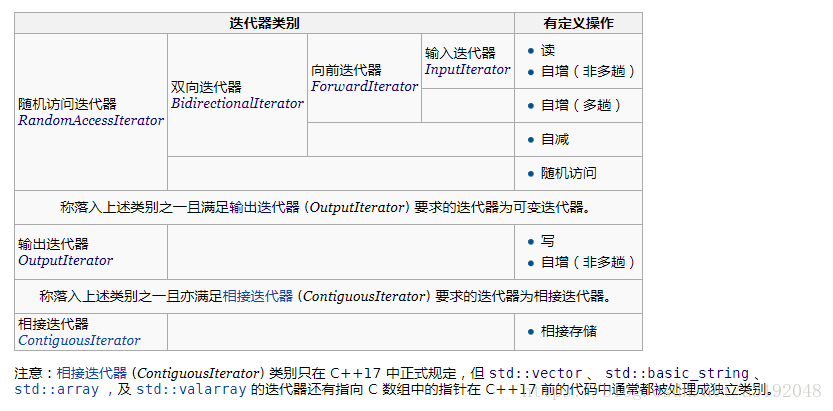
上面即为我们所讨论到的几个迭代器的层次.看起来很像继承是麽?
但是实际上在STL中,这些并不是通过继承关联的.这些只不过是一些符合条件的集合.这样的好处是:少去了一个特殊的基类(input iterator),其次,使得内建类型指针可以成为iterator.
其实只要明白iterator是满足某些特别的功能的集合(包括类和内建类型),就不会觉得是继承了.
Iterator使用:
一个ostream_iteartor的例子:
#include <iostream>
using namespace std;
template<class T>
class Ostream_iterator {
public:
Ostream_iterator(ostream &os,const char* s):
strm(&os), str(s){}
// Ostream_iterator& operator++() {return *this;}
Ostream_iterator& operator++(int) {return *this;}
Ostream_iterator& operator*() {return *this;}
Ostream_iterator& operator=(const T& t)
{
*strm << t << str;
return *this;
}
private:
ostream* strm;
const char *str;
};
template<class In,class Out>
Out Copy(In start,In beyond,Out dest)
{
while(start != beyond)
*dest++ = *start++; // dest并没有执行+1
return dest;
}
int main()
{
Ostream_iterator<int> oi(cout, " \n");
int a[10];
for (int i = 0;i!=10;++i)
a[i] = i+1;
Copy(a,a+10,oi);
return 0;
}在这个例子中,我们简单的构造了一个ostream_iterator,并且使用了copy来输出..这个ostream_iterator和STL差别还是很大,不过功能上已经差不多了.我想读者们应该也能看懂代码吧,所以就不用多做什么解释了.
第二个例子中,我们讲构造一个istream_iterator.
对于一个istream_iterator来说,我们必须要存的是T buffer和istream *strm.不过由于istream的特殊性,我们必须知道buffer是否满,以及是否到达尾部,因此,我们的结构是这样的
template <class T>
class Istream_Iterator{
private:
istream *strm;
T buffer;
int full;
int eof;
};对于构造函数来说,因为有eof的存在,因此,我们自然想到,我们的默认构造函数就应该把eof设为1.而对于有istream的iterator,都应该为0.
Istream_iterator(istream &is):
strm(&is),full(0),eof(0){}
Istream_iterator():strm(0),full(0),eof(1){}对于我们的版本的istream_iterator来说,我们需要完成的功能有
- 进行取值操作(dereference),既*(p)
- 自增操作
- 比较
自增操作:
我们知道,在istream中,一旦获取到一个值了之后,我们将不在访问这个值.我们的iterator也要符合这样的要求,因此,我们通过full来控制.
Istream_iterator& operator++(){
full = 0;
return *this;
}
Istream_iterator operator++(int){
Istream_iterator r = *this;
full = 0;
return r;
}Dereference:
对于解除引用操作来说,我们需要将流中缓存的值存入buffer内.同时,我们要判断读取是否到结尾,到了结尾则应当出错.
在这里我们写了一个私有函数fill(),这个将在比较的时候用到
T operator*() {
fill();
assert(eof);//我们断定不应该出现eof
return buffer;
}
void fill(){
if (!full && !eof) {
if (*strm >> buffer)
full = 1;
else
eof = 1;
}
}比较:
对于比较来说,只有两个istream_iterator都同一个对象或者都处于文件尾时,这两个istream_iterator才相等.因此这里其比较对象为istream_iterator而不是const istream_iterator
template<class T>
int operator==(Istream_iterator<T> &p,Istream_iterator<T>& q)
{
if (p.eof && q.eof)
return 1;
if (!p.eof && !q.eof)
return &p == &q;
p.fill();q.fill();
return p.eof == q.eof;
}最后的测试例子,读者可以把之前的copy和ostream_iterator拷下来
int main()
{
Ostream_iterator<int> o(cout,"\t");
Istream_iterator<int> i(cin);
Istream_iterator<int> eof;
Copy(i,eof,o);
return 0;
}结论:
iterator是STL实现所有算法已经其通用型的基础.通过对iterator分类,使得算法的使用者在使用时不需要知道具体实现就可知道算法对于参数的要求,形成一个通用的体系。


参考链接:https://www.cnblogs.com/marchtea/archive/2012/02/27/2370068.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号