
第一次个人编程作业
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | 930 | 1110 |
| · Analysis | · 需求分析 (包括学习新技术) |
240 | 300 |
| · Design Spec | · 生成设计文档 | 90 | 90 |
| · Design Review | · 设计复审 | 30 | 40 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) |
30 | 20 |
| · Design | · 具体设计 | 90 | 60 |
| · Coding | · 具体编码 | 360 | 480 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试 (自我测试,修改代码,提交修改) |
60 | 90 |
| Reporting | 报告 | 90 | 95 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 | 20 | 30 |
| -- | 合计 | 1050 | 1235 |
设计与实现
思路
首先想到的是把电话号码这个捣乱的字符串提取出来,才方便进行下一步。其他的利用正则表达式进行匹配。(也有导入数据库之类的方法,但是不太会弄,就学学正则吧...)
实现过程
首先在正则表达式测试网站上整理好表达式,类似这种:

不过总感觉有些特殊情况顾及不到,应该是自己理解不够深入,以后再研究研究。
之后就用Java来实现,有两个类,一个Main,一个AddressResolution,Main里面的主函数负责文件的IO操作,AddressResolution负责格式化数据,其中拥有一个函数resolution:
public JSONObject resolution(String raw_address)
接收一个字符串并将其格式化为JSONObject。格式化Json数组的功能是利用外部导入的jar包FastJson来实现的。
以下是程序流程图:

算法其实很简单,就是正则表达式直接匹配,复杂的是正则表达式内部如何写才能够涵盖尽可能多的情况。下面是我的正则表达式,供参考:
- 1!
(?<name>[^,]+),(?<province>[^省]+自治区|黑龙江[省]?|.{2}(?!市)省?|.*?行政区)?(?<city>[^市]+自治州|.*?地区|.*?行政单位|.+盟|市辖区|.+?市|.*?直辖市)?(?<county>[^县]+县|[^社小]+?区|.+县级市|.+?市|.+?旗|.+海域|.+?岛)?(?<town>[^镇]+?镇|.+?乡|.+?街道|.+?办事处)?(?<village>.*)\\.
- 2!
(?<name>[^,]+),(?<province>[^省]+自治区|黑龙江[省]?|.{2}(?!市)省?|.*?行政区)?(?<city>[^市]+自治州|.*?地区|.*?行政单位|.+盟|市辖区|.+?市|.*?直辖市)?(?<county>[^县]+县|[^社小]+?区|.+县级市|.+?市|.+?旗|.+海域|.+?岛)?(?<town>[^镇]+?镇|.+?乡|.+?街道|.+?办事处)?(?<road>[^路]+路|.+街|.+道|.+巷[子]?)?(?<num>[^号]+弄|.*[#-]\\d+|.+号)?(?<village>.*)\\.
注:已经提取过手机号码和难度等级了。
3!等级的只对特殊情况比如直辖市进行了处理,其他的就无能为力了,除非借助外力,借助地图或者地址表什么的,但是不太会...
性能分析
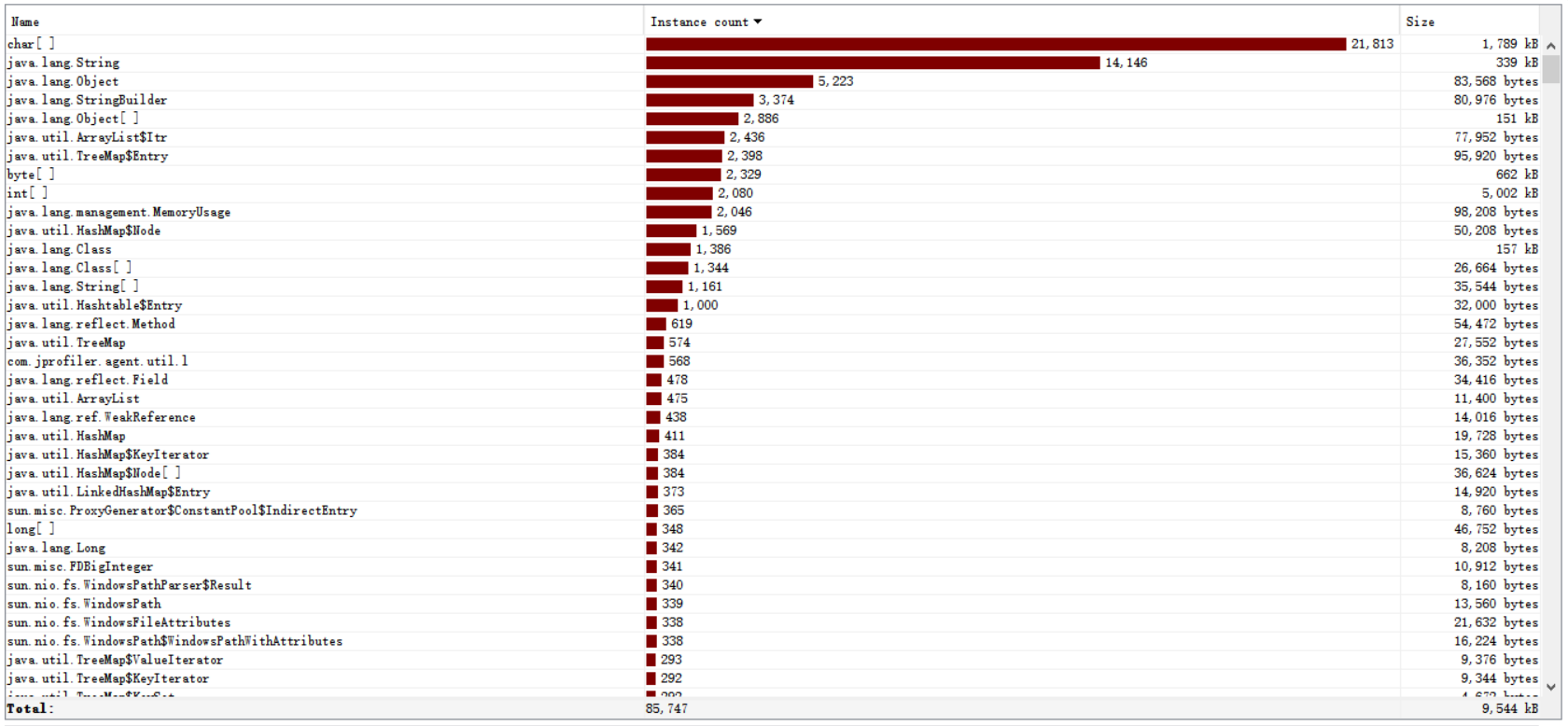
由图片可以看出来,占用内存最大的主要就是char,string,Object这几类,因为用正则匹配的话,要进行大量的字符串比较,由上面那个正则测试的图也可以看出,比较复杂的情况就达到了200多步的匹配。匹配之后还要进行JSONObject和JSONArray的转换,性能瓶颈就在字符串操作这一方面。所以要优化的话其实感觉就是在尽可能少的匹配次数中得到最准确的结果。然而对于地址这种数据,特殊情况又特别多,所以正则匹配的方法大概也就是这点有些不足吧。
单元测试
@Test
public void testMain1() {
AddressResolution resolution = new AddressResolution();
String raw_address = "1!鲁胞,上海长宁区周18951233466家桥街道长宁路999号春天花园.";
String format_address = resolution.resolution(raw_address).toString();
System.out.println(format_address);
}
//为了节省空间,下面只写另外四个测试的输入数据
//"鲁胞,上海长宁区周18951233466家桥街道长宁路999号春天花园."
//"1!上海长宁区周18951233466家桥街道长宁路999号春天花园."
//"1!鲁胞,上海长宁区周家桥街道长宁路999号春天花园."
//"1!鲁胞,上海长宁区周18951233466家桥街道长宁路999号春天花园"
测试结果如下:
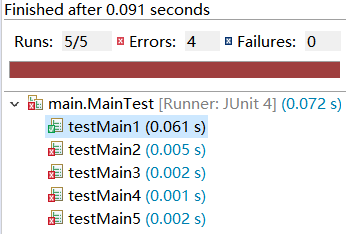
后四条数据的共同点是,都缺失了和正则表达式匹配的关键数据,难度等级、姓名、手机号码以及结尾的英文句号,从而导致出现异常。由于在这道题目中这些数据是关键数据,所以可以在提取后先判断关键数据是否缺失,来避免错误发生。而其他字段的缺失不会报错,只会影响正确答案。
单元测试还不是很懂,其他一些功能没有深入学习,就先写这些。
异常处理
- 省级缺失的情况
输入数据:
"3!小美,北京市东15822153326城区交道口东大街1号北京市东城区人民法院."
省级缺失时,由于匹配省级的表达式除了黑龙江(省)外要固定匹配两个汉字,所以在遇到这种情况时,北京会被匹配为省级,而市级就只剩一个市字。为了避免这种情况,需要在匹配省级时加上限制条件:.{2}(?!市)省?。如果两个字后面跟的是市字,就不进行匹配,除了黑龙江省要特殊判断,其他省的名字都只有两个字,所以不会出错。
市字缺失的情况
输入数据:
"1!张三,福建福州闽13599622362侯县上街镇福州大学10#111."
这种情况,由于没有市字,匹配市级行政区时失去了结尾的判断依据,导致市级为空,县级为福州闽侯县。这种情况,由于市的名字情况很多,长短不一,用正则没有很好的解决办法,可以通过导入省市对照表来进行额外判断,不过也需要额外的时间和空间。
- 县级缺失且后面有能够匹配县级的字符
输入数据:
"1!韩潜咏,广东省茂名市坡心镇964乡道潭阪社区居委会13602287339."
这条数据缺失县级行政区,而在后面出现了社区两个字,而在匹配县级时有对区字的判断,导致县级为坡心镇964乡道潭阪社区,进而导致乡镇级为空,详细地址也错误,十分严重。为了避免这种情况,在判断区字时也手动加上限制条件:[^社小]+?区。如果区是社区、小区的一部分,则不进行匹配。这样县级为空,后面的也都符合答案。
- 其他
至于其他的异常,就是后面各级行政区的情况,由于越往后,稀奇古怪的地址名就越多(什么巷、坊、弄等等...),会导致正则表达式无法完美匹配,尤其是要分为七级地址的时候,如果要顾及所有情况,正则表达式会越来越长,这样就很不方便,而且搜集各种名称也很复杂,所以治标不治本。只能感叹中国文化博大精深啊...
后记
其实一开始看到这个题目的时候,我是拒绝的,哇,什么奇怪的要求,这么复杂的地址,电话号码还会到处跑,想想就头疼,当时我还完全不懂正则表达式。后来DDL临近,不得不开始这次的作业了,于是强迫自己学习正则,没想到还挺快,学完发现并不是那么难,还是非常有规律可循的,同时感叹正则表达式的强大(当然自己也只是了解了一点点而已,并不是很精通)。之后写出正则,在测试网站上正确匹配出一串地址的时候,确实是很有成就感的。再然后连Java都是临时学的,之前也是完全没写过的。几天边学边做的经历中,印象最深刻的除了各种奇怪的人名、地名,大概就是浏览器上常驻的十几个有关Java的标签页了。不管最终效果怎样,我是真的肝不动了...希望能好好享受接下来的国庆假期。什么?居然还有作业!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号