基础算法知识点小结
前言
终于从递推的深渊中解放出来,做一点简单的东西,同房的神犇都在刷ctsc,而我一个菜鸡还在做这么简单的东西,我几次想放弃收集这些太基础的知识,但是毕竟我这些知识原来也没怎么学好,但最终我还是整理完了。
其实,ms多次教导我,你太菜了,别人成绩比你好,都不省写。我可能确实是写的太精简了,可能本文面向对象都不是一点都没学的人(尽管叫做基础算法知识点小结),至少是给有点基础的人,通过此文开阔思维,如果有看不懂的,欢迎提问,便于让这篇文章更加大众化,真正符合它的名字,成为新司机上路有力工具。
最后,提一下,本文的参考代码中有些缩写,后面就不会解释意思了:
ll均表示long long
il表示inline
基本运算知识
bit
指1个0或者1
二进制
十六进制
表示
以\(0x\)开头后面接十六进制数,如\(0x75\)表示十六进制数75,即\((75)_6=117\)
0~15二进制与十六进制对应表
| 十六进制数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| 二进制数 | 0 | 1 | 10 | 11 | 100 | 101 | 110 | 111 |
| 十六进制数 | 8 | 9 | a(10) | b(1) | c(12) | d(13) | e(14) | f(15) |
| 二进制数 | 1000 | 1001 | 1010 | 1011 | 1100 | 1101 | 1110 | 1111 |
注:
最好能够记得,然后随便给你一个十六进制数,你能一秒内写出它的二进制位,十六进制的好处在于,十进制无法凸显二进制中的每一位,而十六进制的一位可以表现二进制中的8位,虽然考试不考,但是肯定对你有帮助,而且也可以锻炼你的记忆能力,尽管我现在都还记不得。
位运算
(讲解顺序按算术优先级排序)
\(\sim\)(非)
表达式:\(\sim a\)
性质
在证明二进制或者01序列的一一对应中,每种不同的序列,将某个位置或某段较为固定的区间全部取反的序列不同。
解释
对a的二进制位下每一位进行取反操作,即0变为1,1变为0,如3为二进制数\(~(101)_2=(010)_2\)
\(<<,>>\)(左移,右移)
表达式
\(a<<b,a>>b\)
解释
- 其中a表示要进行操作的数,b表示右移或者左移的位数
- 右移1位等价与/2向0取整(对负数也成立,如\(3>>1=1,-3>>1=-1\)),二进制下的理解即所有的数字向右移动,最高位补0,低位舍去,如\((101111)_2>>3=(000101)_2\)
- 左移一位等价与乘2,(同样对负数也成立,如\(3<<2=12,-3<<2=-12\)),二进制理解下即所有数字向向左移动,最高位溢出舍去,最低位补0.如\(00101111<<2=(10111100)_2\)。
\(\&\)(与)
表达式\(:a\&b\)
解释
a,b二进制位下,对于对应的每一位二进制位,同为1才为运算后才为1,否则为0,如\((10011)_2\&(10000)_2=(10000)_2\)
$$(异或)
表达式:\(a\wedge b\)
解释
- 对a,b的二进制位下的每一位分别运算,相异为1,相同为0,即\((10011)_2\wedge(10000)_2=(00011)_2\)
- 只有二进制位上的有1在运算中才会改变,类似奇偶
- 任何数异或0为其本身
- 异或满足交换律和结合律,于是多次异或同一个数无效\(a\wedge b\wedge b=a\)
- 结合2,3条,对于类异或问题,即操作后1变为0,0变成1,那么多次进行重复操作无效,并且操作顺序不存在先后,这是重要的性质
- 在图论中的异或和路径,即路径长为i经过的所有边的边权的异或起来的值,去了一个地方,原路返回等于没走,因此类似瞬间转移,真正产生结果的为环,而环中套环可以作为线性基处理。
- 二进制拆分,对每一位考虑问题,从高位考虑问题
\(|\)(或)
表达式:\(a|b\)
解释
对于a,b每一位二进制位对应运算,只要有1就为1,如\((10011)_2\wedge(10000)_2=(10011)_2\)
与或非通性
二进制拆分,运算中可以拆开每一位独自运算,这样对于二进制运算的题目,我们可以对于每一位独自运算,这样会更加好做。
补码和反码
采取补码的类型满足\(-x=\sim x+1\)
采取反码的类型满足\(-x=\sim x\)
注:c++通常采用补码
无符号整型和有符号整型
以下对第n位而言
| 类型 | 范围 | 溢出 | 最低位 | 最高位 |
|---|---|---|---|---|
| 无符号整型 | \(0\sim 2^n-1\) | 对\(2^n\)取模 | 0 | n |
| 有符号整型 | \(-2^{n-1}\sim 2^{n-1}-1{\tiny\boxed{1}}\) | 对\(2^{n-1}\)取模 | 0 | n-1 |
注释
\({\tiny\boxed{1}}:\)
对于有符号整型\(-2^{n-1}\)等价于0,因为0的取反+1为0,而\(-2^{n-1}\)取反+1也为0,而这也解释为什么溢出了是对\(2^{n-1}\)取模。
memset
表达式
解释
- a表示要进行操作的数组,\(sizeof(a)\)取得是a的大小,好像把数组传到函数进行memset下或报错,因为不知道数组大小。
- b表示你要给数组每个元素赋值的数,应该是一个8进制数,然后会将你的数组的每一个元素的每8位赋值为b的二进制位,推荐几个常用赋值的数,\(0x3f\)好处在于每三位\(0011\ 1111\),并且乘以2不过intmax(即\(0x7fffffff\)),还有就是\(0x7f\)也就是赋值为前面的intmax,还有就是\(-1\),全部赋值为-1
快速幂
二分快速幂
(注:以下所有快速幂全部使用pow为函数名)
原理:\(x^y=(x^{y/2})^2\times \begin{cases}x(y\in\text{奇数})\\1(y\in\text{偶数})\end{cases}\)
代码实现:
int pow(int x,int y,int yyb){
if(!y)return 1;
int ans(pow(x,y>>1,yyb));
return ans*ans%yyb*((y&1)?x:1)%yyb;
}
二进制(拆分)幂
原理:\({\Large x^y=x^{c_{k-1}2^{k-1}+c_{k-2}2^{k-2}+...+c_02^0}}\)
代码实现:
int pow(int x,int y,int yyb){
int ans(1%yyb);while(y){
if(y&1)ans=(ll)ans*x%yyb;
x=x*x%yyb,y>>=1;
}return ans;
64位乘法
问题
求\(a\times b \%yyb\),其中,\(a,b,yyb\leq 10^{18}\)
根号乘
原理
代码实现
此法已萎,有兴趣者自我娱乐
龟速乘
原理
参考代码
ll mult(ll a,ll b,ll p){
ll ans(0);while(b){
if(b&1)(ans+=a)%=p;
(a<<=1)%=p,b>>=1;
}return ans;
}
快速乘
原理
代码实现
ll mult(ll a,ll b,ll p){
ll ans(a*b-(ll)((lb)a*b/p)*p);
if(ans<0)ans+=p;return ans;
}
证明:
设\(x=a\times b,y=[a\times b/yyb]\times yyb,x\equiv x'(mod\ 2^{63}),y\equiv y'(mod\ 2^{63})\)
显然有\(x-y\equiv x'-y'(mod\ 2^{63})\equiv a\times b\%yyb\),而\(yyb<2^{63}\),于是有
\((x-y)\% 2^{63}=a\times b\%yyb\),得证
二进制压缩
标志
数据范围小
做法
用一个数字的二进制位表示bool变量的0 和 1,如你要开个\(bool\ a[31]\),不妨就用一个变量b存储,其中b二进制第0位等价与\(a[0]\),第一位等价与\(a[0]\),第二位等价于\(a[2]\),...以此类推
常用操作
| 代码 | 解释 |
|---|---|
| \(n>>k\&1\ or\ 1<<k\$n\) | 取第k位上的数字 |
| \(n\&((1<<k+1)-1)\) | 取后k位 |
| \(n\wedge 1<<k\) | 第k位上数字取反 |
| \(n\)|\(1<<k\) | 第k位数字赋值为1 |
| \(n\&1<<k\) | 第k位数字赋值为0 |
练习:
成对变换
定义
\(n\wedge1=\begin{cases}n+1(n\in\text{偶数})\\n-1(n\in\text{奇数})\end{cases}\)
于是称一对相邻的奇数偶数\(a,b(b-a=1)\)为成对变换,而且具有性质\(a\wedge 1=b,b\wedge1=a\)
lowbit
定义
应用
快速查找一个二进制数x的每一个1所在的位置
做法:
- 预处理\(to[37]\),枚举i计算\(to[2^i\%37]=i(i=0,1,...,36)\)
求证:
\(2^0\%37,2^1\%37,...,2^{36}\% 37\)互不相同
证明:
注意到37是一个质数,且与2互质,故满足费马小定理,有\(2^{36}\equiv 1(mod\ 37)\)
于是易知余数循环节为36,故36以内的数互不相同
- 输出\(to[lowbit(x)\%37]\),令\(x-=lowbit(x)\),当x为0时,停止程序
参考代码
void prepare(){
for(int i(0);i<37;++i)
to[(1<<i)%37]=i;
}
void work(int n){
while(n){
printf("%d ",to[lowbit(n)%37]);
n-=lowbit(n);
}
}
基本模型
前缀和
定义
对于长度为n数列\(\{a_i\}\),而言,它的前缀和为\(\{s_i\}\),即\(s_i=\sum_{j=1}^ia_j=a_1+a_2+...+a_i\),经常性的,定义\(s_0=0\)。
性质
-
\(s_r-s_{l-1}=a_l+a_{l+1}+...+a_r\)
-
对于二维数组\(a[i][j]\)前缀和,即记\(s[i][j]\)为前i行前j列的元素之和,其递推式为\(s[i][j]=a[i][j]+s[i-1][j]+s[i][j-1]\),查询以\(A(y_1,x_1)\)和\(B(y_2,x_2)\)为对角线的矩形之和,有公式\(s[y_2][x_2]-s[y_2][x_1-1]-s[y_1-1][x_2]+s[y_1-1][x_1-1]\)(B在A右上方)
区间问题
定义
对于区间的维护,查询,处理,区间递推,区间划分问题的一切与区间有关或者可以看成区间的问题。
方法
考虑关系
- 包含
- 交叉
- 相离和相邻
(注:字面意思即可理解,不解释,再提及的目的为了让思维更加全面开阔)
维护
- 排序,先按左端点排序,再按右端点排序,或者先按右端点排序,再按左端点排序,注意灵活运用
- 枚举左端点在枚举右端点(或者枚举右端点再枚举左端点,强调的目的为了说明这两者对思维的影响),得到\(O(n^2)\)暴力,在寻求优化。
- 区间包含关系的剔除,先按左端点排序,再按右端点排序,把区间加入栈,如果被栈顶包含,则拒绝入栈,否则入栈。
- 对于一段区间的所包含的所有元素的性质维护,时间复杂度通常是\(O(n^2)\),通用办法是将信息存储到区间的两个端点,再利用前缀和表现出来。
递推的状态
- 位置,即该区间所包含的一个个位置
- 区间,即以整个区间为状态,注意排序防止后效性。
递归
指数型枚举
输出n个数字\(1\sim n\)。每个数可选可不选的所有方案。
自动递归版
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
using namespace std;
int sta[16],top,n;
il void dfs(int);
int main(){
scanf("%d",&n),dfs(1);
return 0;
}
il void dfs(int n){
if(n>::n){
for(int i(1);i<=top;++i)
printf("%d ",sta[i]);
putchar('\n');return;
}dfs(n+1);
sta[++top]=n,dfs(n+1),--top;
}
手动递归版
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
using namespace std;
struct fst{
int n,ret_address;
}sta[20];
il void call(int,int&),
ret(int&);
int num[20],tot,top;
int main(){
int n,address;
scanf("%d",&n);
call(1,address);
while(top){
switch(address){
case 0:
if(sta[top].n>n){
for(int i(1);i<=tot;++i)
printf("%d ",num[i]);
putchar('\n'),ret(address);continue;
}call(sta[top].n+1,address);
continue;
case 1:
num[++tot]=sta[top].n;
call(sta[top].n+1,address);
continue;
case 2:
--tot,ret(address);
continue;
}
}
return 0;
}
il void ret(int &address){
address=sta[top].ret_address,--top;
}
il void call(int n,int &address){sta[++top].n=n;
sta[top].ret_address=address+1,address&=0;
}
组合型枚举
输出n个数字\(1\sim n\),选出m个数字的所有方案
自动递归版
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
using namespace std;
int n,m,sta[26],top;
void dfs(int);
int main(){
scanf("%d%d",&n,&m),dfs(1);
return 0;
}
void dfs(int n){
if(top>m||top+::n-n+1<m)return;
if(n>::n){
for(int i(1);i<=top;++i)
printf("%d ",sta[i]);
putchar('\n');return;
}sta[++top]=n,dfs(n+1),--top,dfs(n+1);
}
手动实现递归版
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
using namespace std;
struct fs{
int n,ret_address;
}stack[10001];
int top,num[101],tot;
il void ret(int&);
il void call(int,int,int&);
int main(){
int n,m,address;
scanf("%d%d",&n,&m);
call(1,0,address);
while(top){
switch(address){
case 0:
if(tot>m||tot+n-stack[top].n+1<m){
ret(address);continue;
}
if(stack[top].n>n){
for(int i(1);i<=tot;++i)
printf("%d ",num[i]);
putchar('\n');ret(address);
continue;
}num[++tot]=stack[top].n;
call(stack[top].n+1,address+1,address);
continue;
case 1:--tot;
call(stack[top].n+1,address+1,address);
continue;
case 2:
ret(address);
continue;
}
}
return 0;
}
il void ret(int &address){
address=stack[top].ret_address,--top;
}
il void call(int n,int ret_address,int &address){
stack[++top].n=n,address&=0;
stack[top].ret_address=ret_address;
}
全排列枚举
输出\(1\sim n\)的全排列中的所有方案。
自动递归
#include <iostream>
#include <cstdio>
#define il inline
#define ri register
using namespace std;
bool is[10];
int num[10],n;
void dfs(int);
int main(){
scanf("%d",&n),dfs(1);
return 0;
}
void dfs(int n){
if(n>::n){
for(int i(1);i<n;++i)
printf("%d ",num[i]);
putchar('\n');return;
}
for(int i(1);i<=::n;++i){if(is[i])continue;
num[n]=i,is[i]|=true,dfs(n+1),is[i]&=false;
}
}
手动递归
#include <iostream>
#include <cstdio>
#include <cstring>
#define il inline
#define ri register
using namespace std;
struct fst{
int n,ret_address;
}sta[20];
bool is[20];
int top,num[20],tot;
il void call(int,int&),
ret(int&);
int main(){
int n,address(0);scanf("%d",&n);
call(1,address);while(top){
if(sta[top].n>n){
for(int i(1);i<=n;++i)
printf("%d ",num[i]);
putchar('\n'),ret(address);continue;
}
if(address>n){ret(address);continue;}
if(is[address]){++address;continue;}
is[address]|=true,num[++tot]=address;
call(sta[top].n+1,address);
continue;
}
return 0;
}
il void ret(int &address){
address=sta[top].ret_address,--top,
is[address]&=0,--tot,++address;
}
il void call(int n,int &address){
sta[++top].n=n;
sta[top].ret_address=address;
address=1;
}
分治
通性
一个问题可以被划分成多个更小的子问题,且子问题的求解具有相似性,并且都能划分成几个能够求解的问题
如,无限分形图,分形之城
平面最近点对
警告:作者不想画图,以下全部文字描述,请自行画图理解
问题
平面直角坐标系中,有n个点,记第i个点为\((x_i,y_i)\),现在你要选出两个点,最小化它们之间的距离,求出这个距离的值。
解
考虑用分治求解,不妨考虑二分,于是对所有点按x轴坐标排序,设求解的编号为l到r,随便选择一个靠中间的点\(mid=l+r>>1\),以\(x=a_{mid}\)为界分成两个子问题,求解\(l\sim mid\),和\(mid+1\sim r\),分别把这些点集记做\(q_l,q_r\),不妨将求出来的最小距离取Min,保存在变量\(ans\)中。
现在还剩下的问题是,一对在\(q_l\)和\(q_r\)的点可能拥有最短距离,利用求出的\(ans\)剪枝,易知只有x轴坐标在\((a_{mid}-ans,a_{mid}+ans)\)间的点对才可能拥有最短距离,考虑其中的一个点而言,寻找的另外一个点,要拥有最短距离,必然两者y轴方向上的距离小于ans,于是最差的情况下,即这个点在\(x=a_{mid}\)上,以这个点向上延伸ans距离,向下延伸ans距离,向右延伸ans距离,构成了一个\(ans\times 2ans\)的矩形,只有在这个范围内的点才会成为与它成为最优解。
于是对于一个点而言,我们只要最多枚举5个点即可,而就算再差,就不妨\(q_1\)中有\(n/2\)个点,容易知道,只要枚举\(n/2\times 5\approx n\),于是每一层的时间复杂度最少是\(O(n)\),有\(log_n\)层,如果是求出\(q1,q2\)间的点按y轴排序,对于每一个点,这样就可以在常数级别枚举出其他可能和它成为最优解的点,这样算出来是\(nlog(n)^2\)。
注意到x轴坐标的有序性我们只用了一次,就是用来求mid,求完以后接着求解子问题的时候,就不用了,不妨保存下mid这个点,不妨自下而上给y轴坐标归并排序,此时对于每一层,从左至右暴力扫描那些点的x轴坐标在\(q_1,q_2\)内,这样扫描出来的点,能保证它们的y轴坐标是单调递增的,因此就可以\(nlog(n)\)解决整个问题。(但好像没有人详细地讲过这个方法,而且大多人都不是归并)。
参考代码:
#include <iostream>
#include <cstdio>
#include <cmath>
#include <algorithm>
#define il inline
#define ri register
#define Size 200050
using namespace std;
struct pos{
double x,y;
il void read(){
scanf("%lf%lf",&x,&y);
}
il bool operator<(const pos&a)const{
return x<a.x;
}
}p[Size],t[Size];
il double dis(pos,pos),divide(int,int);
template<class free>il free Abs(free);
template<class free>il free Min(free,free);
int main(){
int n;scanf("%d",&n);
for(int i(1);i<=n;++i)p[i].read();
sort(p+1,p+n+1),printf("%.4lf",divide(1,n));
return 0;
}
il double divide(int l,int r){
if(l==r)return 1e16;int mid(l+r>>1);
double mx(p[mid].x),ans(Min(divide(l,mid),divide(mid+1,r)));
int i(l),k(l),j(mid+1),tot(0);
while(i<=mid&&j<=r)
if(p[i].y<p[j].y)t[k++]=p[i++];
else t[k++]=p[j++];
while(j<=r)t[k++]=p[j++];
while(i<=mid)t[k++]=p[i++];
for(i=l;i<=r;++i)p[i]=t[i];
for(i=l;i<=r;++i)
if(Abs(p[i].x-mx)<ans)
t[++tot]=p[i];
for(int i(1),j;i<=tot;++i)
for(j=i+1;j<=tot;++j){
if(t[j].y-t[i].y>=ans)break;
ans=Min(ans,dis(t[i],t[j]));
}return ans;
}
template<class free>
il free Abs(free x){
return x<0?-x:x;
}
template<class free>
il free Min(free a,free b){
return a<b?a:b;
}
il double dis(pos a,pos b){
return sqrt(pow(a.x-b.x,2)+pow(a.y-b.y,2));
}
等比数列求和
问题
询问\((x^0+x^1+...+x^n)\%p\)的结果
解
(以下il为inline简写)
法一:公式法
易知\((x^0+x^1+...+x^n)\%p=\frac{x^{n+1}-1}{x-1}\%p\)
当p与\(x-1\)互质时可以求出\(x-1\)的乘法逆元,从而求解分子,而分母快速幂即可,时间复杂度\(O({\large log_2^n})\)。
参考代码:
il int db(int x,int y,int czf){
return (pow(x,y+1)-1+czf)*pow(x-1+czf,czf-2)%czf;
}
法二:二分(分治)
当n为奇数时,容易知道\((x^0+x^1+...+x^n)\%p=(x^0+..+x^{[n/2]}+x^{[n/2]+1}+...+x^n)\%p=\)
\((x^0+..+x^{[n/2]}+x^{[n/2]+1}(x^0+...+x^{n-[n/2]-1}))\%p=(x^0+..+x^{[n/2]}+x^{[n/2]+1}(x^0+...+x^{[n/2]}))\%p\)
\(=(x^{[n/2]+1}+1)(x^0+...+x^{[n/2]})\%p\)
当n为偶数时,快速幂求最后一项,剩下地作奇数处理,对于式子中还有一项要快速幂,其余按照分治下去即可,时间复杂度是\(O{\large (log_2^n)^2}\)。
参考代码
il int db(int x,int y){if(!y)return 1;
if(y&1)return db(x,y/2)*(pow(x,y/2+1)+1)%czf;
return (db(x,y-1)+pow(x,y))%czf;
}
法三:矩阵快速幂
可以将数列问题抽象化为递推方程,从而通过矩阵快速幂优化,设\(f_i\)为等比数列前缀和,自然有\(f_i=f_{i-1}+x^i\),于是可以写出其状态矩阵
转移矩阵
于是可以\(O({\large log_2^n})\)求解
参考代码:
struct matrix{
int jz[2][2];
il void clear(){memset(jz,0,sizeof(jz));}
il void unit(){clear(),jz[0][0]=jz[1][1]=1;}
il matrix operator*(matrix x){
matrix y;y.clear();
for(ri int i(0),j,k;i<2;++i)
for(j=0;j<2;y.jz[i][j]%=czf,++j)
for(k=0;k<2;++k)
y.jz[i][j]+=jz[i][k]*x.jz[k][j]%czf;
return y;
}template<class free>
il matrix operator^(free y){
matrix ans,x(*this);ans.unit();
while(y){
if(y&1)ans=ans*x;
x=x*x,y>>=1;
}return ans;
}
};
il int db(int x,int y){matrix state,tran;x%=czf;
state.jz[0][0]=x,state.jz[0][1]=1;
tran.jz[0][0]=x,tran.jz[0][1]=1;
tran.jz[1][0]=0,tran.jz[1][1]=1;
return (state*(tran^y)).jz[0][1];
}
法四:倍增
注意到一个问题可能直接递推过于复杂,但是倍增会让之容易递推,设\(f_i=x^0+x^1+...+x^{2^i}\),设\(g_i=x^{2^i}\),容易得知\(f_i=f_{i-1}g_{i-1}+f_{i-1}=f_{i-1}(g_{i-1}+1)\),预处理出这两个东西,接下来根据倍增套路拼接答案即可,时间复杂度\(O({\large log_2^n})\)。
参考代码
il int db(int x,int y){
int f[31],g[31],ans(0);
memset(f,0,sizeof(f));
memset(g,0,sizeof(g));
x%=czf,f[0]=g[0]=x;
for(int i(1);i<31;++i)
g[i]=g[i-1]*g[i-1]%czf,f[i]=(g[i-1]+1)*f[i-1]%czf;
for(int i(30),j(1);i>=0;--i)
if(1<<i<=y){(ans+=f[i]*j)%=czf;
(j*=g[i])%=czf,y-=1<<i;
}return (ans+1)%czf;
}
注:等比数列前缀和是oi重要考点,在下收集了4中方法,各有利弊,看各位所喜好。
快速求等差数列乘另一个数列的和
问题
求\(T_n=a_1f_1+a_2f_2+...+a_nf_n\),其中\(\{a_n\}\)为等差数列,等差数列公差d已知,第一项已知。
解
设等差数列第0项\(a_0=a_1-d\),显然有
设\(\{s_n\}\)为\(\{a_n\}\)前缀和,现有
不妨设\(\{g_n\}\)为\(\{s_n\}\)的前缀和,于是有
此时如果\(s_n\)比较好求,并且带动\(g_n\)好求已经圆满解决了(如fbi数列)
但是如果我们只能写出\(f_n\)的递推方程,并且可以用矩阵快速幂优化,不妨这样考虑,用矩阵快速幂优化,因为矩阵快速幂肯定可以优化前缀和,我们一个矩阵多次转移即可,设状态矩阵
那么有转移矩阵
这样我们就可以一次性求出\(s_n,g_{n-1}\),带入式子,然后求出\(T_n\),时间复杂度不难得知\(O(log_2^n)\)。
二分
整数上的二分——lower_bound 和upper_bound
分别表示返回递增序列中第一个大于等于比较的数和第一个大于的数
参考代码:
int lower_bound(int l,int r,int x,int a[]){
int mid;
while(l<=r){
mid=l+r>>1;
if(x>a[mid])l=mid+1;
else r=mid-1;
}
}
int upper_bound(int l,int r,int x,int a[]){
int mid;
while(l<=r){
mid=l+r>>1;
if(x<a[mid])r=mid-1;
else l=mid+1;
}
}
注:
- \(>>\)会好于除号,原因在于其向0取整,在负数也能正常工作
- 当问题不存在等于时,两种写法均可以
- 几种mid的写法,\(mid=l+r>>1\)mid取不到r,而\(mid=l+r+1>>1\),mid取不到l
三分
使用范围:一个单峰的函数,且峰的左右两侧的函数严格单调,接下来以只有最大值为例
参考代码:
int dfs(int l,int r){
int midl,midr;
while(l<r){
midl=l+(r-l+1)/3,midr=r-(r-l+1)/3;
if(a[midl]>a[midr])r=midr;
else l=midl;
}
}
二分式
定义
当问题需要求一个式子的最优解时,不妨把式子记做函数\(f(x)\),那么设\(f(x)=e\),则变形成\(g(x)-h(x)e=0\)为问题的二分式(\(g(x),h(x)\)为依靠\(f(x)\)变形出来的函数),当然式子要变形到可以二分的程度,问题就转化为只要判断该式子与0的关系,就可以知道是否存在更优解了。
处理办法(简单讲一下)
- 移项
- 合并
- 判断与0的关系
常见模型
- 可以判断方案的合法(通常贪心),通俗讲,可以简单地判断,大于最优解非法,小于最优解合法
- \(max(\text{增函数},\text{减函数})\)可以采取在线地三分(需要严格单调)或者单调队列离线维护
- 序列\(\{a_i\}\)最大子段和,从左至右连续选数,选的小于0就放弃。
- 交互问题中,用最少的次数得到某个答案
- 平均数问题(二分式解决)
- 01分数规划
一道帮助理解的例题
将长度为n的正整数序列\(\{a_i\}\)划分成m个区间,询问这些区间中区间和的最大值的最小值。
解
法一:递推+三分(伪做法)
区间划分问题,不妨考虑一下递推,设\(f[i][j]\)为前i个数划分成j个区间中的区间和的最大值的最小值,显然有
(设\(\{s_i\}\)为\(\{a_i\}\)的前缀和)
于是我们就可以\(O(n^3)\)转移了,但是我们需要更加优秀,注意到\(f[i][j]\)随i的递增而递增
求证:\(f[i][j]\)随i的递增而递增
证明:
假设不成立,那么必然有\(f[i][j]<f[i-1][j]\),那么此时将\(f[i][j]\)的划分方案,拷贝给\(f[i-1][j]\),显然少了最后一个元素,此时\(f[i-1][j]\)就变得至少比\(f[i][j]\)优秀了,即\(f[i-1][j\leq f[i][j]]\),因此矛盾,于是得证。
此外,注意到\(s[i]-s[k]\)随i的增大而增大,随\(k\)的增大而减小,问题存在浓厚的单调性,对于单调性,问题,我们考虑的方向有很多,可以考虑单调队列,平衡树,双堆对顶,二三分,于是我们选择了三分,你不难画出图像
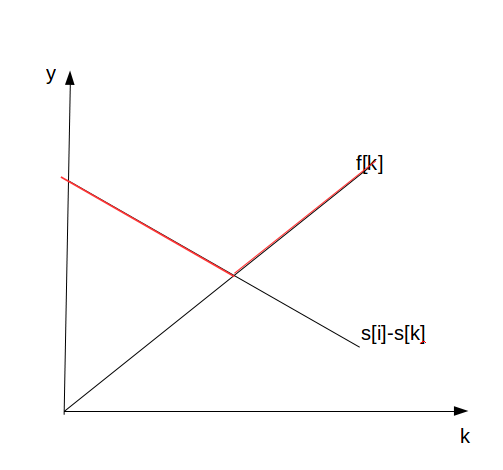
图中红色的线即递推方程的转移式,即\(\{max(f[k][j-1],s[i]-s[k])\}\),该函数存在一个最低点,于是想到用三分去求解,但是f并不是严格递增,故该做法为伪做法。
法二:递推+单调队列
注意到法1中不一定要用三分在线,我们可以单调队列离线,不妨维护最低点右边的函数,注意到函数\(s[i]-s[k]\)随着i的增大,是在向上平移的,那么最低点必然是向右平移的,那么我们只需要把最低点放到单调队列的队首,每次判断队首是否是最低点,以及把新来的决策点加入队尾即可。
法三:二分
同样是单调问题,为什么不考虑二分,不妨选取最优解为二分对象,记做e,接下来的问题是如何判断合法性了,从左至右划分区间,每个区间划分到尽可能大,但不能超过e,记划分的出的区间数为\(m'\),如果\(m'>m\)则答案偏大,否则偏小,于是可以二分做。
注:该例题并未给出数据范围,重在扩宽思路范围,打破知识壁垒,最后一句是ms的名言。
倍增
实现
对于重复的操作,一次转移2的指数幂次,通常2的指数幂次的递推方程转移会i比较好写,而又根据二进制拆分,容易知道任何一个数都能被一个二进制所表示,于是可以通过二的指数幂次的叠加到最终答案,做到时间复杂度\(O(logn)\)
标志
- 固定的重复的转移方向
- 同余
- 循环节
实现方式
- 从二进制高位到低位
- 从二进制低位到高位
注:各有优势,如1会比较好写,但是2有时可以通过维护巧妙降低时间复杂度,应该考虑全面,哪种是最好的。
完美例题
问题
给出一个长度为n的正整数序列\(\{a_i\}\),t次询问,每次询问给出一个p,询问最大的k满足\(\sum_{i=1}^ka_i\leq p\),其中\(n\leq 10^5\)。
解
法一:离线维护
这是一个询问维护,注意到问题并没有强制在线,于是考虑离线,通常离线会比在线好做,于是一次性读入所有询问,从小到大排序,这样所需要回答的答案k只会增加不会减少,于是\(O(n)\)扫描,就可以算出所有答案,总的时间复杂度应该是\(O(tlog^t)\)
法二:二分查找
不一定要离线维护,在线维护更加靠思维,虽然没办法只能前者,设\(\{s_i\}\)为\(\{a_i\}\)的前缀和,显然随着i的增大,序列是在增大的,具有单调性,可以考虑二分查找k,因此可以在\(O(tlog^n)\)内解决问题
法三:倍增
二进制优化,除了二分,还有二进制压缩,二进制拆分,倍增,不妨考虑倍增,而此题倍增也不一定要写出递推方程,对于每次询问,于是声明变量\(k,J\),初始化为\(k=0,J=1\),每次检查\(s_{k+2^j}\)与p的关系,如果大于p,则令\(--j\),否则\(k+=2^j,++J\),当\(J=0\)时,k就是答案。
应用——st表
问题
查询维护长度为n静态数列\(\{a_i\}\)的区间的最大值。(所谓静态数列也就是不会被修改的数列,最小值只是换个符号,没必要再讲一遍,读者自行举一反三)
办法
考虑二进制优化的倍增,设\(dp[i][j]\)为从第i个数字起向后数\(2^j\)个数的最大值,显然有递推方程
边界:\(dp[i][0]=a_i,i=1,2,3,...,n\)
于是对于待查询区间\([l,r]\)而言,设\(gzy=log_2(r-l+1)\),其结果应为\(max(dp[l][gzy],dp[r-2^{gzy}+1][gzy])\),显然用于求值这两段区间必然存在交叉关系,但是正因为存在交叉关系,所以结果才能覆盖整个区间,而对重复的数字取max是不会影响结果的。
参考代码:
struct ST{
int dp[Size][17];
il void prepare(int n,int a[]){
memset(dp,-1,sizeof(dp));
for(ri int i(1);i<=n;++i)dp[i][0]=a[i];
for(ri int i,j(1);j<17;++j)
for(i=1;i<=n;++i)
dp[i][j]=Max(dp[i][j-1],dp[Min(i+(1<<j-1),n)][j-1]);
}
il int ask(int l,int r){
ri int gzy(log(r-l+1)/log(2));
return Max(dp[l][gzy],dp[r-(1<<gzy)+1][gzy]);
}
il int Max(int a,int b){
return a>b?a:b;
}
il int Min(int a,int b){
return a<b?a:b;
}
};
尾声
我还是不知道这篇文章的意义和价值所在,但是毕竟还是放弃+坚持,最终搞出来,但愿对各位有所帮助吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号