4.K均值算法
1. 应用K-means算法进行图片压缩。
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
from sklearn.datasets import load_sample_imageimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansfrom pylab import mplimport sysimport numpy as npimport matplotlib.image as img# 指定字体,解决plot不能显示中文的问题mpl.rcParams['font.sans-serif'] = ['SimHei']china = load_sample_image("china.jpg") # 读取一张图片plt.imshow(china)plt.title("原图片")plt.show() # 显示图片img.imsave('D://img//china.jpg', china) print("图片占内存大小", sys.getsizeof(china)) print("图片数据结构", china.shape) image = china[::3, ::3]print("降低分辨率后图片的数据结构", image.shape)x = image.reshape(-1, 3) # 线性化print("线性化后的数据结构", x.shape)# 用kmeans对图片像素颜色进行聚类n_colors = 64 # (255,255,255)model = KMeans(n_colors) # 64类聚类中心labels = model.fit_predict(x) # 每个像素的颜色类别print("每个像素的颜色类别的数据结构", labels.shape)colors = model.cluster_centers_ # 每个类别的颜色print("每个类别的颜色的数据结构", colors.shape)new_image = colors[labels] # 以聚类中收替代原像素颜色new_image = new_image.reshape(image.shape) # ,还原为二维数组print("压缩图片占内存大小", sys.getsizeof(new_image)) # 压缩图片占内存大小new_image = new_image.astype(np.uint8)plt.imshow(new_image)plt.title("压缩后的图片")plt.show() # 显示图片img.imsave('D://img//new_china.jpg', new_image) # 保存图片,查看压缩图片的文件大小 |



2. 观察学习与生活中可以用K均值解决的问题。
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。

from sklearn.cluster import KMeans #导入kmeans算法
airline_scale = np.load('../tmp/airline_scale.npz')['arr_0']
k = 5 ## 确定聚类中心数
#构建模型
kmeans_model = KMeans(n_clusters = k,n_jobs=4,random_state=123)
fit_kmeans = kmeans_model.fit(airline_scale) #模型训练
kmeans_model.cluster_centers_ #查看聚类中心
kmeans_model.labels_ #查看样本的类别标签
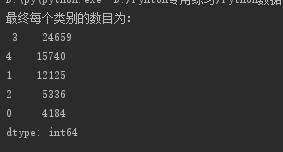
#统计不同类别样本的数目
r1 = pd.Series(kmeans_model.labels_).value_counts()
print('最终每个类别的数目为:\n',r1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号