

SparkSQL+Hive
我这里spark3.0.1+hive3.1.2
先启动Hive的metastore ----node2
nohup /usr/local/hive/bin/hive --service metastore &
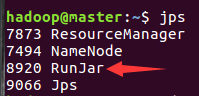
jps
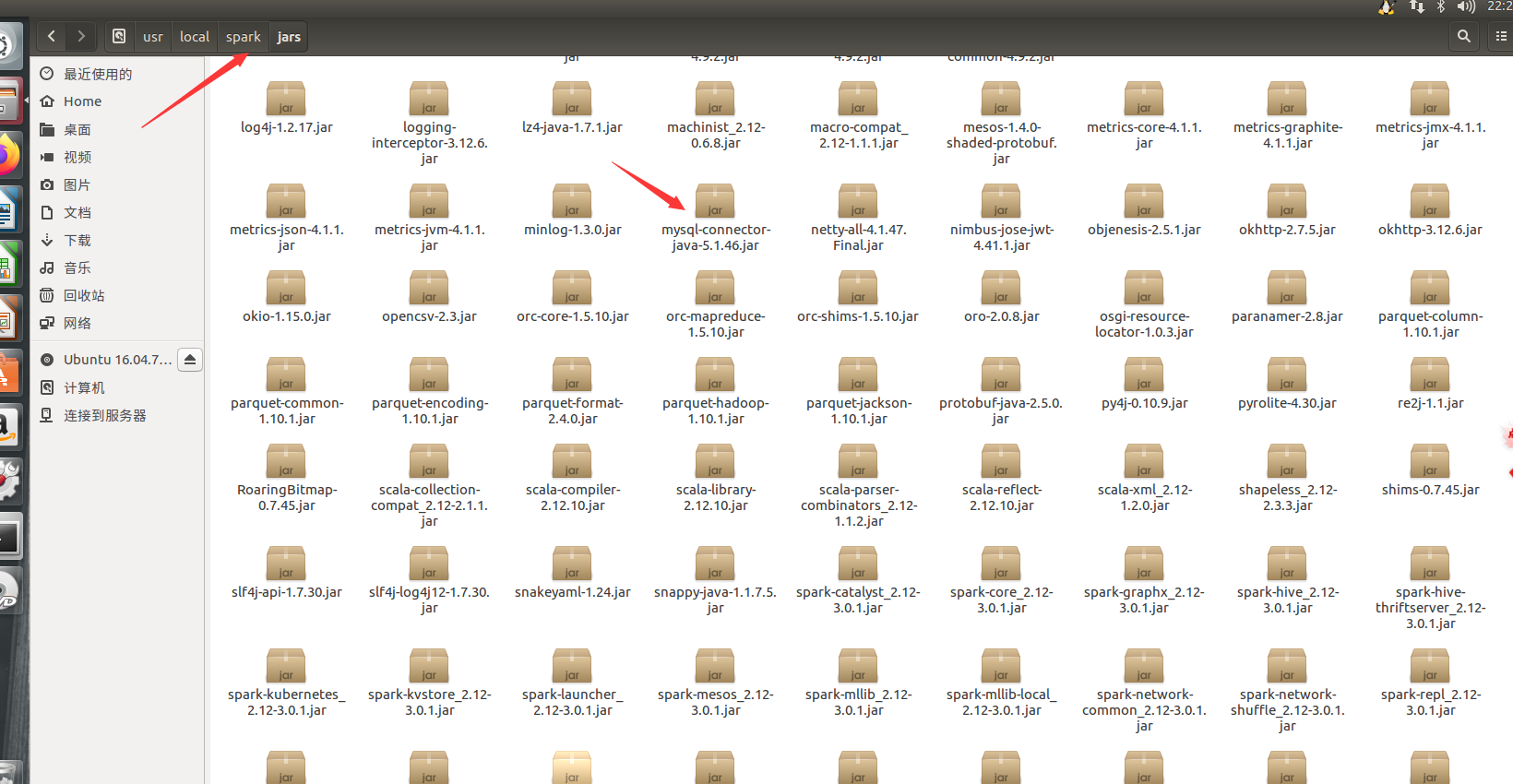
把hive的配置文件hive-site.xml拷贝到spark/conf目录,把mysql驱动上传到spark/jars里面--node1 (也可以把配置文件和jar分发到其他机器,在其他机器使用SparkSQL操作hive)
我的hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>datanucleus.readOnlyDatastore</name> <value>false</value> </property> <property> <name>datanucleus.fixedDatastore</name> <value>false</value> </property> <property> <name>datanucleus.autoCreateSchema</name> <value>true</value> </property> <property> <name>datanucleus.schema.autoCreateAll</name> <value>true</value> </property> <property> <name>datanucleus.autoCreateTables</name> <value>true</value> </property> <property> <name>datanucleus.autoCreateColumns</name> <value>true</value> </property> <property> <name>hive.metastore.local</name> <value>true</value> </property> <!-- 显示表的列名 --> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <!-- 显示数据库名称 --> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>192.168.58.128</value> </property> <property> <name>hive.server2.session.check.interval</name> <value>0</value> </property> </configuration>
启动hdfs服务
start-all.sh
启动spark/bin下的spark-sql命令行
cd /usr/local/spark/bin
spark-sql
执行sql语句--node1
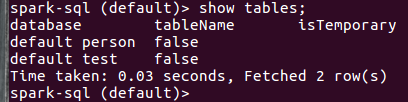
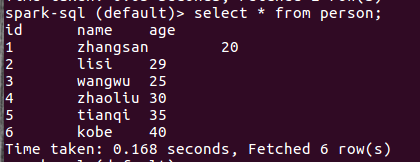
show databases; show tables; CREATE TABLE person (id int, name string, age int) row format delimited fields terminated by ' '; LOAD DATA LOCAL INPATH 'file:////home/hadoop/文档/person.txt' IN TABLE person; show tables; select * from person;

person.txt
1 zhangsan 20 2 lisi 29 3 wangwu 25 4 zhaoliu 30 5 tianqi 35 6 kobe 40
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
注意:需要先启动Hive的metastore
nohup /usr/local/hive/bin/hive --service metastore &
编写代码
package cn.itcast.sql import org.apache.spark.SparkContext import org.apache.spark.sql.expressions.UserDefinedFunction import org.apache.spark.sql.{Dataset, SparkSession} /** * Author itcast * Desc 演示SparkSQL-使用SparkSQL-UDF将数据转为大写 */ object Demo09_Hive { def main(args: Array[String]): Unit = { //TODO 0.准备环境---需要增加参数配置和开启hivesql语法支持 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .config("spark.sql.warehouse.dir", "hdfs://master:9000/user/hive/warehouse")//指定Hive数据库在HDFS上的位置 .config("hive.metastore.uris", "thrift://master:9083") .enableHiveSupport()//开启对hive语法的支持 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.操作Hive spark.sql("show databases").show(false) spark.sql("show tables").show(false) spark.sql("CREATE TABLE person4 (id int, name string, age int) row format delimited fields terminated by ' '") spark.sql("LOAD DATA LOCAL INPATH 'file:///D:/person.txt' INTO TABLE person4") spark.sql("show tables").show(false) spark.sql("select * from person4").show(false) spark.stop() } }
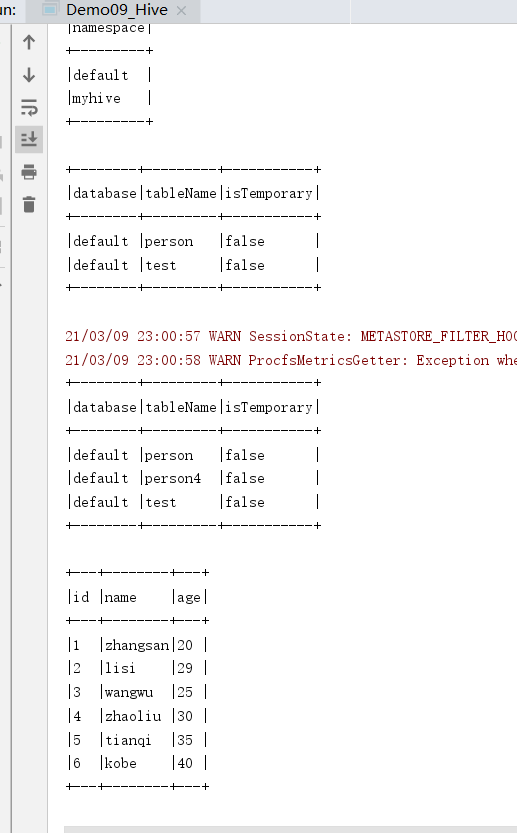
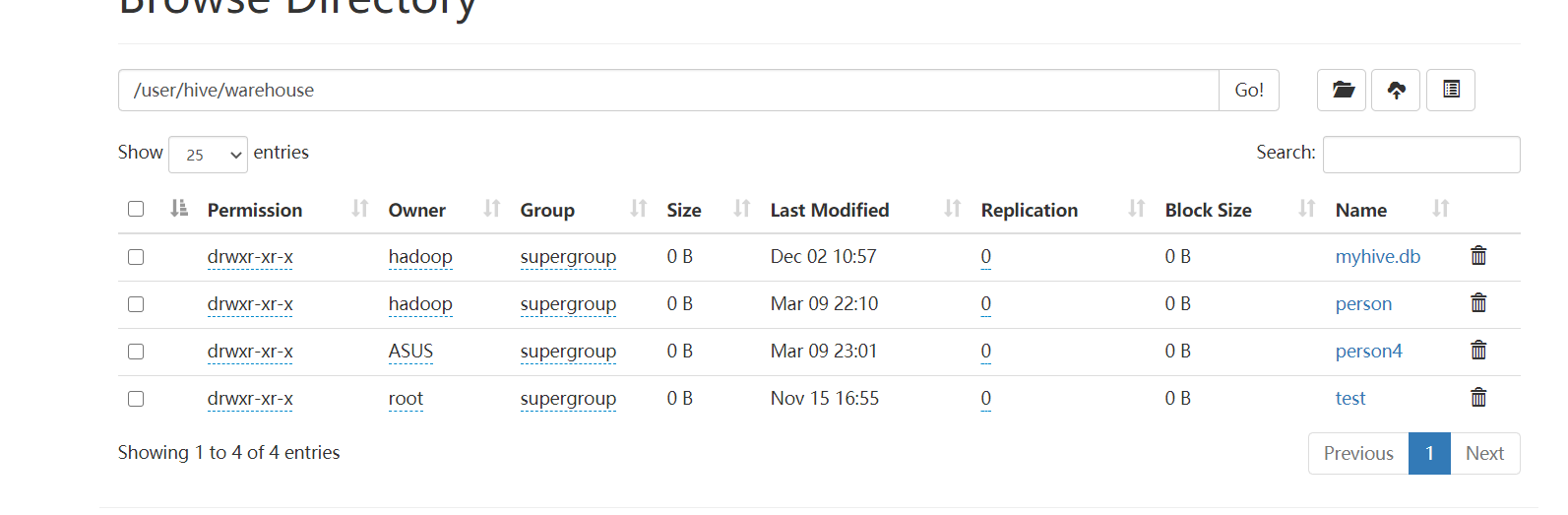

同样的SparkSQL也支持这样的访问方式:
1.SparkSQL的命令行
2.在某一台机器启动SparkSQL的ThriftServer,然后可以在其他机器使用beeline访问
nohup /usr/local/hive/bin/hive --service metastore &
启动SparkSQL的ThriftServer--类似于HiveServer2
cd /usr/local/spark/sbin/
start-thriftserver.sh
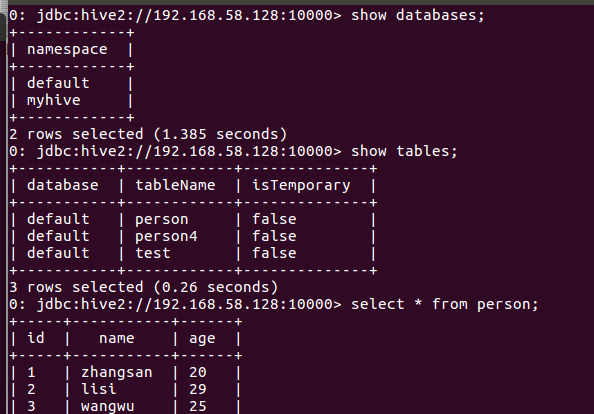
在其他机器(我这里全在master上)使用beeline连接sparkSQL的thriftserver
新开一个终端:
cd /usr/local/spark/bin
beeline
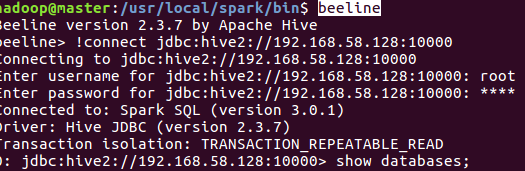
执行sql
show databases; show tables; select * from person;
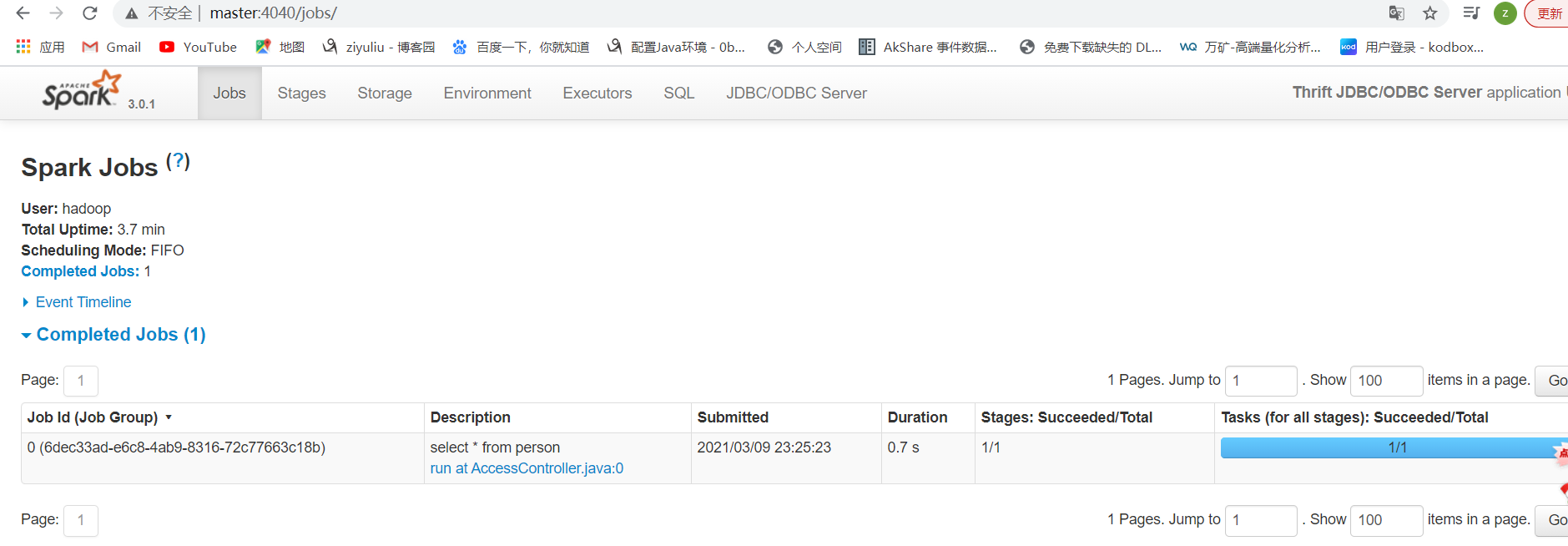
http://master:4040/jobs/
查看spark任务
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
使用jdbc代码访问SparkSQL-thriftserver_2
package cn.itcast.sql import java.sql.{Connection, DriverManager, PreparedStatement, ResultSet} /** * Author itcast * Desc 演示使用jdbc访问SparkSQL的ThriftServer */ object Demo10_ThriftServer{ def main(args: Array[String]): Unit = { //0.加载驱动 Class.forName("org.apache.hive.jdbc.HiveDriver") //1.获取连接 val conn: Connection = DriverManager.getConnection( "jdbc:hive2://master:10000/default", //看上去像是在使用Hive的server2,本质上使用Spark的ThriftServer "root", "4135" ) //2.编写sql val sql = """select id,name,age from person""" //3.获取预编译语句对象 val ps: PreparedStatement = conn.prepareStatement(sql) //4.执行sql val rs: ResultSet = ps.executeQuery() //5.处理结果 while (rs.next()){ val id: Int = rs.getInt("id") val name: String = rs.getString("name") val age: Int = rs.getInt("age") println(s"id=${id},name=${name},age=${age}") } //6.关闭资源 if(rs != null) rs.close() if(ps != null) ps.close() if(conn != null) conn.close() } }

关闭:
虚拟机上运行:
cd /usr/local/spark/sbin stop-thriftserver.sh
cd ~
stop-all.sh
