
模型选择与调优---交叉验证与网格搜索
为什么需要交叉验证
交叉验证目的:为了让被评估的模型更加准确可信
什么是交叉验证(cross validation)
交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。
分析
我们之前知道数据分为训练集和测试集,但是为了让从训练得到模型结果更加准确。做以下处理
- 训练集:训练集+验证集
- 测试集:测试集

问题:那么这个只是对于参数得出更好的结果,那么怎么选择或者调优参数呢?
超参数搜索-网格搜索(Grid Search)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。

模型选择与调优
sklearn.model_selection.GridSearchCV(estimator, param_grid=None,cv=None)
- 对估计器的指定参数值进行详尽搜索
- estimator:估计器对象
- param_grid:估计器参数(dict){“n_neighbors”:[1,3,5]}
- cv:指定几折交叉验证
- fit:输入训练数据
- score:准确率
- 结果分析:
- bestscore:在交叉验证中验证的最好结果_
- bestestimator:最好的参数模型
- cvresults:每次交叉验证后的验证集准确率结果和训练集准确率结果
from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import GridSearchCV def knn_iris_gscv(): """ 用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证 :return: """ # 1)获取数据 iris = load_iris() # 2)划分数据集 x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22) # 3)特征工程:标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4)KNN算法预估器 estimator = KNeighborsClassifier() # 加入网格搜索与交叉验证 # 参数准备 param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=10) estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict:\n", y_predict) print("直接比对真实值和预测值:\n", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为:\n", score) # 最佳参数:best_params_ print("最佳参数:\n", estimator.best_params_) # 最佳结果:best_score_ print("最佳结果:\n", estimator.best_score_) # 最佳估计器:best_estimator_ print("最佳估计器:\n", estimator.best_estimator_) # 交叉验证结果:cv_results_ print("交叉验证结果:\n", estimator.cv_results_) return None if __name__ == "__main__": # 代码2:用KNN算法对鸢尾花进行分类,添加网格搜索和交叉验证 knn_iris_gscv()

案例:预测签到位置

数据介绍:将根据用户的位置,准确性和时间戳预测用户正在查看的业务。
train.csv,test.csv
row_id:登记事件的ID
xy:坐标
准确性:定位准确性
时间:时间戳
place_id:业务的ID,这是您预测的目标
分析
-
对于数据做一些基本处理(这里所做的一些处理不一定达到很好的效果,我们只是简单尝试,有些特征我们可以根据一些特征选择的方式去做处理)
-
1、缩小数据集范围 DataFrame.query()
-
4、删除没用的日期数据 DataFrame.drop(可以选择保留)
-
5、将签到位置少于n个用户的删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id > 3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
-
-
分割数据集
-
标准化处理
-
k-近邻预测
import pandas as pd # 1、获取数据 data = pd.read_csv("./FBlocation/train.csv") data.head()
# 2、基本的数据处理 # 1)缩小数据范围 data = data.query("x < 2.5 & x > 2 & y < 2.5 & y > 1.0") data.head()
# 2)处理时间特征 time_value = pd.to_datetime(data["time"], unit="s") date = pd.DatetimeIndex(time_value) data["day"] = date.day data["weekday"] = date.weekday data["hour"] = date.hour data.head()
# 3)过滤签到次数少的地点 place_count = data.groupby("place_id").count()["row_id"]
data.groupby("place_id").count().head()
place_count[place_count > 3].head()
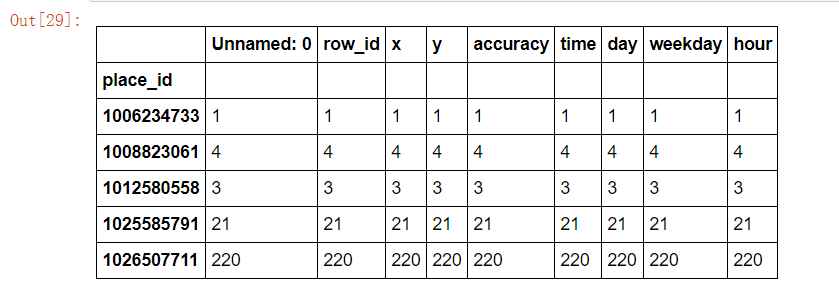
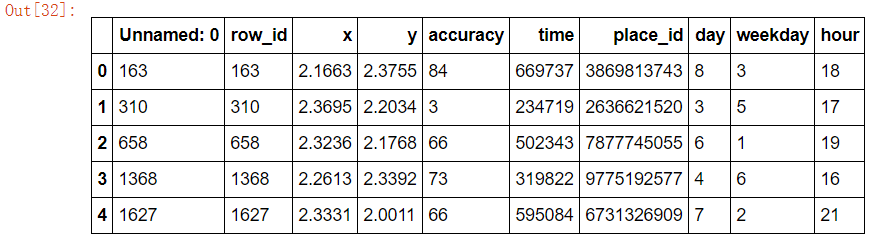
data_final = data[data["place_id"].isin(place_count[place_count > 3].index.values)] data_final.head()
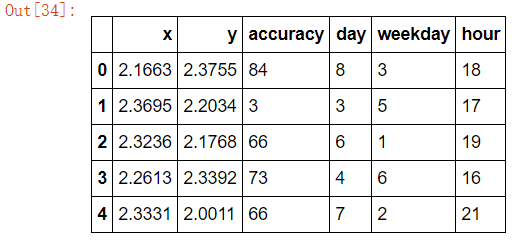
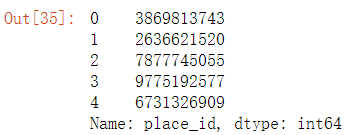
# 筛选特征值和目标值 x = data_final[["x", "y", "accuracy", "day", "weekday", "hour"]] y = data_final["place_id"]
x.head()
y.head()
# 数据集划分 from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y) from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsClassifier from sklearn.model_selection import GridSearchCV # 3)特征工程:标准化 transfer = StandardScaler() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 4)KNN算法预估器 estimator = KNeighborsClassifier() # 加入网格搜索与交叉验证 # 参数准备 param_dict = {"n_neighbors": [3, 5, 7, 9]} estimator = GridSearchCV(estimator, param_grid=param_dict, cv=3) estimator.fit(x_train, y_train) # 5)模型评估 # 方法1:直接比对真实值和预测值 y_predict = estimator.predict(x_test) print("y_predict:\n", y_predict) print("直接比对真实值和预测值:\n", y_test == y_predict) # 方法2:计算准确率 score = estimator.score(x_test, y_test) print("准确率为:\n", score) # 最佳参数:best_params_ print("最佳参数:\n", estimator.best_params_) # 最佳结果:best_score_ print("最佳结果:\n", estimator.best_score_) # 最佳估计器:best_estimator_ print("最佳估计器:\n", estimator.best_estimator_) # 交叉验证结果:cv_results_ print("交叉验证结果:\n", estimator.cv_results_)
结果:
y_predict: [1763501324 8805392384 5806536504 ... 4324144553 8636259224 9854557730] 直接比对真实值和预测值: 62471 False 68137 True 71565 True 31035 False 36975 True 11806 True 18851 False 47924 True 53340 False 61916 False 19798 True 41239 True 70474 False 20649 False 495 False 30741 True 50254 False 46577 False 48649 False 5230 True 10345 True 38856 False 66664 False 63187 False 21734 False 29047 True 65268 False 33937 False 43012 False 29349 True ... 11089 False 42658 False 521 True 11641 False 62860 False 30482 True 28088 True 45868 False 5442 True 49813 False 13207 False 62306 False 47937 False 16489 False 24697 True 51320 False 57418 False 13740 True 10727 True 33412 False 57426 True 24581 False 34841 False 65037 False 28216 False 44388 True 16529 False 32353 False 11631 True 3756 True Name: place_id, Length: 17316, dtype: bool 准确率为: 0.37583737583737586 最佳参数: {'n_neighbors': 5} 最佳结果: 0.3385693385693386 最佳估计器: KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski', metric_params=None, n_jobs=1, n_neighbors=5, p=2, weights='uniform') 交叉验证结果: {'std_train_score': array([0.00225242, 0.00080688, 0.00224685, 0.00241526]), 'split2_test_score': array([0.33309805, 0.34486207, 0.3414505 , 0.33921534]), 'rank_test_score': array([4, 1, 2, 3]), 'split0_test_score': array([0.32239043, 0.33151897, 0.33242615, 0.32800363]), 'mean_score_time': array([0.71891824, 0.77411079, 0.81740459, 0.85257316]), 'mean_test_score': array([0.32782783, 0.33856934, 0.33743359, 0.33414183]), 'mean_train_score': array([0.59913452, 0.52830304, 0.48853409, 0.46089939]), 'std_score_time': array([0.01935619, 0.01170428, 0.01074588, 0.02470553]), 'param_n_neighbors': masked_array(data=[3, 5, 7, 9], mask=[False, False, False, False], fill_value='?', dtype=object), 'std_test_score': array([0.00437858, 0.00549282, 0.00377355, 0.00466418]), 'split1_test_score': array([0.3281918 , 0.3395725 , 0.33859041, 0.33541306]), 'split1_train_score': array([0.60000577, 0.52875455, 0.48810555, 0.4590623 ]), 'params': [{'n_neighbors': 3}, {'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}], 'split0_train_score': array([0.60135234, 0.52898487, 0.49147504, 0.46431174]), 'std_fit_time': array([0.0017271 , 0.00057357, 0.00338652, 0.00039472]), 'mean_fit_time': array([0.0428369 , 0.04024029, 0.04432511, 0.04046241]), 'split2_train_score': array([0.59604544, 0.52716971, 0.48602169, 0.45932412])}

