Python的基本Protobuf指南(序列化数据)
![]()
协议缓冲区(Protobuf)是Google开发的与语言无关的数据序列化格式。Protobuf之所以出色,原因如下:
- 数据量低: Protobuf使用二进制格式,该格式比JSON等其他格式更紧凑。
- 持久性: Protobuf序列化是向后兼容的。这意味着即使接口在此期间发生了更改,您也可以始终还原以前的数据。
- 按合同设计: Protobuf要求使用显式标识符和类型来规范消息。
- gRPC的要求: gRPC(gRPC远程过程调用)是一种利用Protobuf格式的高效远程过程调用系统。
就个人而言,我最喜欢Protobuf的是,如果强迫开发人员明确定义应用程序的接口。这是一个改变规则的游戏,因为它使所有利益相关者都能理解界面设计并为之做出贡献。
在这篇文章中,我想分享我在Python应用程序中使用Protobuf的经验。
安装Protobuf
对于大多数系统,Protobuf必须从源代码安装。在下面,我描述了Unix系统的安装:
1.从Git下载最新的Protobuf版本:
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.12.4/protobuf-all-3.12.4.tar.gz
2.解压缩
tar -xzf protobuf-all-3.12.4.tar.gz
3.安装:
cd protobuf-3.12.4/ && ./configure && make && sudo make install
4.验证安装(protoc现在应该可用!)
protoc
protoc --version
一旦原型编译器可用,我们就可以开始。
1. Protobuf消息的定义
要使用Protobuf,我们首先需要定义我们要传输的消息。消息在.proto文件内定义。请考虑官方文档以获取协议缓冲区语言的详细信息。在这里,我仅提供一个简单的示例,旨在展示最重要的语言功能。
假设我们正在开发一个类似Facebook的社交网络,该社交网络完全是关于人及其联系的。这就是为什么我们要为一个人建模消息。
一个人具有某些固有的特征(例如年龄,性别,身高),还具有我们需要建模的某些外在特征(例如朋友,爱好)。让我们存储以下定义src/interfaces/person.proto:
syntax = "proto3";
import "generated/person_info.proto";
package persons;
message Person {
PersonInfo info = 1; // characteristics of the person
repeated Friend friends = 2; // friends of the person
}
message Friend {
float friendship_duration = 1; // duration of friendship in days
repeated string shared_hobbies = 2; // shared interests
Person person = 3; // identity of the friend
}
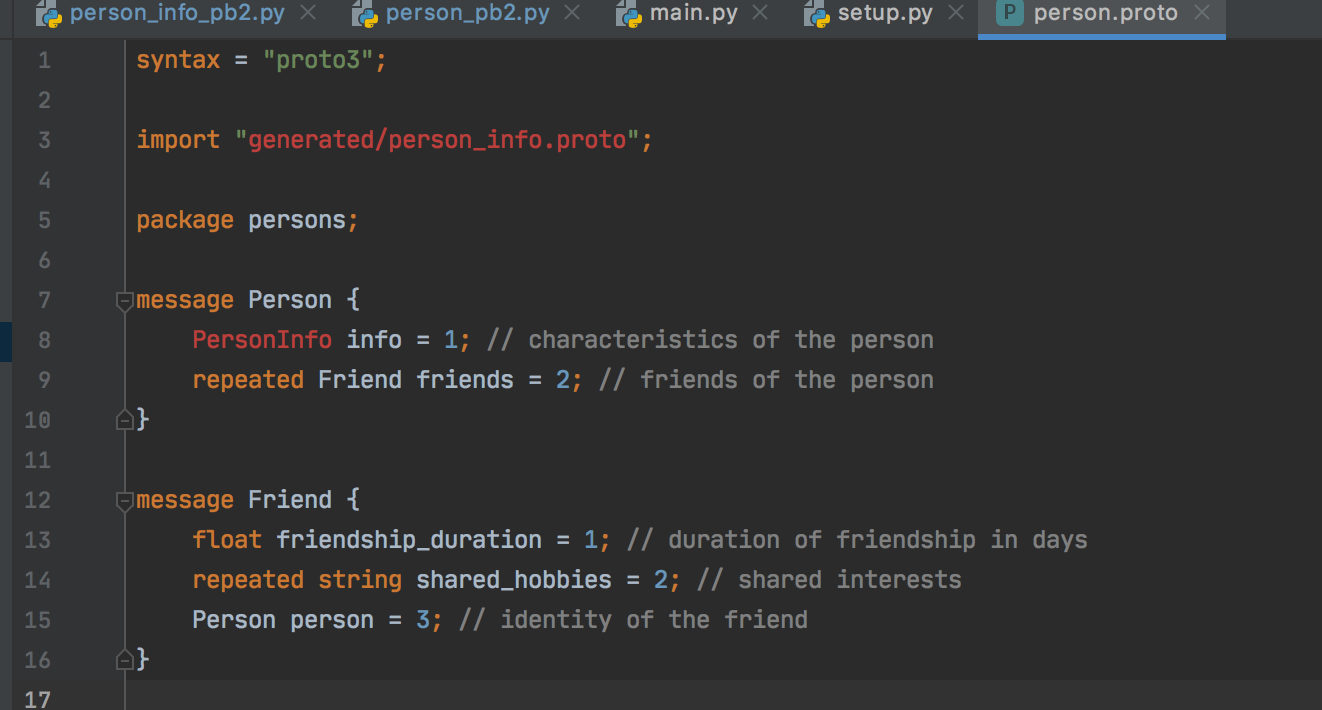
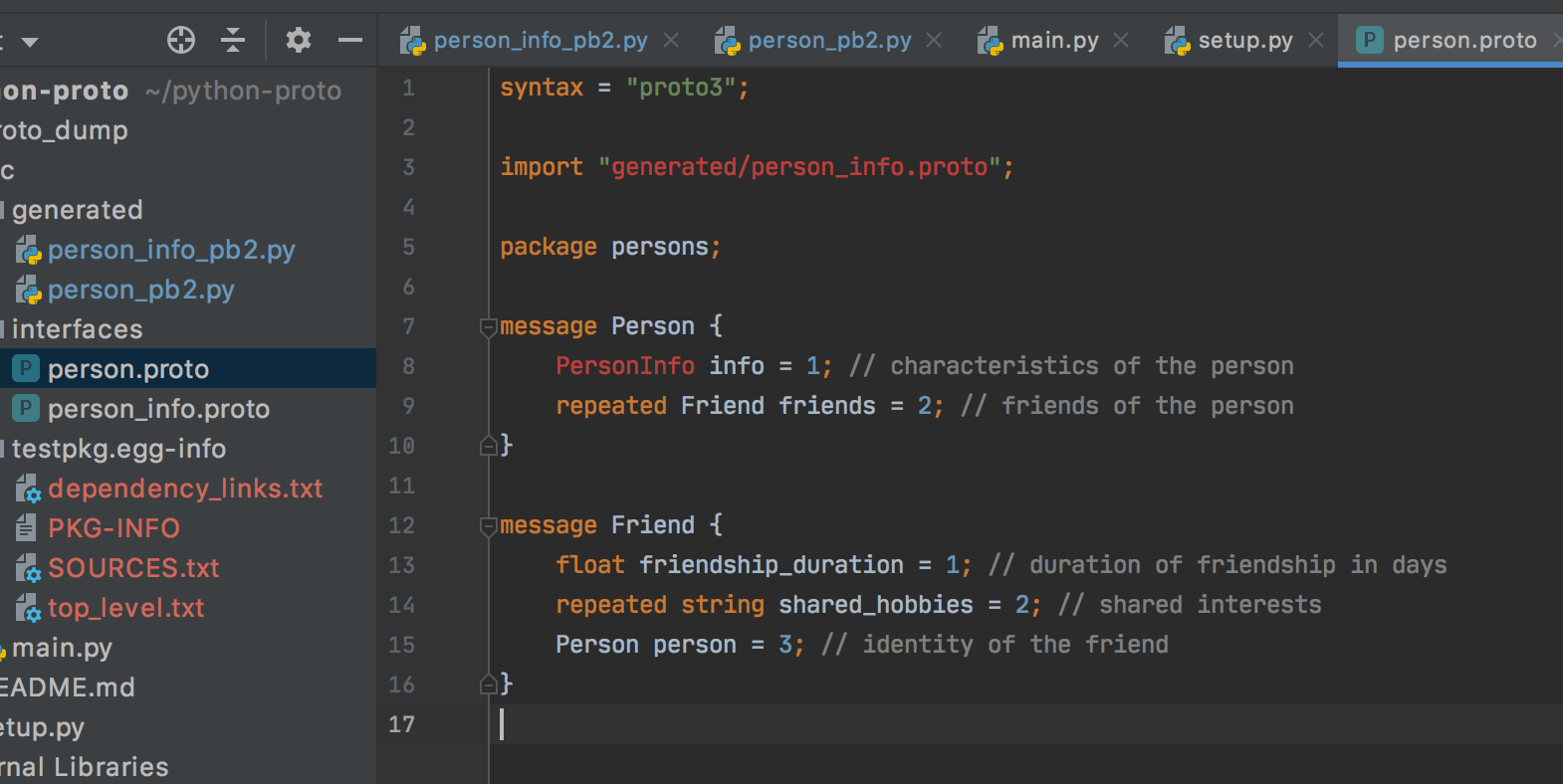
请注意,我们引用的是另一个原始文件,generated/person_info.proto我们将其定义为:
syntax = "proto3";
package persons;
enum Sex {
M = 0; // male
F = 1; // female
O = 2; // other
}
message PersonInfo {
int32 age = 1; // age in years
Sex sex = 2;
int32 height = 3; // height in cm
}
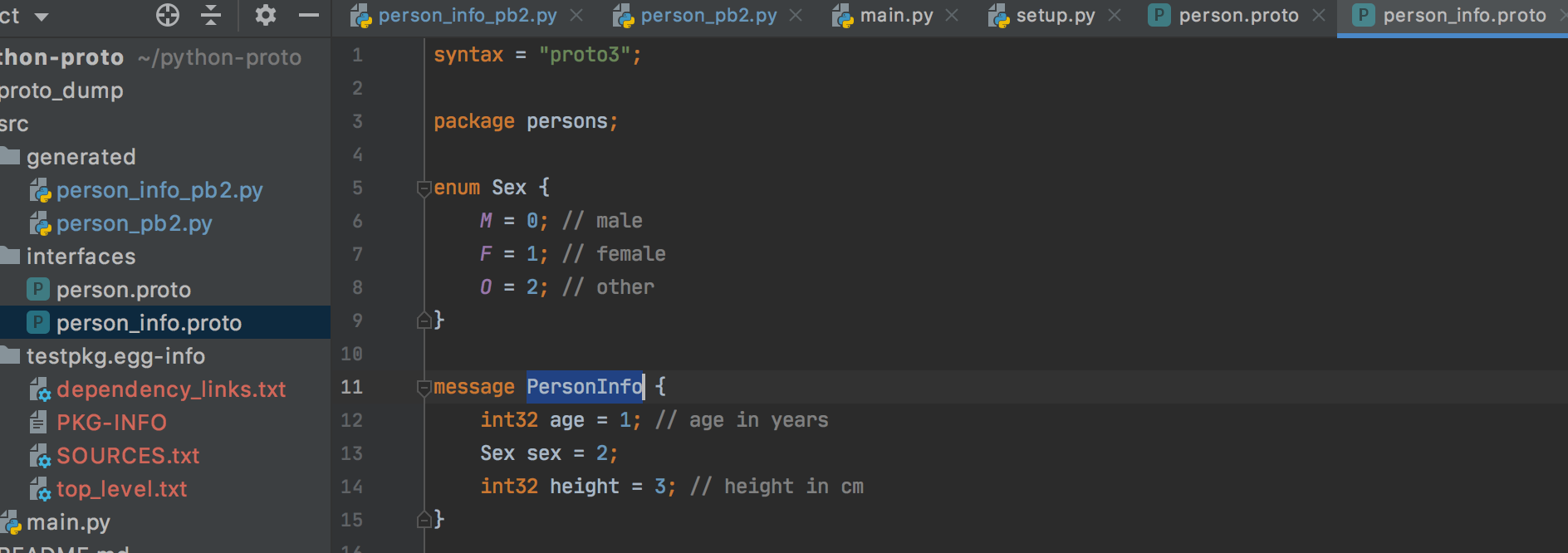
不用担心这些定义对您还没有意义,我现在将解释最重要的关键字:
- 语法:语法定义了规范使用哪个版本的Protobuf。我们正在使用
proto3。 - import:如果根据另一条消息定义了一条消息,则需要使用
import语句将其包括在内。您可能想知道为什么导入person.proto?我们稍后将对此进行更深入的研究-现在仅知道这是由于Python的导入系统所致。generated/person_info.protointerfaces/person_info.proto - package:包定义了属于同一名称空间的消息。这样可以防止名称冲突。
- enum:一个枚举定义一个枚举类型。
- messsage:消息是我们想使用Protobuf建模的一条信息。
- repeat:
repeated关键字指示一个变量,该变量被解释为向量。在我们的情况下,friends是Friend消息的向量。
还要注意,每个消息属性都分配有一个唯一的编号。该编号对于协议的向后兼容是必需的:一旦将编号分配给字段,则不应在以后的时间点对其进行修改。
现在我们有了应用程序的基本原型定义,我们可以开始生成相应的Python代码了。
2.原始文件的编译
要将原始文件编译为Python对象,我们将使用Protobuf编译器protoc。
我们将使用以下选项调用原型编译器:
--python_out:将存储已编译的Python文件的目录--proto_path:由于原始文件不在项目的根文件夹中,因此我们需要使用替代文件。通过指定generated=./src/interfaces,编译器知道在导入其他原始消息时,我们要使用生成文件的路径(generated),而不是接口的位置(src/interfaces)。
有了这种了解,我们可以像下面这样编译原始文件:
mkdir src/generated protoc src/interfaces/person_info.proto --python_out src/ --proto_path generated=./src/interfaces/ protoc src/interfaces/person.proto --python_out src/ --proto_path generated=./src/interfaces/
执行完这些命令后,文件generated/person_pb2.py和generated/person_info_pb2.py应该存在。例如, person_pb2.py如下所示:
_PERSON = _descriptor.Descriptor(
name='Person',
full_name='persons.Person',
filename=None,
file=DESCRIPTOR,
containing_type=None,
create_key=_descriptor._internal_create_key,
fields=[
...
![]()
生成的Python代码并非真正可读。但这没关系,因为我们只需要知道person_pb2.py可以用于构造可序列化的Protobuf对象即可。
3. Protobuf对象的序列化
在我们以有意义的方式序列化Protobuf对象之前,我们需要用一些数据填充它。让我们生成一个有一个朋友的人:
# fill protobuf objects
import generated.person_pb2 as person_pb2
import generated.person_info_pb2 as person_info_pb2
############
# define friend for person of interest
#############
friend_info = person_info_pb2.PersonInfo()
friend_info.age = 40
friend_info.sex = person_info_pb2.Sex.M
friend_info.height = 165
friend_person = person_pb2.Person()
friend_person.info.CopyFrom(friend_info)
friend_person.friends.extend([]) # no friends :-(
#######
# define friendship characteristics
########
friendship = person_pb2.Friend()
friendship.friendship_duration = 365.1
friendship.shared_hobbies.extend(["books", "daydreaming", "unicorns"])
friendship.person.CopyFrom(friend_person)
#######
# assign the friend to the friend of interest
#########
person_info = person_info_pb2.PersonInfo()
person_info.age = 30
person_info.sex = person_info_pb2.Sex.M
person_info.height = 184
person = person_pb2.Person()
person.info.CopyFrom(person_info)
person.friends.extend([friendship]) # person with a single friend
请注意,我们通过直接分配填充了所有琐碎的数据类型(例如,整数,浮点数和字符串)。仅对于更复杂的数据类型,才需要使用其他一些功能。例如,我们利用extend来填充重复的Protobuf字段并CopyFrom填充Protobuf子消息。
要序列化Protobuf对象,我们可以使用SerializeToString()函数。此外,我们还可以使用以下str()函数将Protobuf对象输出为人类可读的字符串:
# serialize proto object
import os
out_dir = "proto_dump"
with open(os.path.join(out_dir, "person.pb"), "wb") as f:
# binary output
f.write(person.SerializeToString())
with open(os.path.join(out_dir, "person.protobuf"), "w") as f:
# human-readable output for debugging
f.write(str(person))
执行完代码段后,可以在proto_dump/person.protobuf以下位置找到生成的人类可读的Protobuf消息:
info {
age: 30
height: 184
}
friends {
friendship_duration: 365.1000061035156
shared_hobbies: "books"
shared_hobbies: "daydreaming"
shared_hobbies: "unicorns"
person {
info {
age: 40
height: 165
}
}
}
请注意,此人的信息既不显示该人的性别,也不显示其朋友的性别。这不是Bug,而是Protobuf的功能:0永远不会打印值为的条目。sex由于这两个人都是男性,因此此处未显示0。
4.自动化的Protobuf编译
在开发过程中,每次更改后必须重新编译原始文件可能会变得很乏味。要在安装开发Python软件包时自动编译原始文件,我们可以使用该setup.py脚本。
让我们创建一个函数,该函数为.proto目录中的所有文件生成Protobuf代码src/interfaces并将其存储在下src/generated:
import pathlib
import os
from subprocess import check_call
def generate_proto_code():
proto_interface_dir = "./src/interfaces"
generated_src_dir = "./src/generated/"
out_folder = "src"
if not os.path.exists(generated_src_dir):
os.mkdir(generated_src_dir)
proto_it = pathlib.Path().glob(proto_interface_dir + "/**/*")
proto_path = "generated=" + proto_interface_dir
protos = [str(proto) for proto in proto_it if proto.is_file()]
check_call(["protoc"] + protos + ["--python_out", out_folder, "--proto_path", proto_path])
接下来,我们需要覆盖develop命令,以便每次安装软件包时都调用该函数:
from setuptools.command.develop import develop
from setuptools import setup, find_packages
class CustomDevelopCommand(develop):
"""Wrapper for custom commands to run before package installation."""
uninstall = False
def run(self):
develop.run(self)
def install_for_development(self):
develop.install_for_development(self)
generate_proto_code()
setup(
name='testpkg',
version='1.0.0',
package_dir={'': 'src'},
cmdclass={
'develop': CustomDevelopCommand, # used for pip install -e ./
},
packages=find_packages(where='src')
)
下次我们运行时pip install -e ./,Protobuf文件将在中自动生成src/generated。
我们节省多少空间?
之前,我提到Protobuf的优点之一是其二进制格式。在这里,我们将通过比较Protobuf消息的大小和Person相应的JSON来考虑此优势:
"person": {
"info": {
"age": 30,
"height": 184
},
"friends": {
"friendship_duration": 365.1000061035156,
"shared_hobbies": ["books", "daydreaming", "unicorns"],
"person": {
"info": {
"age": 40,
"height": 165
}
}
}
}
比较JSON和Protobuf文本表示形式,结果发现JSON实际上更紧凑,因为它的列表表示形式更加简洁。但是,这令人产生误解,因为我们对二进制Protobuf格式感兴趣。
当比较Person对象的二进制Protobuf和JSON占用的字节数时,我们发现以下内容:
du -b person.pb
53 person.pb
du -b person.json
304 person.json
在这里,Protobuf比JSON小5倍
二进制Protobuf(53个字节)比相应的JSON(304个字节)小5倍以上。请注意,如果我们使用gRPC协议传输二进制Protobuf,则只能达到此压缩级别。
如果不选择gRPC,则常见的模式是使用base64编码对二进制Protobuf数据进行编码。尽管此编码不可撤销地将有效载荷的大小增加了33%,但仍比相应的REST有效载荷小得多。
概要
Protobuf是数据序列化的理想格式。它比JSON小得多,并且允许接口的显式定义。由于其良好的性能,我建议在所有使用足够复杂数据的项目中使用Protobuf。尽管Protobuf需要初步的时间投入,但我敢肯定它会很快得到回报。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号