python 常见模块
#windows查看系统返回值命令 echo %ERRORLEVEL% #linux查看系统返回值命令 echo $?
os模块:
os模块是两大核心系统模块中较大的那个,它包含了在C程序和shell脚本中经常用到的所有操作系统调用。
os模块可以轻松实现不依赖于平台的操作系统调用,用os和os.path编写的脚本通常无需改动即可在其他平台上运行。
os.remove() 删除文件 os.unlink() 删除文件 os.rename() 重命名文件 os.listdir() 列出指定目录下所有文件 os.chdir() 改变当前工作目录 os.getcwd() 获取当前文件路径 os.mkdir() 新建目录 os.rmdir() 删除空目录(删除非空目录, 使用shutil.rmtree()) os.makedirs() 创建多级目录 os.removedirs() 删除多级目录 os.stat(file) 获取文件属性 os.chmod(file) 修改文件权限 os.utime(file) 修改文件时间戳 os.name(file) 获取操作系统标识 os.system() 执行操作系统命令 os.execvp() 启动一个新进程 os.fork() 获取父进程ID,在子进程返回中返回0 os.execvp() 执行外部程序脚本(Uinx) os.spawn() 执行外部程序脚本(Windows) os.access(path, mode) 判断文件权限(详细参考cnblogs) os.wait() 暂时未知 os.path模块: os.path.split(filename) 将文件路径和文件名分割(会将最后一个目录作为文件名而分离) os.path.splitext(filename) 将文件路径和文件扩展名分割成一个元组 os.path.dirname(filename) 返回文件路径的目录部分 os.path.basename(filename) 返回文件路径的文件名部分 os.path.join(dirname,basename) 将文件路径和文件名凑成完整文件路径 os.path.abspath(name) 获得绝对路径 os.path.splitunc(path) 把路径分割为挂载点和文件名 os.path.normpath(path) 规范path字符串形式 os.path.exists() 判断文件或目录是否存在 os.path.isabs() 如果path是绝对路径,返回True os.path.realpath(path) #返回path的真实路径 os.path.relpath(path[, start]) #从start开始计算相对路径 os.path.normcase(path) #转换path的大小写和斜杠 os.path.isdir() 判断name是不是一个目录,name不是目录就返回false os.path.isfile() 判断name是不是一个文件,不存在返回false os.path.islink() 判断文件是否连接文件,返回boolean os.path.ismount() 指定路径是否存在且为一个挂载点,返回boolean os.path.samefile() 是否相同路径的文件,返回boolean os.path.getatime() 返回最近访问时间 浮点型 os.path.getmtime() 返回上一次修改时间 浮点型 os.path.getctime() 返回文件创建时间 浮点型 os.path.getsize() 返回文件大小 字节单位 os.path.commonprefix(list) #返回list(多个路径)中,所有path共有的最长的路径 os.path.lexists #路径存在则返回True,路径损坏也返回True os.path.expanduser(path) #把path中包含的”~”和”~user”转换成用户目录 os.path.expandvars(path) #根据环境变量的值替换path中包含的”$name”和”${name}” os.path.sameopenfile(fp1, fp2) #判断fp1和fp2是否指向同一文件 os.path.samestat(stat1, stat2) #判断stat tuple stat1和stat2是否指向同一个文件 os.path.splitdrive(path) #一般用在windows下,返回驱动器名和路径组成的元组 os.path.walk(path, visit, arg) #遍历path,给每个path执行一个函数详细见手册 os.path.supports_unicode_filenames() 设置是否支持unicode路径名
stat模块:
描述os.stat()返回的文件属性列表中各值的意义 fileStats = os.stat(path) 获取到的文件属性列表 fileStats[stat.ST_MODE] 获取文件的模式 fileStats[stat.ST_SIZE] 文件大小 fileStats[stat.ST_MTIME] 文件最后修改时间 fileStats[stat.ST_ATIME] 文件最后访问时间 fileStats[stat.ST_CTIME] 文件创建时间 stat.S_ISDIR(fileStats[stat.ST_MODE]) 是否目录 stat.S_ISREG(fileStats[stat.ST_MODE]) 是否一般文件 stat.S_ISLNK(fileStats[stat.ST_MODE]) 是否连接文件 stat.S_ISSOCK(fileStats[stat.ST_MODE]) 是否COCK文件 stat.S_ISFIFO(fileStats[stat.ST_MODE]) 是否命名管道 stat.S_ISBLK(fileStats[stat.ST_MODE]) 是否块设备 stat.S_ISCHR(fileStats[stat.ST_MODE]) 是否字符设置
sys模块:
MAC

win

用于提供对解释器相关的访问及维护,并有很强的交互功能 常用函数: sys.argv --传参,第一个参数为脚本名称即argv[0] sys.path --模块搜索路径 sys.moudule --加载模块字典 sys.stdin --标准输入 sys.stdout --标准输出 sys.stderr --错误输出 sys.platform --返回系统平台名称 sys.version --查看python版本 sys.maxsize --最大的Int值
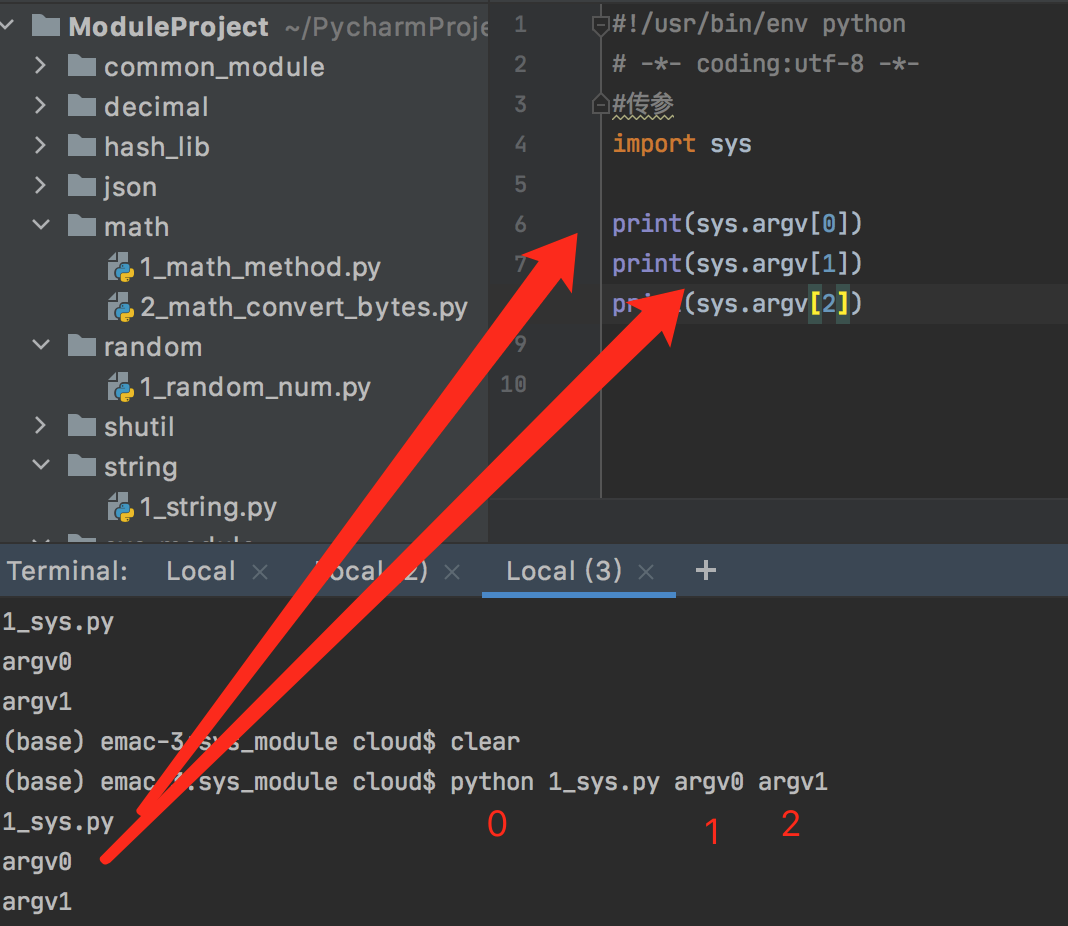
(base) emac-3:sys_module cloud$ python 1_sys.py argv0 argv1 1_sys.py argv0 argv1
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.modules.keys() 返回所有已经导入的模块列表 sys.modules 返回系统导入的模块字段,key是模块名,value是模块 sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback当前处理的异常详细信息 sys.exit(n) 退出程序,正常退出时exit(0) sys.exit()系统返回值 sys.hexversion 获取Python解释程序的版本值,16进制格式如:0x020403F0 sys.version 获取Python解释程序的版本信息 sys.platform 返回操作系统平台名称 sys.stdout 标准输出 sys.stdout.write(‘aaa‘) 标准输出内容 sys.stdout.writelines() 无换行输出 sys.stdin 标准输入 sys.stdin.read() 输入一行 sys.stderr 错误输出 sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息 sys.exec_prefix 返回平台独立的python文件安装的位置 sys.byteorder 本地字节规则的指示器,big-endian平台的值是‘big‘,little-endian平台的值是‘little‘ sys.copyright 记录python版权相关的东西 sys.api_version 解释器的C的API版本 sys.version_info ‘final‘表示最终,也有‘candidate‘表示候选,表示版本级别,是否有后继的发行 sys.getdefaultencoding() 返回当前你所用的默认的字符编码格式 sys.getfilesystemencoding() 返回将Unicode文件名转换成系统文件名的编码的名字 sys.builtin_module_names Python解释器导入的内建模块列表 sys.executable Python解释程序路径 sys.getwindowsversion() 获取Windows的版本 sys.stdin.readline() 从标准输入读一行,sys.stdout.write(“a”) 屏幕输出a sys.setdefaultencoding(name) 用来设置当前默认的字符编码(详细使用参考文档) sys.displayhook(value) 如果value非空,这个函数会把他输出到sys.stdout(详细使用参考文档)
python报错:type object ‘datetime.datetime’ has no attribute ‘datetime’
描述:在第一个python程序里还未报错,第二个程序完全复制过来,导入模块from datetime import datetime ,运行就报错了
原因:被2个相同的datetime给迷惑了,其实2个datetime不是在一个级别上的东西,一个是模块,一个是类。
解决办法:导入模块的from datetime import datetime改成import datetime。
time模块中时间表现的格式主要有三种:
a、timestamp时间戳,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
b、struct_time时间元组,共有九个元素组。
c、format time 格式化时间,已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
1、时间格式转换图:

format time结构化表示
| 格式 | 含义 |
| %a | 本地(locale)简化星期名称 |
| %A | 本地完整星期名称 |
| %b | 本地简化月份名称 |
| %B | 本地完整月份名称 |
| %c | 本地相应的日期和时间表示 |
| %d | 一个月中的第几天(01 - 31) |
| %H | 一天中的第几个小时(24小时制,00 - 23) |
| %I | 第几个小时(12小时制,01 - 12) |
| %j | 一年中的第几天(001 - 366) |
| %m | 月份(01 - 12) |
| %M | 分钟数(00 - 59) |
| %p | 本地am或者pm的相应符 |
| %S | 秒(01 - 61) |
| %U | 一年中的星期数。(00 - 53星期天是一个星期的开始。)第一个星期天之前的所有天数都放在第0周。 |
| %w | 一个星期中的第几天(0 - 6,0是星期天) |
| %W | 和%U基本相同,不同的是%W以星期一为一个星期的开始。 |
| %x | 本地相应日期 |
| %X | 本地相应时间 |
| %y | 去掉世纪的年份(00 - 99) |
| %Y | 完整的年份 |
| %Z | 时区的名字(如果不存在为空字符) |
| %% | ‘%’字符 |
datetime,date,time模块:
datetime.date.today() 本地日期对象,(用str函数可得到它的字面表示(2014-03-24)) datetime.date.isoformat(obj) 当前[年-月-日]字符串表示(2014-03-24) datetime.date.fromtimestamp() 返回一个日期对象,参数是时间戳,返回 [年-月-日] datetime.date.weekday(obj) 返回一个日期对象的星期数,周一是0 datetime.date.isoweekday(obj) 返回一个日期对象的星期数,周一是1 datetime.date.isocalendar(obj) 把日期对象返回一个带有年月日的元组 datetime对象: datetime.datetime.today() 返回一个包含本地时间(含微秒数)的datetime对象 2014-03-24 23:31:50.419000 datetime.datetime.now([tz]) 返回指定时区的datetime对象 2014-03-24 23:31:50.419000 datetime.datetime.utcnow() 返回一个零时区的datetime对象 datetime.fromtimestamp(timestamp[,tz]) 按时间戳返回一个datetime对象,可指定时区,可用于strftime转换为日期表示 datetime.utcfromtimestamp(timestamp) 按时间戳返回一个UTC-datetime对象 datetime.datetime.strptime(‘2014-03-16 12:21:21‘,”%Y-%m-%d %H:%M:%S”) 将字符串转为datetime对象 datetime.datetime.strftime(datetime.datetime.now(), ‘%Y%m%d %H%M%S‘) 将datetime对象转换为str表示形式 datetime.date.today().timetuple() 转换为时间戳datetime元组对象,可用于转换时间戳 datetime.datetime.now().timetuple() time.mktime(timetupleobj) 将datetime元组对象转为时间戳 time.time() 当前时间戳 time.localtime time.gmtime
例子:
import time from datetime import datetime """ datetime.date.today() 本地日期对象,(用str函数可得到它的字面表示(2014-03-24)) datetime.date.isoformat(obj) 当前[年-月-日]字符串表示(2014-03-24) datetime.date.fromtimestamp() 返回一个日期对象,参数是时间戳,返回 [年-月-日] datetime.date.weekday(obj) 返回一个日期对象的星期数,周一是0 datetime.date.isoweekday(obj) 返回一个日期对象的星期数,周一是1 datetime.date.isocalendar(obj) 把日期对象返回一个带有年月日的元组 datetime对象: datetime.datetime.today() 返回一个包含本地时间(含微秒数)的datetime对象 2014-03-24 23:31:50.419000 datetime.datetime.now([tz]) 返回指定时区的datetime对象 2014-03-24 23:31:50.419000 datetime.datetime.utcnow() 返回一个零时区的datetime对象 datetime.fromtimestamp(timestamp[,tz]) 按时间戳返回一个datetime对象,可指定时区,可用于strftime转换为日期表示 datetime.utcfromtimestamp(timestamp) 按时间戳返回一个UTC-datetime对象 datetime.datetime.strptime(‘2014-03-16 12:21:21‘,”%Y-%m-%d %H:%M:%S”) 将字符串转为datetime对象 datetime.datetime.strftime(datetime.datetime.now(), ‘%Y%m%d %H%M%S‘) 将datetime对象转换为str表示形式 datetime.date.today().timetuple() 转换为时间戳datetime元组对象,可用于转换时间戳 datetime.datetime.now().timetuple() time.mktime(timetupleobj) 将datetime元组对象转为时间戳 time.time() 当前时间戳 time.localtime time.gmtime """ t = 1429417200.0 print(datetime.fromtimestamp(t)) # 本地时间 print(datetime.utcfromtimestamp(t)) # UTC时间 '''timestamp''' current_time = time.time() print('当前本地时间:\n{}'.format(datetime.fromtimestamp(current_time))) print('当前UTC时间:\n{}'.format(datetime.utcfromtimestamp(current_time))) '''datetime获取当前datetime''' import datetime now = datetime.datetime.now() print('当前时间是:\n{}'.format(now)) print(datetime.datetime(2015, 1, 12, 23, 9, 12, 946118)) '''time tuple''' local_time = time.localtime() print('local时间是:\n{}'.format(local_time)) '''string time''' import datetime print('当前的字符串日期是:\n{}'.format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))) '''date''' print('date 日期格式是:\n{}'.format(datetime.datetime.now().date())) print('获取当天date:\n{}'.format(datetime.date.today())) def get_x_after_day(x): """获取后X天""" print('获取后{}天: {}'.format(x, datetime.date.today() + datetime.timedelta(days=x))) def get_x_before_day(x): """获取前X天""" current_date = datetime.datetime.now() print(type(current_date)) print(type(datetime.timedelta(days=x))) before_date = current_date - datetime.timedelta(days=x) print('当前日期是:{} 获取前{}天: {}'.format(current_date, x, before_date)) def get_start_end_day(): """获取当天开始和结束时间(00:00:00 23:59:59)""" start_date = datetime.datetime.combine(datetime.date.today(), datetime.time.min) end_date = datetime.datetime.combine(datetime.date.today(), datetime.time.max) print('\n\n当天开始时间是:\n{} \n当天结束时间:\n{}'.format(start_date, end_date)) def get_time_difference(): """获取两个datetime的时间差""" set_date = datetime.datetime(2020, 12, 1, 12, 0, 0) target_second_date = datetime.datetime.now() print('\n\n预定的日期:\n{}\n预定的秒级时间是\n{}'.format(set_date, target_second_date)) time_difference = (set_date - target_second_date).total_seconds() print('\n\n2天时间差是:\n{}'.format(time_difference))
def get_time():
from datetime import datetime
"""
##获取当前日期和时间
"""
now = datetime.now() # 获取当前datetime
print('当前时间是:\n{}\n值类型是:\n{}'.format(now, type(now)))
"""
##获取指定日期和时间
"""
from datetime import datetime
specify_datetime = datetime(2015, 4, 19, 12, 20) # 用指定日期时间创建datetime
print('指定时间是:\n{}\n值类型是:\n{}'.format(specify_datetime, type(specify_datetime)))
if __name__ == '__main__':
# get_x_before_day(int(2))
# get_x_after_day(int(1))
# get_start_end_day()
get_time_difference()
输出:
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/time/3_timestamp_utc.py
2015-04-19 12:20:00
2015-04-19 04:20:00
当前本地时间:
2020-11-16 09:05:47.373171
当前UTC时间:
2020-11-16 01:05:47.373171
当前时间是:
2020-11-16 09:05:47.373207
2015-01-12 23:09:12.946118
local时间是:
time.struct_time(tm_year=2020, tm_mon=11, tm_mday=16, tm_hour=9, tm_min=5, tm_sec=47, tm_wday=0, tm_yday=321, tm_isdst=0)
当前的字符串日期是:
2020-11-16 09:05:47
date 日期格式是:
2020-11-16
获取当天date:
2020-11-16
<class 'datetime.datetime'>
<class 'datetime.timedelta'>
当前日期是:2020-11-16 09:05:47.373312 获取前2天: 2020-11-14 09:05:47.373312
获取后1天: 2020-11-17
当天开始时间是:
2020-11-16 00:00:00
当天结束时间:
2020-11-16 23:59:59.999999
预定的日期:
2020-12-01 12:00:00
预定的秒级时间是
2020-11-16 09:05:47.373909
2天时间差是:
1306452.626091
当前时间是:
2020-11-16 09:05:47.373951
值类型是:
<class 'datetime.datetime'>
指定时间是:
2015-04-19 12:20:00
值类型是:
<class 'datetime.datetime'>
Process finished with exit code 0
借助Pandas计算日期
import datetime from pandas.tseries.offsets import Day def dynamic_date(num): execution_date_1 = (datetime.datetime.now() - int(num) * Day()).strftime('%Y-%m-%d') print('当前日期(减去的差值: {})\n{}'.format(int(num), execution_date_1)) if __name__ == '__main__': # dynamic_date(0) dynamic_date(2) # dynamic_date(10)
time() -- 返回时间戳
sleep() -- 延迟运行单位为s
gmtime() -- 转换时间戳为时间元组(时间对象)
localtime() -- 转换时间戳为本地时间对象
asctime() -- 将时间对象转换为字符串
ctime() -- 将时间戳转换为字符串
mktime() -- 将本地时间转换为时间戳
strftime() -- 将时间对象转换为规范性字符串
常用的格式代码:
%Y Year with century as a decimal number. %m Month as a decimal number [01,12]. %d Day of the month as a decimal number [01,31]. %H Hour (24-hour clock) as a decimal number [00,23]. %M Minute as a decimal number [00,59]. %S Second as a decimal number [00,61]. %z Time zone offset from UTC. %a Locale's abbreviated weekday name. %A Locale's full weekday name. %b Locale's abbreviated month name. %B Locale's full month name. %c Locale's appropriate date and time representation. %I Hour (12-hour clock) as a decimal number [01,12]. %p Locale's equivalent of either AM or PM.
strptime() -- 将时间字符串根据指定的格式化符转换成数组形式的时间
常用格式代码:
同strftime
- 举例
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
print('返回当前时间戳:\n{}'.format(time.time()))
print('返回当前时间:\n{}'.format(time.ctime()))
print('将时间戳转换为字符串:\n{}'.format(time.ctime(time.time() - 86640)))
print('本地时间:\n{}'.format(time.localtime(time.time() - 86400)))
print('与time.localtime()功能相反,将struct_time格式转回成时间戳格式:\n{}'.format(time.mktime(time.localtime())))
print('将struct_time格式转成指定的字符串格式:\n{}'.format(time.strftime("%Y-%m-%d %H:%M:%S", time.gmtime())))
print('将字符串格式转换成struct_time格式:\n{}'.format(time.strptime("2016-01-28", "%Y-%m-%d")))
# 休眠5s
time.sleep(5)
输出
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/time/7_strptime.py
返回当前时间戳:
1605490099.8223639
返回当前时间:
Mon Nov 16 09:28:19 2020
将时间戳转换为字符串:
Sun Nov 15 09:24:19 2020
本地时间:
time.struct_time(tm_year=2020, tm_mon=11, tm_mday=15, tm_hour=9, tm_min=28, tm_sec=19, tm_wday=6, tm_yday=320, tm_isdst=0)
与time.localtime()功能相反,将struct_time格式转回成时间戳格式:
1605490099.0
将struct_time格式转成指定的字符串格式:
2020-11-16 01:28:19
将字符串格式转换成struct_time格式:
time.struct_time(tm_year=2016, tm_mon=1, tm_mday=28, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=28, tm_isdst=-1)
Process finished with exit code 0
定义的类有:
datetime.date --表示日期的类。常用的属性有year, month, day
datetime.time --表示时间的类。常用的属性有hour, minute, second, microsecond
datetime.datetime --表示日期时间
datetime.timedelta --表示时间间隔,即两个时间点之间的长度
- date类
date类表示日期,构造函数如下 :
datetime.date(year, month, day);
year (1-9999)
month (1-12)
day (1-31)
date.today() --返回一个表示当前本地日期的date对象
date.fromtimestamp(timestamp) --根据给定的时间戮,返回一个date对象
import datetime import time print('根据给定的时间戮,返回一个date对象\n{}'.format(datetime.date.fromtimestamp(time.time()))) print('返回一个表示当前本地日期的date对象:\n{}'.format(datetime.datetime.today()))
date.year() --取给定时间的年
date.month() --取时间对象的月
date.day() --取给定时间的日
date.replace() --生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性
date.timetuple() --返回日期对应的time.struct_time对象
date.weekday() --返回weekday,Monday == 0 ... Sunday == 6
date.isoweekday() --返回weekday,Monday == 1 ... Sunday == 7
date.ctime() --返回给定时间的字符串格式
import datetime
from dateutil.relativedelta import relativedelta
# 取时间对象的日
print(datetime.datetime.now())
print('获取当前时间的前一个月\n{}'.format(datetime.datetime.now() - relativedelta(months=+1)))
print('获取当天的前一个月\n{}'.format(datetime.date.today() - relativedelta(months=+1)))
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/time/5_time_stamp.py
2020-11-16 09:18:37.196878
获取当前时间的前一个月
2020-10-16 09:18:37.196919
获取当天的前一个月
2020-10-16
Process finished with exit code 0
time 类
time类表示时间,由时、分、秒以及微秒组成
time.min() --最小表示时间
time.max() --最大表示时间
time.resolution() --微秒
#最大时间
import datetime
print(datetime.time.max)
#最小时间
print(datetime.time.min)
#时间最小单位,微秒
print(datetime.time.resolution)
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/time/4_time_module.py 23:59:59.999999 00:00:00 0:00:00.000001 Process finished with exit code 0
- datetime类
datetime是date与time的结合体,包括date与time的所有信息
datetime.max() --最大值
datetime.min() --最小值
datetime.resolution() --datetime最小单位
datetime.today() --返回一个表示当前本地时间
datetime.fromtimestamp() --根据给定的时间戮,返回一个datetime对象
datetime.year() --取年
datetime.month() --取月
datetime.day() --取日期
datetime.replace() --替换时间
datetime.strptime() --将字符串转换成日期格式
datetime.time() --取给定日期时间的时间
import time import datetime # from datetime import datetime # datetime最大值 print(datetime.datetime.max) # datetime最小值 print(datetime.datetime.min) # datetime最小单位 print(datetime.datetime.resolution) # 返回一个表示当前本地时间 print(datetime.datetime.today()) # 根据给定的时间戮,返回一个datetime对象 print(datetime.datetime.fromtimestamp(time.time())) # 取时间对象的年 print(datetime.datetime.now().year) # 取时间对象的月 print(datetime.datetime.now().month) # 取时间对象的日 print(datetime.datetime.now().day) # 生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性 print(datetime.datetime.now().replace(2010, 6, 12)) # 返回给定时间的时间元组/对象 print(datetime.datetime.now().timetuple()) # 返回weekday,从0开始 print(datetime.datetime.now().weekday()) # 返回weekday,从1开始 print(datetime.datetime.now().isoweekday()) # 返回给定时间的字符串格式 print(datetime.datetime.now().ctime()) # 将字符串转换成日期格式 print(datetime.datetime.strptime("21/11/06 16:30", "%d/%m/%y %H:%M")) # 取给定日期时间的时间 print(datetime.datetime.now().time()) # 获取5日前时间 print(datetime.datetime.now() + datetime.timedelta(days=-5))
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/time/1_datetime.py 9999-12-31 23:59:59.999999 0001-01-01 00:00:00 0:00:00.000001 2020-11-16 09:15:53.984226 2020-11-16 09:15:53.984569 2020 11 16 2010-06-12 09:15:53.984605 time.struct_time(tm_year=2020, tm_mon=11, tm_mday=16, tm_hour=9, tm_min=15, tm_sec=53, tm_wday=0, tm_yday=321, tm_isdst=-1) 0 1 Mon Nov 16 09:15:53 2020 2006-11-21 16:30:00 09:15:53.988208 2020-11-11 09:15:53.988225 Process finished with exit code 0
random模块:
random.random() 产生0-1的随机浮点数
random.uniform(a, b) 产生指定范围内的随机浮点数
random.randint(a, b) 产生指定范围内的随机整数
random.randrange([start], stop[, step]) 从一个指定步长的集合中产生随机数
random.choice(sequence) 从序列中产生一个随机数
random.shuffle(x[, random]) 将一个列表中的元素打乱
random.sample(sequence, k) 从序列中随机获取指定长度的片断
types模块:
保存了所有数据类型名称。 if type(‘1111‘) == types.StringType: MySQLdb模块: MySQLdb.get_client_info() 获取API版本 MySQLdb.Binary(‘string‘) 转为二进制数据形式 MySQLdb.escape_string(‘str‘) 针对mysql的字符转义函数 MySQLdb.DateFromTicks(1395842548) 把时间戳转为datetime.date对象实例 MySQLdb.TimestampFromTicks(1395842548) 把时间戳转为datetime.datetime对象实例 MySQLdb.string_literal(‘str‘) 字符转义 MySQLdb.cursor()游标对象上的方法:《python核心编程》P624
string模块:
str.capitalize() 把字符串的第一个字符大写 str.center(width) 返回一个原字符串居中,并使用空格填充到width长度的新字符串 str.ljust(width) 返回一个原字符串左对齐,用空格填充到指定长度的新字符串 str.rjust(width) 返回一个原字符串右对齐,用空格填充到指定长度的新字符串 str.zfill(width) 返回字符串右对齐,前面用0填充到指定长度的新字符串 str.count(str,[beg,len]) 返回子字符串在原字符串出现次数,beg,len是范围 str.decode(encodeing[,replace]) 解码string,出错引发ValueError异常 str.encode(encodeing[,replace]) 解码string str.endswith(substr[,beg,end]) 字符串是否以substr结束,beg,end是范围 str.startswith(substr[,beg,end]) 字符串是否以substr开头,beg,end是范围 str.expandtabs(tabsize = 8) 把字符串的tab转为空格,默认为8个 str.find(str,[stat,end]) 查找子字符串在字符串第一次出现的位置,否则返回-1 str.index(str,[beg,end]) 查找子字符串在指定字符中的位置,不存在报异常 str.isalnum() 检查字符串是否以字母和数字组成,是返回true否则False str.isalpha() 检查字符串是否以纯字母组成,是返回true,否则false str.isdecimal() 检查字符串是否以纯十进制数字组成,返回布尔值 str.isdigit() 检查字符串是否以纯数字组成,返回布尔值 str.islower() 检查字符串是否全是小写,返回布尔值 str.isupper() 检查字符串是否全是大写,返回布尔值 str.isnumeric() 检查字符串是否只包含数字字符,返回布尔值 str.isspace() 如果str中只包含空格,则返回true,否则FALSE str.title() 返回标题化的字符串(所有单词首字母大写,其余小写) str.istitle() 如果字符串是标题化的(参见title())则返回true,否则false str.join(seq) 以str作为连接符,将一个序列中的元素连接成字符串 str.split(str=‘‘,num) 以str作为分隔符,将一个字符串分隔成一个序列,num是被分隔的字符串 str.splitlines(num) 以行分隔,返回各行内容作为元素的列表 str.lower() 将大写转为小写 str.upper() 转换字符串的小写为大写 str.swapcase() 翻换字符串的大小写 str.lstrip() 去掉字符左边的空格和回车换行符 str.rstrip() 去掉字符右边的空格和回车换行符 str.strip() 去掉字符两边的空格和回车换行符 str.partition(substr) 从substr出现的第一个位置起,将str分割成一个3元组。 str.replace(str1,str2,num) 查找str1替换成str2,num是替换次数 str.rfind(str[,beg,end]) 从右边开始查询子字符串 str.rindex(str,[beg,end]) 从右边开始查找子字符串位置 str.rpartition(str) 类似partition函数,不过从右边开始查找 str.translate(str,del=‘‘) 按str给出的表转换string的字符,del是要过虑的字符
urllib模块:
urllib.quote(string[,safe]) 对字符串进行编码。参数safe指定了不需要编码的字符 urllib.unquote(string) 对字符串进行解码 urllib.quote_plus(string[,safe]) 与urllib.quote类似,但这个方法用‘+‘来替换‘ ‘,而quote用‘%20‘来代替‘ ‘ urllib.unquote_plus(string ) 对字符串进行解码 urllib.urlencode(query[,doseq]) 将dict或者包含两个元素的元组列表转换成url参数。 例如 字典{‘name‘:‘wklken‘,‘pwd‘:‘123‘}将被转换为”name=wklken&pwd=123″ urllib.pathname2url(path) 将本地路径转换成url路径 urllib.url2pathname(path) 将url路径转换成本地路径 urllib.urlretrieve(url[,filename[,reporthook[,data]]]) 下载远程数据到本地 filename:指定保存到本地的路径(若未指定该,urllib生成一个临时文件保存数据) reporthook:回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调 data:指post到服务器的数据 rulrs = urllib.urlopen(url[,data[,proxies]]) 抓取网页信息,[data]post数据到Url,proxies设置的代理 urlrs.readline() 跟文件对象使用一样 urlrs.readlines() 跟文件对象使用一样 urlrs.fileno() 跟文件对象使用一样 urlrs.close() 跟文件对象使用一样 urlrs.info() 返回一个httplib.HTTPMessage对象,表示远程服务器返回的头信息 urlrs.getcode() 获取请求返回状态HTTP状态码 urlrs.geturl() 返回请求的URL
re正则模块:
一.常用正则表达式符号和语法: '.' 匹配所有字符串,除\n以外 ‘-’ 表示范围[0-9] '*' 匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 \*。 '+' 匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 \+ '^' 匹配字符串开头 ‘$’ 匹配字符串结尾 re '\' 转义字符, 使后一个字符改变原来的意思,如果字符串中有字符*需要匹配,可以\*或者字符集[*] re.findall(r'3\*','3*ds')结['3*'] '*' 匹配前面的字符0次或多次 re.findall("ab*","cabc3abcbbac")结果:['ab', 'ab', 'a'] ‘?’ 匹配前一个字符串0次或1次 re.findall('ab?','abcabcabcadf')结果['ab', 'ab', 'ab', 'a'] '{m}' 匹配前一个字符m次 re.findall('cb{1}','bchbchcbfbcbb')结果['cb', 'cb'] '{n,m}' 匹配前一个字符n到m次 re.findall('cb{2,3}','bchbchcbfbcbb')结果['cbb'] '\d' 匹配数字,等于[0-9] re.findall('\d','电话:10086')结果['1', '0', '0', '8', '6'] '\D' 匹配非数字,等于[^0-9] re.findall('\D','电话:10086')结果['电', '话', ':'] '\w' 匹配字母和数字,等于[A-Za-z0-9] re.findall('\w','alex123,./;;;')结果['a', 'l', 'e', 'x', '1', '2', '3'] '\W' 匹配非英文字母和数字,等于[^A-Za-z0-9] re.findall('\W','alex123,./;;;')结果[',', '.', '/', ';', ';', ';'] '\s' 匹配空白字符 re.findall('\s','3*ds \t\n')结果[' ', '\t', '\n'] '\S' 匹配非空白字符 re.findall('\s','3*ds \t\n')结果['3', '*', 'd', 's'] '\A' 匹配字符串开头 '\Z' 匹配字符串结尾 '\b' 匹配单词的词首和词尾,单词被定义为一个字母数字序列,因此词尾是用空白符或非字母数字符来表示的 '\B' 与\b相反,只在当前位置不在单词边界时匹配 '(?P<name>...)' 分组,除了原有编号外在指定一个额外的别名 re.search("(?P<province>[0-9]{4})(?P<city>[0-9]{2})(?P<birthday>[0-9]{8})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '19930614'} [] 是定义匹配的字符范围。比如 [a-zA-Z0-9] 表示相应位置的字符要匹配英文字符和数字。[\s*]表示空格或者*号。 二.常用的re函数: 方法/属性 作用 re.match(pattern, string, flags=0) 从字符串的起始位置匹配,如果起始位置匹配不成功的话,match()就返回none re.search(pattern, string, flags=0) 扫描整个字符串并返回第一个成功的匹配 re.findall(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个列表返回 re.finditer(pattern, string, flags=0) 找到RE匹配的所有字符串,并把他们作为一个迭代器返回 re.sub(pattern, repl, string, count=0, flags=0) 替换匹配到的字符串
math数学运算模块
ceil:取大于等于x的最小的整数值,如果x是一个整数,则返回x copysign:把y的正负号加到x前面,可以使用0 cos:求x的余弦,x必须是弧度 degrees:把x从弧度转换成角度 e:表示一个常量 exp:返回math.e,也就是2.71828的x次方 expm1:返回math.e的x(其值为2.71828)次方的值减1 fabs:返回x的绝对值 factorial:取x的阶乘的值 floor:取小于等于x的最大的整数值,如果x是一个整数,则返回自身 fmod:得到x/y的余数,其值是一个浮点数 frexp:返回一个元组(m,e),其计算方式为:x分别除0.5和1,得到一个值的范围 fsum:对迭代器里的每个元素进行求和操作 gcd:返回x和y的最大公约数 hypot:如果x是不是无穷大的数字,则返回True,否则返回False isfinite:如果x是正无穷大或负无穷大,则返回True,否则返回False isinf:如果x是正无穷大或负无穷大,则返回True,否则返回False isnan:如果x不是数字True,否则返回False ldexp:返回x*(2**i)的值 log:返回x的自然对数,默认以e为基数,base参数给定时,将x的对数返回给定的base,计算式为:log(x)/log(base) log10:返回x的以10为底的对数 log1p:返回x+1的自然对数(基数为e)的值 log2:返回x的基2对数 modf:返回由x的小数部分和整数部分组成的元组 pi:数字常量,圆周率 pow:返回x的y次方,即x**y radians:把角度x转换成弧度 sin:求x(x为弧度)的正弦值 sqrt:求x的平方根 tan:返回x(x为弧度)的正切值 trunc:返回x的整数部分
hashlib,md5模块:
hashlib主要提供字符加密功能,将md5和sha模块整合到了一起,支持md5,sha1, sha224, sha256, sha384, sha512等算法
Python的hashlib模块提供了用于摘要的相关操作,代替了md5,sha模块。 MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示
import hashlib hash_load = hashlib.md5() hash_load.update(bytes('python', encoding='utf-8')) hash_load.update(bytes('hashlib', encoding='utf-8')) print(hash_load.hexdigest())
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/hash_lib/3_common.py 377f64c42b532c45aeb9aefaab0b81c4 Process finished with exit code 0
hashlib.md5(‘md5_str‘).hexdigest() 对指定字符串md5加密 md5.md5(‘md5_str‘).hexdigest() 对指定字符串md5加密 #!/usr/bin/env python # -*- coding: UTF-8 -*- import hashlib # ######## md5 ######## string = "beyongjie" md5 = hashlib.md5() md5.update(string.encode('utf-8')) # 注意转码 res = md5.hexdigest() print("md5加密结果:", res) # ######## sha1 ######## sha1 = hashlib.sha1() sha1.update(string.encode('utf-8')) res = sha1.hexdigest() print("sha1加密结果:", res) # ######## sha256 ######## sha256 = hashlib.sha256() sha256.update(string.encode('utf-8')) res = sha256.hexdigest() print("sha256加密结果:", res) # ######## sha384 ######## sha384 = hashlib.sha384() sha384.update(string.encode('utf-8')) res = sha384.hexdigest() print("sha384加密结果:", res) # ######## sha512 ######## sha512 = hashlib.sha512() sha512.update(string.encode('utf-8')) res = sha512.hexdigest() print("sha512加密结果:", res)
输出:
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/hash_lib/1_hash_lib.py md5加密结果: 0e725e477851ff4076f774dc312d4748 sha1加密结果: 458d32be8ea38b66300174970ab0a8c0b734252f sha256加密结果: 1e62b55bfd02977943f885f6a0998af7cc9cfb95c8ac4a9f30ecccb7c05ec9f4 sha384加密结果: e91cdf0d2570de5c96ee84e8a12cddf16508685e7a03b3e811099cfcd54b7f52183e20197cff7c07f312157f0ba4875b sha512加密结果: 3f0020a726e9c1cb5d22290c967f3dd1bcecb409a51a8088db520750c876aaec3f17a70d7981cd575ed4b89471f743f3f24a146a39d59f215ae3e208d0170073 Process finished with exit code 0
hashlib 加密啊的字符串类型为二进制编码,直接加密字符串会报如下错误:
import hashlib sha1 = hashlib.sha1() string = '2020最后一个月了' sha1.update(string) res = sha1.hexdigest() print("sha1加密结果:", res)
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/hash_lib/2_hashlib_exception.py Traceback (most recent call last): File "/Users/cloud/PycharmProjects/ModuleProject/hash_lib/2_hashlib_exception.py", line 5, in <module> sha1.update(string) TypeError: Unicode-objects must be encoded before hashing Process finished with exit code 1
可以使用encode进行转换
shaa1 = hashlib.sha1()
shaa1.update(string.encode('utf-8'))
res = shaa1.hexdigest()
print("sha1采用encode转换加密结果:",res)
sha1采用encode转换加密结果: c46b8b987b89366f9cff74a16c4640694356554d
- hash.update(arg) 更新哈希对象以字符串参数, 注意:如果同一个hash对象重复调用该方法,则m.update(a); m.update(b) 等效于 m.update(a+b),看下面例子
-
import hashlib def hash_update(): m = hashlib.md5() m.update('a'.encode('utf-8')) res = m.hexdigest() print("第一次a加密:", res) m.update('b'.encode('utf-8')) res = m.hexdigest() print("第二次b加密:", res) m1 = hashlib.md5() m1.update('b'.encode('utf-8')) res = m1.hexdigest() print("b单独加密:", res) m2 = hashlib.md5() m2.update('ab'.encode('utf-8')) res = m2.hexdigest() print("ab单独加密:", res) if __name__ == '__main__': hash_update()
sha1是另一种较为常见的摘要算法,调用与md5相似,SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示。
import hashlib def hash_md5(): hash_md5 = hashlib.md5() hash_md5.update(bytes('admin', encoding='utf-8')) # hash_md5.update(bytes('hashlib', encoding='utf-8')) print('运算后Md5值:\n{}'.format(hash_md5.hexdigest())) def hash_sha1(): hash_sha1 = hashlib.sha1() hash_sha1.update(bytes('admin', encoding='utf-8')) # hash_sha1.update(bytes('hashlib', encoding='utf-8')) print('运算后sha1值:\n{}'.format(hash_sha1.hexdigest())) if __name__ == '__main__': hash_md5() hash_sha1()
输出:
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/hash_lib/3_common.py 运算后Md5值: 21232f297a57a5a743894a0e4a801fc3 运算后sha1值: d033e22ae348aeb5660fc2140aec35850c4da997 Process finished with exit code 0
可以通过碰撞库查询:
https://www.cmd5.com/
logging模块简介
logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级、日志保存路径、日志文件回滚等;相比print,具备如下优点:
1. 可以通过设置不同的日志等级,在release版本中只输出重要信息,而不必显示大量的调试信息;
2. print将所有信息都输出到标准输出中,严重影响开发者从标准输出中查看其它数据;logging则可以由开发者决定将信息输出到什么地方,以及怎么输出;
import logging logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s') logger = logging.getLogger(__name__) logger.info("Start print log") logger.debug("Do something") logger.warning("Something maybe fail.") logger.info("Finish")
输出
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/logging/1_logging.py 2020-11-16 16:14:00,036 - __main__ - INFO - Start print log 2020-11-16 16:14:00,036 - __main__ - DEBUG - Do something 2020-11-16 16:14:00,036 - __main__ - WARNING - Something maybe fail. 2020-11-16 16:14:00,036 - __main__ - INFO - Finish Process finished with exit code 0
logging.basicConfig函数各参数: filename:指定日志文件名; filemode:和file函数意义相同,指定日志文件的打开模式,'w'或者'a'; format:指定输出的格式和内容,format可以输出很多有用的信息, 参数:作用 %(levelno)s:打印日志级别的数值 %(levelname)s:打印日志级别的名称 %(pathname)s:打印当前执行程序的路径,其实就是sys.argv[0] %(filename)s:打印当前执行程序名 %(funcName)s:打印日志的当前函数 %(lineno)d:打印日志的当前行号 %(asctime)s:打印日志的时间 %(thread)d:打印线程ID %(threadName)s:打印线程名称 %(process)d:打印进程ID %(message)s:打印日志信息 datefmt:指定时间格式,同time.strftime(); level:设置日志级别,默认为logging.WARNNING; stream:指定将日志的输出流,可以指定输出到sys.stderr,sys.stdout或者文件,默认输出到sys.stderr,当stream和filename同时指定时,stream被忽略
1.将日志写入到文件
设置logging,创建一个FileHandler,并对输出消息的格式进行设置,将其添加到logger,然后将日志写入到指定的文件中,
import logging logger = logging.getLogger(__name__) logger.setLevel(level = logging.INFO) handler = logging.FileHandler("log.txt") handler.setLevel(logging.INFO) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) logger.addHandler(handler) logger.info("Start print log") logger.debug("Do something") logger.warning("Something maybe fail.") logger.info("Finish")
log.txt中日志数据为:
2020-11-16 16:21:03,061 - __main__ - INFO - Start print log 2020-11-16 16:21:03,062 - __main__ - WARNING - Something maybe fail. 2020-11-16 16:21:03,062 - __main__ - INFO - Finish
2.将日志同时输出到屏幕和日志文件
logger中添加StreamHandler,可以将日志输出到屏幕上,
import logging logger = logging.getLogger(__name__) logger.setLevel(level=logging.INFO) handler = logging.FileHandler("log.txt") handler.setLevel(logging.INFO) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) console = logging.StreamHandler() console.setLevel(logging.INFO) logger.addHandler(handler) logger.addHandler(console) logger.info("Start print log") logger.debug("Do something") logger.warning("Something maybe fail.") logger.info("Finish")
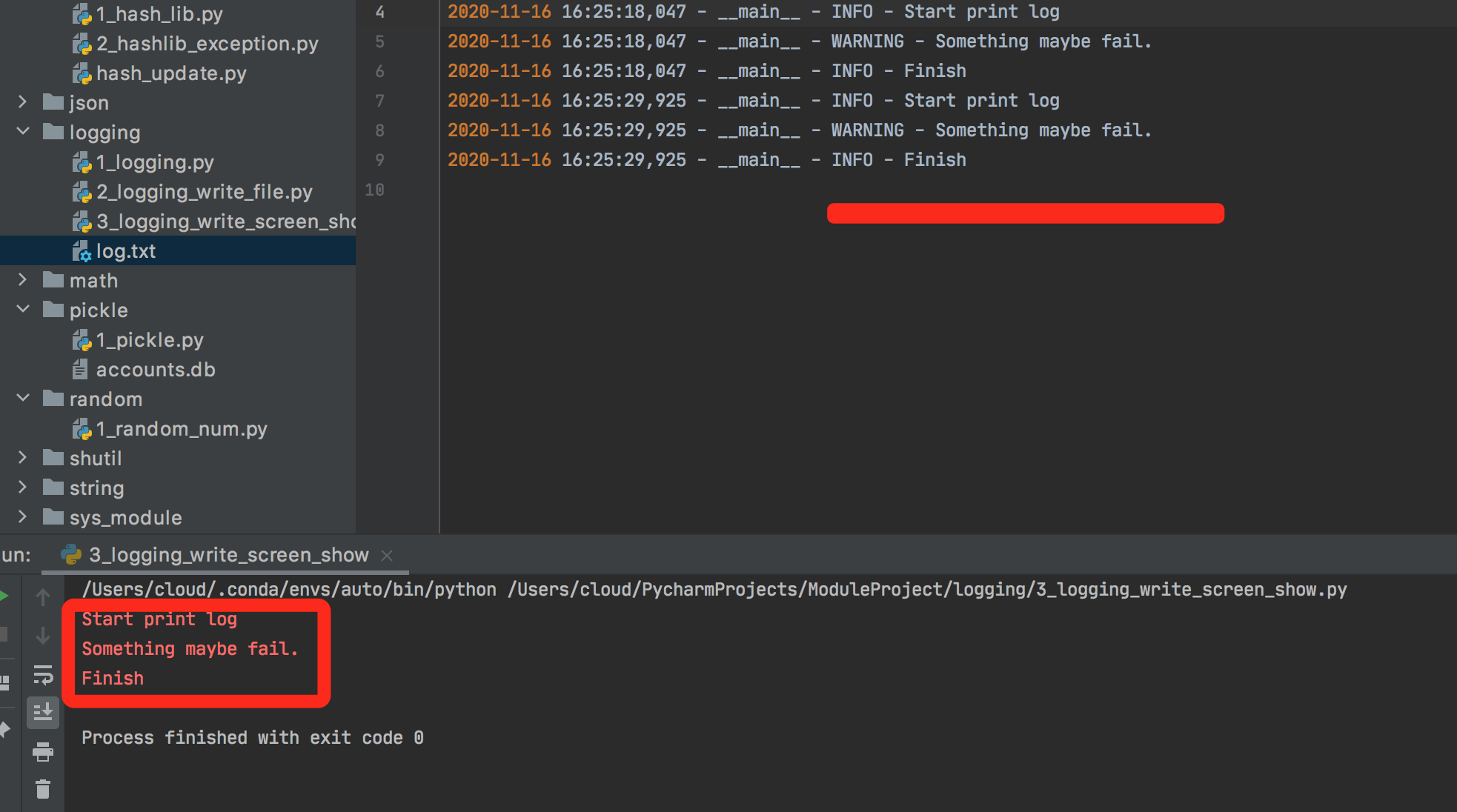
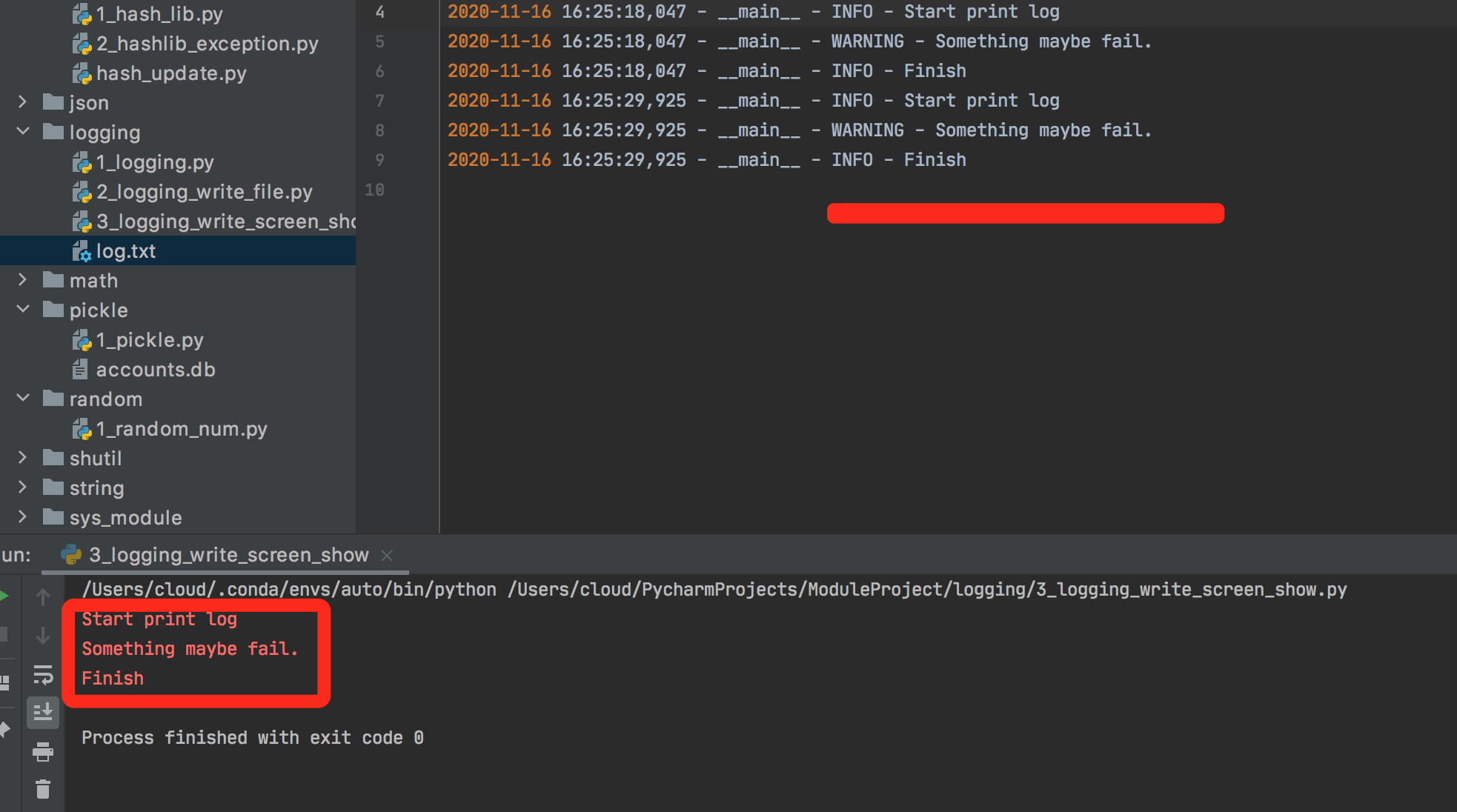
可以发现,logging有一个日志处理的主对象,其他处理方式都是通过addHandler添加进去,logging中包含的handler主要有如下几种,
handler名称:位置;作用
StreamHandler:logging.StreamHandler;日志输出到流,可以是sys.stderr,sys.stdout或者文件
FileHandler:logging.FileHandler;日志输出到文件
BaseRotatingHandler:logging.handlers.BaseRotatingHandler;基本的日志回滚方式
RotatingHandler:logging.handlers.RotatingHandler;日志回滚方式,支持日志文件最大数量和日志文件回滚
TimeRotatingHandler:logging.handlers.TimeRotatingHandler;日志回滚方式,在一定时间区域内回滚日志文件
SocketHandler:logging.handlers.SocketHandler;远程输出日志到TCP/IP sockets
DatagramHandler:logging.handlers.DatagramHandler;远程输出日志到UDP sockets
SMTPHandler:logging.handlers.SMTPHandler;远程输出日志到邮件地址
SysLogHandler:logging.handlers.SysLogHandler;日志输出到syslog
NTEventLogHandler:logging.handlers.NTEventLogHandler;远程输出日志到Windows NT/2000/XP的事件日志
MemoryHandler:logging.handlers.MemoryHandler;日志输出到内存中的指定buffer
HTTPHandler:logging.handlers.HTTPHandler;通过"GET"或者"POST"远程输出到HTTP服务器3 日志回滚
使用RotatingFileHandler,可以实现日志回滚,
import logging
from logging.handlers import RotatingFileHandler
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
# 定义一个RotatingFileHandler,最多备份3个日志文件,每个日志文件最大1K # maxBytes=1 * 1024
rHandler = RotatingFileHandler("log.txt", maxBytes=24, backupCount=3)
rHandler.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
rHandler.setFormatter(formatter)
console = logging.StreamHandler()
console.setLevel(logging.INFO)
console.setFormatter(formatter)
logger.addHandler(rHandler)
logger.addHandler(console)
logger.info("Start print log")
logger.debug("Do something")
logger.warning("Something maybe fail.")
logger.info("Finish")
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/logging/4_rotating_file_handle.py 2020-11-16 16:29:43,500 - __main__ - INFO - Start print log 2020-11-16 16:29:43,501 - __main__ - WARNING - Something maybe fail. 2020-11-16 16:29:43,501 - __main__ - INFO - Finish Process finished with exit code 0
4.设置消息的等级 可以设置不同的日志等级,用于控制日志的输出,
日志等级:使用范围
FATAL:致命错误
CRITICAL:特别糟糕的事情,如内存耗尽、磁盘空间为空,一般很少使用
ERROR:发生错误时,如IO操作失败或者连接问题
WARNING:发生很重要的事件,但是并不是错误时,如用户登录密码错误
INFO:处理请求或者状态变化等日常事务
DEBUG:调试过程中使用DEBUG等级,如算法中每个循环的中间状态5. 捕获traceback
Python中的traceback模块被用于跟踪异常返回信息,可以在logging中记录下traceback
import logging logger = logging.getLogger(__name__) logger.setLevel(level=logging.INFO) handler = logging.FileHandler("log.txt") handler.setLevel(logging.INFO) formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) console = logging.StreamHandler() console.setLevel(logging.INFO) logger.addHandler(handler) logger.addHandler(console) logger.info("Start print log") logger.debug("Do something") logger.warning("Something maybe fail.") try: open("Exception.txt", "rb") except (SystemExit, KeyboardInterrupt): raise except Exception: logger.error("Faild to open sklearn.txt from logger.error", exc_info=True) logger.info("Finish")
控制台和日志文件log.txt中输出
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/logging/5_logging_trace_back.py Start print log Something maybe fail. Faild to open Exception.txt from logger.error Traceback (most recent call last): File "/Users/cloud/PycharmProjects/ModuleProject/logging/5_logging_trace_back.py", line 20, in <module> open("Exception.txt", "rb") FileNotFoundError: [Errno 2] No such file or directory: 'Exception.txt' Finish Process finished with exit code 0
也可以使用logger.exception(msg,_args),它等价于logger.error(msg,exc_info = True,_args),
将
logger.error("Faild to open Exception.txt from logger.error",exc_info = True)替换为,
logger.exception("Failed to open Exception.txt from logger.exception")控制台和日志文件log.txt中输出
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/logging/5_logging_trace_back.py Start print log Something maybe fail. Failed to open Exception.txt from logger.exception Traceback (most recent call last): File "/Users/cloud/PycharmProjects/ModuleProject/logging/5_logging_trace_back.py", line 20, in <module> open("Exception.txt", "rb") FileNotFoundError: [Errno 2] No such file or directory: 'Exception.txt' Finish Process finished with exit code 0
pickle模块
pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump、loads、load
与 json 模块的比较
Pickle 协议和 JSON (JavaScript Object Notation) 间有着本质的不同:
-
JSON 是一个文本序列化格式(它输出 unicode 文本,尽管在大多数时候它会接着以
utf-8编码),而 pickle 是一个二进制序列化格式; -
JSON 是我们可以直观阅读的,而 pickle 不是;
-
JSON是可互操作的,在Python系统之外广泛使用,而pickle则是Python专用的;
-
默认情况下,JSON 只能表示 Python 内置类型的子集,不能表示自定义的类;但 pickle 可以表示大量的 Python 数据类型(可以合理使用 Python 的对象内省功能自动地表示大多数类型,复杂情况可以通过实现 specific object APIs 来解决)。
-
不像pickle,对一个不信任的JSON进行反序列化的操作本身不会造成任意代码执行漏洞。
Functions:
dump(object, file)
dumps(object) -> string
load(file) -> object
loads(string) -> object
pickle.dumps(obj)--把任意对象序列化成一个str,然后,把这个str写入文件
pickle.loads(string) --反序列化出对象
pickle.dump(obj,file) --直接把对象序列化后写入文件
pickle.load(file) --从文件中反序列化出对象
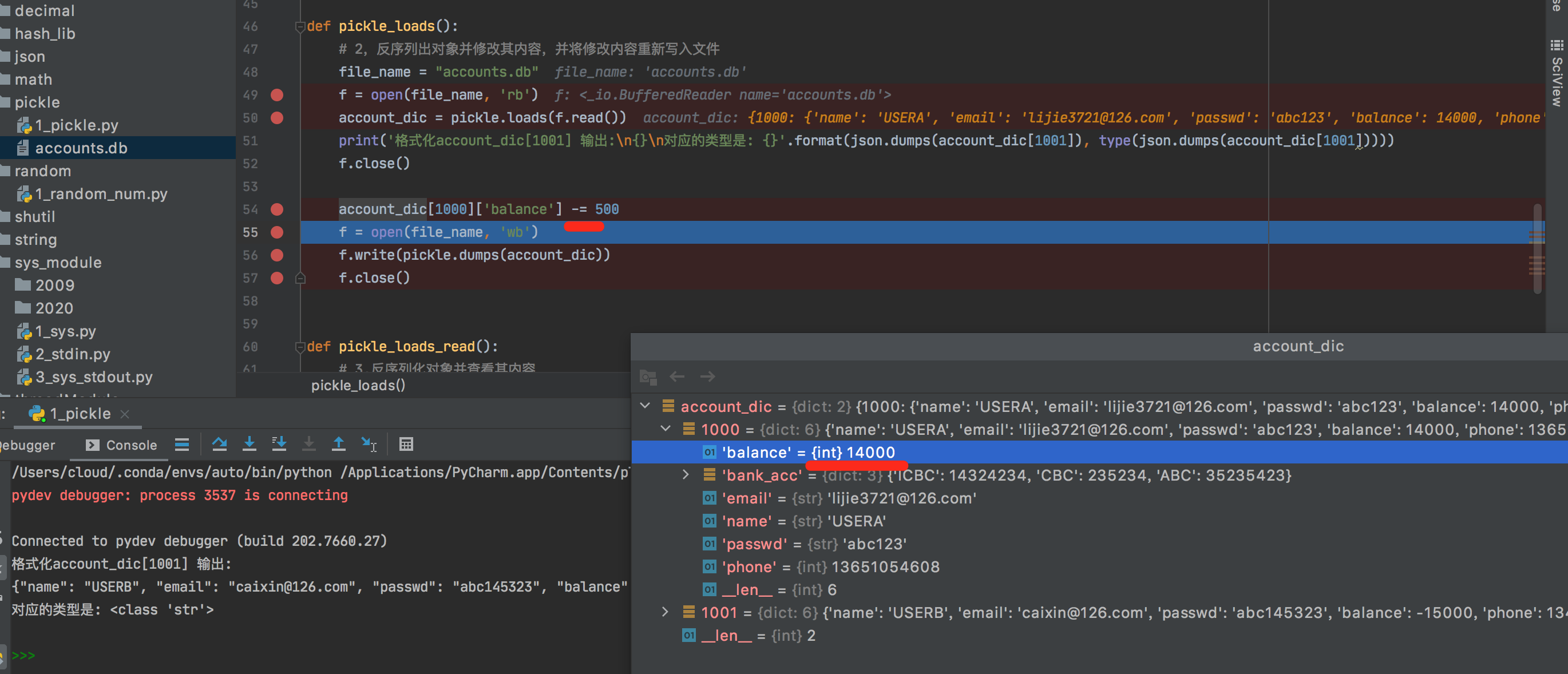
""" 模块 pickle 实现了对一个 Python 对象结构的二进制序列化和反序列化。 "pickling" 是将 Python 对象及其所拥有的层次结构转化为一个字节流的过程,而 "unpickling" 是相反的操作, 会将(来自一个 binary file 或者 bytes-like object 的)字节流转化回一个对象层次结构。 pickling(和 unpickling)也被称为“序列化”, “编组” 1 或者 “平面化”。而为了避免混乱,此处采用术语 “封存 (pickling)” 和 “解封 (unpickling)”。 https://docs.python.org/zh-cn/3/library/pickle.html?highlight=pickle#module-pickle """ # !/usr/bin/env python # -*- coding:utf-8 -*- import pickle import json accounts = { 1000: { 'name': 'USERA', 'email': 'lijie3721@126.com', 'passwd': 'abc123', 'balance': 15000, 'phone': 13651054608, 'bank_acc': { 'ICBC': 14324234, 'CBC': 235234, 'ABC': 35235423 } }, 1001: { 'name': 'USERB', 'email': 'caixin@126.com', 'passwd': 'abc145323', 'balance': -15000, 'phone': 1345635345, 'bank_acc': { 'ICBC': 4334343, } }, } def pickle_dumps(): # 把字典类型写入到文件中 f = open('accounts.db', 'wb') f.write(pickle.dumps(accounts)) f.close() def pickle_loads(): # 2,反序列出对象并修改其内容,并将修改内容重新写入文件 file_name = "accounts.db" f = open(file_name, 'rb') account_dic = pickle.loads(f.read()) print('格式化account_dic[1001] 输出:\n{}\n对应的类型是: {}'.format(json.dumps(account_dic[1001]), type(json.dumps(account_dic[1001])))) f.close() print('修改前的值是:\n{}'.format(account_dic[1000]['balance'])) account_dic[1000]['balance'] -= 500 print('修改之后的值是:\n{}'.format(account_dic[1000]['balance'])) f = open(file_name, 'wb') f.write(pickle.dumps(account_dic)) f.close() def pickle_loads_read(): # 3,反序列化对象并查看其内容 f = open('accounts.db', 'rb') acountdb = pickle.loads(f.read()) print(acountdb) if __name__ == '__main__': # pickle_dumps() pickle_loads()
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/pickle/1_pickle.py 格式化account_dic[1001] 输出: {"name": "USERB", "email": "caixin@126.com", "passwd": "abc145323", "balance": -15000, "phone": 1345635345, "bank_acc": {"ICBC": 4334343}} 对应的类型是: <class 'str'> 修改前的值是: 12500 修改之后的值是: 12000 Process finished with exit code 0
在程序运行的过程中,所有的变量都是在内存中,比如,定义一个 dict:
a = {'name':'Bob','age':20,'score':90}字典 a 可以随时修改变量,比如把 name 改成 'Bill',但是一旦程序结束,变量所占用的内存就被操作系统全部回收。如果没有把修改后的 'Bill'存储到磁盘上,下次重新运行程序,变量又被初始化为 'Bob'。
我们把变量从内存中变成可存储或传输的过程称之为序列化,在 Python 中叫 pickling。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即 unpickling。
- pickle 序列化后的数据,可读性差,人一般无法识别;
- pickle 模块只能在 python 中使用,且只支持同版本,不能跨平台使用;
- Python 中所有的数据类型(列表,字典,集合,类等)都可以用 pickle 来序列化。
- 需导入 pickle 模块 — import pickle
二、pickle模块常用的方法有:dumps、loads、dump、load
1、pickle.dumps(obj) — 把 obj 对象序列化后以 bytes 对象返回,不写入文件
下面代码分别对列表l1、元组t1、字典dic1进行序列化操作,打印后可以看到结果是一堆二进制乱码。代码如下所示
import pickle l1 = [1, 2, 3, 4, 5] t1 = (1, 2, 3, 4, 5) dic1 = {"k1": "v1", "k2": "v2", "k3": "v3"} res_l1 = pickle.dumps(l1) res_t1 = pickle.dumps(t1) res_dic = pickle.dumps(dic1) print('对数据进行序列化操作后,打印数据得到结果为:\n{}\n{}\n{}'.format(res_l1, res_t1, res_dic))
输出
/Users/cloud/.conda/envs/auto/bin/python /Users/cloud/PycharmProjects/ModuleProject/pickle/2_pick_seri.py 对数据进行序列化操作后,打印数据得到结果为: b'\x80\x03]q\x00(K\x01K\x02K\x03K\x04K\x05e.' b'\x80\x03(K\x01K\x02K\x03K\x04K\x05tq\x00.' b'\x80\x03}q\x00(X\x02\x00\x00\x00k1q\x01X\x02\x00\x00\x00v1q\x02X\x02\x00\x00\x00k2q\x03X\x02\x00\x00\x00v2q\x04X\x02\x00\x00\x00k3q\x05X\x02\x00\x00\x00v3q\x06u.' Process finished with exit code 0
2、pickle.loads(bytes_object) — 从 bytes 对象中读取一个反序列化对象,并返回其重组后的对象
下面代码是先分别对列表l1、元组t1、字典dic1进行序列化,然后再对序列化后的对象进行反序列化操作,打印后可以看到序列化之前是什么类型的数据,反序列化后其数据类型不变。代码如下所示:
参考源:
https://www.cnblogs.com/mq0036/p/12846227.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号