Pandas value_counts操作Series数组
列中出现的每个值进行计数 对给定列里面的每个值进行计数并进行降序排序,无效值也会被排除(默认从最高到最低做降序排列)
value_counts () 返回的序列是降序的。我们只需要把参数 ascending 设置为 True,就可以把顺序变成升序。
value_counts()返回的结果是一个Series数组,可以跟别的数组进行运算。value_count()跟透视表里(pandas或者excel)的计数很相似,都是返回一组唯一值,并进行计数。这样能快速找出重复出现的值。
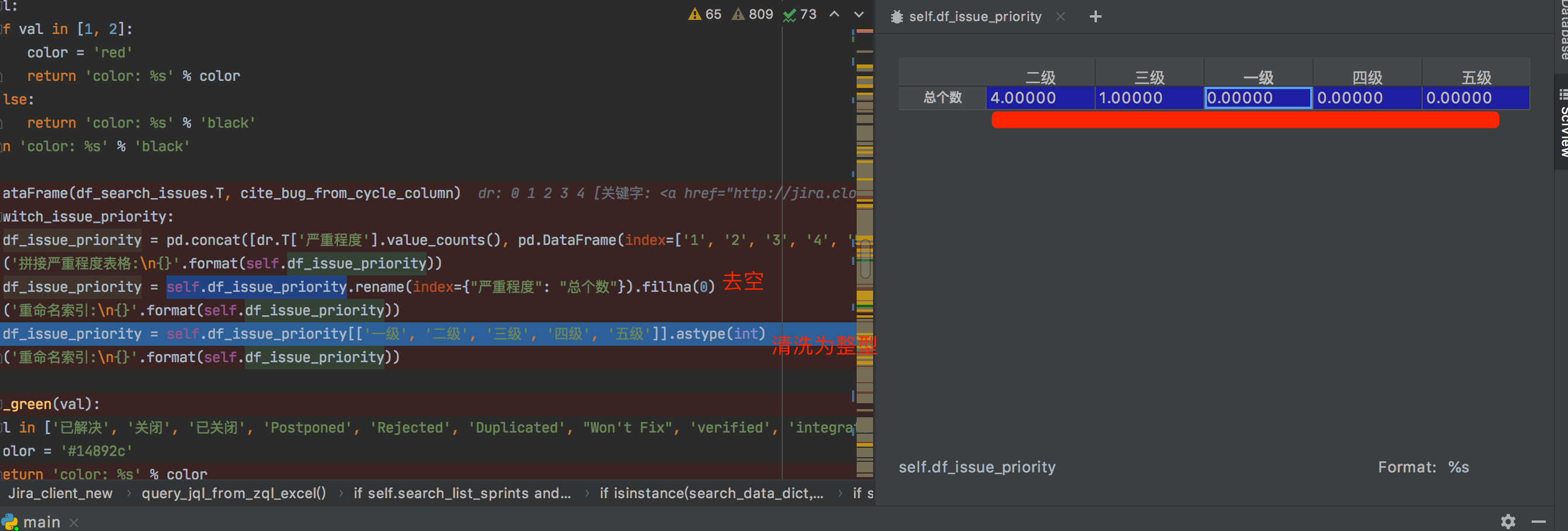
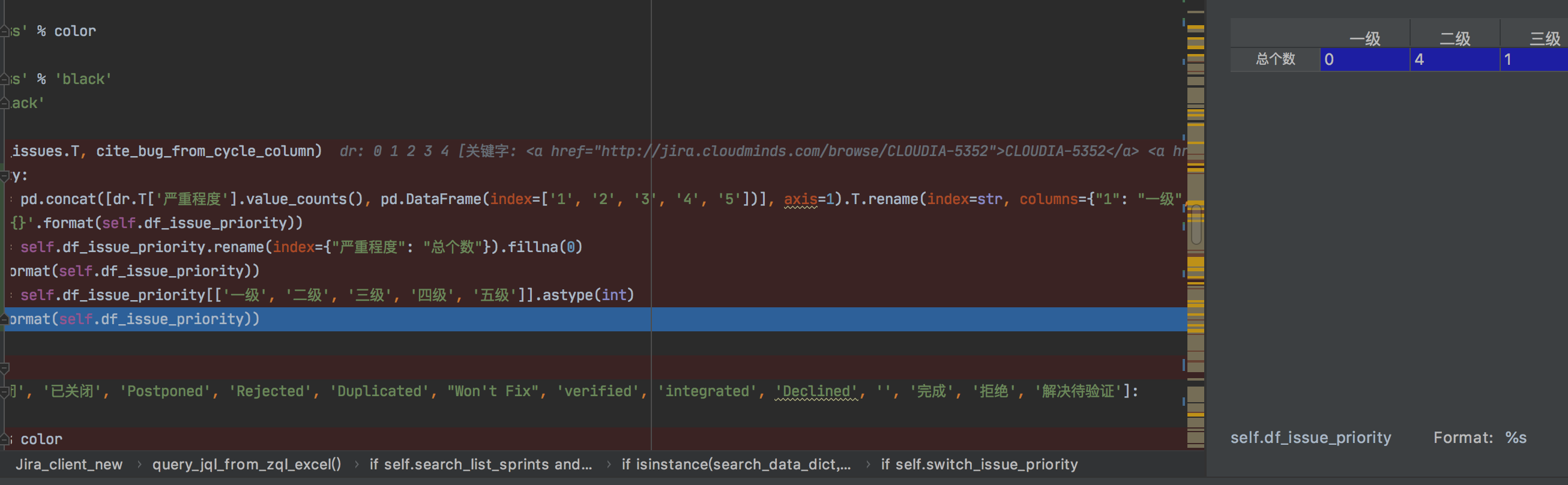
dr = pd.DataFrame(df_search_issues.T, cite_bug_from_cycle_column) if self.switch_issue_priority: self.df_issue_priority = pd.concat([dr.T['严重程度'].value_counts(), pd.DataFrame(index=['1', '2', '3', '4', '5'])], axis=1).T.rename(index=str, columns={"1": "一级", "2": "二级", "3": "三级", "4": "四级", "5": "五级"}) print('拼接严重程度表格:\n{}'.format(self.df_issue_priority)) self.df_issue_priority = self.df_issue_priority.rename(index={"严重程度": "总个数"}).fillna(0) print('重命名索引:\n{}'.format(self.df_issue_priority)) self.df_issue_priority = self.df_issue_priority[['一级', '二级', '三级', '四级', '五级']].astype(int) print('重命名索引:\n{}'.format(self.df_issue_priority))

def value_counts( values, sort: bool = True, ascending: bool = False, normalize: bool = False, bins=None, dropna: bool = True, ) -> "Series": """ Compute a histogram of the counts of non-null values. Parameters ---------- values : ndarray (1-d) sort : bool, default True Sort by values ascending : bool, default False Sort in ascending order normalize: bool, default False If True then compute a relative histogram bins : integer, optional Rather than count values, group them into half-open bins, convenience for pd.cut, only works with numeric data dropna : bool, default True Don't include counts of NaN Returns ------- Series """ from pandas.core.series import Series name = getattr(values, "name", None) if bins is not None: from pandas.core.reshape.tile import cut values = Series(values) try: ii = cut(values, bins, include_lowest=True) except TypeError: raise TypeError("bins argument only works with numeric data.") # count, remove nulls (from the index), and but the bins result = ii.value_counts(dropna=dropna) result = result[result.index.notna()] result.index = result.index.astype("interval") result = result.sort_index() # if we are dropna and we have NO values if dropna and (result.values == 0).all(): result = result.iloc[0:0] # normalizing is by len of all (regardless of dropna) counts = np.array([len(ii)]) else: if is_extension_array_dtype(values): # handle Categorical and sparse, result = Series(values)._values.value_counts(dropna=dropna) result.name = name counts = result.values else: keys, counts = _value_counts_arraylike(values, dropna) result = Series(counts, index=keys, name=name) if sort: result = result.sort_values(ascending=ascending) if normalize: result = result / float(counts.sum()) return result
探索性数据分析(EDA)与数据分析的任何部分一样重要,因为真实的数据集确实很乱,如果您不知道数据,很多事情都会出错。为此,Pandas库配备了一些方便的功能,并且value_counts是其中之一。Pandasvalue_counts返回一个对象,该对象按排序顺序在pandas数据框中包含唯一值的计数。但是,大多数用户倾向于忽略此功能,不仅可以与默认参数一起使用。因此,在本文中,我将向您展示如何value_counts通过更改默认参数和一些其他技巧来从熊猫中获取更多价值,这些技巧将节省您的时间。
什么是value_counts()函数?
该value_counts()函数用于获取包含唯一值计数的系列。生成的对象将按降序排列,以便第一个元素是最频繁出现的元素。默认情况下不包括NA值。
句法
df['your_column'].value_counts() -这将返回指定列中唯一事件的计数。
需要注意的是,value_counts仅适用于pandas系列,不适用于Pandas数据框。结果,我们只包含一个括号df ['your_column'],而不包含两个括号df [['your_column']]。
参量
- normalize(布尔值,默认为False)-如果为True,则返回的对象将包含唯一值的相对频率。
- sort(布尔值,默认为True)-按频率排序。
- 升序(布尔,默认为False)-按升序排序。
- bins(整数,可选)-而不是对值进行计数,而是将它们分组为半开式垃圾箱,这对的方便之处
pd.cut仅适用于数字数据。 - dropna(布尔值,默认为True)-不包括NaN计数。
加载实时演示的数据集
让我们看看使用数据集的此方法的基本用法。我将使用Kaggle的Coursera课程数据集进行实时演示。我还在git上发布了一个随附的笔记本,以防您想要获取我的代码。
让我们从导入所需的库和数据集开始。这是每个数据分析过程中的基本步骤。然后在Jupyter笔记本中查看数据集。
# import package
import pandas as pd
# Loading the dataset
df = pd.read_csv('coursea_data.csv')
#quick look about the information of the csv
df.head(10)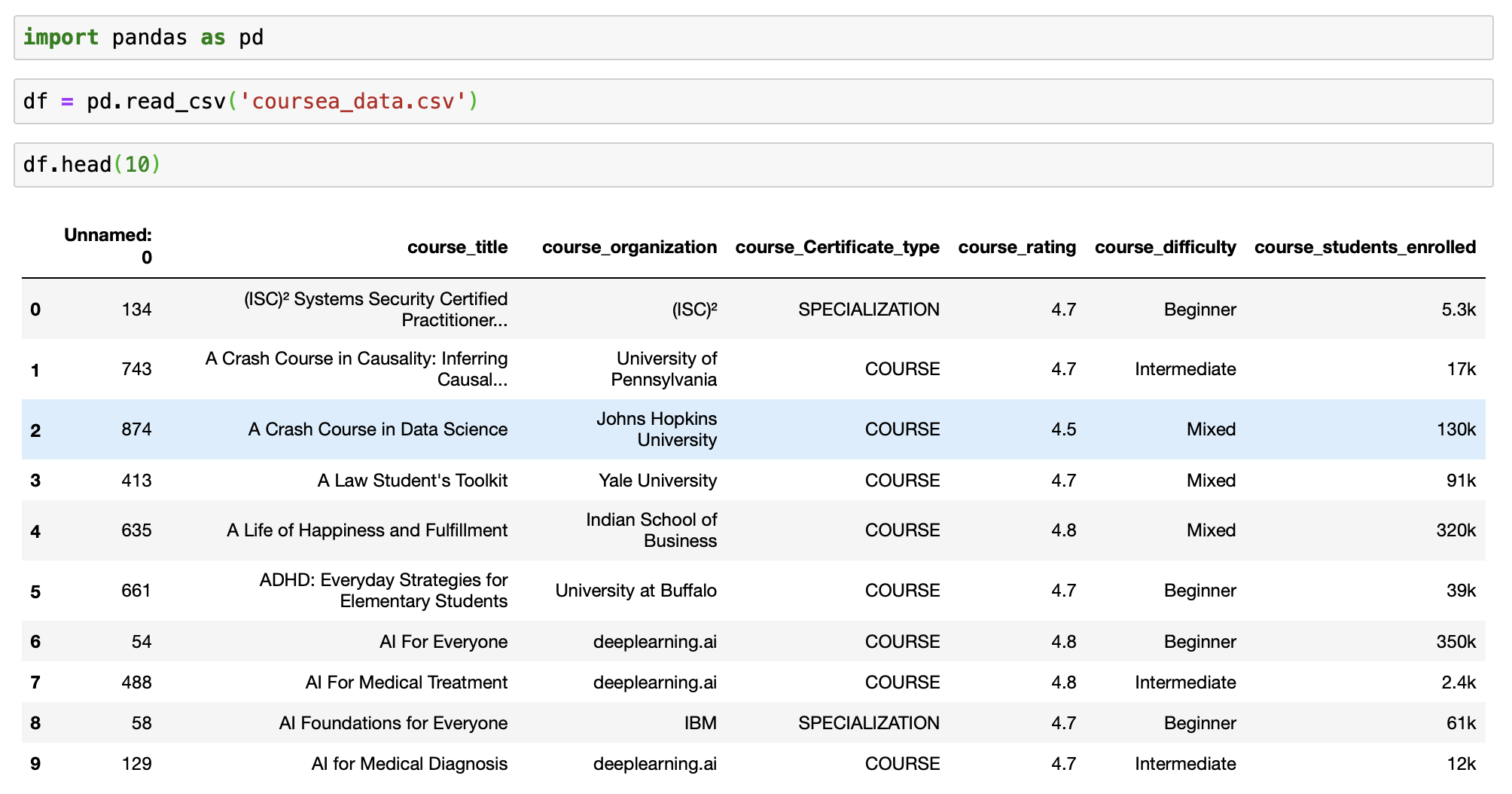 加载数据集
加载数据集
# check how many records are in the dataset
# and if we have any NA
df.info()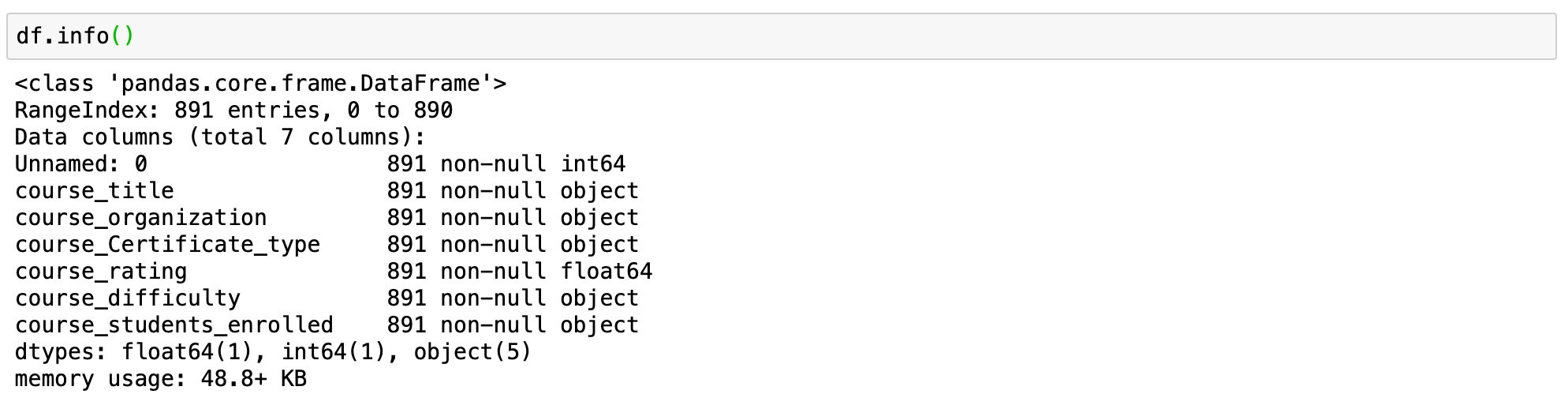
这就告诉我们,我们的数据集中有891条记录,并且没有任何NA值。
1.)使用默认参数的value_counts()
现在我们可以使用value_counts函数了。让我们从函数的基本应用开始。
语法-df['your_column'].value_counts()
我们将从我们的数据框中获取Course_difficulty列的计数。
# count of all unique values for the column course_difficulty
df['course_difficulty'].value_counts() value_counts函数的基本用法
value_counts函数的基本用法
该value_counts函数以降序返回给定索引中所有唯一值的计数,不包含任何空值。我们可以很快地看到最大的课程具有初学者难度,其次是中级和混合,然后是高级。
既然我们已经了解了该函数的基本用法,那么现在该弄清楚参数的作用了。
2.)value_counts()升序
value_counts()默认情况下,返回的系列是降序排列的。我们可以通过将ascending参数设置为来反转大小写True。
语法-df['your_column'].value_counts(ascending=True)
# count of all unique values for the column course_difficulty
# in ascending order
df['course_difficulty'].value_counts(ascending=True) value_counts升序
value_counts升序
3.)value_counts()的人为计数或唯一值的相对频率。
有时,获得百分比计数比正常计数更好。通过设置normalize=True,返回的对象将包含唯一值的相对频率。该normalize参数False默认设置为。
语法-df['your_column'].value_counts(normalize=True)
# value_counts percentage view
df['course_difficulty'].value_counts(normalize=True) 以百分比表示的value_counts
以百分比表示的value_counts
4.)value_counts()将连续数据分成离散间隔
这是一个通常未被充分利用的伟大黑客。的 value_counts()可用于连续仓数据分成离散的间隔与所述的帮助bin参数。此选项仅适用于数值数据。它类似于pd.cut功能。让我们使用course_rating列查看其工作方式。让我们将列的计数分为4个bin。
语法-df['your_column'].value_counts(bin = number of bins)
# applying value_counts with default parameters
df['course_rating'].value_counts()
# applying value_counts on a numerical column
# with the bin parameter
df['course_rating'].value_counts(bins=4)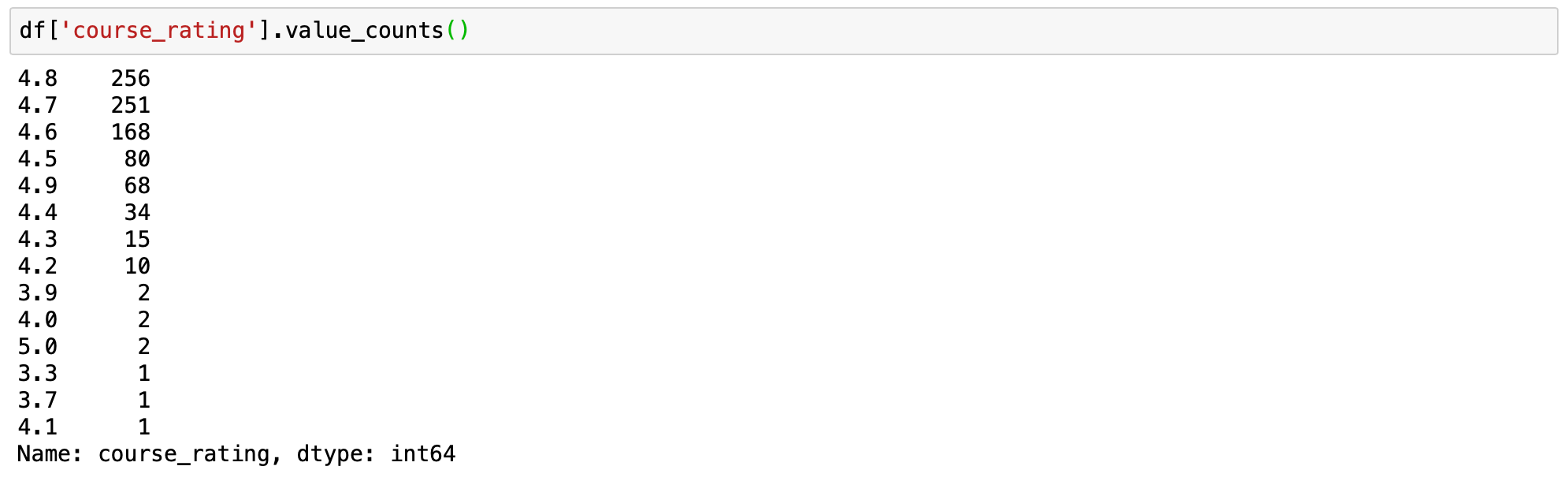 valse_counts默认参数
valse_counts默认参数  合并的value_counts个
合并的value_counts个
Binning使您很容易理解所传达的想法。我们可以很容易地看到,总人口中的大多数人对课程的评分高于4.5。评分低于4.15的异常值很少(只有7个评分低于4.15的课程)。
5.)value_counts()显示NaN值
默认情况下,从结果中排除空值计数。但是,通过将dropna参数设置为,可以轻松显示相同内容False。由于我们的数据集没有任何空值,因此设置dropna参数不会有任何不同。但这可以用于另一个具有空值的数据集,因此请记住这一点。
语法-df['your_column'].value_counts(dropna=False)
6.)value_counts()作为数据框
如本文开头所述,value_counts返回系列,而不是数据框。如果您希望将计数作为数据框使用,可以使用。.to_frame()之后的函数.value_counts()。
我们可以将序列转换为数据框,如下所示:
语法-df['your_column'].value_counts().to_frame()
# applying value_counts with default parameters
df['course_difficulty'].value_counts()
# value_counts as dataframe
df['course_difficulty'].value_counts().to_frame()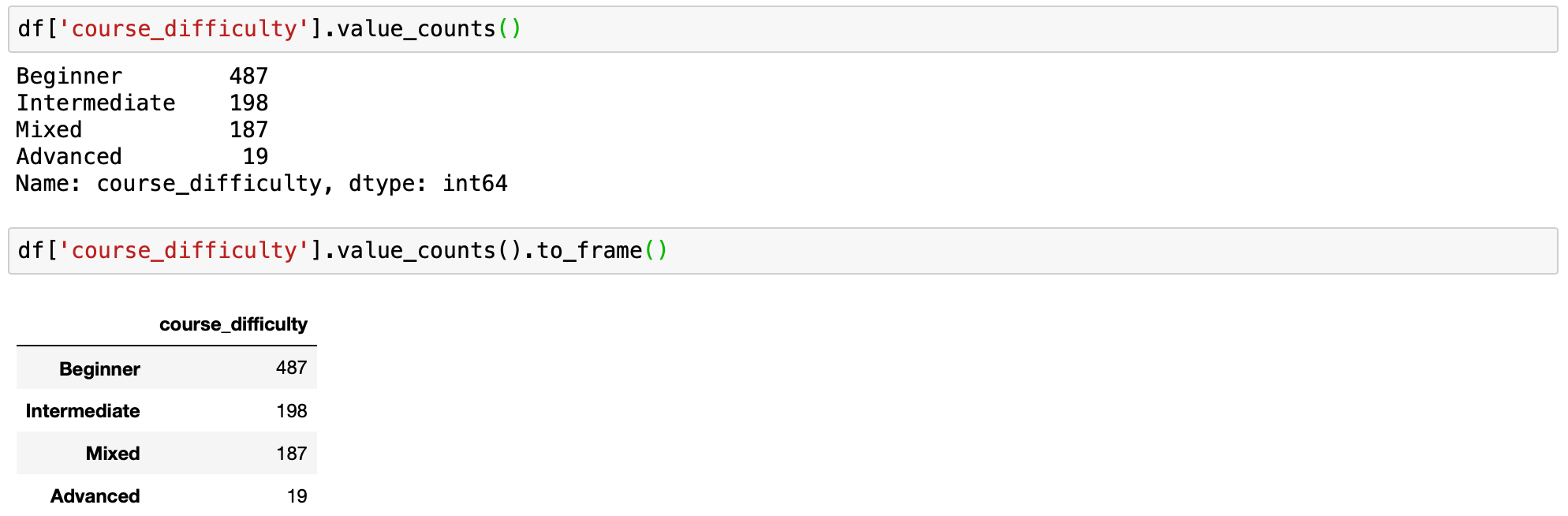 正常的value_counts和value_counts为df
正常的value_counts和value_counts为df
如果您需要命名索引列并重命名一列(在数据框中包含计数),则可以以略有不同的方式转换为数据框。
value_counts = df['course_difficulty'].value_counts()
# converting to df and assigning new names to the columns
df_value_counts = pd.DataFrame(value_counts)
df_value_counts = df_value_counts.reset_index()
df_value_counts.columns = ['unique_values', 'counts for course_difficulty'] # change column names
df_value_counts7.)分组和value_counts
这是value_counts()函数的我最喜欢的用法之一,也是未得到充分利用的函数。Groupby是一种非常强大的熊猫方法。您可以使用来对一列进行分组并针对该列值计算另一列的值value_counts。
语法-df.groupby('your_column_1')['your_column_2'].value_counts()
使用groupby和value_counts我们可以计算每种类型的课程难度的证书类型数量。
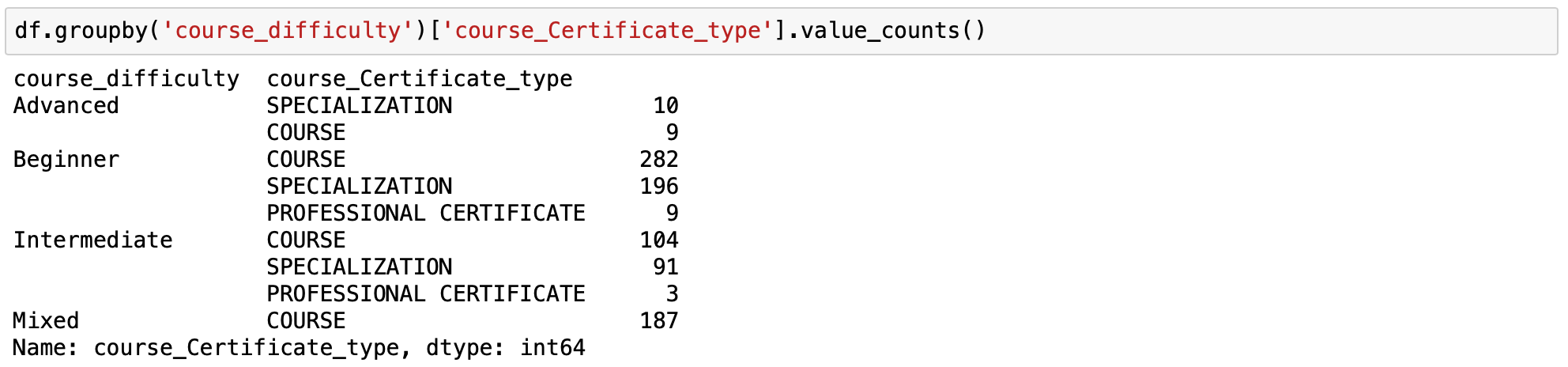 按课程难度和课程证书类型的值计数进行分组
按课程难度和课程证书类型的值计数进行分组
这是一个多索引,是pandas数据框中的一个有价值的窍门,它使我们可以在数据框中使用几个级别的索引层次结构。在这种情况下,课程难度为索引的级别0,证书类型为级别1。
8.带有约束的熊猫值计数
使用数据集时,可能需要使用索引列返回的出现次数,该次数value_counts()也受到约束的限制。
语法-df['your_column'].value_counts().loc[lambda x : x>1]
上面的快速单行代码将过滤出唯一数据的计数,并且仅查看指定列中的值大于1的数据。
让我们通过限制课程等级大于4来证明这一点。
# prints standart value_counts for the column
df['course_rating'].value_counts()
# prints filtered value_counts for the column
df['course_rating'].value_counts().loc[lambda x : x>4] 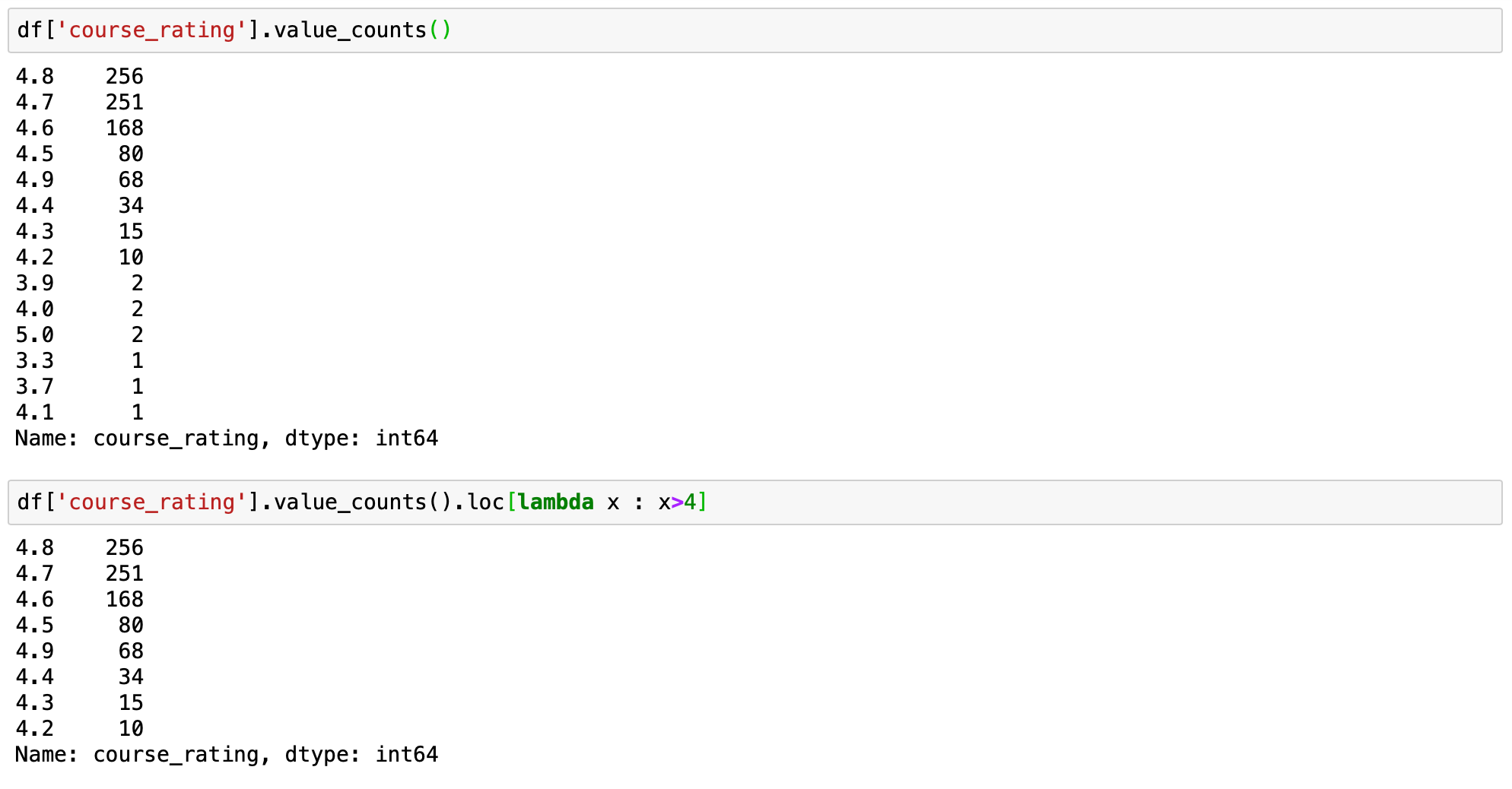 有约束的value_counts
有约束的value_counts
因此,我们可以看到值计数是一个方便的工具,并且我们可以用这一行代码进行一些有趣的分析
The resulting object will be in descending order so that the first element is the most frequently-occurring element. Excludes NA values by default.
Syntax:
Series.value_counts(self, normalize=False, sort=True, ascending=False, bins=None, dropna=True)

Parameters:
| Name | Description | Type/Default Value | Required / Optional |
|---|---|---|---|
| normalize | If True then the object returned will contain the relative frequencies of the unique values. | boolean Default Value: False |
Required |
| sort | Sort by frequencies. | boolean Default Value: True |
Required |
| ascending | Sort in ascending order. | boolean Default Value: False |
Required |
| bins | IRather than count values, group them into half-open bins, a convenience for pd.cut, only works with numeric data. | integer | Optional |
| dropna | Don’t include counts of NaN. | boolean Default Value: True |
Required |
Returns: Series
Example:
Examples
import numpy as np
import pandas as pd
index = pd.Index([2, 2, 5, 3, 4, np.nan])
index.value_counts()

With normalize set to True, returns the relative frequency by dividing all values by the sum of values.
s = pd.Series([2, 2, 5, 3, 4, np.nan])
s.value_counts(normalize=True)

bins
Bins can be useful for going from a continuous variable to a categorical variable; instead of counting
unique apparitions of values, divide the index in the specified number of half-open bins.
s.value_counts(bins=3)
dropna
With dropna set to False we can also see NaN index values.
s.value_counts(dropna=False)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号