merge()、. join()和concat()合并Pandas中的数据
在本教程中,您将学习如何以及何时在Pandas中结合以下数据:
merge()用于合并公共列或索引上的数据.join()用于组合键列或索引上的数据concat()用于跨行或跨列组合DataFrame
如果您具有在Pandas中使用DataFrame和Series对象的一些经验,并且准备学习如何组合它们,那么本教程将帮助您做到这一点。如果要在继续操作之前对DataFrames进行快速刷新,那么Pandas DataFrames 101将使您立即赶上来。
您可以使用交互式Jupyter Notebook和下面链接中的数据文件来跟随本教程中的示例:
下载笔记本和数据集: 单击此处以获取Jupyter笔记本和CSV数据集,您将使用它们来学习本教程中的Pandas merge()、. join()和concat()。
注意:您将在下面学到的技术通常适用于DataFrame和Series对象。但是为了简单明了,这些示例将使用术语数据集来引用可以是DataFrame或Series的对象。\
merge():在公共列的数据组合或指数
您将学习的第一种技术是merge()。您可以随时使用merge()与数据库类似的联接操作。这是您将学习的三个操作中最灵活的。
当您想要以与关系数据库类似的方式组合基于一个或多个键的数据对象时,merge()则需要使用此工具。更具体地说,merge()当您想要合并共享数据的行时,它最有用。
您可以使用实现多对一和多对多联接merge()。在多对一联接中,您的一个数据集的合并列中将有很多行重复相同的值(例如1、1、3、5、5),而另一个数据集中的合并列将不具有重复值(例如1、3、5)。
您可能已经猜到了,在多对多联接中,两个合并列都将具有重复值。这些合并更加复杂,并导致连接行的笛卡尔积。
这意味着在合并之后,您将在键列中拥有共享相同值的行的每种组合。您将在下面的示例中看到这一点。
是什么让merge()如此灵活是定义你的合并行为的选项数量之多。尽管列表看起来令人生畏,但通过实践,您将能够熟练地合并各种数据集。
使用时merge(),您将提供两个必需的参数:
- 数据
left框 - 数据
right框
之后,您可以提供许多可选参数来定义如何合并数据集:
-
how:这定义了进行哪种合并。它默认'inner',但其他可能的选项包括'outer','left',和'right'。 -
on:使用它可以告诉您要加入的merge()列或索引(也称为键列或键索引)。这是可选的。如果未指定,并且left_index和right_index(在下面介绍)是False,则两个名称共享的DataFrame中的列将用作联接键。如果使用on,则指定的列或索引必须同时存在于两个对象中。 -
left_on和right_on:使用这两个选项之一可以指定仅在您要合并的left或right对象中存在的列或索引。两者都默认为None。 -
left_index和right_index:将它们设置True为使用要合并的左侧或右侧对象的索引。两者都默认为False。 -
suffixes:这是一个字符串的元组,附加到不是合并键的相同列名。这使您可以跟踪具有相同名称的列的来源。
这些是传递给的一些最重要的参数merge()。有关完整列表,请参见Pandas文档。
注意:在本教程中,您将看到示例始终指定要与之连接的列on。这是合并数据的最安全方法,因为您和任何阅读您代码的人都将确切知道merge()调用该调用时的期望。如果您未使用来指定合并列on,则Pandas将使用与合并键同名的任何列。
如何merge()
在深入了解如何使用之前merge(),您应该首先了解各种形式的联接:
innerouterleftright
注意:即使你关于合并的学习,你会看到inner,outer,left,并且right也被称为连接操作。对于本教程,您可以认为这些术语等效。
您将在下面详细了解这些内容,但首先请看一下这些不同联接的直观表示:
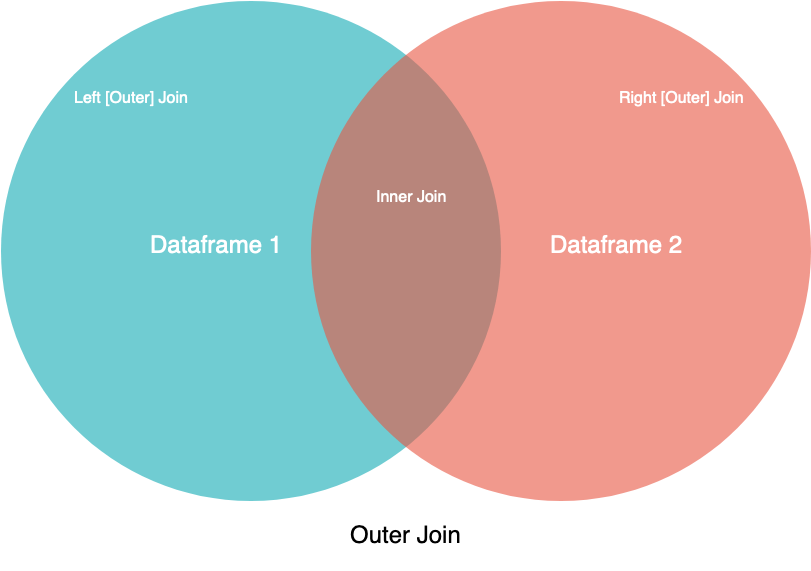 联接类型的可视表示
联接类型的可视表示
在此图像中,两个圆圈是您的两个数据集,标签指向您希望看到的数据集的一部分。虽然此图并未涵盖所有细微差别,但对于视觉学习者而言,它可能是一个方便的指南。
如果您具有SQL背景,则可以从JOIN语法中识别合并操作名称。除此之外inner,所有这些技术都是外部联接的类型。使用外部联接,您将基于左侧对象,右侧对象或两者中的所有键合并数据。对于仅存在于一个对象中的键,另一对象中不匹配的列将用NaN(非数字)填充。
您还可以在Coding Horror的SQL上下文中看到各种联接的直观说明。现在让我们看一下不同的联接。
范例
许多Pandas教程都提供了非常简单的DataFrame,以说明它们试图解释的概念。由于您无法将数据与任何具体内容相关联,因此这种方法可能会造成混淆。因此,在本教程中,您将使用两个真实的数据集作为要合并的DataFrame:
- 加利福尼亚州的气候常态(温度)
- 加利福尼亚州的气候正常值(降水)
您可以浏览这些数据集,并使用交互式Jupyter Notebook和气候数据CSV遵循以下示例:
下载笔记本和数据集: 单击此处以获取Jupyter笔记本和CSV数据集,您将使用它们来学习本教程中的Pandas merge()、. join()和concat()。
如果您想学习如何使用Jupyter Notebook,请查看Jupyter Notebook:简介。
这两个数据集来自美国国家海洋和大气管理局(NOAA),并且来自NOAA公共数据存储库。首先,将数据集加载到单独的DataFrame中:
>>> import pandas as pd
>>> climate_temp = pd.read_csv("climate_temp.csv")
>>> climate_precip = pd.read_csv("climate_precip.csv")
在上面的代码中,您使用了Pandasread_csv()来方便地将源CSV文件加载到DataFrame对象中。然后,您可以使用以下命令查看已加载的DataFrame的标题和前几行.head():
>>> climate_temp.head()
STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL
0 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15
1 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15
2 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15
3 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15
4 GHCND:USC00049099 TWENTYNINE PALMS CA US ... 10 15
>>> climate_precip.head()
STATION ... DLY-SNOW-PCTALL-GE050TI
0 GHCND:USC00049099 ... -9999
1 GHCND:USC00049099 ... -9999
2 GHCND:USC00049099 ... -9999
3 GHCND:USC00049099 ... 0
4 GHCND:USC00049099 ... 0
在这里,您曾经.head()获得每个DataFrame的前五行。确保使用交互式Jupyter Notebook或在控制台中自行尝试,以便您可以更深入地浏览数据。
接下来,快速浏览两个DataFrame的尺寸:
>>> climate_temp.shape
(127020, 21)
>>> climate_precip.shape
(151110, 29)
请注意,这.shape是DataFrame对象的属性,它告诉您DataFrame的尺寸。对于climate_temp,输出的结果.shape表明DataFrame具有127,020行和21列。
内联
在此示例中,将使用merge()其默认参数,这将导致内部联接。请记住,在内部联接中,您将丢失其他DataFrame的key列中不匹配的行。
将这两个数据集加载到DataFrame对象中后,您将选择降水数据集的一小部分,然后使用普通merge()调用进行内部联接。这将产生一个更小,更集中的数据集:
>>> precip_one_station = climate_precip[climate_precip["STATION"] == "GHCND:USC00045721"]
>>> precip_one_station.head()
STATION ... DLY-SNOW-PCTALL-GE050TI
1460 GHCND:USC00045721 ... -9999
1461 GHCND:USC00045721 ... -9999
1462 GHCND:USC00045721 ... -9999
1463 GHCND:USC00045721 ... -9999
1464 GHCND:USC00045721 ... -9999
在这里,您创建了一个precip_one_station从DataFrame调用的新DataFrame climate_precip,仅选择了STATION字段为的行"GHCND:USC00045721"。
如果检查该shape属性,则将看到它有365行。合并时,您认为合并的DataFrame中会得到多少行?请记住,您将进行内部联接:
>>> inner_merged = pd.merge(precip_one_station, climate_temp)
>>> inner_merged.head()
STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL
0 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
1 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
2 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
3 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
4 GHCND:USC00045721 MITCHELL CAVERNS CA US ... 14 19
>>> inner_merged.shape
(365, 47)
如果您猜到了365行,那么您是正确的!这是因为merge()默认为内部联接,而内部联接将仅丢弃那些不匹配的行。由于您所有的行都有匹配项,因此没有丢失。您还应该注意,现在还有更多列:确切地说是47列。
使用merge(),您还可以控制要加入的列。假设您要合并两个数据集,但只能合并Station,Date因为两者的结合将为每一行产生唯一的值。为此,可以使用on参数:
inner_merged_total = pd.merge(climate_temp, climate_precip, on=["STATION", "DATE"])
inner_merged_total.head()
inner_merged_total.shape
您可以使用字符串指定单个键列,也可以使用列表指定多个键列。这将导致DataFrame具有123,005行和48列。
为什么用48列而不是47列?因为您指定了要连接的键列,所以Pandas不会尝试合并所有可合并列。这可能会导致“重复”的列名,它们可能具有也可能没有不同的值。
用引号引起来“重复”,因为列名将不完全匹配。默认情况下,它们附加_x和_y。您还可以使用suffixes参数来控制附加到列名称的内容。
为防止意外,以下所有示例将使用on参数指定要连接的一个或多个列。
外连接
在这里,您将使用how参数指定外部联接。请记住,从上图中可以看出,在外部联接(也称为完全外部联接)中,两个DataFrame中的所有行都将出现在新DataFrame中。
如果一行在另一个DataFrame中没有匹配项(基于键列),则不会像使用内部联接那样丢失该行。相反,该行将位于合并的DataFrame中,NaN并在适当的地方填充值。
最好在一个示例中说明:
outer_merged = pd.merge(precip_one_station, climate_temp, how="outer", on=["STATION", "DATE"])
outer_merged.head()
outer_merged.shape
如果您从检查的.shape属性时还记得climate_temp,那么您会发现其中的行数outer_merged是相同的。通过外部联接,可以期望与较大的DataFrame具有相同的行数。这是因为,即使在另一个DataFrame中没有匹配项,外部联接中也不会丢失任何行。
左加入
在这个例子中,你会指定一个LEFT JOIN,也称为左外连接-附的how参数。使用左外部联接将使新合并的DataFrame保留左侧数据框架中的所有行,同时丢弃右侧数据框架中在左侧DataFrame的键列中不匹配的行。
您可以将其视为半外半内的合并。下面的示例向您展示了这一功能:
left_merged = pd.merge(climate_temp, precip_one_station,
how="left", on=["STATION", "DATE"])
left_merged.head()
left_merged.shape
left_merged有127,020行,与左侧DataFrame中的行数匹配climate_temp。为了证明这仅适用于左侧的DataFrame,请运行相同的代码,但更改precip_one_stationand的位置climate_temp:
left_merged_reversed = pd.merge(precip_one_station, climate_temp, how="left", on=["STATION", "DATE"])
left_merged_reversed.head()
left_merged_reversed.shape
这将导致DataFrame具有365行,与中的行数匹配precip_one_station。
右加入
右连接(或右外部连接)是左连接的镜像版本。通过此连接,将保留右侧DataFrame中的所有行,而左侧DataFrame中与右侧DataFrame的键列中不匹配的行将被丢弃。
为了演示左右联接是如何相互镜像的,在下面的示例中,您将left_merged仅从上一次使用右联接重新从上方创建DataFrame:
right_merged = pd.merge(precip_one_station, climate_temp, how="right", on=["STATION", "DATE"])
right_merged.head()
right_merged.shape
在这里,您只需翻转输入DataFrame的位置并指定右连接。检查时right_merged,您可能会注意到它与并不完全相同left_merged。两者之间的唯一区别是列的顺序:第一个输入的列将始终是新形成的DataFrame中的第一个列。
merge()是Pandas数据组合工具中最复杂的。这也是构建其他工具的基础。它的复杂性是其最大的优势,它使您能够以各种方式组合数据集并生成对数据的新见解。
另一方面,merge()如果没有对集合论和数据库操作的直观了解,这种复杂性将使其难以使用。在本节中,您学习了各种数据合并技术以及多对一和多对多合并,这些合并最终来自集合论。有关集合理论的更多信息,请查看Python中的集合。
join():合并列或索引上的数据
虽然merge()是模块函数,但是.join()是驻留在DataFrame上的对象函数。这使您仅可以指定一个DataFrame,它将加入您所调用的DataFrame .join()。
在幕后,.join()使用merge(),但与完全指定的merge()调用相比,它提供了一种更有效的联接DataFrame的方法。在深入探讨可用选项之前,请看以下简短示例:
precip_one_station.join(climate_temp, lsuffix="_left", rsuffix="_right")
在索引可见的情况下,您可以看到此处发生了左连接,precip_one_station即为左DataFrame。您可能会注意到,此示例提供了参数lsuffix和rsuffix。因为.join()在索引上联接并且不直接合并DataFrame,所以所有列(即使是具有匹配名称的列)都保留在结果DataFrame中。
如果翻转前一个示例,而是调用.join()较大的DataFrame,则会注意到该DataFrame较大,但是较小的DataFrame(precip_one_station)中不存在的数据将填充以下NaN值:
climate_temp.join(precip_one_station, lsuffix="_left", rsuffix="_right")
如何.join()
默认情况下,.join()将尝试对索引进行左连接。如果要像使用一样加入列merge(),则需要将这些列设置为索引。
像一样merge(),.join()具有一些参数,可以为您的联接提供更大的灵活性。但是,使用时.join(),参数列表相对较短:
-
other:这是唯一必需的参数。它定义了另一个要联接的DataFrame。您还可以在此处指定DataFrames列表,从而可以在一个.join()调用中合并多个数据集。 -
on:此参数为左侧DataFrame(climate_temp在上一个示例中)指定一个可选的列或索引名称,以连接otherDataFrame的索引。如果将其设置为None,这是默认设置,则联接将为index-on-index。 -
how:此选项与howfrom相同merge()。区别在于,它是基于索引的,除非您还使用指定了列on。 -
lsuffix和rsuffix:这是类似于suffixes在merge()。它们指定一个后缀以添加到任何重叠的列,但在传递otherDataFrame列表时不起作用。 -
sort:启用此功能可以通过连接键对结果DataFrame进行排序。
范例
在本部分中,您将看到一些示例,这些示例显示的一些不同用例.join()。有些会简化merge()通话。其他功能将.join()与更冗长的merge()调用区分开。
由于您已经看到了一个简短的.join()通话,因此在第一个示例中,您将尝试使用创建一个merge()通话.join()。这需要什么?花点时间考虑一下可能的解决方案,然后在下面查看建议的解决方案:
inner_merged_total = pd.merge(climate_temp, climate_precip, on=["STATION", "DATE"])
inner_merged_total.head()
inner_joined_total = climate_temp.join(
climate_precip.set_index(["STATION", "DATE"]),
lsuffix="_x",
rsuffix="_y",
on=["STATION", "DATE"],
)
inner_joined_total.head()
因为.join()对索引有效,所以如果我们想merge()从之前重新创建,那么我们必须在指定的联接列上设置索引。在此示例中,您曾经.set_index()将索引设置为联接内的关键列。
有了这个,之间的连接merge(),并.join()应该是比较清楚。
在下面,您将看到一个几乎是裸露的.join()电话。因为有重叠的列,你就需要使用指定后缀lsuffix,rsuffix或两者,但这个例子将展示的更典型行为.join():
climate_temp.join(climate_precip, lsuffix="_left")
这个例子应该让人想起您在.join()前面的介绍中看到的内容。调用是相同的,导致左连接产生与相同行数的DataFrame cliamte_temp。
在本节中,您已经了解了.join()它的参数和用法。您还了解了幕后.join()工作原理,并重新创建了一个merge()调用.join()以更好地了解这两种技术之间的联系。熊猫concat():结合数据通过行或列
串联与您在上面看到的合并技术有些不同。通过合并,通常可以基于某些通用性,期望结果数据集将来自父数据集的行混合在一起。根据合并的类型,您可能还会丢失其他数据集中没有匹配项的行。
使用串联时,您的数据集仅沿着一个轴(行轴或列轴)缝合在一起。视觉上,沿行不带参数的串联看起来像这样:
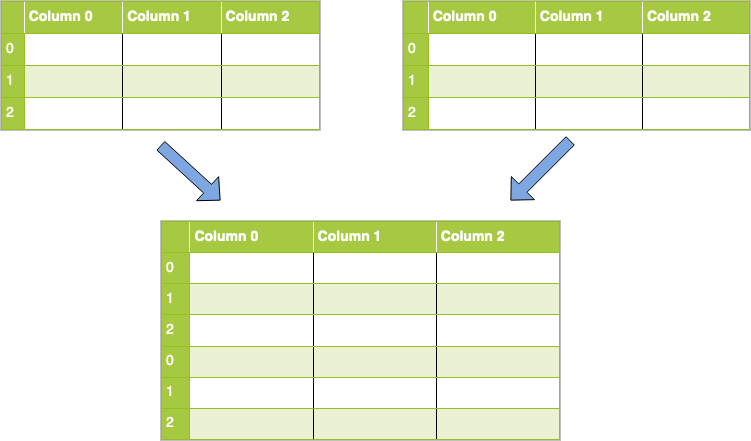
要在代码中实现此目的,您将使用要concat()传递的DataFrame列表并将其传递给它。此任务的代码如下所示:
concatenated = pandas.concat([df1, df2])
注意:此示例假定您的列名相同。如果在沿行(轴0)连接时,列名不同,则默认情况下还将添加列,并NaN在适用时填充值。
相反,如果您想沿列进行串联怎么办?首先,看一下该操作的直观表示:
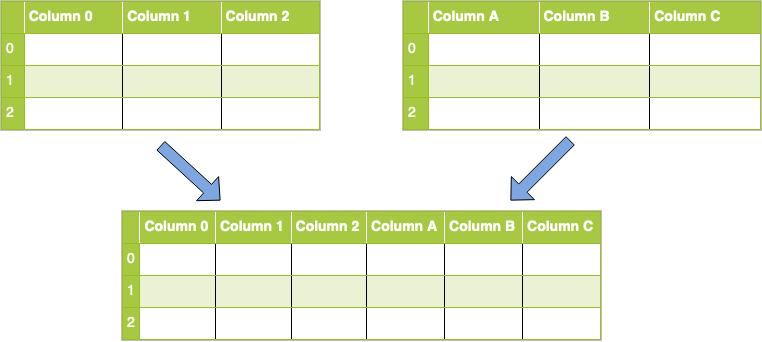
为此,您将concat()像上面一样使用一个调用,但是您还需要传递axis一个值为的参数1:
concatenated = pandas.concat([df1, df2], axis=1)
注意:此示例假定数据集之间的索引相同。如果沿列(轴1)连接时它们不同,则默认情况下还将添加额外的索引(行),并NaN在适用时填充值。
您将concat()在以下部分中了解有关参数的更多信息。如您所见,串联是合并数据集的更简单方法。它通常用于形成单个较大的集合,以对其执行其他操作。
注意:调用时concat(),将复制要连接的所有数据。您应谨慎对待多个concat()调用,因为制作的许多副本可能会对性能产生负面影响。或者,您可以将可选copy参数设置为False
串联数据集时,可以指定串联的轴。但是另一根轴会发生什么呢?
没有。默认情况下,串联会产生set union,其中将保留所有数据。通过merge()和.join()作为外部联接,您已经看到了这一点,并且可以使用join参数指定它。
如果使用此参数,那么您的选项outer(默认情况下)是和inner,这将执行内部联接(或设置交集)。
与您之前看到的其他内部联接一样,使用进行内部联接时可能会发生一些数据丢失concat()。仅在轴标签匹配的地方,您才能保留行或列。
注意:请记住,该join参数仅指定如何处理未串联的轴。
既然您已经了解了该join参数,那么以下是一些其他concat()需要使用的参数:
-
objs:此参数采用要连接的Series或DataFrame对象的任何序列(通常是列表)。您还可以提供字典。在这种情况下,键将用于构造层次结构索引。 -
axis:与其他技术一样,它表示您将串联的轴。默认值为0,它沿索引(或行轴)1连接,而沿列(垂直)连接。您也可以使用字符串值index或columns。 -
join:这类似于how其他技术中的参数,但仅接受值inner或outer。默认值为outer,它保留数据,而inner将消除其他数据集中不匹配的数据。 -
ignore_index:此参数采用布尔值(True或False),默认为False。如果为True,则新的组合数据集将不会在axis参数中指定的轴上保留原始索引值。这使您拥有全新的索引值。 -
keys:使用此参数可以构造层次结构索引。一种常见的用例是在保留原始索引的同时拥有一个新索引,这样您就可以知道哪些行来自哪个原始数据集。 -
copy:此参数指定您是否要复制源数据。默认值为True。如果将该值设置为False,则Pandas将不会复制源数据。
此列表并不详尽。您可以在Pandas文档中找到完整的最新参数列表。
如何使用添加到DataFrameappend()
在进入concat()示例之前,您应该了解.append()。这是concat()提供连接的更简单,更严格的接口的快捷方式。您可以.append()在Series和DataFrame对象上使用,并且两者的工作方式相同。
要使用.append(),请在可用的一个数据集上调用,然后将另一个数据集(或数据集列表)作为方法的参数传递:
concatenated = df1.append(df2)
您在此处执行的操作与调用时的操作相同pandas.concat([df1, df2]),只是使用实例方法.append()而不是模块方法concat()。
范例
首先,您将使用在本教程中一直使用的DataFrame沿默认轴进行基本的串联:
double_precip = pd.concat([precip_one_station, precip_one_station])
通过设计,这一步骤非常简单。在这里,您创建了一个DataFrame,它是先前制作的小型DataFrame的两倍。要注意的一件事是索引重复。如果您想要一个新的,从0开始的索引,则可以使用ignore_index参数:
reindexed = pd.concat([precip_one_station, precip_one_station], ignore_index=True)
如前所述,如果沿轴0(行)连接,但轴1(列)中的标签不匹配,则将添加这些标签并用NaN值填充。这导致外部联接:
outer_joined = pd.concat([climate_precip, climate_temp])
使用这两个DataFrame,由于您只是沿行串联,因此很少有列具有相同的名称。这意味着您将看到很多带有NaN值的列。
要改为删除缺少任何数据的列,请使用join带有值的参数"inner"进行内部联接:
inner_joined = pd.concat([climate_temp, climate_precip], join="inner")
使用内部联接,你会留下只有那些列,原来DataFrames的共同点:STATION,STATION_NAME,和DATE。
您还可以通过设置axis参数来翻转它:
inner_joined_cols = pd.concat([climate_temp, climate_precip], axis=1, join="inner")
现在,在两个DataFrame中,只有行包含所有列的数据。行数与较小的DataFrame的行数相对应并非巧合。
串联的另一个有用技巧是使用keys参数创建分层轴标签。如果要保留原始数据集的索引或列名,但又要向上一级添加新索引,此功能将非常有用:
hierarchical_keys = pd.concat([climate_temp, climate_precip], keys=["temp", "precip"])
如果检查原始的DataFrame,则可以验证是否将更高级别的轴标签temp和precip添加到了适当的行。
最后,看看第一个改写为使用的串联示例.append():
appended = precip_one_station.append(precip_one_station)
注意,using的结果与本节开始.append()时使用的结果相同concat()。结论
您现在已经了解了在熊猫中组合数据的三种最重要的技术:
merge()用于合并公共列或索引上的数据.join()用于组合键列或索引上的数据concat()用于跨行或跨列组合DataFrame
除了学习如何使用这些技术外,您还通过试验加入数据集的不同方法来了解集合逻辑。您还了解了上述技术的API,以及一些类似的调用.append(),可以用来简化代码。
您在从NOAA获得的真实数据集上看到了这些技术的实际应用,它不仅向您展示了如何组合数据,而且还向您展示了熊猫内置的技术所带来的好处。如果尚未下载项目文件,则可以在这里获取它们:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号