适用于生态学家的Python中的数据分析和可视化
DataFrame与Pandas结合
总览
问题
我可以使用来自多个来源的数据吗?
如何合并来自不同数据集的数据?
目标
使用merge和concat将多个文件中的数据合并到单个DataFrame中。
使用在两个DataFrame中找到的唯一ID组合两个DataFrame。
聘请
to_csv导出CSV格式的数据帧。使用公共字段(联接键)联接DataFrame。
在许多“现实世界”情况下,我们要使用的数据位于多个文件中。我们经常需要将这些文件组合到单个DataFrame中以分析数据。pandas包提供了多种组合DataFrame的方法,包括 merge和concat。
为了完成下面的示例,我们首先需要将物种和调查文件加载到pandas DataFrames中。在iPython中:
import pandas as pd
surveys_df = pd.read_csv("data/surveys.csv",
keep_default_na=False, na_values=[""])
surveys_df
record_id month day year plot species sex hindfoot_length weight
0 1 7 16 1977 2 NA M 32 NaN
1 2 7 16 1977 3 NA M 33 NaN
2 3 7 16 1977 2 DM F 37 NaN
3 4 7 16 1977 7 DM M 36 NaN
4 5 7 16 1977 3 DM M 35 NaN
... ... ... ... ... ... ... ... ... ...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[35549 rows x 9 columns]
species_df = pd.read_csv("data/species.csv",
keep_default_na=False, na_values=[""])
species_df
species_id genus species taxa
0 AB Amphispiza bilineata Bird
1 AH Ammospermophilus harrisi Rodent
2 AS Ammodramus savannarum Bird
3 BA Baiomys taylori Rodent
4 CB Campylorhynchus brunneicapillus Bird
.. ... ... ... ...
49 UP Pipilo sp. Bird
50 UR Rodent sp. Rodent
51 US Sparrow sp. Bird
52 ZL Zonotrichia leucophrys Bird
53 ZM Zenaida macroura Bird
[54 rows x 4 columns]
请注意,read_csv我们使用的方法可能会包含一些以前未使用的其他选项。Python中的许多功能都有一组选项,用户可以根据需要设置这些选项。在这种情况下,我们告诉熊猫在CSV中将空值分配给NaN keep_default_na=False, na_values=[""]。 有关所有read_csv选项的更多信息,请参见此处。
串联数据框
我们可以concat在pandas中使用该函数将一个DataFrame的列或行追加到另一个。让我们获取数据的两个子集,以了解其工作原理。
# Read in first 10 lines of surveys table
survey_sub = surveys_df.head(10)
# Grab the last 10 rows
survey_sub_last10 = surveys_df.tail(10)
# Reset the index values to the second dataframe appends properly
survey_sub_last10 = survey_sub_last10.reset_index(drop=True)
# drop=True option avoids adding new index column with old index values
连接DataFrame时,需要指定轴。axis=0告诉熊猫将第二个DataFrame堆叠在第一个之下。它将自动检测列名是否相同,并进行相应的堆栈。 axis=1将第二个DataFrame中的列堆叠到第一个DataFrame的右侧。要垂直堆叠数据,我们需要确保两个数据集中的列和关联的列格式相同。当我们水平堆叠时,我们要确保正在做的事情有意义(即数据以某种方式相关)。
# Stack the DataFrames on top of each other
vertical_stack = pd.concat([survey_sub, survey_sub_last10], axis=0)
# Place the DataFrames side by side
horizontal_stack = pd.concat([survey_sub, survey_sub_last10], axis=1)
行索引值和连接
看一下vertical_stack数据框?注意到有什么不寻常的地方吗?两个数据帧行的索引survey_sub和survey_sub_last10 已经重复。我们可以使用该reset_index()方法重新索引新的数据框。
将数据写到CSV
我们可以使用该to_csv命令以CSV格式导出DataFrame。请注意,以下代码默认情况下会将数据保存到当前工作目录中。我们可以通过在文件名中添加文件夹名和斜杠来将其保存到其他文件夹中 vertical_stack.to_csv('foldername/out.csv')。我们使用'index = False',以便熊猫不包括每一行的索引号。
# Write DataFrame to CSV
vertical_stack.to_csv('data_output/out.csv', index=False)
检查您的工作目录,以确保CSV正确写出,并且您可以打开它!如果需要,请尝试将其重新带回Python以确保其正确导入。
# For kicks read our output back into Python and make sure all looks good
new_output = pd.read_csv('data_output/out.csv', keep_default_na=False, na_values=[""])
挑战-合并数据
在数据文件夹中,有两个调查数据文件:
surveys2001.csv和surveys2002.csv。将数据读入Python并合并文件以构成一个新的数据框。创建按性别分组的按年平均地块权重的图。将结果以CSV格式导出,并确保将其正确读回Python。
联接数据框
当我们串联DataFrame时,我们只是将它们彼此添加-垂直或并排堆叠。组合DataFrame的另一种方法是在每个数据集中使用包含公用值(公用唯一ID)的列。使用公共字段组合DataFrame的过程称为“联接”。包含公共值的列称为“连接键”。当一个DataFrame是一个“查找表”,其中包含我们想要包含在另一个数据中的其他数据时,以这种方式连接DataFrame通常很有用。
注意:连接表的过程类似于我们对SQL数据库中的表的处理。
例如,species.csv我们一直在使用的文件是一个查找表。该表包含55种的属,种和分类代码。种类代码对于每行都是唯一的。这些物种在我们的调查数据中也使用唯一的物种代码进行标识。我们可以为35,549行“调查”数据表中的属,种和类群增加3列,而不是用种信息维护较短的表。当我们想要访问该信息时,我们可以创建一个查询,该查询将其他信息列与调查数据连接起来。
以这种方式存储数据有很多好处,包括:
- 如果每个物种只输入一次,它可以确保物种属性(属,物种和分类单元)拼写的一致性。想象成千上万次进入属和种的拼写错误的可能性!
- 这也使我们很容易对物种信息进行一次更改,而不必在较大的调查数据中找到每个物种的实例。
- 它优化了我们的数据大小。
连接两个数据框
为了更好地理解联接,让我们将数据的前10行作为子集来使用。我们将使用该.head方法来执行此操作。我们还将读取物种表的子集。
# Read in first 10 lines of surveys table
survey_sub = surveys_df.head(10)
# Import a small subset of the species data designed for this part of the lesson.
# It is stored in the data folder.
species_sub = pd.read_csv('data/speciesSubset.csv', keep_default_na=False, na_values=[""])
在此示例中,species_sub是包含我们要与数据结合在一起的属,种和类群名称的查找表,survey_sub以生成一个新的DataFrame,其中包含来自species_df 和的 所有列survey_df。
识别联接键
为了识别适当的连接键,我们首先需要知道文件(DataFrames)之间共享哪些字段。我们可能会同时检查两个DataFrame以标识这些列。如果幸运的话,两个DataFrame都将具有相同名称的列,这些列也包含相同的数据。如果运气不太好,我们需要在每个DataFrame中标识一个包含相同信息的(不同名称)列。
>>> species_sub.columns
Index([u'species_id', u'genus', u'species', u'taxa'], dtype='object')
>>> survey_sub.columns
Index([u'record_id', u'month', u'day', u'year', u'plot_id', u'species_id',
u'sex', u'hindfoot_length', u'weight'], dtype='object')
在我们的示例中,连接键是包含两个字母的物种标识符的列,称为species_id。
既然我们知道每个DataFrame中具有公共物种ID属性的字段,我们几乎准备好加入我们的数据。但是,由于 联接的类型不同,我们还需要确定哪种联接类型对我们的分析有意义。
内联
最常见的联接类型称为内部联接。内部联接基于联接键组合两个DataFrame,并返回一个新DataFrame,该DataFrame仅包含 在两个原始DataFrame中具有匹配值的行。
内部联接产生的DataFrame仅包含两个表中都存在要联接的值的行。下面是一个内部联接的示例,该示例摘自Jeff Atwood关于SQL联接的博客文章:
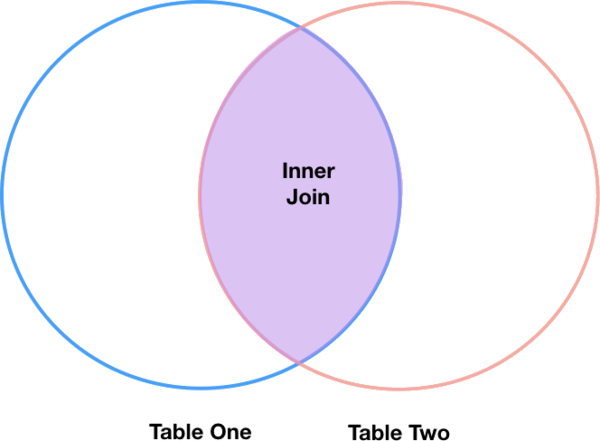
调用用于执行联接的pandas函数,“内部联接”是merge默认选项:
merged_inner = pd.merge(left=survey_sub, right=species_sub, left_on='species_id', right_on='species_id')
# In this case `species_id` is the only column name in both dataframes, so if we skipped `left_on`
# And `right_on` arguments we would still get the same result
# What's the size of the output data?
merged_inner.shape
merged_inner
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 8 7 16 1977 1 DM M 37
6 9 7 16 1977 1 DM F 34
7 7 7 16 1977 2 PE F NaN
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN Dipodomys merriami Rodent
6 NaN Dipodomys merriami Rodent
7 NaN Peromyscus eremicus Rodent
的内连接的结果survey_sub和species_sub是包含组合组从列的新数据帧survey_sub和species_sub。它 仅包含具有两个字母的物种代码的行,该代码在survey_sub和数据species_sub帧中均相同。换句话说,如果在一排 survey_sub具有的价值species_id,它不会出现在species_id 列species,它不会被包含在数据帧返回由内连接。同样,如果在一排species_sub具有的价值species_id ,它不会出现在species_id列survey_sub,该行不会被包含在数据帧返回由内连接。
我们要联接的两个DataFramemerge使用left和right参数传递给函数。该left_on='species'参数告诉merge 使用species_id列作为survey_sub(left DataFrame)中的联接键。同样,right_on='species_id'参数告诉merge使用species_id列作为species_sub(right DataFrame)中的联接键。对于内部联接,left和right参数的顺序无关紧要。
结果merged_innerDataFrame包含来自survey_sub (记录ID,月,日等)的所有列以及来自species_sub (species_id,属,物种和分类群)的所有列。
请注意,该merged_inner行的行数少于survey_sub。这是有以行的指示surveys_df与值(一个或多个),用于species_id不存在对作为值(S)species_id在species_df。
左联接
如果我们想要什么,从信息添加species_sub到survey_sub没有丢失任何信息survey_sub?在这种情况下,我们使用另一种类型的联接,称为“左外部联接”或“左联接”。
像内部联接一样,左联接使用联接键组合两个DataFrame。与内部 联接不同,左联接将返回DataFrame中的所有行left,即使那些联接键在right DataFrame中没有值的行也是如此。数据left框中缺少连接键值的行中的行将仅对right结果连接的数据框中的那些列具有空值(即,NaN或无)。
注意:左right联接仍将丢弃DataFrame中没有DataFrame中联接键值的left行。

通过调用merge用于内部联接的相同函数,在熊猫中执行左联接,但使用how='left'参数:
merged_left = pd.merge(left=survey_sub, right=species_sub, how='left', left_on='species_id', right_on='species_id')
merged_left
record_id month day year plot_id species_id sex hindfoot_length \
0 1 7 16 1977 2 NL M 32
1 2 7 16 1977 3 NL M 33
2 3 7 16 1977 2 DM F 37
3 4 7 16 1977 7 DM M 36
4 5 7 16 1977 3 DM M 35
5 6 7 16 1977 1 PF M 14
6 7 7 16 1977 2 PE F NaN
7 8 7 16 1977 1 DM M 37
8 9 7 16 1977 1 DM F 34
9 10 7 16 1977 6 PF F 20
weight genus species taxa
0 NaN Neotoma albigula Rodent
1 NaN Neotoma albigula Rodent
2 NaN Dipodomys merriami Rodent
3 NaN Dipodomys merriami Rodent
4 NaN Dipodomys merriami Rodent
5 NaN NaN NaN NaN
6 NaN Peromyscus eremicus Rodent
7 NaN Dipodomys merriami Rodent
8 NaN Dipodomys merriami Rodent
9 NaN NaN NaN NaN
就其包含的列而言,左联接(merged_left)的结果DataFrame非常类似于内部联接(merged_inner)的结果DataFrame 。但是,与不同merged_inner,它merged_left包含与原始survey_subDataFrame相同的行数。当我们检查 merged_left中,我们发现有行,其中应该有来自信息species_sub(即species_id,genus和taxa)缺失(它们包含NaN值):
merged_left[ pd.isnull(merged_left.genus) ]
record_id month day year plot_id species_id sex hindfoot_length \
5 6 7 16 1977 1 PF M 14
9 10 7 16 1977 6 PF F 20
weight genus species taxa
5 NaN NaN NaN NaN
9 NaN NaN NaN NaN
这些行是species_idfrom中survey_sub(在本例中为PF)的值不出现的行species_sub。
其他联接类型
pandasmerge函数支持其他两种连接类型:
- 右(外)连接:通过
how='right'作为参数传递而调用。与左联接类似,除了保留DataFrame中的所有行right,而left丢弃不匹配联接键值的DataFrame中的行。 - 完全(外部)连接:通过
how='outer'作为参数传递而调用。此连接类型返回两个DataFrame中所有成对的行组合;即,结果DataFrame将NaN在其中一个数据帧中丢失数据的位置。这种连接类型很少使用。
最终挑战
挑战-发行
通过连接
surveys.csv和species.csv表的内容来创建新的DataFrame 。然后计算并绘制以下分布:
- 按情节分类
- 按性别按性别分类
挑战-多样性指数
关键点
Pandas
merge和concat可以用于合并DataFrame的子集,甚至可以合并来自不同文件的数据。
join函数根据索引或列组合DataFrame。连接两个DataFrame可以通过多种方式(左,右和内部)完成,具体取决于最终DataFrame中必须包含哪些数据。
to_csv可用于以CSV格式写出DataFrame。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号