重塑和数据透视表
通过旋转DataFrame对象进行重塑
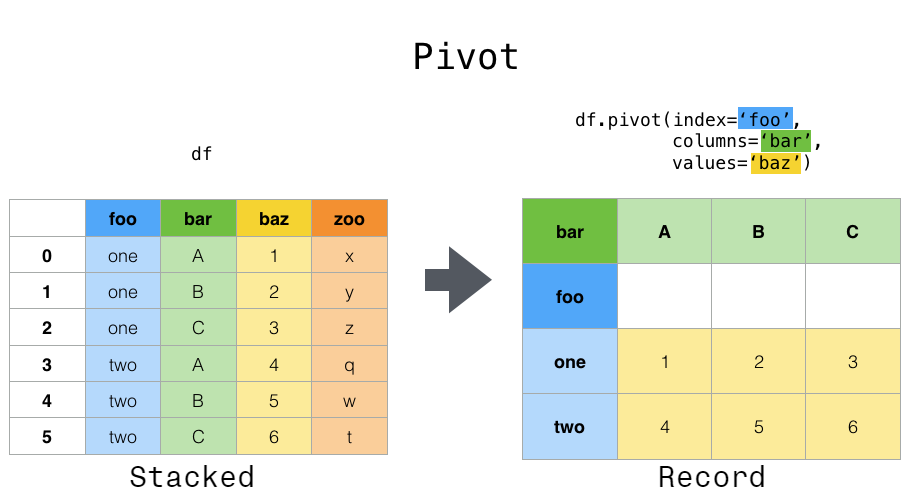
数据通常以所谓的“堆叠”或“记录”格式存储:
In [1]: df
Out[1]:
date variable value
0 2000-01-03 A 0.469112
1 2000-01-04 A -0.282863
2 2000-01-05 A -1.509059
3 2000-01-03 B -1.135632
4 2000-01-04 B 1.212112
5 2000-01-05 B -0.173215
6 2000-01-03 C 0.119209
7 2000-01-04 C -1.044236
8 2000-01-05 C -0.861849
9 2000-01-03 D -2.104569
10 2000-01-04 D -0.494929
11 2000-01-05 D 1.071804
奇怪的是,上面是如何DataFrame创建的:
import pandas._testing as tm
def unpivot(frame):
N, K = frame.shape
data = {'value': frame.to_numpy().ravel('F'),
'variable': np.asarray(frame.columns).repeat(N),
'date': np.tile(np.asarray(frame.index), K)}
return pd.DataFrame(data, columns=['date', 'variable', 'value'])
df = unpivot(tm.makeTimeDataFrame(3))
要选择所有变量,A我们可以做:
In [2]: df[df['variable'] == 'A']
Out[2]:
date variable value
0 2000-01-03 A 0.469112
1 2000-01-04 A -0.282863
2 2000-01-05 A -1.509059
但是,假设我们希望对变量进行时间序列运算。更好的表示形式是columns唯一变量和 index日期标识单独观察的位置。为了将数据重塑为这种形式,我们使用DataFrame.pivot()方法(也实现为顶级函数pivot()):
In [3]: df.pivot(index='date', columns='variable', values='value')
Out[3]:
variable A B C D
date
2000-01-03 0.469112 -1.135632 0.119209 -2.104569
2000-01-04 -0.282863 1.212112 -1.044236 -0.494929
2000-01-05 -1.509059 -0.173215 -0.861849 1.071804
如果values省略该参数,并且输入DataFrame具有多于一列的值,这些值不用作的列或索引输入pivot,则结果“透视”DataFrame将具有层次结构的列,其最高级别指示相应的值列:
In [4]: df['value2'] = df['value'] * 2
In [5]: pivoted = df.pivot(index='date', columns='variable')
In [6]: pivoted
Out[6]:
value value2
variable A B C D A B C D
date
2000-01-03 0.469112 -1.135632 0.119209 -2.104569 0.938225 -2.271265 0.238417 -4.209138
2000-01-04 -0.282863 1.212112 -1.044236 -0.494929 -0.565727 2.424224 -2.088472 -0.989859
2000-01-05 -1.509059 -0.173215 -0.861849 1.071804 -3.018117 -0.346429 -1.723698 2.143608
然后,您可以从枢纽中选择子集DataFrame:
In [7]: pivoted['value2']
Out[7]:
variable A B C D
date
2000-01-03 0.938225 -2.271265 0.238417 -4.209138
2000-01-04 -0.565727 2.424224 -2.088472 -0.989859
2000-01-05 -3.018117 -0.346429 -1.723698 2.143608
请注意,在数据是同类型类型的情况下,这将返回基础数据的视图。
注意
pivot()如果索引/列对不是唯一的,将出现错误。在这种情况下,请考虑使用后者是数据透视表的通用化,可以处理一个索引/列对的重复值。ValueError: Index contains duplicate entries, cannot reshapepivot_table()
通过堆叠和堆叠重塑
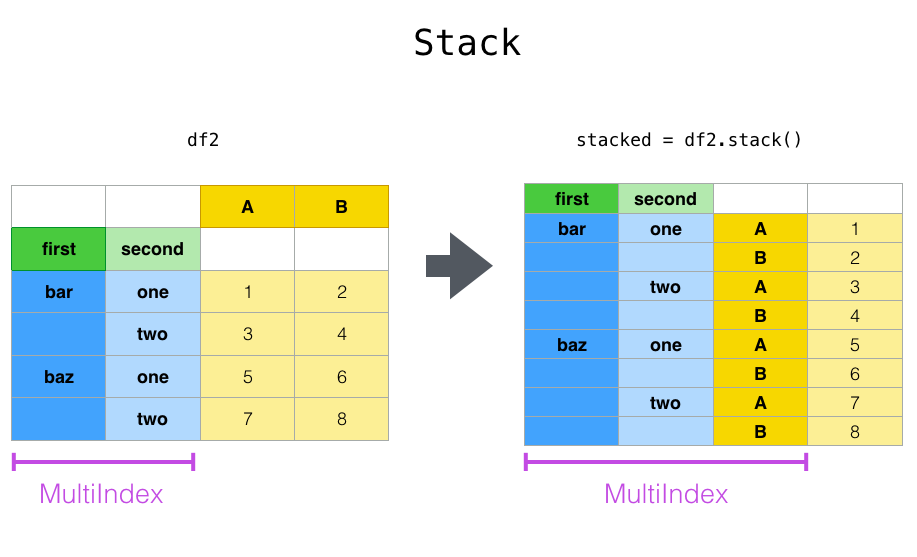
密切相关的pivot()方法相关的 stack()和unstack()可用的方法上 Series和DataFrame。这些方法旨在与MultiIndex对象一起使用 (请参阅有关分层索引的部分)。这些方法本质上是什么:
-
stack:“旋转”某一级(可能是分层的)列标签,并返回DataFrame带有索引的索引,该索引具有新的最内层的行标签。 -
unstack:(的反向操作stack)将(可能是分层的)行索引的某个级别“旋转”到列轴,从而DataFrame使用新的最内部的列标签级别进行重塑 。
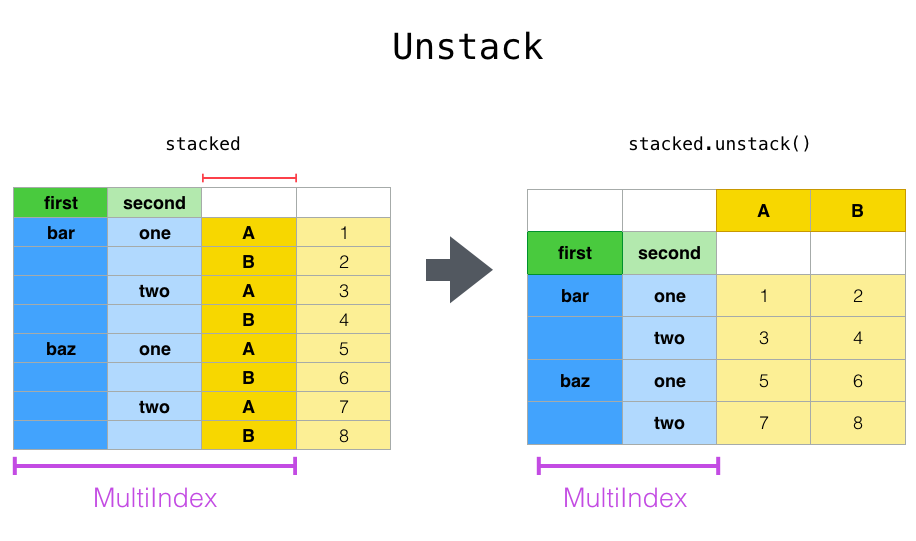
最清晰的解释方式是通过示例。让我们从分层索引部分获得一个示例数据集:
In [8]: tuples = list(zip(*[['bar', 'bar', 'baz', 'baz',
...: 'foo', 'foo', 'qux', 'qux'],
...: ['one', 'two', 'one', 'two',
...: 'one', 'two', 'one', 'two']]))
...:
In [9]: index = pd.MultiIndex.from_tuples(tuples, names=['first', 'second'])
In [10]: df = pd.DataFrame(np.random.randn(8, 2), index=index, columns=['A', 'B'])
In [11]: df2 = df[:4]
In [12]: df2
Out[12]:
A B
first second
bar one 0.721555 -0.706771
two -1.039575 0.271860
baz one -0.424972 0.567020
two 0.276232 -1.087401
该stack函数“压缩”“ DataFrame”列中的某个级别以产生以下任一行为:
-
Series在简单列索引的情况下为A。 -
A
DataFrame,在MultiIndex列中为a的情况下。
如果列中有MultiIndex,则可以选择要堆叠的级别。堆叠的级别成为MultiIndex列中a的新最低级别:
In [13]: stacked = df2.stack()
In [14]: stacked
Out[14]:
first second
bar one A 0.721555
B -0.706771
two A -1.039575
B 0.271860
baz one A -0.424972
B 0.567020
two A 0.276232
B -1.087401
dtype: float64
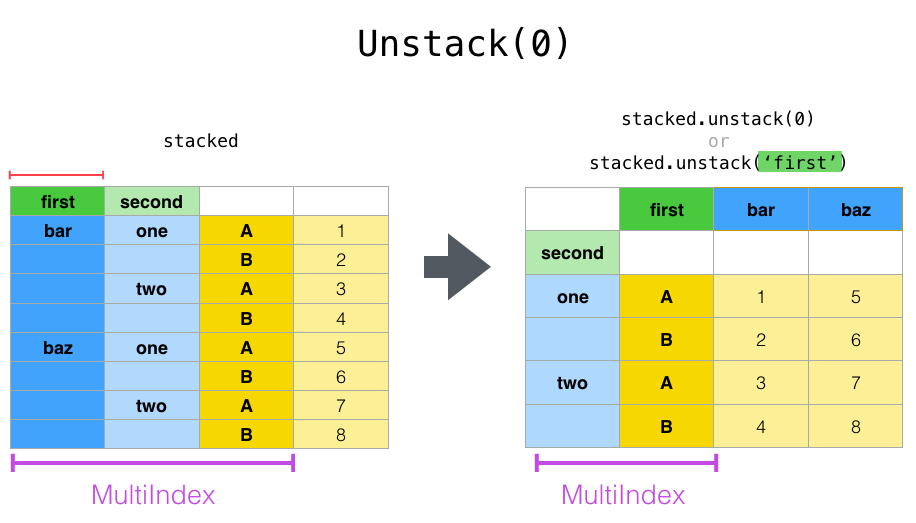
使用“ stacked”DataFrame或Series(具有aMultiIndex作为 index)时,stackis的逆运算unstack默认情况下将取消最后一级的堆叠:
In [15]: stacked.unstack()
Out[15]:
A B
first second
bar one 0.721555 -0.706771
two -1.039575 0.271860
baz one -0.424972 0.567020
two 0.276232 -1.087401
In [16]: stacked.unstack(1)
Out[16]:
second one two
first
bar A 0.721555 -1.039575
B -0.706771 0.271860
baz A -0.424972 0.276232
B 0.567020 -1.087401
In [17]: stacked.unstack(0)
Out[17]:
first bar baz
second
one A 0.721555 -0.424972
B -0.706771 0.567020
two A -1.039575 0.276232
B 0.271860 -1.087401
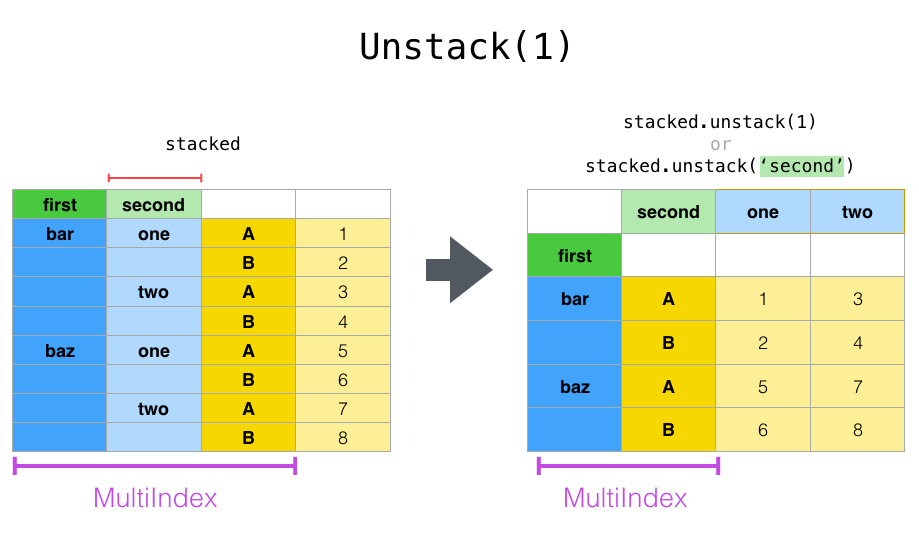
如果索引具有名称,则可以使用级别名称而不是指定级别编号:
In [18]: stacked.unstack('second')
Out[18]:
second one two
first
bar A 0.721555 -1.039575
B -0.706771 0.271860
baz A -0.424972 0.276232
B 0.567020 -1.087401
注意,stack和unstack方法隐式对涉及的索引级别进行排序。因此,一个以电话stack,然后unstack,或反之,将导致排序副本原件DataFrame或Series:
In [19]: index = pd.MultiIndex.from_product([[2, 1], ['a', 'b']])
In [20]: df = pd.DataFrame(np.random.randn(4), index=index, columns=['A'])
In [21]: df
Out[21]:
A
2 a -0.370647
b -1.157892
1 a -1.344312
b 0.844885
In [22]: all(df.unstack().stack() == df.sort_index())
Out[22]: True
TypeError如果对的调用sort_index已删除,则上面的代码将引发a 。
多层次
您还可以通过传递级别列表来一次堆叠或取消堆叠一个以上的级别,在这种情况下,最终结果就好像列表中的每个级别都是单独处理的一样。
In [23]: columns = pd.MultiIndex.from_tuples([
....: ('A', 'cat', 'long'), ('B', 'cat', 'long'),
....: ('A', 'dog', 'short'), ('B', 'dog', 'short')],
....: names=['exp', 'animal', 'hair_length']
....: )
....:
In [24]: df = pd.DataFrame(np.random.randn(4, 4), columns=columns)
In [25]: df
Out[25]:
exp A B A B
animal cat cat dog dog
hair_length long long short short
0 1.075770 -0.109050 1.643563 -1.469388
1 0.357021 -0.674600 -1.776904 -0.968914
2 -1.294524 0.413738 0.276662 -0.472035
3 -0.013960 -0.362543 -0.006154 -0.923061
In [26]: df.stack(level=['animal', 'hair_length'])
Out[26]:
exp A B
animal hair_length
0 cat long 1.075770 -0.109050
dog short 1.643563 -1.469388
1 cat long 0.357021 -0.674600
dog short -1.776904 -0.968914
2 cat long -1.294524 0.413738
dog short 0.276662 -0.472035
3 cat long -0.013960 -0.362543
dog short -0.006154 -0.923061
级别列表可以包含级别名称或级别编号(但不能同时包含两者)。
# df.stack(level=['animal', 'hair_length'])
# from above is equivalent to:
In [27]: df.stack(level=[1, 2])
Out[27]:
exp A B
animal hair_length
0 cat long 1.075770 -0.109050
dog short 1.643563 -1.469388
1 cat long 0.357021 -0.674600
dog short -1.776904 -0.968914
2 cat long -1.294524 0.413738
dog short 0.276662 -0.472035
3 cat long -0.013960 -0.362543
dog short -0.006154 -0.923061
丢失的数据
这些功能对于处理丢失的数据非常智能,并且不希望层次结构索引中的每个子组具有相同的标签集。他们还可以处理未排序的索引(但是您当然可以通过调用来对其进行排序sort_index)。这是一个更复杂的示例:
In [28]: columns = pd.MultiIndex.from_tuples([('A', 'cat'), ('B', 'dog'),
....: ('B', 'cat'), ('A', 'dog')],
....: names=['exp', 'animal'])
....:
In [29]: index = pd.MultiIndex.from_product([('bar', 'baz', 'foo', 'qux'),
....: ('one', 'two')],
....: names=['first', 'second'])
....:
In [30]: df = pd.DataFrame(np.random.randn(8, 4), index=index, columns=columns)
In [31]: df2 = df.iloc[[0, 1, 2, 4, 5, 7]]
In [32]: df2
Out[32]:
exp A B A
animal cat dog cat dog
first second
bar one 0.895717 0.805244 -1.206412 2.565646
two 1.431256 1.340309 -1.170299 -0.226169
baz one 0.410835 0.813850 0.132003 -0.827317
foo one -1.413681 1.607920 1.024180 0.569605
two 0.875906 -2.211372 0.974466 -2.006747
qux two -1.226825 0.769804 -1.281247 -0.727707
如上所述,stack可以使用level参数来调用以选择要堆叠的列中的级别:
In [33]: df2.stack('exp')
Out[33]:
animal cat dog
first second exp
bar one A 0.895717 2.565646
B -1.206412 0.805244
two A 1.431256 -0.226169
B -1.170299 1.340309
baz one A 0.410835 -0.827317
B 0.132003 0.813850
foo one A -1.413681 0.569605
B 1.024180 1.607920
two A 0.875906 -2.006747
B 0.974466 -2.211372
qux two A -1.226825 -0.727707
B -1.281247 0.769804
In [34]: df2.stack('animal')
Out[34]:
exp A B
first second animal
bar one cat 0.895717 -1.206412
dog 2.565646 0.805244
two cat 1.431256 -1.170299
dog -0.226169 1.340309
baz one cat 0.410835 0.132003
dog -0.827317 0.813850
foo one cat -1.413681 1.024180
dog 0.569605 1.607920
two cat 0.875906 0.974466
dog -2.006747 -2.211372
qux two cat -1.226825 -1.281247
dog -0.727707 0.769804
如果子组没有相同的标签集,则堆积可能会导致值丢失。默认情况下,缺失值将替换为该数据类型的默认填充值,NaNfloat,NaTdatetimelike等。对于整数类型,默认情况下,数据将转换为float,而缺失值将设置为NaN。
In [35]: df3 = df.iloc[[0, 1, 4, 7], [1, 2]]
In [36]: df3
Out[36]:
exp B
animal dog cat
first second
bar one 0.805244 -1.206412
two 1.340309 -1.170299
foo one 1.607920 1.024180
qux two 0.769804 -1.281247
In [37]: df3.unstack()
Out[37]:
exp B
animal dog cat
second one two one two
first
bar 0.805244 1.340309 -1.206412 -1.170299
foo 1.607920 NaN 1.024180 NaN
qux NaN 0.769804 NaN -1.281247
或者,unstack采用可选fill_value参数,用于指定丢失数据的值。
In [38]: df3.unstack(fill_value=-1e9)
Out[38]:
exp B
animal dog cat
second one two one two
first
bar 8.052440e-01 1.340309e+00 -1.206412e+00 -1.170299e+00
foo 1.607920e+00 -1.000000e+09 1.024180e+00 -1.000000e+09
qux -1.000000e+09 7.698036e-01 -1.000000e+09 -1.281247e+00
用多指标
在列为a时拆栈MultiIndex也要注意做正确的事情:
In [39]: df[:3].unstack(0)
Out[39]:
exp A B A
animal cat dog cat dog
first bar baz bar baz bar baz bar baz
second
one 0.895717 0.410835 0.805244 0.81385 -1.206412 0.132003 2.565646 -0.827317
two 1.431256 NaN 1.340309 NaN -1.170299 NaN -0.226169 NaN
In [40]: df2.unstack(1)
Out[40]:
exp A B A
animal cat dog cat dog
second one two one two one two one two
first
bar 0.895717 1.431256 0.805244 1.340309 -1.206412 -1.170299 2.565646 -0.226169
baz 0.410835 NaN 0.813850 NaN 0.132003 NaN -0.827317 NaN
foo -1.413681 0.875906 1.607920 -2.211372 1.024180 0.974466 0.569605 -2.006747
qux NaN -1.226825 NaN 0.769804 NaN -1.281247 NaN -0.727707
通过融合重塑
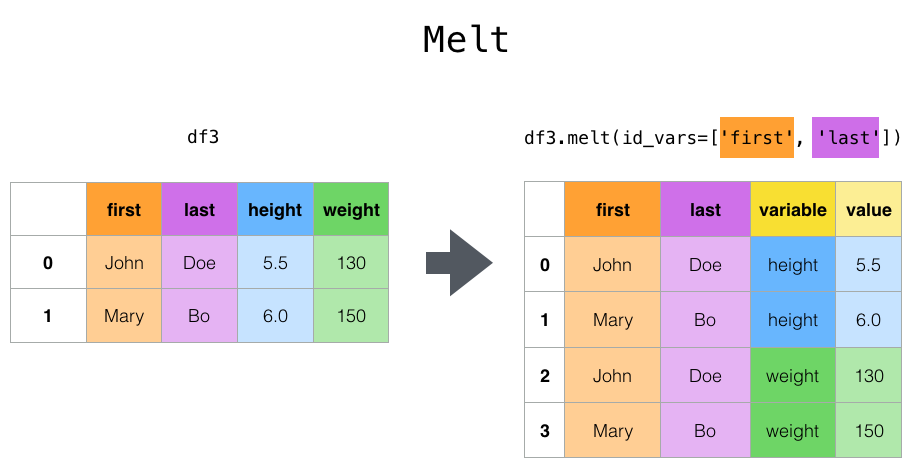
顶层melt()函数和相应的函数DataFrame.melt() 对于将a按摩DataFrame成一种格式是有用的,其中一列或多列是标识符变量,而所有其他列(被视为测量变量)都“未透视”到行轴,仅留下两个非标识符列,“变量”和“值”。可以通过提供var_name和value_name参数来自定义这些列的名称。
例如,
In [41]: cheese = pd.DataFrame({'first': ['John', 'Mary'],
....: 'last': ['Doe', 'Bo'],
....: 'height': [5.5, 6.0],
....: 'weight': [130, 150]})
....:
In [42]: cheese
Out[42]:
first last height weight
0 John Doe 5.5 130
1 Mary Bo 6.0 150
In [43]: cheese.melt(id_vars=['first', 'last'])
Out[43]:
first last variable value
0 John Doe height 5.5
1 Mary Bo height 6.0
2 John Doe weight 130.0
3 Mary Bo weight 150.0
In [44]: cheese.melt(id_vars=['first', 'last'], var_name='quantity')
Out[44]:
first last quantity value
0 John Doe height 5.5
1 Mary Bo height 6.0
2 John Doe weight 130.0
3 Mary Bo weight 150.0
使用转换DataFrame时melt(),索引将被忽略。可以通过将ignore_index参数设置为来保留原始索引值False(默认值为True)。但是,这将复制它们。
1.1.0版中的新功能。
In [45]: index = pd.MultiIndex.from_tuples([('person', 'A'), ('person', 'B')])
In [46]: cheese = pd.DataFrame({'first': ['John', 'Mary'],
....: 'last': ['Doe', 'Bo'],
....: 'height': [5.5, 6.0],
....: 'weight': [130, 150]},
....: index=index)
....:
In [47]: cheese
Out[47]:
first last height weight
person A John Doe 5.5 130
B Mary Bo 6.0 150
In [48]: cheese.melt(id_vars=['first', 'last'])
Out[48]:
first last variable value
0 John Doe height 5.5
1 Mary Bo height 6.0
2 John Doe weight 130.0
3 Mary Bo weight 150.0
In [49]: cheese.melt(id_vars=['first', 'last'], ignore_index=False)
Out[49]:
first last variable value
person A John Doe height 5.5
B Mary Bo height 6.0
A John Doe weight 130.0
B Mary Bo weight 150.0
另一种转换方式是使用wide_to_long()面板数据便利功能。它不如灵活melt(),但更易于使用。
In [50]: dft = pd.DataFrame({"A1970": {0: "a", 1: "b", 2: "c"},
....: "A1980": {0: "d", 1: "e", 2: "f"},
....: "B1970": {0: 2.5, 1: 1.2, 2: .7},
....: "B1980": {0: 3.2, 1: 1.3, 2: .1},
....: "X": dict(zip(range(3), np.random.randn(3)))
....: })
....:
In [51]: dft["id"] = dft.index
In [52]: dft
Out[52]:
A1970 A1980 B1970 B1980 X id
0 a d 2.5 3.2 -0.121306 0
1 b e 1.2 1.3 -0.097883 1
2 c f 0.7 0.1 0.695775 2
In [53]: pd.wide_to_long(dft, ["A", "B"], i="id", j="year")
Out[53]:
X A B
id year
0 1970 -0.121306 a 2.5
1 1970 -0.097883 b 1.2
2 1970 0.695775 c 0.7
0 1980 -0.121306 d 3.2
1 1980 -0.097883 e 1.3
2 1980 0.695775 f 0.1
与统计信息和GroupBy结合使用
将pivot/ stack/unstack与GroupBy以及基本的Series和DataFrame统计功能结合使用可以产生一些非常有表现力和快速的数据操作,这不足为奇。
In [54]: df
Out[54]:
exp A B A
animal cat dog cat dog
first second
bar one 0.895717 0.805244 -1.206412 2.565646
two 1.431256 1.340309 -1.170299 -0.226169
baz one 0.410835 0.813850 0.132003 -0.827317
two -0.076467 -1.187678 1.130127 -1.436737
foo one -1.413681 1.607920 1.024180 0.569605
two 0.875906 -2.211372 0.974466 -2.006747
qux one -0.410001 -0.078638 0.545952 -1.219217
two -1.226825 0.769804 -1.281247 -0.727707
In [55]: df.stack().mean(1).unstack()
Out[55]:
animal cat dog
first second
bar one -0.155347 1.685445
two 0.130479 0.557070
baz one 0.271419 -0.006733
two 0.526830 -1.312207
foo one -0.194750 1.088763
two 0.925186 -2.109060
qux one 0.067976 -0.648927
two -1.254036 0.021048
# same result, another way
In [56]: df.groupby(level=1, axis=1).mean()
Out[56]:
animal cat dog
first second
bar one -0.155347 1.685445
two 0.130479 0.557070
baz one 0.271419 -0.006733
two 0.526830 -1.312207
foo one -0.194750 1.088763
two 0.925186 -2.109060
qux one 0.067976 -0.648927
two -1.254036 0.021048
In [57]: df.stack().groupby(level=1).mean()
Out[57]:
exp A B
second
one 0.071448 0.455513
two -0.424186 -0.204486
In [58]: df.mean().unstack(0)
Out[58]:
exp A B
animal
cat 0.060843 0.018596
dog -0.413580 0.232430
透视表
虽然pivot()熊猫提供pivot_table() 了各种数据类型(字符串,数字等)的通用数据透视,但熊猫还提供了数字数据聚合的透视。
该函数pivot_table()可用于创建电子表格样式的数据透视表。有关某些高级策略,请参见本食谱。
它带有许多参数:
-
data:一个DataFrame对象。 -
values:要汇总的一列或一列列表。 -
index:与数据或它们的列表具有相同长度的列,Grouper,数组。在数据透视表索引上进行分组的键。如果传递了数组,则其使用方式与列值相同。 -
columns:与数据或它们的列表具有相同长度的列,Grouper,数组。在数据透视表列上进行分组的键。如果传递了数组,则其使用方式与列值相同。 -
aggfunc:用于汇总的函数,默认为numpy.mean。
考虑这样的数据集:
In [59]: import datetime
In [60]: df = pd.DataFrame({'A': ['one', 'one', 'two', 'three'] * 6,
....: 'B': ['A', 'B', 'C'] * 8,
....: 'C': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'] * 4,
....: 'D': np.random.randn(24),
....: 'E': np.random.randn(24),
....: 'F': [datetime.datetime(2013, i, 1) for i in range(1, 13)]
....: + [datetime.datetime(2013, i, 15) for i in range(1, 13)]})
....:
In [61]: df
Out[61]:
A B C D E F
0 one A foo 0.341734 -0.317441 2013-01-01
1 one B foo 0.959726 -1.236269 2013-02-01
2 two C foo -1.110336 0.896171 2013-03-01
3 three A bar -0.619976 -0.487602 2013-04-01
4 one B bar 0.149748 -0.082240 2013-05-01
.. ... .. ... ... ... ...
19 three B foo 0.690579 -2.213588 2013-08-15
20 one C foo 0.995761 1.063327 2013-09-15
21 one A bar 2.396780 1.266143 2013-10-15
22 two B bar 0.014871 0.299368 2013-11-15
23 three C bar 3.357427 -0.863838 2013-12-15
[24 rows x 6 columns]
我们可以很容易地从这些数据生成数据透视表:
In [62]: pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'])
Out[62]:
C bar foo
A B
one A 1.120915 -0.514058
B -0.338421 0.002759
C -0.538846 0.699535
three A -1.181568 NaN
B NaN 0.433512
C 0.588783 NaN
two A NaN 1.000985
B 0.158248 NaN
C NaN 0.176180
In [63]: pd.pivot_table(df, values='D', index=['B'], columns=['A', 'C'], aggfunc=np.sum)
Out[63]:
A one three two
C bar foo bar foo bar foo
B
A 2.241830 -1.028115 -2.363137 NaN NaN 2.001971
B -0.676843 0.005518 NaN 0.867024 0.316495 NaN
C -1.077692 1.399070 1.177566 NaN NaN 0.352360
In [64]: pd.pivot_table(df, values=['D', 'E'], index=['B'], columns=['A', 'C'],
....: aggfunc=np.sum)
....:
Out[64]:
D E
A one three two one three two
C bar foo bar foo bar foo bar foo bar foo bar foo
B
A 2.241830 -1.028115 -2.363137 NaN NaN 2.001971 2.786113 -0.043211 1.922577 NaN NaN 0.128491
B -0.676843 0.005518 NaN 0.867024 0.316495 NaN 1.368280 -1.103384 NaN -2.128743 -0.194294 NaN
C -1.077692 1.399070 1.177566 NaN NaN 0.352360 -1.976883 1.495717 -0.263660 NaN NaN 0.872482
结果对象是DataFrame在行和列上具有潜在层次索引的对象。如果values未提供列名,则数据透视表将在列的其他层次结构中包含所有可以汇总的数据:
In [65]: pd.pivot_table(df, index=['A', 'B'], columns=['C'])
Out[65]:
D E
C bar foo bar foo
A B
one A 1.120915 -0.514058 1.393057 -0.021605
B -0.338421 0.002759 0.684140 -0.551692
C -0.538846 0.699535 -0.988442 0.747859
three A -1.181568 NaN 0.961289 NaN
B NaN 0.433512 NaN -1.064372
C 0.588783 NaN -0.131830 NaN
two A NaN 1.000985 NaN 0.064245
B 0.158248 NaN -0.097147 NaN
C NaN 0.176180 NaN 0.436241
另外,您可以使用Grouperforindex和columns关键字。有关详细信息Grouper,请参见使用Grouper规范进行分组。
In [66]: pd.pivot_table(df, values='D', index=pd.Grouper(freq='M', key='F'),
....: columns='C')
....:
Out[66]:
C bar foo
F
2013-01-31 NaN -0.514058
2013-02-28 NaN 0.002759
2013-03-31 NaN 0.176180
2013-04-30 -1.181568 NaN
2013-05-31 -0.338421 NaN
2013-06-30 -0.538846 NaN
2013-07-31 NaN 1.000985
2013-08-31 NaN 0.433512
2013-09-30 NaN 0.699535
2013-10-31 1.120915 NaN
2013-11-30 0.158248 NaN
2013-12-31 0.588783 NaN
to_string如果愿意,可以通过调用以下方法来呈现表的良好输出,从而省略缺失值:
In [67]: table = pd.pivot_table(df, index=['A', 'B'], columns=['C'])
In [68]: print(table.to_string(na_rep=''))
D E
C bar foo bar foo
A B
one A 1.120915 -0.514058 1.393057 -0.021605
B -0.338421 0.002759 0.684140 -0.551692
C -0.538846 0.699535 -0.988442 0.747859
three A -1.181568 0.961289
B 0.433512 -1.064372
C 0.588783 -0.131830
two A 1.000985 0.064245
B 0.158248 -0.097147
C 0.176180 0.436241
- 请注意,
pivot_table它也可以作为DataFrame上的实例方法使用,
添加边距
如果您传递margins=True到pivot_table,All则会添加特殊的列和行,并在行和列的类别之间添加部分组聚合:
In [69]: df.pivot_table(index=['A', 'B'], columns='C', margins=True, aggfunc=np.std)
Out[69]:
D E
C bar foo All bar foo All
A B
one A 1.804346 1.210272 1.569879 0.179483 0.418374 0.858005
B 0.690376 1.353355 0.898998 1.083825 0.968138 1.101401
C 0.273641 0.418926 0.771139 1.689271 0.446140 1.422136
three A 0.794212 NaN 0.794212 2.049040 NaN 2.049040
B NaN 0.363548 0.363548 NaN 1.625237 1.625237
C 3.915454 NaN 3.915454 1.035215 NaN 1.035215
two A NaN 0.442998 0.442998 NaN 0.447104 0.447104
B 0.202765 NaN 0.202765 0.560757 NaN 0.560757
C NaN 1.819408 1.819408 NaN 0.650439 0.650439
All 1.556686 0.952552 1.246608 1.250924 0.899904 1.059389
交叉表格
使用crosstab()计算的两个(或更多)的因素交叉列表。默认情况下crosstab,除非传递值数组和聚合函数,否则将计算因子的频率表。
它需要很多参数
-
index:类似于数组,在行中按分组的值。 -
columns:类似于数组,在列中按分组的值。 -
values:类似数组的,可选的值数组,可根据因素进行汇总。 -
aggfunc:函数,可选,如果未传递任何值数组,则计算频率表。 -
rownames:sequence,默认为None,必须与传递的行数组数匹配。 -
colnames:序列,默认值None,如果传递,则必须与传递的列数组数匹配。 -
margins:布尔值,默认值False,添加行/列边距(小计) -
normalize:布尔值,{'all','index','columns'}或{0,1}(默认)False。通过将所有值除以值的总和进行归一化。
Series除非指定交叉列表的行名或列名,否则任何传递的都将使用其name属性
例如:
In [70]: foo, bar, dull, shiny, one, two = 'foo', 'bar', 'dull', 'shiny', 'one', 'two'
In [71]: a = np.array([foo, foo, bar, bar, foo, foo], dtype=object)
In [72]: b = np.array([one, one, two, one, two, one], dtype=object)
In [73]: c = np.array([dull, dull, shiny, dull, dull, shiny], dtype=object)
In [74]: pd.crosstab(a, [b, c], rownames=['a'], colnames=['b', 'c'])
Out[74]:
b one two
c dull shiny dull shiny
a
bar 1 0 0 1
foo 2 1 1 0
如果crosstab仅接收两个系列,它将提供一个频率表。
In [75]: df = pd.DataFrame({'A': [1, 2, 2, 2, 2], 'B': [3, 3, 4, 4, 4],
....: 'C': [1, 1, np.nan, 1, 1]})
....:
In [76]: df
Out[76]:
A B C
0 1 3 1.0
1 2 3 1.0
2 2 4 NaN
3 2 4 1.0
4 2 4 1.0
In [77]: pd.crosstab(df['A'], df['B'])
Out[77]:
B 3 4
A
1 1 0
2 1 3
crosstab也可以实现为Categorical数据。
In [78]: foo = pd.Categorical(['a', 'b'], categories=['a', 'b', 'c'])
In [79]: bar = pd.Categorical(['d', 'e'], categories=['d', 'e', 'f'])
In [80]: pd.crosstab(foo, bar)
Out[80]:
col_0 d e
row_0
a 1 0
b 0 1
如果您想包括所有数据类别,即使实际数据不包含特定类别的任何实例,也应设置dropna=False。
例如:
In [81]: pd.crosstab(foo, bar, dropna=False)
Out[81]:
col_0 d e f
row_0
a 1 0 0
b 0 1 0
c 0 0 0
归
频率表也可以使用normalize参数归一化以显示百分比,而不是计数:
In [82]: pd.crosstab(df['A'], df['B'], normalize=True)
Out[82]:
B 3 4
A
1 0.2 0.0
2 0.2 0.6
normalize 还可以规范每一行或每一列中的值:
In [83]: pd.crosstab(df['A'], df['B'], normalize='columns')
Out[83]:
B 3 4
A
1 0.5 0.0
2 0.5 1.0
crosstab还可以传递第三个Series和一个聚合函数(aggfunc),该函数将应用于Series前两个所定义的每个组中第三个的值Series:
In [84]: pd.crosstab(df['A'], df['B'], values=df['C'], aggfunc=np.sum)
Out[84]:
B 3 4
A
1 1.0 NaN
2 1.0 2.0
添加边距
最后,还可以增加边距或将输出标准化。
In [85]: pd.crosstab(df['A'], df['B'], values=df['C'], aggfunc=np.sum, normalize=True,
....: margins=True)
....:
Out[85]:
B 3 4 All
A
1 0.25 0.0 0.25
2 0.25 0.5 0.75
All 0.50 0.5 1.00
平铺
该cut()函数为输入数组的值计算分组,通常用于将连续变量转换为离散变量或分类变量:
In [86]: ages = np.array([10, 15, 13, 12, 23, 25, 28, 59, 60])
In [87]: pd.cut(ages, bins=3)
Out[87]:
[(9.95, 26.667], (9.95, 26.667], (9.95, 26.667], (9.95, 26.667], (9.95, 26.667], (9.95, 26.667], (26.667, 43.333], (43.333, 60.0], (43.333, 60.0]]
Categories (3, interval[float64]): [(9.95, 26.667] < (26.667, 43.333] < (43.333, 60.0]]
如果bins关键字是整数,则会形成等宽的bin。或者,我们可以指定自定义bin-edges:
In [88]: c = pd.cut(ages, bins=[0, 18, 35, 70])
In [89]: c
Out[89]:
[(0, 18], (0, 18], (0, 18], (0, 18], (18, 35], (18, 35], (18, 35], (35, 70], (35, 70]]
Categories (3, interval[int64]): [(0, 18] < (18, 35] < (35, 70]]
如果bins关键字是IntervalIndex,则这些将用于对传递的数据进行装箱:
pd.cut([25, 20, 50], bins=c.categories)
计算指示器/虚变量
要将分类变量转换为“虚拟”或“指示符” DataFrame,例如DataFrame(a Series)中具有k不同值DataFrame的k列,可以使用以下方法派生包含1和0的列 get_dummies():
In [90]: df = pd.DataFrame({'key': list('bbacab'), 'data1': range(6)})
In [91]: pd.get_dummies(df['key'])
Out[91]:
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
有时为列名加上前缀是很有用的,例如,在将结果与原始合并时DataFrame:
In [92]: dummies = pd.get_dummies(df['key'], prefix='key')
In [93]: dummies
Out[93]:
key_a key_b key_c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
In [94]: df[['data1']].join(dummies)
Out[94]:
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
此函数通常与离散化函数一起使用,例如cut:
In [95]: values = np.random.randn(10)
In [96]: values
Out[96]:
array([ 0.4082, -1.0481, -0.0257, -0.9884, 0.0941, 1.2627, 1.29 ,
0.0824, -0.0558, 0.5366])
In [97]: bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
In [98]: pd.get_dummies(pd.cut(values, bins))
Out[98]:
(0.0, 0.2] (0.2, 0.4] (0.4, 0.6] (0.6, 0.8] (0.8, 1.0]
0 0 0 1 0 0
1 0 0 0 0 0
2 0 0 0 0 0
3 0 0 0 0 0
4 1 0 0 0 0
5 0 0 0 0 0
6 0 0 0 0 0
7 1 0 0 0 0
8 0 0 0 0 0
9 0 0 1 0 0
get_dummies()也接受一个DataFrame。默认情况下,所有类别变量(统计意义上的类别变量,具有对象或 类别dtype的变量)均被编码为伪变量。
In [99]: df = pd.DataFrame({'A': ['a', 'b', 'a'], 'B': ['c', 'c', 'b'],
....: 'C': [1, 2, 3]})
....:
In [100]: pd.get_dummies(df)
Out[100]:
C A_a A_b B_b B_c
0 1 1 0 0 1
1 2 0 1 0 1
2 3 1 0 1 0
所有非对象列均未包含在输出中。您可以控制使用columns关键字编码的列。
In [101]: pd.get_dummies(df, columns=['A'])
Out[101]:
B C A_a A_b
0 c 1 1 0
1 c 2 0 1
2 b 3 1 0
请注意,该B列仍包含在输出中,只是尚未进行编码。如果您不想在输出中包含它,可以B在调用之前删除get_dummies它。
如同Series版本,您可以为传递值prefix和 prefix_sep。默认情况下,列名用作前缀,“ _”用作前缀分隔符。您可以通过3种方式指定prefix和prefix_sep:
-
串:使用相同的值
prefix或prefix_sep用于待编码的每一列。 -
list:长度必须与要编码的列数相同。
-
dict:将列名称映射到前缀。
In [102]: simple = pd.get_dummies(df, prefix='new_prefix')
In [103]: simple
Out[103]:
C new_prefix_a new_prefix_b new_prefix_b new_prefix_c
0 1 1 0 0 1
1 2 0 1 0 1
2 3 1 0 1 0
In [104]: from_list = pd.get_dummies(df, prefix=['from_A', 'from_B'])
In [105]: from_list
Out[105]:
C from_A_a from_A_b from_B_b from_B_c
0 1 1 0 0 1
1 2 0 1 0 1
2 3 1 0 1 0
In [106]: from_dict = pd.get_dummies(df, prefix={'B': 'from_B', 'A': 'from_A'})
In [107]: from_dict
Out[107]:
C from_A_a from_A_b from_B_b from_B_c
0 1 1 0 0 1
1 2 0 1 0 1
2 3 1 0 1 0
有时,将结果提供给统计模型时,仅保留k-1个分类变量级别以避免共线性是很有用的。您可以通过打开切换到此模式drop_first。
In [108]: s = pd.Series(list('abcaa'))
In [109]: pd.get_dummies(s)
Out[109]:
a b c
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
4 1 0 0
In [110]: pd.get_dummies(s, drop_first=True)
Out[110]:
b c
0 0 0
1 1 0
2 0 1
3 0 0
4 0 0
当一列仅包含一个级别时,其结果将被省略。
In [111]: df = pd.DataFrame({'A': list('aaaaa'), 'B': list('ababc')})
In [112]: pd.get_dummies(df)
Out[112]:
A_a B_a B_b B_c
0 1 1 0 0
1 1 0 1 0
2 1 1 0 0
3 1 0 1 0
4 1 0 0 1
In [113]: pd.get_dummies(df, drop_first=True)
Out[113]:
B_b B_c
0 0 0
1 1 0
2 0 0
3 1 0
4 0 1
默认情况下,新列将具有np.uint8dtype。要选择另一个dtype,请使用dtype参数:
In [114]: df = pd.DataFrame({'A': list('abc'), 'B': [1.1, 2.2, 3.3]})
In [115]: pd.get_dummies(df, dtype=bool).dtypes
Out[115]:
B float64
A_a bool
A_b bool
A_c bool
dtype: object
0.23.0版中的新功能。
分解值
要将一维值编码为枚举类型,请使用factorize():
In [116]: x = pd.Series(['A', 'A', np.nan, 'B', 3.14, np.inf])
In [117]: x
Out[117]:
0 A
1 A
2 NaN
3 B
4 3.14
5 inf
dtype: object
In [118]: labels, uniques = pd.factorize(x)
In [119]: labels
Out[119]: array([ 0, 0, -1, 1, 2, 3])
In [120]: uniques
Out[120]: Index(['A', 'B', 3.14, inf], dtype='object')
请注意,该factorize操作类似于numpy.unique,但在处理NaN方面有所不同:
注意
numpy.unique在Python 3下,以下命令会TypeError 因订购错误而失败,并带有。另请参阅 此处。
In [1]: x = pd.Series(['A', 'A', np.nan, 'B', 3.14, np.inf])
In [2]: pd.factorize(x, sort=True)
Out[2]:
(array([ 2, 2, -1, 3, 0, 1]),
Index([3.14, inf, 'A', 'B'], dtype='object'))
In [3]: np.unique(x, return_inverse=True)[::-1]
Out[3]: (array([3, 3, 0, 4, 1, 2]), array([nan, 3.14, inf, 'A', 'B'], dtype=object))
注意
如果您只想将一列作为分类变量(如R的因数)处理,则可以使用 或 。有关完整的文档,请参阅分类简介和 API文档。df["cat_col"] = pd.Categorical(df["col"])df["cat_col"] = df["col"].astype("category")Categorical
例子
在本节中,我们将回顾常见问题和示例。列名和相关列值的命名与在以下答案中如何旋转此DataFrame相对应。
In [121]: np.random.seed([3, 1415])
In [122]: n = 20
In [123]: cols = np.array(['key', 'row', 'item', 'col'])
In [124]: df = cols + pd.DataFrame((np.random.randint(5, size=(n, 4))
.....: // [2, 1, 2, 1]).astype(str))
.....:
In [125]: df.columns = cols
In [126]: df = df.join(pd.DataFrame(np.random.rand(n, 2).round(2)).add_prefix('val'))
In [127]: df
Out[127]:
key row item col val0 val1
0 key0 row3 item1 col3 0.81 0.04
1 key1 row2 item1 col2 0.44 0.07
2 key1 row0 item1 col0 0.77 0.01
3 key0 row4 item0 col2 0.15 0.59
4 key1 row0 item2 col1 0.81 0.64
.. ... ... ... ... ... ...
15 key0 row3 item1 col1 0.31 0.23
16 key0 row0 item2 col3 0.86 0.01
17 key0 row4 item0 col3 0.64 0.21
18 key2 row2 item2 col0 0.13 0.45
19 key0 row2 item0 col4 0.37 0.70
[20 rows x 6 columns]
单聚合枢
假设我们要透视df以使col值是列, row值是索引,值的均值val0是?特别是,生成的DataFrame应该看起来像:
col col0 col1 col2 col3 col4
row
row0 0.77 0.605 NaN 0.860 0.65
row2 0.13 NaN 0.395 0.500 0.25
row3 NaN 0.310 NaN 0.545 NaN
row4 NaN 0.100 0.395 0.760 0.24
此解决方案使用pivot_table()。另请注意,这 aggfunc='mean'是默认设置。此处包含它是明确的。
In [128]: df.pivot_table(
.....: values='val0', index='row', columns='col', aggfunc='mean')
.....:
Out[128]:
col col0 col1 col2 col3 col4
row
row0 0.77 0.605 NaN 0.860 0.65
row2 0.13 NaN 0.395 0.500 0.25
row3 NaN 0.310 NaN 0.545 NaN
row4 NaN 0.100 0.395 0.760 0.24
请注意,我们还可以使用fill_value 参数替换缺少的值。
In [129]: df.pivot_table(
.....: values='val0', index='row', columns='col', aggfunc='mean', fill_value=0)
.....:
Out[129]:
col col0 col1 col2 col3 col4
row
row0 0.77 0.605 0.000 0.860 0.65
row2 0.13 0.000 0.395 0.500 0.25
row3 0.00 0.310 0.000 0.545 0.00
row4 0.00 0.100 0.395 0.760 0.24
还要注意,我们也可以传入其他聚合函数。例如,我们也可以传入sum。
In [130]: df.pivot_table(
.....: values='val0', index='row', columns='col', aggfunc='sum', fill_value=0)
.....:
Out[130]:
col col0 col1 col2 col3 col4
row
row0 0.77 1.21 0.00 0.86 0.65
row2 0.13 0.00 0.79 0.50 0.50
row3 0.00 0.31 0.00 1.09 0.00
row4 0.00 0.10 0.79 1.52 0.24
我们可以做的另一种汇总方法是计算列和行一起出现的频率,也称为“交叉表”。为此,我们可以传递 size给aggfunc参数。
In [131]: df.pivot_table(index='row', columns='col', fill_value=0, aggfunc='size')
Out[131]:
col col0 col1 col2 col3 col4
row
row0 1 2 0 1 1
row2 1 0 2 1 2
row3 0 1 0 2 0
row4 0 1 2 2 1
使用多个聚合枢轴
我们还可以执行多个聚合。例如,要同时执行 sum和mean,我们可以将列表传递给aggfunc参数。
In [132]: df.pivot_table(
.....: values='val0', index='row', columns='col', aggfunc=['mean', 'sum'])
.....:
Out[132]:
mean sum
col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4
row
row0 0.77 0.605 NaN 0.860 0.65 0.77 1.21 NaN 0.86 0.65
row2 0.13 NaN 0.395 0.500 0.25 0.13 NaN 0.79 0.50 0.50
row3 NaN 0.310 NaN 0.545 NaN NaN 0.31 NaN 1.09 NaN
row4 NaN 0.100 0.395 0.760 0.24 NaN 0.10 0.79 1.52 0.24
注意要聚合多个值列,我们可以将列表传递给 values参数。
In [133]: df.pivot_table(
.....: values=['val0', 'val1'], index='row', columns='col', aggfunc=['mean'])
.....:
Out[133]:
mean
val0 val1
col col0 col1 col2 col3 col4 col0 col1 col2 col3 col4
row
row0 0.77 0.605 NaN 0.860 0.65 0.01 0.745 NaN 0.010 0.02
row2 0.13 NaN 0.395 0.500 0.25 0.45 NaN 0.34 0.440 0.79
row3 NaN 0.310 NaN 0.545 NaN NaN 0.230 NaN 0.075 NaN
row4 NaN 0.100 0.395 0.760 0.24 NaN 0.070 0.42 0.300 0.46
注意要细分为多列,我们可以将列表传递给 columns参数。
In [134]: df.pivot_table(
.....: values=['val0'], index='row', columns=['item', 'col'], aggfunc=['mean'])
.....:
Out[134]:
mean
val0
item item0 item1 item2
col col2 col3 col4 col0 col1 col2 col3 col4 col0 col1 col3 col4
row
row0 NaN NaN NaN 0.77 NaN NaN NaN NaN NaN 0.605 0.86 0.65
row2 0.35 NaN 0.37 NaN NaN 0.44 NaN NaN 0.13 NaN 0.50 0.13
row3 NaN NaN NaN NaN 0.31 NaN 0.81 NaN NaN NaN 0.28 NaN
row4 0.15 0.64 NaN NaN 0.10 0.64 0.88 0.24 NaN NaN NaN NaN
Exploding a list-like column
0.25.0版中的新功能。
有时列中的值类似于列表。
In [135]: keys = ['panda1', 'panda2', 'panda3']
In [136]: values = [['eats', 'shoots'], ['shoots', 'leaves'], ['eats', 'leaves']]
In [137]: df = pd.DataFrame({'keys': keys, 'values': values})
In [138]: df
Out[138]:
keys values
0 panda1 [eats, shoots]
1 panda2 [shoots, leaves]
2 panda3 [eats, leaves]
我们可以使用来“values分解”列,将每个列表式转换为单独的行explode()。这将复制原始行中的索引值:
In [139]: df['values'].explode()
Out[139]:
0 eats
0 shoots
1 shoots
1 leaves
2 eats
2 leaves
Name: values, dtype: object
You can also explode the column in the DataFrame
In [140]: df.explode('values')
Out[140]:
keys values
0 panda1 eats
0 panda1 shoots
1 panda2 shoots
1 panda2 leaves
2 panda3 eats
2 panda3 leaves
Series.explode()将用替换空列表np.nan并保留标量条目。结果的dtypeSeries始终为object。
In [141]: s = pd.Series([[1, 2, 3], 'foo', [], ['a', 'b']])
In [142]: s
Out[142]:
0 [1, 2, 3]
1 foo
2 []
3 [a, b]
dtype: object
In [143]: s.explode()
Out[143]:
0 1
0 2
0 3
1 foo
2 NaN
3 a
3 b
dtype: object
这是一个典型的用例。您在列中用逗号分隔了字符串,并希望对此进行扩展。
In [144]: df = pd.DataFrame([{'var1': 'a,b,c', 'var2': 1},
.....: {'var1': 'd,e,f', 'var2': 2}])
.....:
In [145]: df
Out[145]:
var1 var2
0 a,b,c 1
1 d,e,f 2
使用爆炸和链接操作现在很容易创建长格式的DataFrame
Creating a long form DataFrame is now straightforward using explode and chained operations
In [146]: df.assign(var1=df.var1.str.split(',')).explode('var1')
Out[146]:
var1 var2
0 a 1
0 b 1
0 c 1
1 d 2
1 e 2
1 f 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号