Pandas数据分析介绍

熊猫数据帧是一个结构,它包含二维数据和其相应的标签。DataFrames广泛用于数据科学,机器学习,科学计算以及许多其他数据密集型领域。
数据框类似于SQL表或您在Excel或Calc中使用的电子表格。在许多情况下,DataFrames比表格或电子表格更快,更易于使用且功能更强大,因为它们是Python和NumPy生态系统的组成部分。
在本教程中,您将学习:
- 什么是Pandas DataFrame以及如何创建一个
- 如何访问,修改,添加,排序,过滤和删除数据
- 如何处理缺失值
- 如何使用时间序列数据
- 如何快速可视化数据
是时候开始使用Pandas DataFrames了!介绍大熊猫数据帧
Pandas DataFrames是包含以下内容的数据结构:
- 数据以二维(行和列)进行组织
- 对应于行和列的标签
您可以通过导入 Pandas开始使用DataFrames :
>>> import pandas as pd
现在您已经导入了熊猫,您可以使用DataFrames了。
想象一下,您正在使用Pandas分析有关应聘者的数据,以便使用Python开发Web应用程序。假设您对应聘者的姓名,城市,年龄和分数感兴趣,您可以使用Python编程测试,也可以py-score:
name | city | age | py-score | |
|---|---|---|---|---|
101 |
Xavier |
Mexico City |
41 |
88.0 |
102 |
Ann |
Toronto |
28 |
79.0 |
103 |
Jana |
Prague |
33 |
81.0 |
104 |
Yi |
Shanghai |
34 |
80.0 |
105 |
Robin |
Manchester |
38 |
68.0 |
106 |
Amal |
Cairo |
31 |
61.0 |
107 |
Nori |
Osaka |
37 |
84.0 |
在该表中,第一行包含列标签(name,city,age和py-score)。第一列包含行标签(101,102等)。所有其他单元格都填充有数据值。
现在,您拥有创建Pandas DataFrame所需的一切。
有几种创建Pandas DataFrame的方法。在大多数情况下,您将使用DataFrame构造函数并提供数据,标签和其他信息。您可以将数据作为二维列表,元组或NumPy数组传递。您也可以将其作为字典或PandasSeries实例,或作为本教程未介绍的其他几种数据类型之一传递。
对于此示例,假设您使用字典来传递数据:
>>> data = {
... 'name': ['Xavier', 'Ann', 'Jana', 'Yi', 'Robin', 'Amal', 'Nori'],
... 'city': ['Mexico City', 'Toronto', 'Prague', 'Shanghai',
... 'Manchester', 'Cairo', 'Osaka'],
... 'age': [41, 28, 33, 34, 38, 31, 37],
... 'py-score': [88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0]
... }
>>> row_labels = [101, 102, 103, 104, 105, 106, 107]
data是一个Python变量,它引用保存您的候选数据的字典。它还包含列的标签:
'name''city''age''py-score'
最后,row_labels指向包含行标签的列表,行标签是从101到的数字107。
现在您可以创建一个Pandas DataFrame:
>>> df = pd.DataFrame(data=data, index=row_labels)
>>> df
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
而已!df是一个变量,其中包含对Pandas DataFrame的引用。该Pandas DataFrame看起来像上面的候选表,并具有以下功能:
- 行标签从
101到107 - 列标签,例如
'name','city','age',和'py-score' - 数据如候选人姓名,城市,年龄,和Python测试成绩
该图显示了来自的标签和数据df:
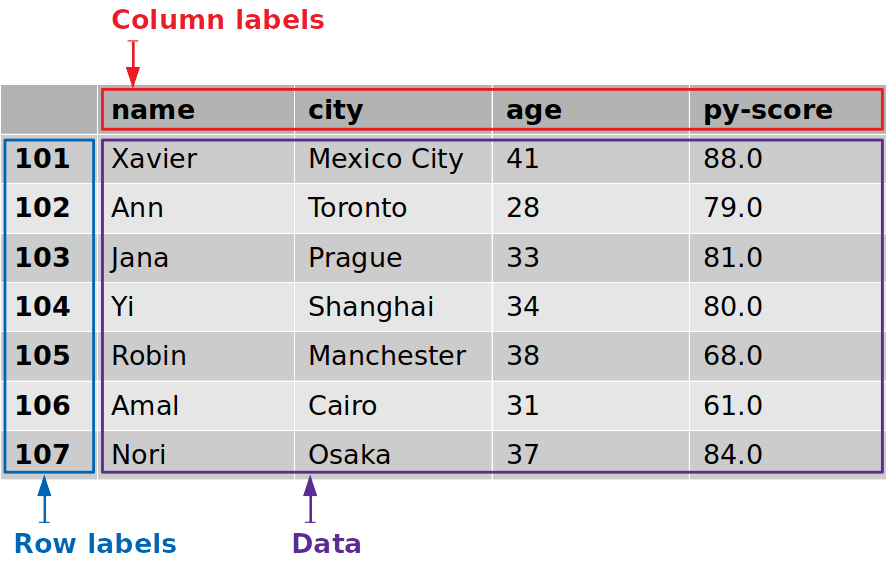
行标签用蓝色框起来,而列标签用红色框起来,数据值用紫色框起来。
Pandas DataFrames有时可能非常大,使其无法一次查看所有行。您可以.head()用来显示前几项,也.tail()可以显示后几项:
>>> df.head(n=2)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
>>> df.tail(n=2)
name city age py-score
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
这样便可以仅显示Pandas DataFrame的开头或结尾。该参数n指定要显示的行数。
注意:将Pandas DataFrame视为具有许多附加功能的列字典或Pandas Series可能会有所帮助。
您可以按照从字典中获取值的方式访问Pandas DataFrame中的列:
>>> cities = df['city']
>>> cities
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: object
这是从Pandas DataFrame获取列的最方便的方法。
如果列名是一个有效的Python标识符字符串,则可以使用点表示法来访问它。也就是说,您可以按照获取类实例的属性的方式访问列:
>>> df.city
101 Mexico City
102 Toronto
103 Prague
104 Shanghai
105 Manchester
106 Cairo
107 Osaka
Name: city, dtype: object
这就是您获得特定列的方式。您已经提取了与label对应的列'city',其中包含所有求职者的位置。
请注意,您已经提取了数据和相应的行标签,这一点很重要:
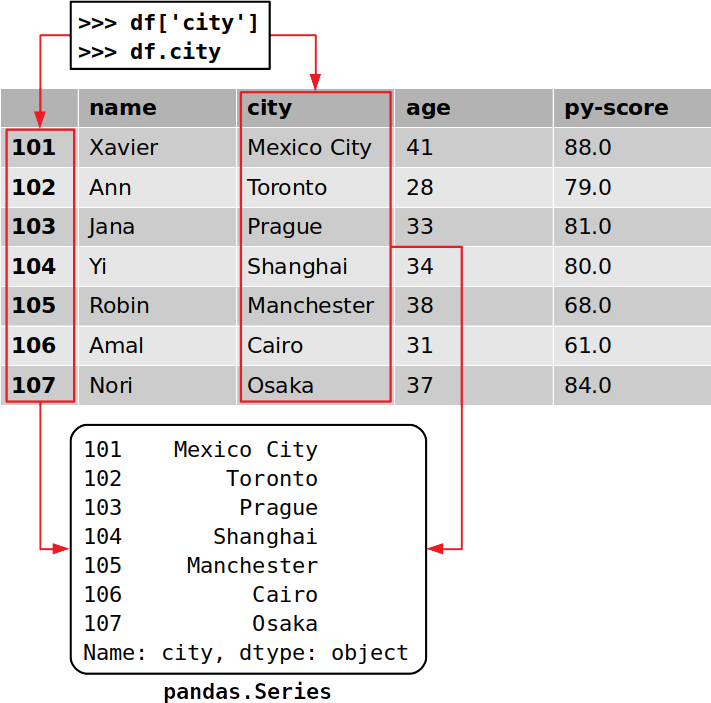
Pandas DataFrame的每一列都是的实例,该实例pandas.Series保存一维数据及其标签。Series通过使用其标签作为键,可以像使用字典一样获得对象的单个项目:
>>> cities[102]
'Toronto'
在这种情况下,'Toronto'是数据值,并且102是对应的标签。正如您将在后面的部分中看到的那样,还有其他方法可以在Pandas DataFrame中获取特定项目。
>>> df.loc[103]
name Jana
city Prague
age 33
py-score 81
Name: 103, dtype: object
这次,您提取了与标签相对应的行103,其中包含名为的候选人的数据Jana。除了该行的数据值之外,您还提取了相应列的标签:
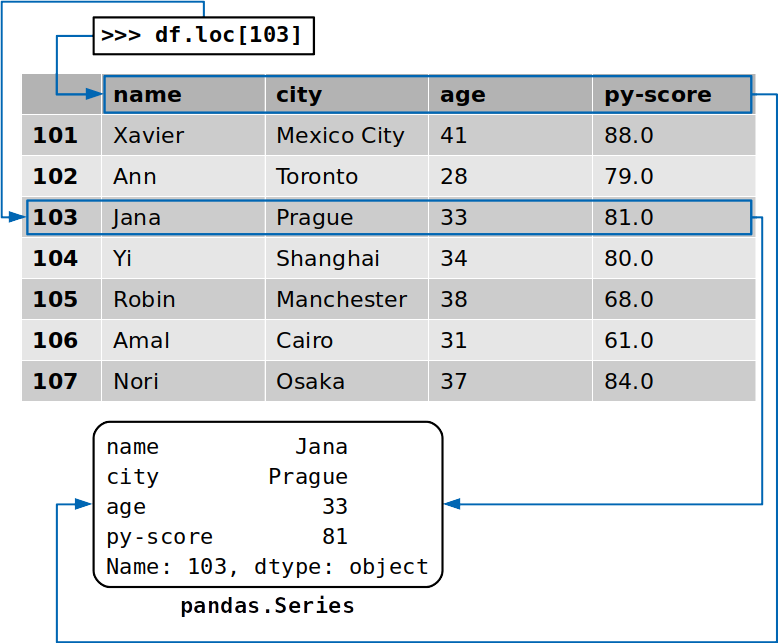
返回的行也是的实例pandas.Series。
创建熊猫数据帧
如前所述,有几种创建Pandas DataFrame的方法。在本节中,您将学习如何使用DataFrame构造函数以及以下内容来做到这一点:
- Python字典
- Python清单
- 二维NumPy数组
- 档案
还有其他方法,您可以在官方文档中了解到。
您可以首先将Pandas和NumPy一起导入,在以下示例中将使用它们:
>>> import numpy as np
>>> import pandas as pd
而已。现在,您准备创建一些DataFrames。
创建熊猫数据框使用词典
如您所见,您可以使用Python字典创建Pandas DataFrame:
>>> d = {'x': [1, 2, 3], 'y': np.array([2, 4, 8]), 'z': 100}
>>> pd.DataFrame(d)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
字典的键是DataFrame的列标签,而字典的值是相应DataFrame列中的数据值。这些值可以包含在tuple,list,一维NumPy数组,PandasSeries对象或其他几种数据类型之一中。您还可以提供一个将沿整列复制的值。
可以使用columns参数和行标签控制列的顺序index:
>>> pd.DataFrame(d, index=[100, 200, 300], columns=['z', 'y', 'x'])
z y x
100 100 2 1
200 100 4 2
300 100 8 3
正如你所看到的,您所指定的行标签100,200和300。您也已经被迫列的顺序:z,y,x。
创建熊猫数据框使用列表
创建Pandas DataFrame的另一种方法是使用词典列表:
>>> l = [{'x': 1, 'y': 2, 'z': 100},
... {'x': 2, 'y': 4, 'z': 100},
... {'x': 3, 'y': 8, 'z': 100}]
>>> pd.DataFrame(l)
x y z
0 1 2 100
1 2 4 100
2 3 8 100
同样,字典键是列标签,字典值是DataFrame中的数据值。
您还可以使用嵌套列表或列表列表作为数据值。如果这样做,明智的做法是在创建DataFrame时显式指定列,行或两者的标签:
>>> l = [[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]]
>>> pd.DataFrame(l, columns=['x', 'y', 'z'])
x y z
0 1 2 100
1 2 4 100
2 3 8 100
这样便可以使用嵌套列表创建Pandas DataFrame。您也可以以相同的方式使用元组列表。为此,只需将上面示例中的嵌套列表替换为元组即可。
使用NumPy数组创建Pandas DataFrame
您可以DataFrame使用与列表相同的方式将二维NumPy数组传递给构造函数:
>>> arr = np.array([[1, 2, 100],
... [2, 4, 100],
... [3, 8, 100]])
>>> df_ = pd.DataFrame(arr, columns=['x', 'y', 'z'])
>>> df_
x y z
0 1 2 100
1 2 4 100
2 3 8 100
尽管此示例看起来与上面的嵌套列表实现几乎相同,但是它具有一个优点:您可以指定optional参数copy。
当copy设置为False(默认设置)时,不会复制NumPy数组中的数据。这意味着将数组中的原始数据分配给Pandas DataFrame。如果您修改数组,那么您的DataFrame也将更改:
>>> arr[0, 0] = 1000
>>> df_
x y z
0 1000 2 100
1 2 4 100
2 3 8 100
如您所见,当您更改的第一项时arr,您还修改了df_。
注意:在处理大型数据集时,不复制数据值可以为您节省大量时间和处理能力。
如果这种行为不是您想要的,则应copy=True在DataFrame构造函数中指定。这样,df_将使用from值的副本arr代替实际值来创建。
创建一个熊猫数据帧从文件
您可以将数据和标签从Pandas DataFrame保存并加载到多种文件类型,包括CSV,Excel,SQL,JSON等。这是一个非常强大的功能。
您可以使用以下命令将求职者DataFrame保存到CSV文件中.to_csv():
>>> df.to_csv('data.csv')
上面的语句将产生一个CSV文件名为data.csv在您的工作目录:
,name,city,age,py-score
101,Xavier,Mexico City,41,88.0
102,Ann,Toronto,28,79.0
103,Jana,Prague,33,81.0
104,Yi,Shanghai,34,80.0
105,Robin,Manchester,38,68.0
106,Amal,Cairo,31,61.0
107,Nori,Osaka,37,84.0
现在,您已经有了一个包含数据的CSV文件,可以使用以下命令加载它read_csv():
>>> pd.read_csv('data.csv', index_col=0)
name city age py-score
101 Xavier Mexico City 41 88.0
102 Ann Toronto 28 79.0
103 Jana Prague 33 81.0
104 Yi Shanghai 34 80.0
105 Robin Manchester 38 68.0
106 Amal Cairo 31 61.0
107 Nori Osaka 37 84.0
这就是从文件中获取Pandas DataFrame的方式。在这种情况下,index_col=0指定行标签位于CSV文件的第一列中。
检索标签和数据
创建了DataFrame之后,您就可以开始从中检索信息了。使用熊猫,您可以执行以下操作:
- 检索和修改行和列标签为序列
- 将数据表示为NumPy数组
- 检查并调整数据类型
- 分析
DataFrame对象的大小
熊猫DataFrame标签作为序列
您可以使用来获取DataFrame的行标签,.index并通过来获取其列标签.columns:
>>> df.index
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64')
>>> df.columns
Index(['name', 'city', 'age', 'py-score'], dtype='object')
现在,您将行和列标签作为特殊种类的序列。与其他任何Python序列一样,您可以获得一个项目:
>>> df.columns[1]
'city'
除了提取特定项目外,您还可以应用其他序列操作,包括遍历行或列的标签。但是,这几乎没有必要,因为Pandas提供了其他遍历DataFrames的方法,您将在下一节中看到。
您还可以使用这种方法来修改标签:
>>> df.index = np.arange(10, 17)
>>> df.index
Int64Index([10, 11, 12, 13, 14, 15, 16], dtype='int64')
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
在此示例中,您用于numpy.arange()生成新的行标签序列,其中包含从10到的整数16。要了解更多信息arange(),请查看NumPy arange():如何使用np.arange()。
请记住,如果您尝试修改.index或的特定项,.columns则会得到TypeError。
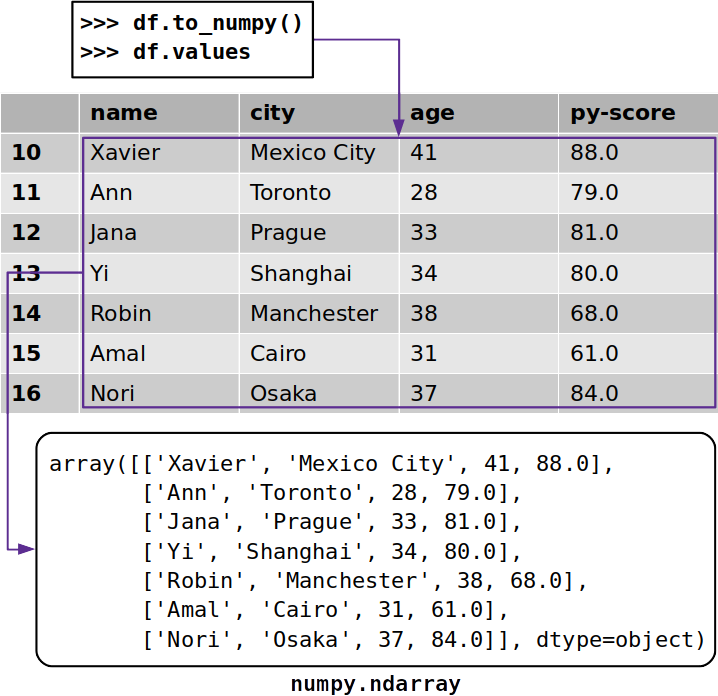
数据NumPy的数组
有时您可能想从没有其标签的Pandas DataFrame中提取数据。要获取带有未标记数据的NumPy数组,可以使用.to_numpy()或.values:
>>> df.to_numpy()
array([['Xavier', 'Mexico City', 41, 88.0],
['Ann', 'Toronto', 28, 79.0],
['Jana', 'Prague', 33, 81.0],
['Yi', 'Shanghai', 34, 80.0],
['Robin', 'Manchester', 38, 68.0],
['Amal', 'Cairo', 31, 61.0],
['Nori', 'Osaka', 37, 84.0]], dtype=object)
无论.to_numpy()与.values工作相似,它们都返回一个与NumPy阵列从熊猫数据帧中的数据:
熊猫文档建议使用,.to_numpy()因为两个可选参数提供了灵活性:
dtype:使用此参数来指定结果数组的数据类型。None默认设置为。copy:False如果要使用DataFrame中的原始数据,请将此参数设置为。True如果要复制数据,请将其设置为。
但是,.values它的存在时间比.to_numpy()熊猫0.20.2版中引入的要长得多。这意味着您可能会.values经常看到,尤其是在较旧的代码中。
数据类型
数据值的类型(也称为数据类型或dtypes)很重要,因为它们确定了DataFrame使用的内存量以及其计算速度和精度级别。
熊猫严重依赖NumPy数据类型。但是,Pandas 1.0引入了一些其他类型:
BooleanDtype并BooleanArray支持缺少的布尔值和Kleene三值逻辑。StringDtype并StringArray代表专用的字符串类型。
您可以使用以下命令获取Pandas DataFrame每一列的数据类型.dtypes:
>>> df.dtypes
name object
city object
age int64
py-score float64
dtype: object
如您所见,.dtypes返回一个Series对象,该对象的列名称为标签,而相应的数据类型为值。
如果要修改一个或多个列的数据类型,则可以使用.astype():
>>> df_ = df.astype(dtype={'age': np.int32, 'py-score': np.float32})
>>> df_.dtypes
name object
city object
age int32
py-score float32
dtype: object
的最重要也是唯一的必需参数.astype()是dtype。它需要一个数据类型或字典。如果您通过字典,则键为列名,值为所需的对应数据类型。
如您所见,列age和py-scoreDataFramedf中的数据类型均为int64,它们表示64位(或8字节)整数。但是,df_还提供了一个较小的32位(4字节)整数数据类型,称为int32。
熊猫数据帧大小
属性.ndim,.size和分别.shape返回维度数,每个维度的数据值数和数据值的总数:
>>> df_.ndim
2
>>> df_.shape
(7, 4)
>>> df_.size
28
DataFrame实例具有二维(行和列),因此.ndimreturn 2。一个Series对象,而另一方面,只有一个尺寸,所以在这种情况下,.ndim将返回1。
该.shape属性返回具有行数(在本例中为7)和列数(为4)的元组。最后,.size返回一个等于DataFrame(28)中值个数的整数。
您甚至可以使用以下命令检查每列使用的内存量.memory_usage():
>>> df_.memory_usage()
Index 56
name 56
city 56
age 28
py-score 28
dtype: int64
如您所见,.memory_usage()返回一个Series,列名称为标签,内存使用量以字节为数据值。如果要排除保存行标签的列的内存使用量,请传递可选参数index=False。
在上面的示例中,最后两列age和分别py-score使用28个字节的内存。这是因为这些列有七个值,每个值都是一个整数,占用32位或4个字节。七个整数乘以每个4字节等于总共28个字节的内存使用量。
访问和修改数据
您已经学习了如何将Pandas DataFrame的特定行或列作为Series对象:
>>> df['name']
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
>>> df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: object
在第一个示例中,使用列name的标签作为键,就像访问字典中的元素一样访问列。如果列标签是有效的Python标识符,则还可以使用点符号来访问列。在第二个示例中,您使用.loc[]其标签来获取行10。
获取数据随着访问者
除了.loc[]可以通过标签获取行或列的访问器之外.iloc[],Pandas还提供了访问器,该访问器通过其整数索引检索行或列。在大多数情况下,您可以使用以下两种方法之一:
>>> df.loc[10]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: object
>>> df.iloc[0]
name Xavier
city Mexico City
age 41
py-score 88
Name: 10, dtype: object
df.loc[10]返回带有标签的行10。同样,df.iloc[0]返回具有从零开始的索引0的行,即第一行。如您所见,两个语句都返回与Series对象相同的行。
熊猫共有四个访问器:
-
.loc[]接受行和列的标签,并返回Series或DataFrames。您可以使用它来获取整个行或列及其部分。 -
.iloc[]接受行和列的从零开始的索引,并返回Series或DataFrames。您可以使用它来获取整个行或列或其部分。 -
.at[]接受行和列的标签并返回单个数据值。 -
.iat[]接受行和列的从零开始的索引,并返回一个数据值。
其中,.loc[]并且.iloc[]特别强大。它们支持切片和NumPy样式索引。您可以使用它们来访问列:
>>> df.loc[:, 'city']
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
>>> df.iloc[:, 1]
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
df.loc[:, 'city']返回列city。行标签位置中的slice构造(:)表示应包括所有行。df.iloc[:, 1]返回同一列,因为从零开始的索引1引用第二列city。
就像使用NumPy一样,您可以提供切片以及列表或数组而不是索引来获取多行或多列:
>>> df.loc[11:15, ['name', 'city']]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal Cairo
>>> df.iloc[1:6, [0, 1]]
name city
11 Ann Toronto
12 Jana Prague
13 Yi Shanghai
14 Robin Manchester
15 Amal Cairo
在此示例中,您使用:
- 切片与标签获得的行
11通过15,相当于给指数1通过5 - 用于获取
name和的列的列表city,它们等效于索引0和1
这两个语句都返回一个Pandas DataFrame,其中有所需的五行和两列的交集。
这带来了.loc[]和之间非常重要的区别.iloc[]。你可以从前面的例子中看到的,当你通过行标签11:15来.loc[],你得到的行11通过15。但是,当你通过行索引1:6到.iloc[],你只与指数获得的行1通过5。
你只能得到指数的原因1通过5是,随着.iloc[]中,停止索引片是独家,这意味着它从返回的值排除。这与Python序列和NumPy数组一致。.loc[]但是,使用时,开始索引和停止索引都包含在内,这意味着它们包含在返回值中。
您可以使用.iloc[]与切片元组,列表和NumPy数组相同的方式跳过行和列:
>>> df.iloc[1:6:2, 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
在此示例中,您可以使用slice指定所需的行索引1:6:2。这意味着您将从具有索引1的行(第二行)开始,在具有索引的行6(第七行)之前停止,然后跳过第二行。
除了使用切片构造,还可以使用内置的Python类slice()以及numpy.s_[]或pd.IndexSlice[]:
>>> df.iloc[slice(1, 6, 2), 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
>>> df.iloc[np.s_[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
>>> df.iloc[pd.IndexSlice[1:6:2], 0]
11 Ann
13 Yi
15 Amal
Name: name, dtype: object
根据您的情况,您可能会发现其中一种方法比其他方法更方便。
可以使用.loc[]和.iloc[]获取特定的数据值。但是,当您只需要一个值时,Pandas建议使用专用的访问器.at[]和.iat[]:
>>> df.at[12, 'name']
'Jana'
>>> df.iat[2, 0]
'Jana'
在这里,您曾经.at[]使用其对应的列和行标签来获取单个候选者的名称。您还曾经.iat[]使用其列和行索引来检索相同的名称。
设定数据存取器
您可以使用访问器通过传递Python序列,NumPy数组或单个值来修改Pandas DataFrame的部分:
>>> df.loc[:, 'py-score']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
>>> df.loc[:13, 'py-score'] = [40, 50, 60, 70]
>>> df.loc[14:, 'py-score'] = 0
>>> df['py-score']
10 40.0
11 50.0
12 60.0
13 70.0
14 0.0
15 0.0
16 0.0
Name: py-score, dtype: float64
该语句使用提供的列表中的值df.loc[:13, 'py-score'] = [40, 50, 60, 70]修改列中的前四项(行10至13)py-score。使用df.loc[14:, 'py-score'] = 0将此列中的剩余值设置为0。
下面的示例说明您可以使用负索引.iloc[]来访问或修改数据:
>>> df.iloc[:, -1] = np.array([88.0, 79.0, 81.0, 80.0, 68.0, 61.0, 84.0])
>>> df['py-score']
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
在此示例中,您访问并修改了最后一列('py-score'),它对应于整数列index -1。此行为与Python序列和NumPy数组一致。
插入和删除数据
熊猫提供了几种方便的技术来插入和删除行或列。您可以根据自己的情况和需求进行选择。
插入和删除行
假设您想将一个新人添加到您的求职者列表中。您可以从创建一个Series代表该新候选对象的新对象开始:
>>> john = pd.Series(data=['John', 'Boston', 34, 79],
... index=df.columns, name=17)
>>> john
name John
city Boston
age 34
py-score 79
Name: 17, dtype: object
>>> john.name
17
新对象的标签与中的列标签相对应df。这就是您需要的原因index=df.columns。
您可以添加john一个新行的末尾df有.append():
>>> df = df.append(john)
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
17 John Boston 34 79.0
在此,.append()返回带有新行的Pandas DataFrame。请注意,Pandas如何使用属性john.namevalue17来为新行指定标签。
您已经添加了一个新行,其中包含一次调用.append(),您可以通过一个调用将其删除.drop():
>>> df = df.drop(labels=[17])
>>> df
name city age py-score
10 Xavier Mexico City 41 88.0
11 Ann Toronto 28 79.0
12 Jana Prague 33 81.0
13 Yi Shanghai 34 80.0
14 Robin Manchester 38 68.0
15 Amal Cairo 31 61.0
16 Nori Osaka 37 84.0
在此,.drop()删除使用参数指定的行labels。默认情况下,它将返回已删除指定行的Pandas DataFrame。如果通过inplace=True,则原始DataFrame将被修改,您将获得None作为返回值。
插入和删除列
在Pandas DataFrame中插入列的最直接方法是遵循将项目添加到字典时所使用的相同过程。您可以按照以下方法在JavaScript测试中添加一列包含考生分数的列:
>>> df['js-score'] = np.array([71.0, 95.0, 88.0, 79.0, 91.0, 91.0, 80.0])
>>> df
name city age py-score js-score
10 Xavier Mexico City 41 88.0 71.0
11 Ann Toronto 28 79.0 95.0
12 Jana Prague 33 81.0 88.0
13 Yi Shanghai 34 80.0 79.0
14 Robin Manchester 38 68.0 91.0
15 Amal Cairo 31 61.0 91.0
16 Nori Osaka 37 84.0 80.0
现在,原始DataFramejs-score在其末尾还有一列。
您不必提供完整的值序列。您可以添加具有单个值的新列:
>>> df['total-score'] = 0.0
>>> df
name city age py-score js-score total-score
10 Xavier Mexico City 41 88.0 71.0 0.0
11 Ann Toronto 28 79.0 95.0 0.0
12 Jana Prague 33 81.0 88.0 0.0
13 Yi Shanghai 34 80.0 79.0 0.0
14 Robin Manchester 38 68.0 91.0 0.0
15 Amal Cairo 31 61.0 91.0 0.0
16 Nori Osaka 37 84.0 80.0 0.0
df现在,DataFrame的附加列填充了零。
如果您过去使用过字典,那么您可能会熟悉这种插入列的方式。但是,它不允许您指定新列的位置。如果新列的位置很重要,则可以.insert()改用:
>>> df.insert(loc=4, column='django-score',
... value=np.array([86.0, 81.0, 78.0, 88.0, 74.0, 70.0, 81.0]))
>>> df
name city age py-score django-score js-score total-score
10 Xavier Mexico City 41 88.0 86.0 71.0 0.0
11 Ann Toronto 28 79.0 81.0 95.0 0.0
12 Jana Prague 33 81.0 78.0 88.0 0.0
13 Yi Shanghai 34 80.0 88.0 79.0 0.0
14 Robin Manchester 38 68.0 74.0 91.0 0.0
15 Amal Cairo 31 61.0 70.0 91.0 0.0
16 Nori Osaka 37 84.0 81.0 80.0 0.0
您刚刚插入了另一列带有Django测试成绩的列。该参数loc确定Pandas DataFrame中新列的位置或从零开始的索引。column设置新列的标签,并value指定要插入的数据值。
您可以像使用常规Python词典那样从Pandas DataFrame中删除一个或多个列,方法是使用以下del语句:
>>> del df['total-score']
>>> df
name city age py-score django-score js-score
10 Xavier Mexico City 41 88.0 86.0 71.0
11 Ann Toronto 28 79.0 81.0 95.0
12 Jana Prague 33 81.0 78.0 88.0
13 Yi Shanghai 34 80.0 88.0 79.0
14 Robin Manchester 38 68.0 74.0 91.0
15 Amal Cairo 31 61.0 70.0 91.0
16 Nori Osaka 37 84.0 81.0 80.0
现在您df没有专栏了total-score。与字典的另一个相似之处是使用的能力.pop(),它可以删除指定的列并返回它。这意味着您可以执行类似的操作df.pop('total-score')而不是使用del。
您也可以.drop()像以前处理行那样删除一个或多个列。同样,您需要使用来指定所需列的标签labels。另外,当您要删除列时,需要提供参数axis=1:
>>> df = df.drop(labels='age', axis=1)
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
您已从ageDataFrame中删除了该列。
默认情况下,.drop()除非您通过,否则返回不包含指定列的DataFrame inplace=True。
运用算术运算
您可以像使用NumPy数组一样,对熊猫Series和DataFrame对象应用基本的算术运算,例如加,减,乘和除。
>>> df['py-score'] + df['js-score']
10 159.0
11 174.0
12 169.0
13 159.0
14 159.0
15 152.0
16 164.0
dtype: float64
>>> df['py-score'] / 100
10 0.88
11 0.79
12 0.81
13 0.80
14 0.68
15 0.61
16 0.84
Name: py-score, dtype: float64
您可以使用此技术在Pandas DataFrame中插入新列。例如,尝试将total分数计算为候选人的Python,Django和JavaScript分数的线性组合:
>>> df['total'] =\
... 0.4 * df['py-score'] + 0.3 * df['django-score'] + 0.3 * df['js-score']
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
现在,您的DataFrame中有一个列,该列的total分数是根据考生的个人考试成绩计算得出的。更好的是,您仅需一个语句就可以实现这一目标!
应用与NumPy和SciPy的功能
大多数NumPy和SciPy例程可以作为参数而不是作为NumPy数组应用于熊猫Series或DataFrame对象。为了说明这一点,您可以使用NumPy例程计算候选人的总考试成绩numpy.average()。
无需将NumPy数组传递给numpy.average(),而是传递Pandas DataFrame的一部分:
>>> import numpy as np
>>> score = df.iloc[:, 2:5]
>>> score
py-score django-score js-score
10 88.0 86.0 71.0
11 79.0 81.0 95.0
12 81.0 78.0 88.0
13 80.0 88.0 79.0
14 68.0 74.0 91.0
15 61.0 70.0 91.0
16 84.0 81.0 80.0
>>> np.average(score, axis=1,
... weights=[0.4, 0.3, 0.3])
array([82.3, 84.4, 82.2, 82.1, 76.7, 72.7, 81.9])
score现在,该变量引用具有Python,Django和JavaScript得分的DataFrame。您可以将score用作指定参数numpy.average()的列,并获得具有指定权重的列的线性组合。
但这还不是全部!您可以将返回的NumPy数组average()用作的新列df。首先,total从中删除现有列df,然后使用添加新列average():
>>> del df['total']
>>> df
name city py-score django-score js-score
10 Xavier Mexico City 88.0 86.0 71.0
11 Ann Toronto 79.0 81.0 95.0
12 Jana Prague 81.0 78.0 88.0
13 Yi Shanghai 80.0 88.0 79.0
14 Robin Manchester 68.0 74.0 91.0
15 Amal Cairo 61.0 70.0 91.0
16 Nori Osaka 84.0 81.0 80.0
>>> df['total'] = np.average(df.iloc[:, 2:5], axis=1,
... weights=[0.4, 0.3, 0.3])
>>> df
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
16 Nori Osaka 84.0 81.0 80.0 81.9
结果与前面的示例相同,但是在这里您使用了现有的NumPy函数,而不是编写自己的代码。
分选熊猫数据帧
您可以使用以下命令对Pandas DataFrame进行排序.sort_values():
>>> df.sort_values(by='js-score', ascending=False)
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9
13 Yi Shanghai 80.0 88.0 79.0 82.1
10 Xavier Mexico City 88.0 86.0 71.0 82.3
本示例通过column中的值对DataFrame进行排序js-score。该参数by设置要作为排序依据的行或列的标签。ascending指定是按升序(True)还是降序(False)排序,后一种是默认设置。您可以通过axis选择是否要对行(axis=0)或列(axis=1)进行排序。
如果要按多列排序,则只需将列表作为by和的参数传递ascending:
>>> df.sort_values(by=['total', 'py-score'], ascending=[False, False])
name city py-score django-score js-score total
11 Ann Toronto 79.0 81.0 95.0 84.4
10 Xavier Mexico City 88.0 86.0 71.0 82.3
12 Jana Prague 81.0 78.0 88.0 82.2
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
14 Robin Manchester 68.0 74.0 91.0 76.7
15 Amal Cairo 61.0 70.0 91.0 72.7
在这种情况下,DataFrame按列排序total,但是如果两个值相同,则它们的顺序由column中的值确定py-score。
可选参数inplace也可以与一起使用.sort_values()。False默认情况下设置为,以确保.sort_values()返回新的Pandas DataFrame。设置后inplace=True,现有的DataFrame将被修改并.sort_values()返回None。
如果您曾经尝试在Excel中对值进行排序,那么您可能会发现Pandas方法更加有效和便捷。当您拥有大量数据时,Pandas可以大大胜过Excel。
过滤数据
数据过滤是Pandas的另一个强大功能。它的工作方式类似于在NumPy中使用布尔数组建立索引。
如果对某个Series对象应用某些逻辑运算,则将获得另一个具有Boolean值True和的Series False:
>>> filter_ = df['django-score'] >= 80
>>> filter_
10 True
11 True
12 False
13 True
14 False
15 False
16 True
Name: django-score, dtype: bool
在这种情况下,df['django-score'] >= 80返回TrueDjango得分大于或等于80的那些行。返回FalseDjango得分小于80的那些行。
现在,您已filter_用布尔数据填充了系列。该表达式df[filter_]返回一个Pandas DataFrame,其中的行df对应于Truein filter_:
>>> df[filter_]
name city py-score django-score js-score total
10 Xavier Mexico City 88.0 86.0 71.0 82.3
11 Ann Toronto 79.0 81.0 95.0 84.4
13 Yi Shanghai 80.0 88.0 79.0 82.1
16 Nori Osaka 84.0 81.0 80.0 81.9
正如你所看到的,filter_[10],filter_[11],filter_[13],和filter_[16]都是True,所以df[filter_]包含这些标签的行。在另一方面,filter_[12],filter_[14],和filter_[15]是False的,所以相应的行不会出现在df[filter_]。
通过将逻辑运算与以下运算符结合在一起,可以创建功能强大且复杂的表达式:
NOT(~)AND(&)OR(|)XOR(^)
例如,你可以用它的候选人一个数据帧py-score和js-score是大于或等于80:
>>> df[(df['py-score'] >= 80) & (df['js-score'] >= 80)]
name city py-score django-score js-score total
12 Jana Prague 81.0 78.0 88.0 82.2
16 Nori Osaka 84.0 81.0 80.0 81.9
该表达式(df['py-score'] >= 80) & (df['js-score'] >= 80)返回一个Series,True在和的行中,两个py-score和js-score均大于或等于80,False在其他行中。在这种情况下,只有带有标签的行12同时16满足这两个条件。
您也可以应用NumPy逻辑例程而不是运算符。
对于某些需要数据过滤的操作,使用起来更加方便.where()。它替换不满足所提供条件的位置中的值:
>>> df['django-score'].where(cond=df['django-score'] >= 80, other=0.0)
10 86.0
11 81.0
12 0.0
13 88.0
14 0.0
15 0.0
16 81.0
Name: django-score, dtype: float64
在此示例中,条件为df['django-score'] >= 80。.where()在条件为的情况下,调用的DataFrame或Series的值将保持不变,并且在条件为的情况下True将被other(在这种情况下0.0)的值替换False。
确定数据统计
熊猫为DataFrame提供了许多统计方法。您可以使用以下命令获取Pandas DataFrame的数字列的基本统计信息.describe():
>>> df.describe()
py-score django-score js-score total
count 7.000000 7.000000 7.000000 7.000000
mean 77.285714 79.714286 85.000000 80.328571
std 9.446592 6.343350 8.544004 4.101510
min 61.000000 70.000000 71.000000 72.700000
25% 73.500000 76.000000 79.500000 79.300000
50% 80.000000 81.000000 88.000000 82.100000
75% 82.500000 83.500000 91.000000 82.250000
max 88.000000 88.000000 95.000000 84.400000
在这里,.describe()返回一个新的DataFrame,其中包含以表示的行数,以及列count的均值,标准差,最小值,最大值和四分位数。
如果要获取某些或全部列的特定统计信息,则可以调用诸如.mean()或的方法.std():
>>> df.mean()
py-score 77.285714
django-score 79.714286
js-score 85.000000
total 80.328571
dtype: float64
>>> df['py-score'].mean()
77.28571428571429
>>> df.std()
py-score 9.446592
django-score 6.343350
js-score 8.544004
total 4.101510
dtype: float64
>>> df['py-score'].std()
9.446591726019244
当应用于Pandas DataFrame时,这些方法将返回Series以及每一列的结果。当施加到一个Series对象,或者一个数据帧的单个列中,该方法返回标量。
要了解有关使用Pandas进行统计计算的更多信息,请查看Python和NumPy,SciPy和Pandas的描述性统计数据:与Python的相关性。
处理缺少数据
数据丢失在数据科学和机器学习中非常普遍。但是不要害怕!熊猫具有非常强大的功能,可以处理丢失的数据。实际上,其文档中有一整节致力于处理丢失的数据。
熊猫通常用NaN(不是数字)值表示丢失的数据。在Python中,你可以得到NaN的float('nan'),math.nan或numpy.nan。与熊猫1.0开始,新类型的喜欢BooleanDtype,Int8Dtype,Int16Dtype,Int32Dtype,和Int64Dtype使用pandas.NA作为一个缺失值。
这是一个缺少值的Pandas DataFrame的示例:
>>> df_ = pd.DataFrame({'x': [1, 2, np.nan, 4]})
>>> df_
x
0 1.0
1 2.0
2 NaN
3 4.0
该变量df_引用具有一列,x四个值的DataFrame 。nan默认情况下,第三个值是并且被认为丢失。
计算与数据缺失
nan除非明确指示不要执行以下操作,否则许多Pandas方法会在执行计算时忽略值:
>>> df_.mean()
x 2.333333
dtype: float64
>>> df_.mean(skipna=False)
x NaN
dtype: float64
在第一个示例中,df_.mean()计算平均值时不考虑NaN(第三个值)。它只是需要1.0,2.0以及4.0返回他们的平均水平,这是2.33。
但是,如果您指示.mean()不要使用跳过nan值skipna=False,则它将考虑它们并nan在数据中是否缺少任何值的情况下返回。
填补缺失数据
熊猫有几种选择,可以用其他值填充或替换缺失的值。最方便的方法之一是.fillna()。您可以使用它来替换缺少的值:
- 规定值
- 缺失值以上的值
- 缺失值以下的值
这是您如何应用上述选项的方法:
>>> df_.fillna(value=0)
x
0 1.0
1 2.0
2 0.0
3 4.0
>>> df_.fillna(method='ffill')
x
0 1.0
1 2.0
2 2.0
3 4.0
>>> df_.fillna(method='bfill')
x
0 1.0
1 2.0
2 4.0
3 4.0
在第一个示例中,.fillna(value=0)将缺失的值替换为,将0.0其指定为value。在第二个示例中,.fillna(method='ffill')将缺失值替换为它上面的值2.0。在第三个示例中,.fillna(method='bfill')使用小于缺失值的值4.0。
另一个流行的选择是应用插值,并用插值替换缺失值。您可以使用.interpolate():
>>> df_.interpolate()
x
0 1.0
1 2.0
2 3.0
3 4.0
如您所见,.interpolate()用内插值替换缺少的值。
您还可以将可选参数inplace与一起使用.fillna()。这样做将:
- 在以下情况下创建并返回一个新的DataFrame
inplace=False - 修改现有的数据框和返回
None时inplace=True
的默认设置inplace是False。但是,inplace=True当您处理大量数据并希望避免不必要和低效的复制时,此功能非常有用。
删除缺少数据的行和列
在某些情况下,您可能要删除缺少值的行甚至列。您可以使用.dropna():
>>> df_.dropna()
x
0 1.0
1 2.0
3 4.0
在这种情况下,.dropna()只需删除带有的行nan,包括其标签。它还具有可选参数inplace,其行为与.fillna()和相同.interpolate()。
遍历Pandas DataFrame
如前所述,可以使用.index和检索DataFrame的行和列标签作为序列.columns。您可以使用此功能遍历标签并获取或设置数据值。但是,Pandas提供了几种更方便的迭代方法:
.items()遍历列.iteritems()遍历列.iterrows()遍历行.itertuples()遍历行并获取命名元组
使用.items()和.iteritems(),您可以遍历Pandas DataFrame的列。每次迭代都会产生一个以列名称和列数据为Series对象的元组:
>>> for col_label, col in df.iteritems():
... print(col_label, col, sep='\n', end='\n\n')
...
name
10 Xavier
11 Ann
12 Jana
13 Yi
14 Robin
15 Amal
16 Nori
Name: name, dtype: object
city
10 Mexico City
11 Toronto
12 Prague
13 Shanghai
14 Manchester
15 Cairo
16 Osaka
Name: city, dtype: object
py-score
10 88.0
11 79.0
12 81.0
13 80.0
14 68.0
15 61.0
16 84.0
Name: py-score, dtype: float64
django-score
10 86.0
11 81.0
12 78.0
13 88.0
14 74.0
15 70.0
16 81.0
Name: django-score, dtype: float64
js-score
10 71.0
11 95.0
12 88.0
13 79.0
14 91.0
15 91.0
16 80.0
Name: js-score, dtype: float64
total
10 82.3
11 84.4
12 82.2
13 82.1
14 76.7
15 72.7
16 81.9
Name: total, dtype: float64
这就是您使用.items()和的方式.iteritems()。
使用.iterrows(),您可以遍历Pandas DataFrame的行。每次迭代都会生成一个以行名和行数据为Series对象的元组:
>>> for row_label, row in df.iterrows():
... print(row_label, row, sep='\n', end='\n\n')
...
10
name Xavier
city Mexico City
py-score 88
django-score 86
js-score 71
total 82.3
Name: 10, dtype: object
11
name Ann
city Toronto
py-score 79
django-score 81
js-score 95
total 84.4
Name: 11, dtype: object
12
name Jana
city Prague
py-score 81
django-score 78
js-score 88
total 82.2
Name: 12, dtype: object
13
name Yi
city Shanghai
py-score 80
django-score 88
js-score 79
total 82.1
Name: 13, dtype: object
14
name Robin
city Manchester
py-score 68
django-score 74
js-score 91
total 76.7
Name: 14, dtype: object
15
name Amal
city Cairo
py-score 61
django-score 70
js-score 91
total 72.7
Name: 15, dtype: object
16
name Nori
city Osaka
py-score 84
django-score 81
js-score 80
total 81.9
Name: 16, dtype: object
这就是您使用的方式.iterrows()。
类似地,.itertuples()对行进行迭代,并在每次迭代中产生一个带有(可选)索引和数据的命名元组:
>>> for row in df.loc[:, ['name', 'city', 'total']].itertuples():
... print(row)
...
Pandas(Index=10, name='Xavier', city='Mexico City', total=82.3)
Pandas(Index=11, name='Ann', city='Toronto', total=84.4)
Pandas(Index=12, name='Jana', city='Prague', total=82.19999999999999)
Pandas(Index=13, name='Yi', city='Shanghai', total=82.1)
Pandas(Index=14, name='Robin', city='Manchester', total=76.7)
Pandas(Index=15, name='Amal', city='Cairo', total=72.7)
Pandas(Index=16, name='Nori', city='Osaka', total=81.9)
您可以使用参数指定命名元组的名称,该参数默认name设置为'Pandas'。您还可以指定是否使用包含行标签index,True默认情况下设置为。
工作时间序列
熊猫擅长处理时间序列。尽管此功能部分基于NumPy日期时间和timedelta,但Pandas提供了更大的灵活性。
创建DataFrames以时间系列标签
在本节中,您将使用一天中的每小时温度数据创建一个Pandas DataFrame。
您可以先创建一个包含数据值的列表(或元组,NumPy数组或其他数据类型),该值将是每小时温度,单位为摄氏度:
>>> temp_c = [ 8.0, 7.1, 6.8, 6.4, 6.0, 5.4, 4.8, 5.0,
... 9.1, 12.8, 15.3, 19.1, 21.2, 22.1, 22.4, 23.1,
... 21.0, 17.9, 15.5, 14.4, 11.9, 11.0, 10.2, 9.1]
现在,您有了变量temp_c,它引用温度值列表。
下一步是创建日期和时间序列。熊猫date_range()为此提供了非常方便的功能:
>>> dt = pd.date_range(start='2019-10-27 00:00:00.0', periods=24,
... freq='H')
>>> dt
DatetimeIndex(['2019-10-27 00:00:00', '2019-10-27 01:00:00',
'2019-10-27 02:00:00', '2019-10-27 03:00:00',
'2019-10-27 04:00:00', '2019-10-27 05:00:00',
'2019-10-27 06:00:00', '2019-10-27 07:00:00',
'2019-10-27 08:00:00', '2019-10-27 09:00:00',
'2019-10-27 10:00:00', '2019-10-27 11:00:00',
'2019-10-27 12:00:00', '2019-10-27 13:00:00',
'2019-10-27 14:00:00', '2019-10-27 15:00:00',
'2019-10-27 16:00:00', '2019-10-27 17:00:00',
'2019-10-27 18:00:00', '2019-10-27 19:00:00',
'2019-10-27 20:00:00', '2019-10-27 21:00:00',
'2019-10-27 22:00:00', '2019-10-27 23:00:00'],
dtype='datetime64[ns]', freq='H')
date_range()接受用于指定范围的开始或结束,周期数,频率,时区等的参数。
注意:尽管其他选项可用,但熊猫默认情况下大多使用ISO 8601日期和时间格式。
有了温度值以及相应的日期和时间后,就可以创建DataFrame了。在许多情况下,将日期时间值用作行标签很方便:
>>> temp = pd.DataFrame(data={'temp_c': temp_c}, index=dt)
>>> temp
temp_c
2019-10-27 00:00:00 8.0
2019-10-27 01:00:00 7.1
2019-10-27 02:00:00 6.8
2019-10-27 03:00:00 6.4
2019-10-27 04:00:00 6.0
2019-10-27 05:00:00 5.4
2019-10-27 06:00:00 4.8
2019-10-27 07:00:00 5.0
2019-10-27 08:00:00 9.1
2019-10-27 09:00:00 12.8
2019-10-27 10:00:00 15.3
2019-10-27 11:00:00 19.1
2019-10-27 12:00:00 21.2
2019-10-27 13:00:00 22.1
2019-10-27 14:00:00 22.4
2019-10-27 15:00:00 23.1
2019-10-27 16:00:00 21.0
2019-10-27 17:00:00 17.9
2019-10-27 18:00:00 15.5
2019-10-27 19:00:00 14.4
2019-10-27 20:00:00 11.9
2019-10-27 21:00:00 11.0
2019-10-27 22:00:00 10.2
2019-10-27 23:00:00 9.1
而已!您已经创建了一个具有时间序列数据和日期时间行索引的DataFrame。
索引和切片
一旦有了带有时间序列数据的Pandas DataFrame,就可以方便地应用切片以仅获取部分信息:
>>> temp['2019-10-27 05':'2019-10-27 14']
temp_c
2019-10-27 05:00:00 5.4
2019-10-27 06:00:00 4.8
2019-10-27 07:00:00 5.0
2019-10-27 08:00:00 9.1
2019-10-27 09:00:00 12.8
2019-10-27 10:00:00 15.3
2019-10-27 11:00:00 19.1
2019-10-27 12:00:00 21.2
2019-10-27 13:00:00 22.1
2019-10-27 14:00:00 22.4
此示例显示了如何提取05:00和14:00(凌晨5点和下午2点)之间的温度。尽管已提供了字符串,但Pandas知道行标签是日期时间值,并将字符串解释为日期和时间。
重采样和滚动
您已经了解了如何组合日期时间行标签并使用切片从时间序列数据中获取所需的信息。这仅仅是开始。它变得更好了!
如果您想将一天分成四个六个小时的间隔,并获取每个间隔的平均温度,那么您仅需声明一个即可。熊猫提供了方法.resample(),您可以将其与其他方法结合使用,例如.mean():
>>> temp.resample(rule='6h').mean()
temp_c
2019-10-27 00:00:00 6.616667
2019-10-27 06:00:00 11.016667
2019-10-27 12:00:00 21.283333
2019-10-27 18:00:00 12.016667
现在,您将拥有一个新的带有四行的Pandas DataFrame。每行对应一个六个小时的间隔。例如,该值为数据6.616667帧中前六个温度的平均值temp,而12.016667为后六个温度的平均值。
代替.mean(),您可以应用.min()或.max()获取每个时间间隔的最低和最高温度。您也可以使用.sum()来获取数据值的总和,尽管在使用温度时此信息可能没有用。
您可能还需要做一些滚动窗口分析。这涉及到计算指定数量的相邻行的统计信息,这些相邻行构成了数据窗口。您可以通过选择一组不同的相邻行来“滚动”窗口以执行计算。
您的第一个窗口从DataFrame中的第一行开始,并包含您指定的任意多相邻行。然后,将窗口向下移动一行,拖放第一行,然后添加紧接在最后一行之后的行,然后再次计算相同的统计信息。您重复此过程,直到到达DataFrame的最后一行。
熊猫.rolling()为此提供了一种方法:
>>> temp.rolling(window=3).mean()
temp_c
2019-10-27 00:00:00 NaN
2019-10-27 01:00:00 NaN
2019-10-27 02:00:00 7.300000
2019-10-27 03:00:00 6.766667
2019-10-27 04:00:00 6.400000
2019-10-27 05:00:00 5.933333
2019-10-27 06:00:00 5.400000
2019-10-27 07:00:00 5.066667
2019-10-27 08:00:00 6.300000
2019-10-27 09:00:00 8.966667
2019-10-27 10:00:00 12.400000
2019-10-27 11:00:00 15.733333
2019-10-27 12:00:00 18.533333
2019-10-27 13:00:00 20.800000
2019-10-27 14:00:00 21.900000
2019-10-27 15:00:00 22.533333
2019-10-27 16:00:00 22.166667
2019-10-27 17:00:00 20.666667
2019-10-27 18:00:00 18.133333
2019-10-27 19:00:00 15.933333
2019-10-27 20:00:00 13.933333
2019-10-27 21:00:00 12.433333
2019-10-27 22:00:00 11.033333
2019-10-27 23:00:00 10.100000
现在,您有了一个DataFrame,其平均温度针对几个三个小时的窗口计算。该参数window指定移动时间窗口的大小。
在上面的例子中,第三值(7.3)是用于最初三小时的平均温度(00:00:00,01:00:00,和02:00:00)。第四值是小时的平均温度02:00:00,03:00:00和04:00:00。最后一个值是最后三个小时,平均温度21:00:00,22:00:00和23:00:00。缺少前两个值,因为没有足够的数据来计算它们。
绘制随着熊猫DataFrames
熊猫允许您可视化数据或基于DataFrames创建图。它在后台使用Matplotlib,因此利用Pandas的绘图功能与使用Matplotlib非常相似。
如果要显示图,则首先需要导入matplotlib.pyplot:
>>> import matplotlib.pyplot as plt
现在,您可以pandas.DataFrame.plot()用来创建图并plt.show()显示它:
>>> temp.plot()
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070cd9d950>
>>> plt.show()
现在.plot()返回一个plot看起来像这样的对象:
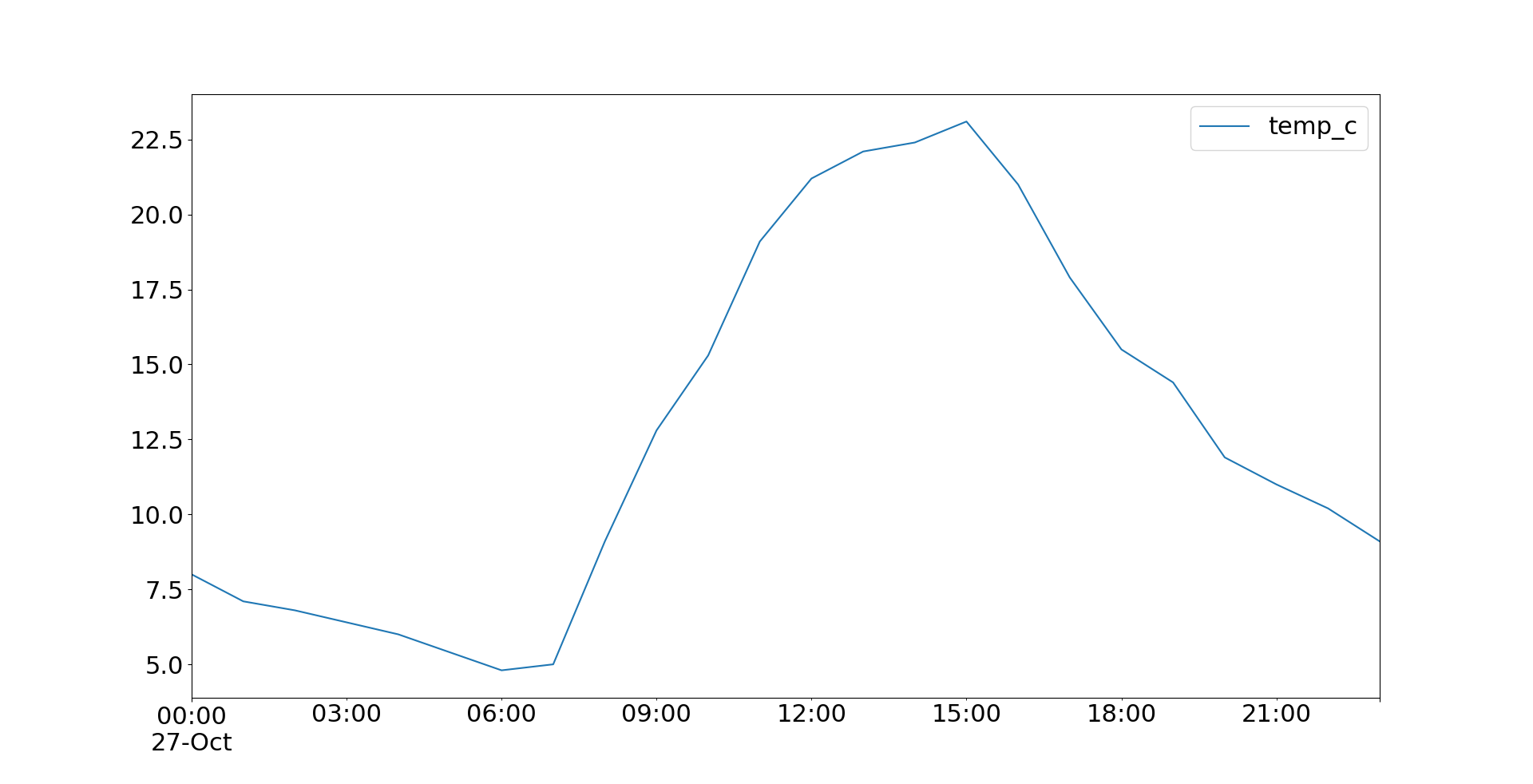
您也可以申请.plot.line()并获得相同的结果。双方.plot()并.plot.line()有很多可选参数,你可以用它来指定地块的外观。其中一些直接传递给底层的Matplotlib方法。
您可以通过链接方法.get_figure()和来保存您的身材.savefig():
>>> temp.plot().get_figure().savefig('temperatures.png')
该语句创建绘图并将其另存为'temperatures.png'工作目录中的文件。
您可以使用Pandas DataFrame获得其他类型的图。例如,你可以从之前想像你的求职者数据作为直方图有.plot.hist():
>>> df.loc[:, ['py-score', 'total']].plot.hist(bins=5, alpha=0.4)
<matplotlib.axes._subplots.AxesSubplot object at 0x7f070c69edd0>
>>> plt.show()
在此示例中,您将提取Python测试成绩和总成绩数据,并使用直方图将其可视化。结果图如下:
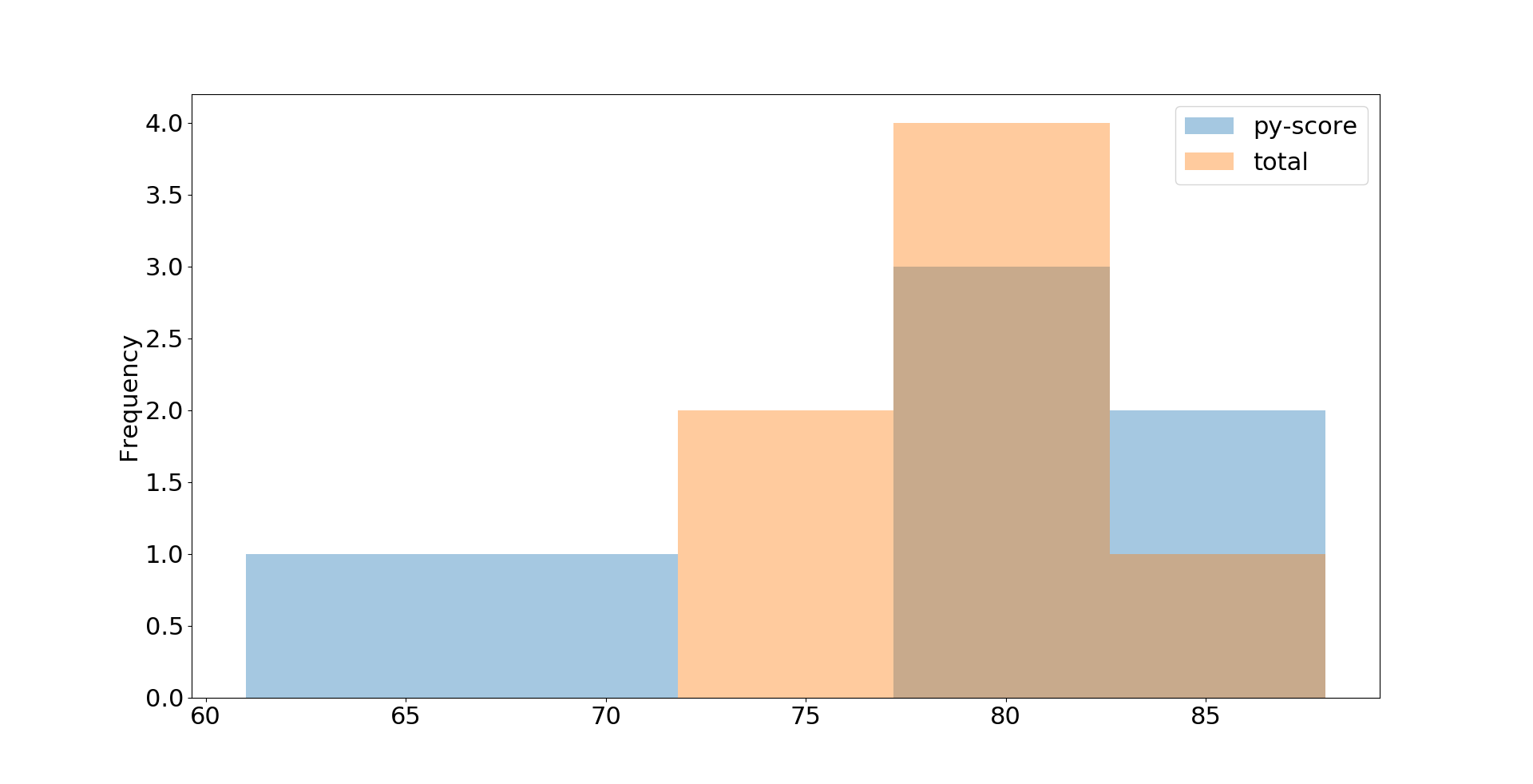
这只是基本外观。您可以使用.plot.hist(),Matplotlibplt.rcParams以及其他许多可选参数来调整细节。您可以在《Matplotlib的解剖》中找到详细的说明。
延伸阅读
Pandas DataFrame是非常全面的对象,支持本教程中未提及的许多操作。其中一些包括:
该官员大熊猫教程总结了一些很好的可用选项。如果您想了解有关Pandas和DataFrames的更多信息,那么可以查看以下教程:
- 使用Pandas和NumPy进行Pythonic数据清理
- 熊猫数据框101
- 熊猫和文森特简介
- Python熊猫:您可能不知道的技巧和功能
- 惯用的熊猫:您可能不知道的技巧和功能
- 用熊猫读取CSV
- 用熊猫写CSV
- 用Python读写CSV文件
- 读写CSV文件
- 使用熊猫在Python中读取大型Excel文件
- 快速,灵活,轻松和直观:如何加快熊猫项目
您已经了解到Pandas DataFrames处理二维数据。如果您需要使用二维以上的带标签数据,则可以查看xarray,这是另一个功能强大的Python数据科学Python库,其功能与Pandas非常相似。
如果您使用大数据并希望获得类似DataFrame的体验,则可以给Dask一个机会,并使用其DataFrame API。甲DASK数据帧包含在许多熊猫DataFrames和执行计算懒惰方式。
结论
现在,您知道什么是Pandas DataFrame,其某些功能以及如何使用它来有效地处理数据。Pandas DataFrames是强大的,用户友好的数据结构,可用于深入了解数据集!
在本教程中,您学习了:
- 什么是Pandas DataFrame以及如何创建一个
- 如何访问,修改,添加,排序,过滤和删除数据
- 如何将NumPy例程与DataFrames一起使用
- 如何处理缺失值
- 如何使用时间序列数据
- 如何可视化包含在DataFrames中的数据
您已经学到了足够的知识来介绍DataFrames的基础知识。如果您想深入研究使用Python进行数据处理,请查看Pandas教程的全部范围。
https://realpython.com/pandas-dataframe/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号