pandas之表格样式
在juoyter notebook中直接通过df输出DataFrame时,显示的样式为表格样式,通过sytle可对表格的样式做一些定制,类似excel的条件格式。
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D']) s = df.style print(s,type(s)) #<pandas.io.formats.style.Styler object at 0x000001CD7B409710> <class 'pandas.io.formats.style.Styler'>
对表格创建样式有两种方式,都需要额外定义一个处理样式的函数
①df.style.applymap(func,*args,**kwargs):对DataFrame中的每一个元素都按照func的逻辑处理

# 将小于0.2的值字体设置为红色,否则设置为黑色
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D'])
def lt_red(val):
if val<0.2:
color = 'red'
else:
color = 'black'
# print(color)
return ('color:%s'%color)
df.style.applymap(lt_red)
②df.style.apply(func,axis=0,subset=**,*args,**kwargs):对DataFrame的行或列按照func的逻辑处理,axis默认为0按照列处理,1按照行处理。
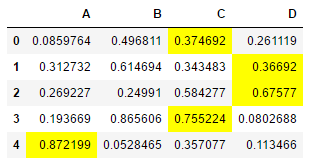
# 将A、C、D列中的每一列最大值背景颜色填充为黄色
def highlight_max(s):
is_max = s == s.max()
l = []
for v in is_max:
if v:
l.append(' padding: 0px; line-height: 1.8; color: rgb(128, 0, 0);">')
else:
l.append('')
# print(l)
return l
df.style.apply(highlight_max,axis = 1,subset = ['A','C','D'])

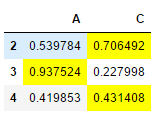
如果在style中需要同时进行行和列的切片,需要用到pandas的IndexSlice
# 对索引为2-5行,列为A、C、D中的每一列最大值背景颜色填充为黄色 df.style.apply(highlight_max,axis=1,subset = pd.IndexSlice[2:5,['A','B','C']]) ## df.loc[2:5,['A','C']].style.apply(highlight_max,axis=1)也可以实现
## 上一种方法会显示所有的DataFrame内容,然后对满足条件的行和列做格式处理;而后一种方法是只显示满足条件的行和列,再做格式处理

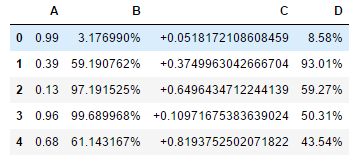
格式化DataFrame中的数值
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D'])
# df.style.format('{:.2%}',subset=['B','C']) #对所有符合条件的采用一种格式format,整个格式用''括起来
df.style.format({'A':'{:.2f}','B':'{:%}','C':'{:+}','D':'{:.2%}'}) #对不同的列采用不同的format,参数为一个字典,key为列名,value为格式
# A、B、C、D列的格式分别为2位小数、百分数、前面加+号,2位小数的百分数
定位空值df.style.highlight_null(null_color='red'),对空值设置背景颜色
对应还有highlight_max()和highlight_min(),参数(subset=None, color='yellow', axis=0)
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D']) df['B'][2] = np.nan df.style.highlight_null(null_color='red')

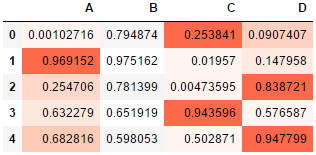
色彩映射
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D']) df.style.background_gradient(cmap='Reds',axis = 1,low = 0,high = 1,subset = ['A','C','D']) # 按行处理,最小值对应颜色表中的最浅色,最大值对应颜色表中的最深色,1表示按行处理
条形图
df = pd.DataFrame(np.random.rand(5,4),columns=['A','B','C','D']) df.style.bar(width=100,subset=['A','C','D'],color='lightpink')
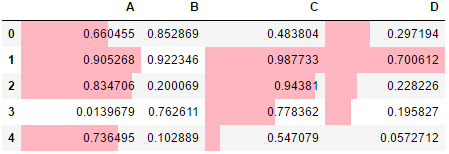
分段式构建样式
df.style.\
bar(width=100,subset=['A'],color='lightpink').\
highlight_max(axis = 1,color='red').\
highlight_min(axis = 1,color='green')
#除最后一行,每一行都以.\结尾
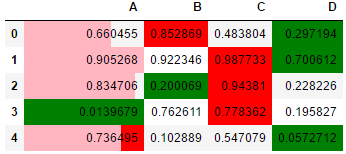
(转)
https://www.cnblogs.com/Forever77/p/11336981.html
# 设置宽度
pd.set_option('display.width',100)
# 设置精确度
pd.set_option('precision',4)
# 设置显示所有列
pd.set_option('display.max_columns',None)
# 设置显示所有行
pd.set_option('display.max_rows',None)
参考:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.set_option.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号