pandas.DataFrame.to_sql
DataFrame.to_sql(self,name : str,con,schema = None,if_exists : str = 'fail',index : bool = True,index_label = None,chunksize = None,dtype = None,method = None) → 无[资源]
将存储在DataFrame中的记录写入SQL数据库。
支持SQLAlchemy [1]支持的数据库。可以新建,追加或覆盖表。
- 参量
- 名称str
-
SQL表的名称。
- con sqlalchemy.engine.Engine或sqlite3.Connection
-
使用SQLAlchemy可以使用该库支持的任何数据库。为sqlite3.Connection对象提供了旧版支持。用户负责处理和处置SQLAlchemy connectable的连接,请参见此处
- 模式str,可选
-
指定模式(如果数据库支持)。如果为None,请使用默认架构。
- if_exists {'fail','replace','append'},默认为'fail'
-
如果表已经存在,该如何表现。
-
失败:引发ValueError。
-
replace:在插入新值之前删除表。
-
append:将新值插入现有表。
-
- 索引布尔值,默认为True
-
将DataFrame索引写为列。使用index_label作为表中的列名。
- index_label str或序列,默认为无
-
索引列的列标签。如果给出None(默认)并且 index为True,则使用索引名。如果DataFrame使用MultiIndex,则应给出一个序列。
- chunksize int,可选
-
指定一次要写入的每个批次中的行数。默认情况下,所有行将一次写入。
- dtype dict或标量,可选
-
指定列的数据类型。如果使用字典,则键应为列名,值应为SQLAlchemy类型或sqlite3传统模式的字符串。如果提供了标量,它将应用于所有列。
- 方法{None,'multi',callable},可选
-
控制使用的SQL插入子句:
-
无:使用标准SQL
INSERT子句(每行一个)。 -
'multi':在单个
INSERT子句中传递多个值。 -
可签名的。
(pd_table, conn, keys, data_iter)
详细信息和示例可调用实现可以在部分insert方法中找到。
0.24.0版中的新功能。
-
- 加薪
- ValueError
-
当表已经存在并且if_exists为'fail'时(默认)。
也可以看看
read_sql-
从表中读取一个DataFrame。
笔记
如果数据库支持,则时区感知日期时间列将与SQLAlchemy 一起写为 类型。否则,日期时间将被存储为时区,而不知道原始时区的本地时间戳。Timestamp with timezone
0.24.0版中的新功能。
参考资料
例子
-
创建一个内存中的SQLite数据库。
from sqlalchemy import create_engine engine = create_engine('sqlite://', echo=False)
从头开始创建带有3行的表。
df = pd.DataFrame({'name' : ['User 1', 'User 2', 'User 3']}) print(df) name 0 User 1 1 User 2 2 User 3df.to_sql('users', con=engine) engine.execute("SELECT * FROM users").fetchall() [(0, 'User 1'), (1, 'User 2'), (2, 'User 3')] df1 = pd.DataFrame({'name' : ['User 4', 'User 5']}) df1.to_sql('users', con=engine, if_exists='append') engine.execute("SELECT * FROM users").fetchall() [(0, 'User 1'), (1, 'User 2'), (2, 'User 3'), (0, 'User 4'), (1, 'User 5')]
用Just覆盖表
df1。df1.to_sql('users', con=engine, if_exists='replace', index_label='id') engine.execute("SELECT * FROM users").fetchall() [(0, 'User 4'), (1, 'User 5')]
指定dtype(特别适用于缺少值的整数)。请注意,虽然熊猫被迫将数据存储为浮点数,但数据库支持可为空的整数。使用Python提取数据时,我们会返回整数标量。
df = pd.DataFrame({"A": [1, None, 2]}) df A 0 1.0 1 NaN 2 2.0 from sqlalchemy.types import Integer df.to_sql('integers', con=engine, index=False, dtype={"A": Integer()}) engine.execute("SELECT * FROM integers").fetchall() [(1,), (None,), (2,)]engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') engine.execute('DROP TABLE if exists jira_report_01') engine.execute('CREATE TABLE jira_report_01 LIKE jira_report;') df_r_t_data.to_sql('jira_report_01', con=engine, if_exists='append', index=True, index_label='CycleName') engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') dfReport = pd.read_sql_table(table_name='jira_report_01', con=engine, columns=['CycleName','通过', '失败', '未执行', '阻止', '不适用']) DataHtml = pd.DataFrame.to_html(dfReport) encoding_type = self.get_encoding_type('/Users/cloud/7_3/JIRA_REST_API/jira_data/email_template.html') tags_stats = {"project_name": self.project_name, "project_version": self.project_version, "test_date": datetime.date.today(), "result_body": DataHtml, "new_defects_added_today": self.new_defects_added_today, "current_version_reference_defect": self.current_version_reference_defect } template_dic = {"test_stat": tags_stats} templates_path = os.path.abspath('..') + os.sep + 'templates/' env = jinja2.Environment( loader=jinja2.FileSystemLoader(templates_path,encoding=encoding_type) ) template = env.get_template('email_template.html') send_mail_template = template.render(template_dic) email_canvas = send_mail_template self.email_status = self.email_static_execution_distribution('2285989001@qq.com', '【{}】【{}】【{}】自动化测试情况'.format(self.project_name, self.project_version, datetime.date.today()), email_canvas) return self.email_status
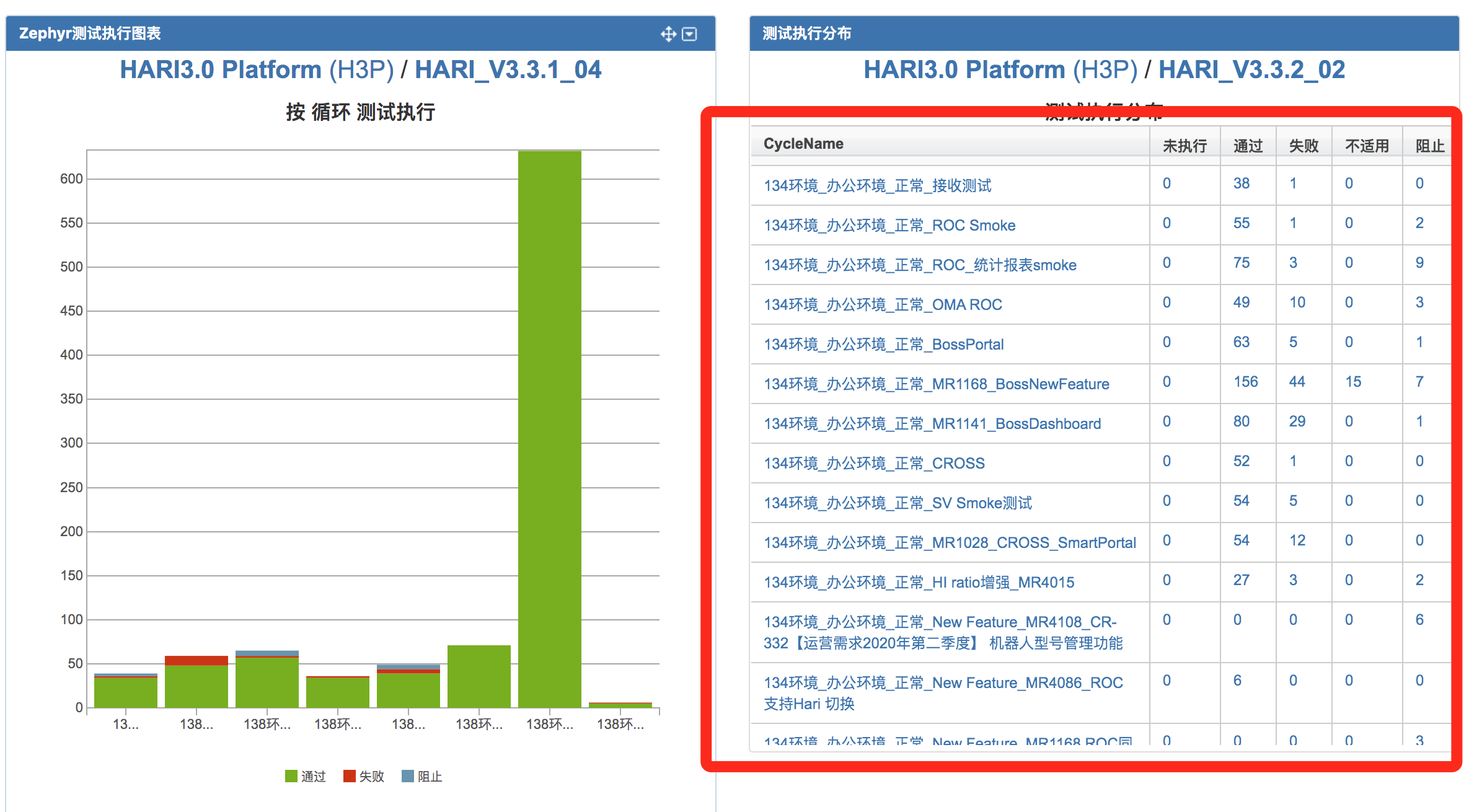
JIRA 循环获取接口参数
![]()
![]()
-
log_prefix = "{} executions_status_count_for_cycle_by_projectId_and_version:".format(self.tag) print(log_prefix) self.project_name = project_name self.project_version = project_version self.tester_email = tester_email jira = JIRA(server=self.base_url, basic_auth=(self.jira_user, self.jira_password)) projects = jira.projects() if isinstance(self.project_name, str) and isinstance(self.project_version,str): for i in range(len(projects)): if str(projects).__contains__(self.project_name) and projects[i].key == self.project_name: project_id = projects[i].id print('HARI3.0 Platform 项目ID是 : ', project_id) print('version \n', jira.project(project_id).versions) print(len(jira.project(project_id).versions)) for j in range(len(jira.project(project_id).versions)): if str(jira.project(project_id).versions).__contains__(self.project_version) and jira.project(project_id).versions[j].name == self.project_version: version_id = jira.project(project_id).versions[j].id print('项目version编号ID是 \n', version_id) url = '/rest/zephyr/latest/execution/executionsStatusCountForCycleByProjectIdAndVersion?projectId={}&versionId={}&components=&_={}'.format( project_id, version_id, int(round(time.time() * 1000))) r = self.session.get(self.base_url + url, headers=self.jira_headers, verify=False) print('\njira返回值\n', r.text) if r.status_code == 200: print("\n获取JIRA列表成功: {} ".format(r.text)) result_json = r.json() new_dict = {k.split(':')[0]: v for k, v in result_json.items()} print(new_dict) self.email_status =self.export_excel(new_dict) return self.email_status else: self.email_status = ['FAIL','邮件发送失败,回调信息 project_version 错误或者不存在!\n当前的版本是{}'.format(jira.project(project_id).versions)] return self.email_status else: self.email_status = ['FAIL','邮件发送失败,回调信息 JIRA 项目名称 project_name 错误!\n{}'.format(str(projects))] return self.email_status
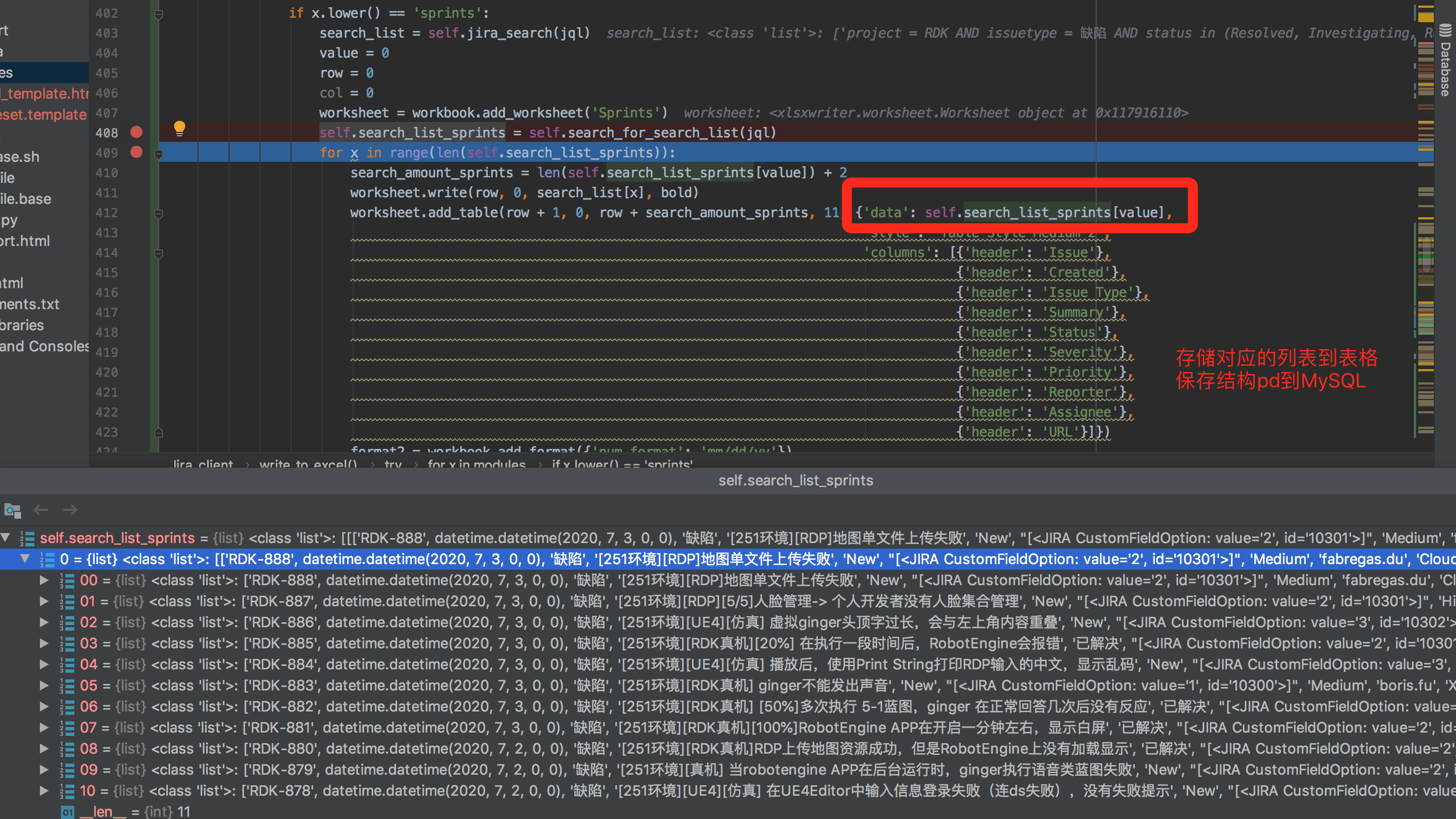
def sql_issue_excel(self, table_name, jql): print('PASS') self.write_to_excel('Sprints', jql) search_list = self.search_list_sprints[0] print(search_list) print(type(search_list)) search_data = pd.DataFrame(search_list) search_data_dict = search_data.to_dict() print('current search_data \n', search_data) print(type(search_data_dict)) print(len(search_data_dict)) if isinstance(search_data_dict, dict): search_data_dict["Issue"] = search_data_dict.pop(0) search_data_dict["Created"] = search_data_dict.pop(1) search_data_dict["Issue Type"] = search_data_dict.pop(2) search_data_dict["Summary"] = search_data_dict.pop(3) search_data_dict["Status"] = search_data_dict.pop(4) search_data_dict["Severity"] = search_data_dict.pop(5) search_data_dict["Priority"] = search_data_dict.pop(6) search_data_dict["Reporter"] = search_data_dict.pop(7) search_data_dict["Assignee"] = search_data_dict.pop(8) search_data_dict["URL"] = search_data_dict.pop(9) print(len(search_data_dict)) print(search_data_dict) search_data = search_data_dict search_data_pd = pd.DataFrame(search_data) print('current \n', search_data_pd) dtypedict = { 'Issue': NVARCHAR(length=255), 'Created': DATE, 'Issue Type': NVARCHAR(length=255), 'Summary': NVARCHAR(length=255), 'Status': NVARCHAR(length=255), 'Severity': NVARCHAR(length=255), 'Priority': NVARCHAR(length=255), 'Reporter': NVARCHAR(length=255), 'Assignee': NVARCHAR(length=255), 'URL': NVARCHAR(length=255) } engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') engine.execute('DROP TABLE if exists {}'.format(table_name)) # engine.execute('CREATE TABLE search_issues LIKE search_issues_template;') search_data_pd.to_sql(table_name, con=engine, if_exists='append', index=False, dtype=dtypedict) df_search_issues = pd.read_sql_table(table_name=table_name, con=engine, columns=['Issue', 'Created', 'Issue Type', 'Summary', 'Status', 'Severity', 'Priority', 'Reporter', 'Assignee', 'URL']) return pd.DataFrame.to_html(df_search_issues) def export_excel(self, export): try: jql_new_defects_added_today = ['''project = RDK AND issuetype = 缺陷 AND status in (Resolved, Investigating, Rejected, Duplicated, Monitor, New, Reopen, Analysing, integrated) AND affectedVersion = V0.6 AND created >= -1d AND created <= 1d ORDER BY created DESC, status DESC, summary ASC, key ASC, priority DESC, updated DESC'''] jql_current_version_reference_defect = ['''project = RDK AND issuetype = 缺陷 AND status in (Resolved, Investigating, Rejected, Duplicated, Monitor, New, Reopen, Analysing, integrated) AND affectedVersion = V0.6 AND created >= -7d AND created <= 7d ORDER BY created DESC, status DESC, summary ASC, key ASC, priority DESC, updated DESC'''] self.sql_issue_excel('new_defects_added_today',jql_new_defects_added_today) self.current_version_reference_defect = self.sql_issue_excel('current_version_reference_defect', jql_current_version_reference_defect) df_r_t_data = pd.DataFrame(export) df_r_t_data = df_r_t_data.T engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') engine.execute('DROP TABLE if exists jira_report_01') engine.execute('CREATE TABLE jira_report_01 LIKE jira_report;') df_r_t_data.to_sql('jira_report_01', con=engine, if_exists='append', index=True, index_label='CycleName') engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') dfReport = pd.read_sql_table(table_name='jira_report_01', con=engine, columns=['CycleName','通过', '失败', '未执行', '阻止', '不适用']) DataHtml = pd.DataFrame.to_html(dfReport) encoding_type = self.get_encoding_type('/Users/cloud/7_3/JIRA_REST_API/jira_data/email_template.html') tags_stats = {"project_name": self.project_name, "project_version": self.project_version, "test_date": datetime.date.today(), "result_body": DataHtml, "new_defects_added_today": self.new_defects_added_today, "current_version_reference_defect": self.current_version_reference_defect } template_dic = {"test_stat": tags_stats} templates_path = os.path.abspath('..') + os.sep + 'templates/' env = jinja2.Environment( loader=jinja2.FileSystemLoader(templates_path,encoding=encoding_type) ) template = env.get_template('email_template.html') send_mail_template = template.render(template_dic) email_canvas = send_mail_template self.email_status = self.email_static_execution_distribution('2285989001@qq.com', '【{}】【{}】【{}】SIT测试情况'.format(self.project_name, self.project_version, datetime.date.today()), email_canvas) return self.email_status except Exception as e: self.email_status = ['FAIL','邮件发送失败,回调信息{}'.format(e)] return self.email_status
![]()
workbook = xlsxwriter.Workbook(jira_current_issue_list_file) bold = workbook.add_format({'bold': True}) row = 0 col = 0 value = 0 print("Attempting to create data tables for: {}".format(modules)) modules = modules.split() # 为不同类型的数据创建单独的工作表 for x in modules: print("\nSearching: {}".format(x.upper())) # 为之前创建的2个模块中的每个模块创建特定格式 if x.lower() == 'sprints': search_list = self.jira_search(jql) value = 0 row = 0 col = 0 worksheet = workbook.add_worksheet('Sprints') self.search_list_sprints = self.search_for_search_list(jql) for x in range(len(self.search_list_sprints)): search_amount_sprints = len(self.search_list_sprints[value]) + 2 worksheet.write(row, 0, search_list[x], bold) worksheet.add_table(row + 1, 0, row + search_amount_sprints, 11, {'data': self.search_list_sprints[value], 'style': 'Table Style Medium 2', 'columns': [{'header': 'Issue'}, {'header': 'Created'}, {'header': 'Issue Type'}, {'header': 'Summary'}, {'header': 'Status'}, {'header': 'Severity'}, {'header': 'Priority'}, {'header': 'Reporter'}, {'header': 'Assignee'}, {'header': 'URL'}]}) format2 = workbook.add_format({'num_format': 'mm/dd/yy'}) # Little column formatting worksheet.set_column('A:A', 15) worksheet.set_column('B:B', 10, format2) worksheet.set_column('C:C', 5) worksheet.set_column('D:D', 5) worksheet.set_column('E:E', 12) worksheet.set_column('F:F', 20) row += search_amount_sprints + 1 value += 1 else: print('There are no more values to add') workbook.close() except Exception as e: print(e) return e
![]()
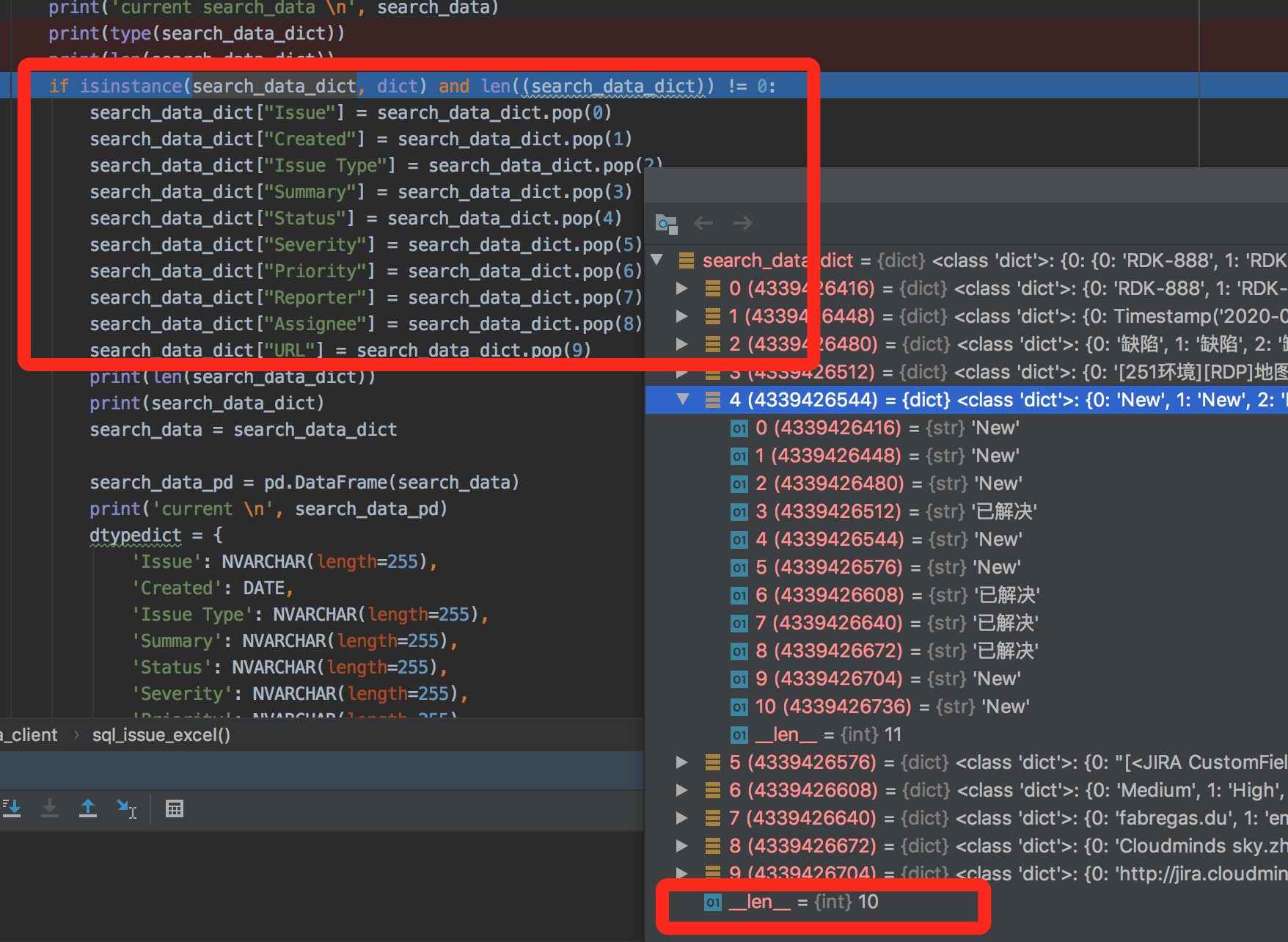
def sql_issue_excel(self, table_name, jql): print('PASS') if not self.new_defects_added_today and isinstance(jql, list) and not self.current_version_reference_defect: print('当前执行的是【今天新增缺陷】{} new_defects_added_today'.format(jql)) self.write_to_excel('Sprints', jql) if not self.current_version_reference_defect and isinstance(jql, list) and self.new_defects_added_today: print('当前执行的是【当前版本引用缺陷】{} current_version_reference_defect'.format(jql)) self.write_to_excel('Sprints', jql) search_list = self.search_list_sprints[0] print(search_list) print(type(search_list)) search_data = pd.DataFrame(search_list) search_data_dict = search_data.to_dict() print('current search_data \n', search_data) print(type(search_data_dict)) print(len(search_data_dict)) if isinstance(search_data_dict, dict) and len((search_data_dict)) != 0: search_data_dict["Issue"] = search_data_dict.pop(0) search_data_dict["Created"] = search_data_dict.pop(1) search_data_dict["Issue Type"] = search_data_dict.pop(2) search_data_dict["Summary"] = search_data_dict.pop(3) search_data_dict["Status"] = search_data_dict.pop(4) search_data_dict["Severity"] = search_data_dict.pop(5) search_data_dict["Priority"] = search_data_dict.pop(6) search_data_dict["Reporter"] = search_data_dict.pop(7) search_data_dict["Assignee"] = search_data_dict.pop(8) search_data_dict["URL"] = search_data_dict.pop(9) print(len(search_data_dict)) print(search_data_dict) search_data = search_data_dict search_data_pd = pd.DataFrame(search_data) print('current \n', search_data_pd) dtypedict = { 'Issue': NVARCHAR(length=255), 'Created': DATE, 'Issue Type': NVARCHAR(length=255), 'Summary': NVARCHAR(length=255), 'Status': NVARCHAR(length=255), 'Severity': NVARCHAR(length=255), 'Priority': NVARCHAR(length=255), 'Reporter': NVARCHAR(length=255), 'Assignee': NVARCHAR(length=255), 'URL': NVARCHAR(length=255) } engine = create_engine('mysql+pymysql://admin:111111@172.16.13.119:3306/jt') engine.execute('DROP TABLE if exists {}'.format(table_name)) # engine.execute('CREATE TABLE search_issues LIKE search_issues_template;') search_data_pd.to_sql(table_name, con=engine, if_exists='append', index=False, dtype=dtypedict) df_search_issues = pd.read_sql_table(table_name=table_name, con=engine,columns=['Issue', 'Created', 'Issue Type', 'Summary', 'Status', 'Severity', 'Priority', 'Reporter', 'Assignee', 'URL']) return pd.DataFrame.to_html(df_search_issues) elif len((search_data_dict)) == 0: return print('当前查询数据返回空值')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号