Improving Compression Artifact Reduction via End-to-End Learning of Side Information-2020
概要:
该文提出通过传输side信息来减弱基于神经网络压缩方法的伪影。
6.1 应用场景:
该文的工作是初步的探索端到端学习边信息的压缩,为得到增强的解码信息提供了借鉴。
6.2 关键设计思路:
边信息是由编码器通过分析原始图像和压缩图像之间的差别而获得的伪影描述符。在解码器中,接收到的描述符作为后处理神经网络的附加输入。同时为了降低传输开销,在速率失真约束下,通过端到端学习对整个模型进行了联合优化。
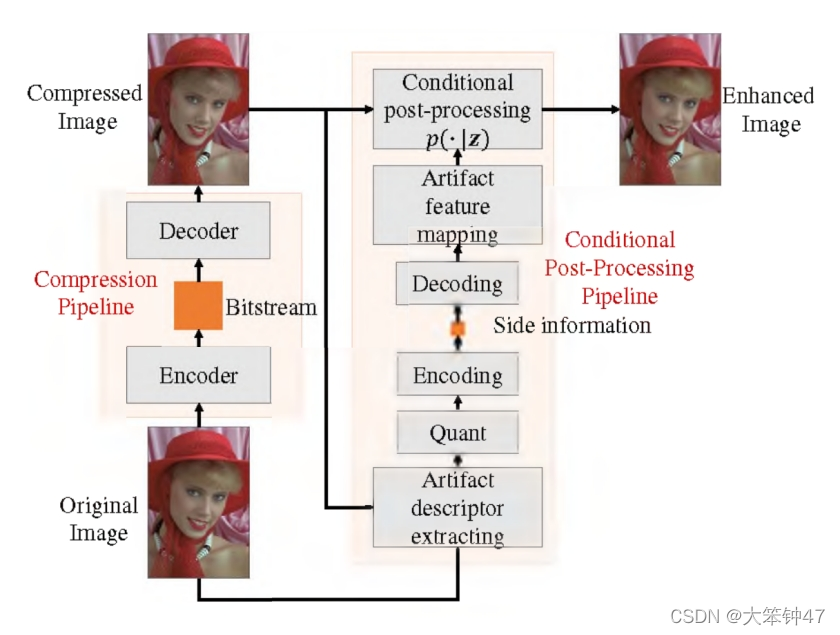](https://img-blog.csdnimg.cn/0d6d3114b7734e15bea51df302ce45ee.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aSn56yo6ZKfNDc=,size_20,color_FFFFFF,t_70,g_se,x_16)
模型架构
6.2.1 Artifact Decriptor Extraction
下图为所设计的Artifact Descriptor提取神经网络的结构。

原始图像和压缩图像分别经过三个卷积层,提取特征\(f_{ori}\)和\(f_{rec}\),\(f_{ori}\)、\(f_{rec}\)和它们的差异拼接在一起,输入到后续的层中。在最后一步中使用了1x1的卷积和softmax操作来将特征映射到浮点概率向量,称为伪影描述符。我们将伪影描述符的通道维度设置为16。它也有可能取另一种取值。
6.2.2 Quantization
为了量化浮点伪影描述符,同时确保梯度在反向传播过程中能够通过量化层,该文利用了soft-to-hard量化。具体地说,从图像中提取的每个Artifact描述符\(x\in R^{16}\)都需要被量化为16个one-hot向量\(C=\{c_1,c_2,...,c_{16}\}\in B^{16}\)中的一个。在正向传递中,x被量化为最近的one-hot向量。
播在反向传递中,将上述公式近似为软量化,以保证反向传播:
6.2.3 Rate Estimation
采用中上下文模型的思想来准确估计传输侧信息的比特率。
在训练过程中,需要同时考虑侧边信息的比特率和重建信息的质量。与端到端图像压缩类似,设计的训练损失如下:
其中,D是输出和原始图像之间的均方误差(MSE),R估计边信息的比特率。
具体来说,该文使用一个5x5掩蔽卷积层和三个1x1卷积层来实现上下文模型。输出有16个通道,沿通道方向标准化softmax,得到概率向量\(p\in R^{16}\)。比特率可以计算如下:
式中,X是一幅图像的所有量化Artifact描述符的集合,\(\hat{x}\cdot p_{\hat{x}}\)表示向量\(x\)和\(p_{\hat{x}}\)之间的向量点积,||X||为X的大小。
6.2.4 Artifact Feature Mapping
在重构解码器中的Artifact描述符后,首先通过下图所示的神经网络将这些one-hot向量转换为浮点数向量,其中“2x”和“8x”代表2倍和8倍的上采样。

6.2.5 Conditional Residual Block
我们去掉了EDSR神经网络中的上采样层,并将其作为后处理神经网络的主干。为了区别于它和原网络,我们称之为EDSR-baseline*。对于条件概率模型,Artifact特征在1x1的卷积层后直接乘以残差块的输入特征。

6.3 测试条件:
JPEG
6.4 测试效率
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-onSmMCOv-1648649510002)(file:///C:\Users\LIUJIA~1\AppData\Local\Temp\ksohtml\wpsEDCD.tmp.jpg)]](https://img-blog.csdnimg.cn/74de6bcd171941caa33feca478598de7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aSn56yo6ZKfNDc=,size_20,color_FFFFFF,t_70,g_se,x_16)
DIV2K验证数据集上的RD曲线
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nOyfeNeL-1648649510003)(file:///C:\Users\LIUJIA~1\AppData\Local\Temp\ksohtml\wpsEDCE.tmp.jpg)]](https://img-blog.csdnimg.cn/0fae5a5c20af4d71ae8a499c4bc48b40.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aSn56yo6ZKfNDc=,size_20,color_FFFFFF,t_70,g_se,x_16)
LIVE1验证数据集上的RD曲线
6.5 Reference
Reference:Improving Compression Artifact Reduction via End-to-End Learning of Side Information

 浙公网安备 33010602011771号
浙公网安备 33010602011771号