squad_convert_example_to_features
最近在看QA,对dataset不是很了解,所以看了一下pytorch中的squad_convert_example_to_features。
1.squad_convert_example_to_features
以下为pytorch源代码:
其中example数据大致呈现(不完整):
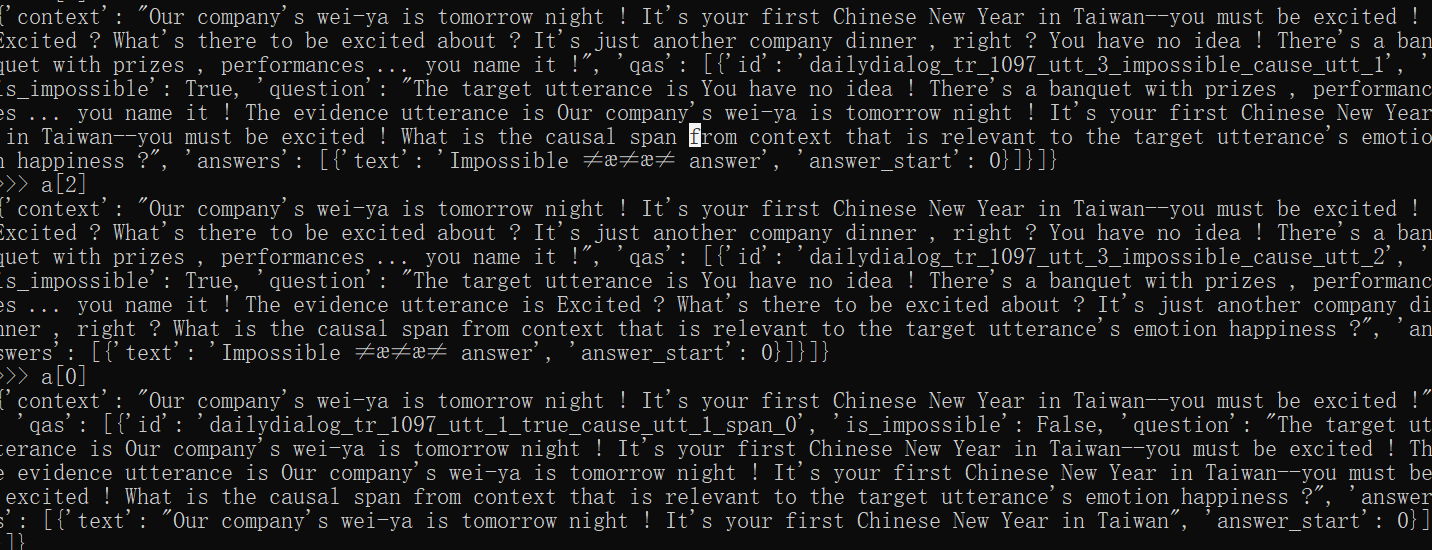
def squad_convert_example_to_features( example, max_seq_length, doc_stride, max_query_length, padding_strategy, is_training ):
# example:需要转化为dataset的数据
“”“
doc_stride:如果context过长的话,会进行截断,doc_stride就代表平移的步长(相邻的截断中会出现重复的,详情请见后面)
max_seq_length:代表最长的sequence length(包括query_length+sequence_added_tokens_length+doc_stride+repeat_length)
repeat_length:代表每一段span中,重复的个数
”“”
features = [] if is_training and not example.is_impossible:
# is_imposiible=False,代表正样本 # Get start and end position
# start_position代表answer text在context text中的start position(注意,这里代表的是词,eg.cuting)
# end_position 代表answer text在context text中的end position(注意,这里代表的是词)
start_position = example.start_position end_position = example.end_position # If the answer cannot be found in the text, then skip this example. actual_text = " ".join(example.doc_tokens[start_position : (end_position + 1)]) cleaned_answer_text = " ".join(whitespace_tokenize(example.answer_text)) if actual_text.find(cleaned_answer_text) == -1: logger.warning(f"Could not find answer: '{actual_text}' vs. '{cleaned_answer_text}'") return [] tok_to_orig_index = [] orig_to_tok_index = [] all_doc_tokens = [] for (i, token) in enumerate(example.doc_tokens): orig_to_tok_index.append(len(all_doc_tokens)) if tokenizer.__class__.__name__ in [ "RobertaTokenizer", "LongformerTokenizer", "BartTokenizer", "RobertaTokenizerFast", "LongformerTokenizerFast", "BartTokenizerFast", ]:
# 代表分词,分为把不同的token,eg.cuting=cut+ing sub_tokens = tokenizer.tokenize(token, add_prefix_space=True) else: sub_tokens = tokenizer.tokenize(token) for sub_token in sub_tokens: tok_to_orig_index.append(i)
# 代表context tokens all_doc_tokens.append(sub_token) if is_training and not example.is_impossible: tok_start_position = orig_to_tok_index[example.start_position] if example.end_position < len(example.doc_tokens) - 1: tok_end_position = orig_to_tok_index[example.end_position + 1] - 1 else: tok_end_position = len(all_doc_tokens) - 1 # 获得answer在contex中的start与end postion (tok_start_position, tok_end_position) = _improve_answer_span( all_doc_tokens, tok_start_position, tok_end_position, tokenizer, example.answer_text ) spans = [] # 将question进行分词+convert_token_ids;
# 参数add_special_tokens=False,代表分词结果不出现特殊的token,eg.[cls],[sep]等 truncated_query = tokenizer.encode( example.question_text, add_special_tokens=False, truncation=True, max_length=max_query_length
)
# Tokenizers who insert 2 SEP tokens in-between <context> & <question> need to have special handling
# in the way they compute mask of added tokens.
tokenizer_type = type(tokenizer).__name__.replace("Tokenizer", "").lower()
sequence_added_tokens = (
tokenizer.model_max_length - tokenizer.max_len_single_sentence + 1
if tokenizer_type in MULTI_SEP_TOKENS_TOKENIZERS_SET
else tokenizer.model_max_length - tokenizer.max_len_single_sentence
)
sequence_pair_added_tokens = tokenizer.model_max_length - tokenizer.max_len_sentences_pair
span_doc_tokens = all_doc_tokens
# 在context length较大的情况下,根据步长为doc_stride进行分段
while len(spans) * doc_stride < len(all_doc_tokens):
# Define the side we want to truncate / pad and the text/pair sorting
if tokenizer.padding_side == "right":
# padding_side代表context片段和question拼接的相对位置关系
texts = truncated_query
pairs = span_doc_tokens
truncation = TruncationStrategy.ONLY_SECOND.value
else:
texts = span_doc_tokens
pairs = truncated_query
truncation = TruncationStrategy.ONLY_FIRST.value
# 当padding_size为right时,拼接的token为question+context片段,总长为max_length(前提是context过长)
encoded_dict = tokenizer.encode_plus( # TODO(thom) update this logic
texts,
pairs,
truncation=truncation,
padding=padding_strategy,
max_length=max_seq_length,
return_overflowing_tokens=True,
stride=max_seq_length - doc_stride - len(truncated_query) - sequence_pair_added_tokens,
return_token_type_ids=True,
)
# 求本段span长度
paragraph_len = min(
# 本段长度未达到max_length
len(all_doc_tokens) - len(spans) * doc_stride,
# 求得本段context总长度,注意,这时的值应该比doc_stride要大
max_seq_length - len(truncated_query) - sequence_pair_added_tokens,
)
if tokenizer.pad_token_id in encoded_dict["input_ids"]:
if tokenizer.padding_side == "right":
non_padded_ids = encoded_dict["input_ids"][: encoded_dict["input_ids"].index(tokenizer.pad_token_id)]
else:
last_padding_id_position = (
len(encoded_dict["input_ids"]) - 1 - encoded_dict["input_ids"][::-1].index(tokenizer.pad_token_id)
)
non_padded_ids = encoded_dict["input_ids"][last_padding_id_position + 1 :]
else:
non_padded_ids = encoded_dict["input_ids"]
tokens = tokenizer.convert_ids_to_tokens(non_padded_ids)
token_to_orig_map = {}
for i in range(paragraph_len):
index = len(truncated_query) + sequence_added_tokens + i if tokenizer.padding_side == "right" else i
token_to_orig_map[index] = tok_to_orig_index[len(spans) * doc_stride + i]
encoded_dict["paragraph_len"] = paragraph_len
encoded_dict["tokens"] = tokens
encoded_dict["token_to_orig_map"] = token_to_orig_map
encoded_dict["truncated_query_with_special_tokens_length"] = len(truncated_query) + sequence_added_tokens
encoded_dict["token_is_max_context"] = {}
encoded_dict["start"] = len(spans) * doc_stride
encoded_dict["length"] = paragraph_len
spans.append(encoded_dict)
if "overflowing_tokens" not in encoded_dict or (
"overflowing_tokens" in encoded_dict and len(encoded_dict["overflowing_tokens"]) == 0
):
break
# overflowing_len代表剩下的context text
span_doc_tokens = encoded_dict["overflowing_tokens"]
for doc_span_index in range(len(spans)):
for j in range(spans[doc_span_index]["paragraph_len"]):
is_max_context = _new_check_is_max_context(spans, doc_span_index, doc_span_index * doc_stride + j)
index = (
j
if tokenizer.padding_side == "left"
else spans[doc_span_index]["truncated_query_with_special_tokens_length"] + j
)
spans[doc_span_index]["token_is_max_context"][index] = is_max_context
for span in spans:
# Identify the position of the CLS token
cls_index = span["input_ids"].index(tokenizer.cls_token_id)
# p_mask: mask with 1 for token than cannot be in the answer (0 for token which can be in an answer)
# Original TF implementation also keep the classification token (set to 0)
p_mask = np.ones_like(span["token_type_ids"])
if tokenizer.padding_side == "right":
p_mask[len(truncated_query) + sequence_added_tokens :] = 0
else:
p_mask[-len(span["tokens"]) : -(len(truncated_query) + sequence_added_tokens)] = 0
pad_token_indices = np.where(span["input_ids"] == tokenizer.pad_token_id)
special_token_indices = np.asarray(
tokenizer.get_special_tokens_mask(span["input_ids"], already_has_special_tokens=True)
).nonzero()
p_mask[pad_token_indices] = 1
p_mask[special_token_indices] = 1
# Set the cls index to 0: the CLS index can be used for impossible answers
p_mask[cls_index] = 0
span_is_impossible = example.is_impossible
start_position = 0
end_position = 0
if is_training and not span_is_impossible:
# For training, if our document chunk does not contain an annotation
# we throw it out, since there is nothing to predict.
doc_start = span["start"]
doc_end = span["start"] + span["length"] - 1
out_of_span = False
if not (tok_start_position >= doc_start and tok_end_position <= doc_end):
out_of_span = True
if out_of_span:
start_position = cls_index
end_position = cls_index
span_is_impossible = True
else:
if tokenizer.padding_side == "left":
doc_offset = 0
else:
doc_offset = len(truncated_query) + sequence_added_tokens
# 标记一下本段是否出现answer的相关文本,并标记其start和endposition
start_position = tok_start_position - doc_start + doc_offset
end_position = tok_end_position - doc_start + doc_offset
features.append(
SquadFeatures(
span["input_ids"],
span["attention_mask"],
span["token_type_ids"],
cls_index,
p_mask.tolist(),
example_index=0, # Can not set unique_id and example_index here. They will be set after multiple processing.
unique_id=0,
paragraph_len=span["paragraph_len"],
token_is_max_context=span["token_is_max_context"],
tokens=span["tokens"],
token_to_orig_map=span["token_to_orig_map"],
start_position=start_position,
end_position=end_position,
is_impossible=span_is_impossible,
qas_id=example.qas_id,
)
)
return features
关于encode_plus的解释:
import torch
from transformers import BertTokenizer
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
sentence = "Hello, my son is laughing."
sentence2 = "Hello, my son is cuting."
print(tokenizer.encode_plus(sentence,sentence2))
结果:
{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length",max_length=12,stride=2,return_token_type_ids=True,return_overflowing_tokens=True,))
结果:此时doc_stride=0
{'overflowing_tokens': [7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length",max_length=12,stride=1,return_token_type_ids=True,return_overflowing_tokens=True,))
结果:此时doc_stirde=1
{'overflowing_tokens': [1010, 2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length",max_length=12,stride=0,return_token_type_ids=True,return_overflowing_tokens=True,))
结果:此时doc_stride=2
{'overflowing_tokens': [2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
2.生成dataset
pytorch中源代码:
def squad_convert_examples_to_features(
examples,
tokenizer,
max_seq_length,
doc_stride,
max_query_length,
is_training,
padding_strategy="max_length",
return_dataset=False,
threads=1,
tqdm_enabled=True,
args=None,
):
"""
Converts a list of examples into a list of features that can be directly given as input to a model.
It is model-dependant and takes advantage of many of the tokenizer's features to create the model's inputs.
Args:
examples: list of :class:`~transformers.data.processors.squad.SquadExample`
tokenizer: an instance of a child of :class:`~transformers.PreTrainedTokenizer`
max_seq_length: The maximum sequence length of the inputs.
doc_stride: The stride used when the context is too large and is split across several features.
max_query_length: The maximum length of the query.
is_training: whether to create features for model evaluation or model training.
return_dataset: Default False. Either 'pt' or 'tf'.
if 'pt': returns a torch.data.TensorDataset,
if 'tf': returns a tf.data.Dataset
threads: multiple processing threadsa-smi
Returns:
list of :class:`~transformers.data.processors.squad.SquadFeatures`
Example::
processor = SquadV2Processor()
examples = processor.get_dev_examples(data_dir)
features = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
)
"""
# Defining helper methods
features = []
threads = min(threads, cpu_count())
if args.use_multiprocessing:
with Pool(threads, initializer=squad_convert_example_to_features_init, initargs=(tokenizer,)) as p:
annotate_ = partial(
squad_convert_example_to_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
max_query_length=max_query_length,
padding_strategy=padding_strategy,
is_training=is_training,
)
features = list(
tqdm(
p.imap(annotate_, examples, chunksize=args.multiprocessing_chunksize),
total=len(examples),
desc="convert squad examples to features",
disable=not tqdm_enabled,
position=0, leave=True
)
)
else:
squad_convert_example_to_features_init(tokenizer)
annotate_ = partial(
squad_convert_example_to_features,
max_seq_length=max_seq_length,
doc_stride=doc_stride,
max_query_length=max_query_length,
padding_strategy=padding_strategy,
is_training=is_training,
)
features = [annotate_(example) for example in tqdm(examples, disable=not tqdm_enabled, position=0, leave=True)]
new_features = []
unique_id = 1000000000
example_index = 0
for example_features in tqdm(
features, total=len(features), desc="add example index and unique id", disable=not tqdm_enabled, position=0, leave=True
):
if not example_features:
continue
for example_feature in example_features:
example_feature.example_index = example_index
example_feature.unique_id = unique_id
new_features.append(example_feature)
unique_id += 1
example_index += 1
features = new_features
del new_features
# Convert to Tensors and build dataset
max_len = 512
all_input_ids = torch.tensor([f.input_ids[:max_len] for f in features], dtype=torch.long)
all_attention_masks = torch.tensor([f.attention_mask[:max_len] for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids[:max_len] for f in features], dtype=torch.long)
all_cls_index = torch.tensor([f.cls_index for f in features], dtype=torch.long)
all_p_mask = torch.tensor([f.p_mask[:max_len] for f in features], dtype=torch.float)
all_is_impossible = torch.tensor([f.is_impossible for f in features], dtype=torch.float)
if not is_training:
all_feature_index = torch.arange(all_input_ids.size(0), dtype=torch.long)
dataset = TensorDataset(
all_input_ids, all_attention_masks, all_token_type_ids, all_feature_index, all_cls_index, all_p_mask
)
else:
all_start_positions = torch.tensor([f.start_position for f in features], dtype=torch.long)
all_end_positions = torch.tensor([f.end_position for f in features], dtype=torch.long)
dataset = TensorDataset(
all_input_ids,
all_attention_masks,
all_token_type_ids,
all_start_positions,
all_end_positions,
all_cls_index,
all_p_mask,
all_is_impossible,
)
return features, dataset
在生成dataset的时候,若样本中的contetx长度过长,将会进行分段(question+context),当作一组训练数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号