encode和encode_plus和tokenizer的区别
1.encode和encode_plus的区别
区别
1. encode仅返回input_ids
2. encode_plus返回所有的编码信息,具体如下:
’input_ids:是单词在词典中的编码
‘token_type_ids’:区分两个句子的编码(上句全为0,下句全为1)
‘attention_mask’:指定对哪些词进行self-Attention操作
代码演示:
import torch
from transformers import BertTokenizer
model_name = 'bert-base-uncased'
# a.通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
sentence = "Hello, my son is laughing."
print(tokenizer.encode(sentence))
print(tokenizer.encode_plus(sentence))
运行结果:
[101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102]
{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}
下面展示一下pytorch中的源代码:
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def encode_plus(
self,
text: Union[TextInput, PreTokenizedInput, EncodedInput],
text_pair: Optional[Union[TextInput, PreTokenizedInput, EncodedInput]] = None,
add_special_tokens: bool = True,
padding: Union[bool, str, PaddingStrategy] = False,
truncation: Union[bool, str, TruncationStrategy] = False,
max_length: Optional[int] = None,
stride: int = 0,
is_split_into_words: bool = False,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs
) -> BatchEncoding:
"""
Tokenize and prepare for the model a sequence or a pair of sequences.
.. warning::
This method is deprecated, ``__call__`` should be used instead.
Args:
text (:obj:`str`, :obj:`List[str]` or :obj:`List[int]` (the latter only for not-fast tokenizers)):
The first sequence to be encoded. This can be a string, a list of strings (tokenized string using the
``tokenize`` method) or a list of integers (tokenized string ids using the ``convert_tokens_to_ids``
method).
text_pair (:obj:`str`, :obj:`List[str]` or :obj:`List[int]`, `optional`):
Optional second sequence to be encoded. This can be a string, a list of strings (tokenized string using
the ``tokenize`` method) or a list of integers (tokenized string ids using the
``convert_tokens_to_ids`` method).
"""
# Backward compatibility for 'truncation_strategy', 'pad_to_max_length'
padding_strategy, truncation_strategy, max_length, kwargs = self._get_padding_truncation_strategies(
padding=padding,
truncation=truncation,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
verbose=verbose,
**kwargs,
)
return self._encode_plus(
text=text,
text_pair=text_pair,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
stride=stride,
is_split_into_words=is_split_into_words,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
return_token_type_ids=return_token_type_ids,
return_attention_mask=return_attention_mask,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_offsets_mapping=return_offsets_mapping,
return_length=return_length,
verbose=verbose,
**kwargs,
)
add_special_tokens的默认参数为True。
text_pair:Optional second sequence to be encoded。
import torch
from transformers import BertTokenizer
model_name = 'bert-base-uncased'
# a.通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
sentence = "Hello, my son is laughing."
sentence2 = "Hello, my son is cuting."
print(tokenizer.encode_plus(sentence,sentence2))
结果:
{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
其中101代表[cls],102代表[sep]。由于add_special_tokens的默认参数为True,所以中间拼接会有连接词[sep],‘token_type_ids’:区分两个句子的编码(上句全为0,下句全为1)。
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length"))
padding为补零操作,默认加到max_length=512;
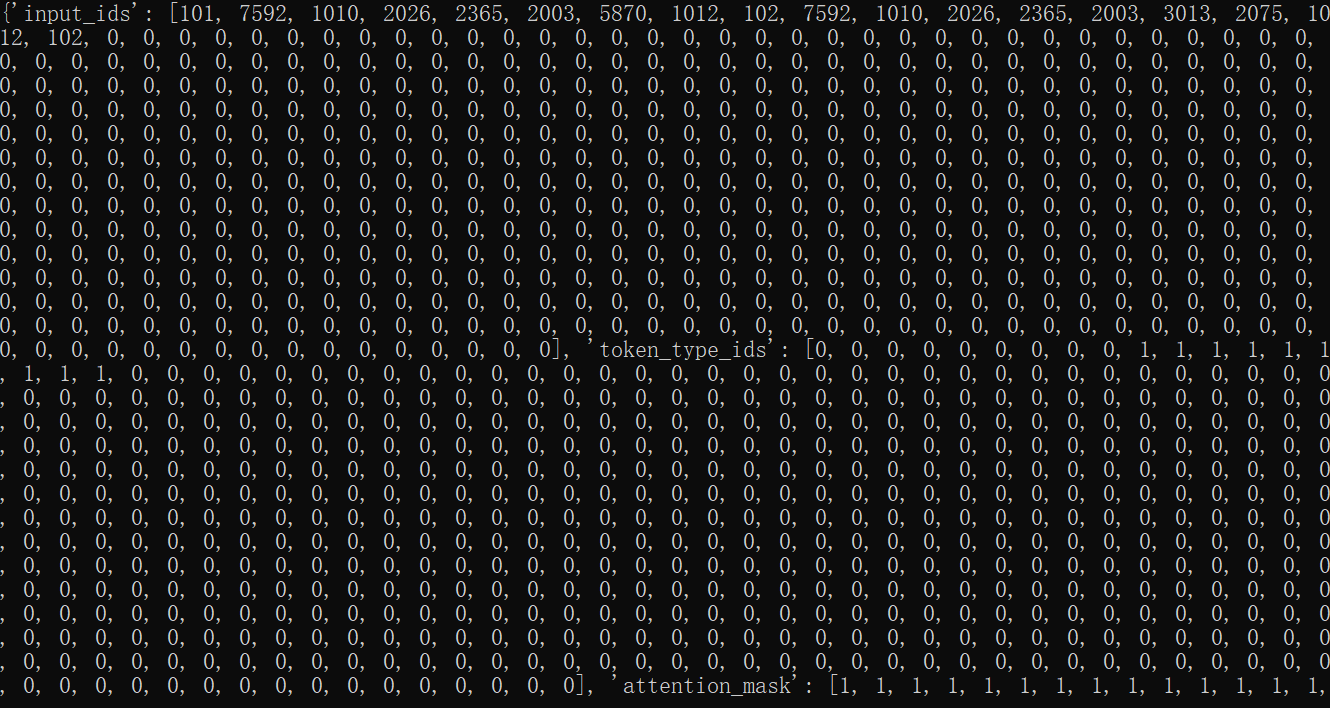
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length",max_length=12,stride=2,return_token_type_ids=True,))
{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
print(tokenizer.encode_plus(sentence,sentence2,truncation="only_second",padding="max_length",max_length=12,stride=2,return_token_type_ids=True,return_overflowing_tokens=True,))
结果:
{'overflowing_tokens': [7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012], 'num_truncated_tokens': 6, 'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102, 7592, 1010, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}

2.encode和tokeninze方法的区别
- 直接上代码比较直观(其中处理的句子是随便起的,为了凸显WordPiece功能):
sentence = "Hello, my son is cuting."
input_ids_method1 = torch.tensor(
tokenizer.encode(sentence, add_special_tokens=True)) # Batch size 1
# tensor([ 101, 7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012, 102])
input_token2 = tokenizer.tokenize(sentence)
# ['hello', ',', 'my', 'son', 'is', 'cut', '##ing', '.']
input_ids_method2 = tokenizer.convert_tokens_to_ids(input_token2)
# tensor([7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012])
# 并没有开头和结尾的标记:[cls]、[sep]
(当tokenizer.encode函数中的add_special_tokens设置为False时,同样不会出现开头和结尾标记:[cls], [sep]。)
从例子中可以看出,encode方法可以一步到位地生成对应模型的输入。
相比之下,tokenize只是用于分词,可以分成WordPiece的类型,并且在分词之后还要手动使用convert_tokens_to_ids方法,比较麻烦。
通过源码阅读,发现encode方法中调用了tokenize方法,所以在使用的过程中,我们可以通过设置encode方法中的参数,达到转化数据到可训练格式一步到位的目的,下面开始介绍encode的相关参数与具体操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号