BertConfig, BertForQuestionAnswering, BertTokenizer
1.BertConfig
类 BertConfigBertForQuestionAnswering
BERT 模型的配置类,BERT 的超参配置都在这里。其参数(蓝色)和方法(黄色)总览如下:
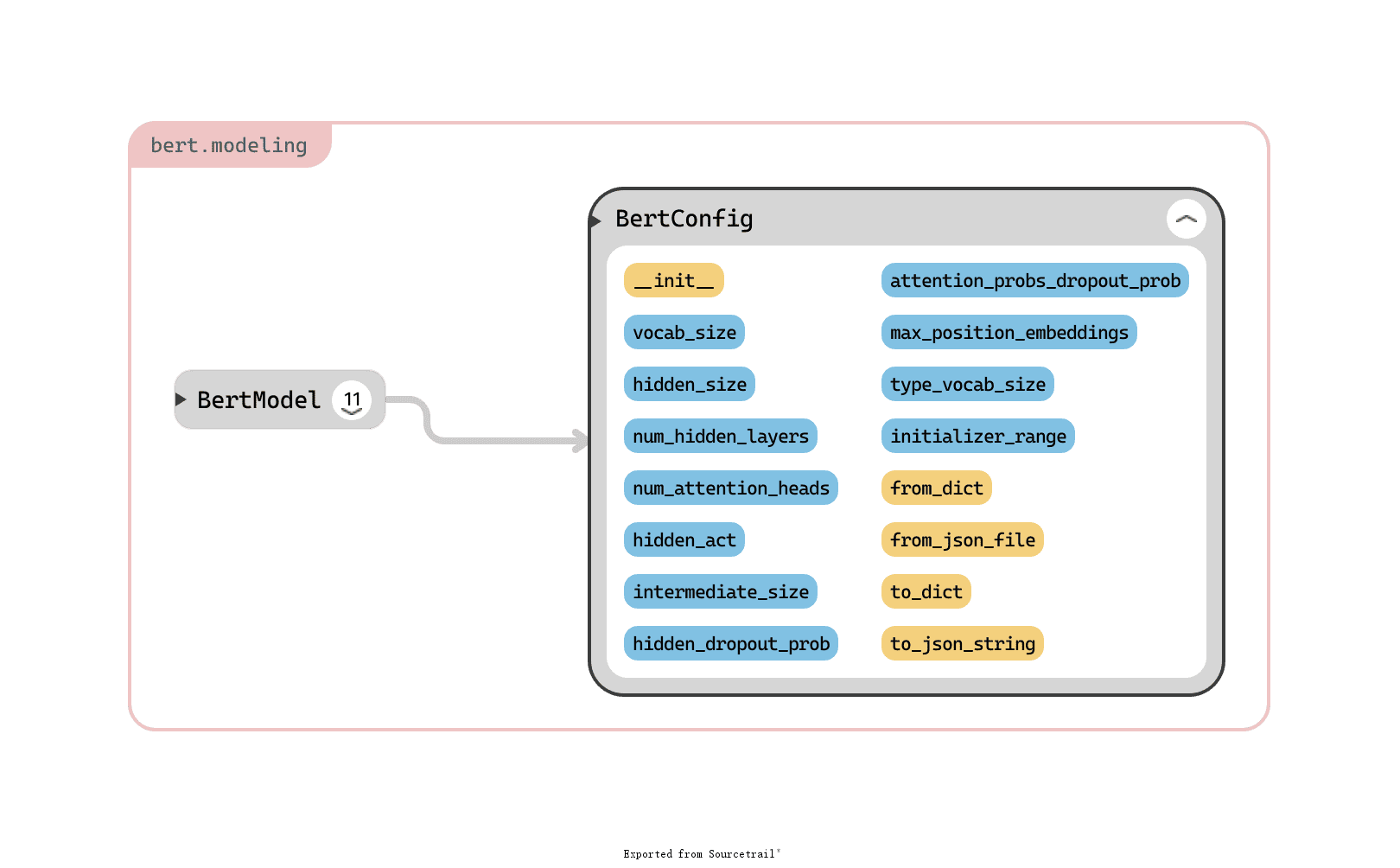
参数
vocab_size:词汇表大小。
hidden_size=768:encoder 层和 pooler 层大小。这实际上就是 embedding_size,BERT 干的事情就是不停地优化 embedding。。。
num_hidden_layers=12:encoder 中隐层个数。
num_attention_heads=12:每个 attention 层的 head 个数。
intermediate_size=3072:中间层大小。
hidden_act="gelu":隐层激活函数。
hidden_dropout_prob=0.1:所有全连接层的 dropout 概率,包括 embedding 和 pooler。
attention_probs_dropout_prob=0.1:attention 层的 dropout 概率。
max_position_embeddings=512:最大序列长度。
type_vocab_size=16:token_type_ids 的词汇表大小。
initializer_range=0.02:初始化所有权重时的标准差。
方法
from_dict(cls, json_object):从一个字典来构建配置。
from_json_file(cls, json_file):从一个 json 文件来构建配置。
to_dict(self):将配置保存为字典。
to_json_string(self):将配置保存为 json 字符串。
原文链接:https://blog.csdn.net/u010099080/article/details/106915111
2.BertForQuestionAnswering
Pytorch下载好transformers后,点击进入源代码:
def requires_backends(obj, backends):
if not isinstance(backends, (list, tuple)):
backends = [backends]
name = obj.__name__ if hasattr(obj, "__name__") else obj.__class__.__name__
if not all(BACKENDS_MAPPING[backend][0]() for backend in backends):
raise ImportError("".join([BACKENDS_MAPPING[backend][1].format(name) for backend in backends]))
3.BertTokenizer
BERT 源码中 tokenization.py 就是预处理进行分词的程序,主要有两个分词器:BasicTokenizer 和 WordpieceTokenizer,另外一个 FullTokenizer 是这两个的结合:先进行 BasicTokenizer 得到一个分得比较粗的 token 列表,然后再对每个 token 进行一次 WordpieceTokenizer,得到最终的分词结果。
BasicTokenizer
BasicTokenizer(以下简称 BT)是一个初步的分词器。对于一个待分词字符串,流程大致就是转成 unicode -> 去除各种奇怪字符 -> 处理中文 -> 空格分词 -> 去除多余字符和标点分词 -> 再次空格分词,结束。
WordpieceTokenizer
按照从左到右的顺序,将一个词拆分成多个子词,每个子词尽可能长。 greedy longest-match-first algorithm,贪婪最长优先匹配算法。
例如:比如"loved",“loving”,"loves"这三个单词。其实本身的语义都是“爱”的意思,但是如果我们以单词为单位,那它们就算不一样的词,在英语中不同后缀的词非常的多,就会使得词表变的很大,训练速度变慢,训练的效果也不是太好。
BPE算法通过训练,能够把上面的3个单词拆分成"lov",“ed”,“ing”,"es"几部分,这样可以把词的本身的意思和时态分开,有效的减少了词表的数量。
以下摘自源代码:
class WordpieceTokenizer(object):
"""Runs WordPiece tokenization."""
def __init__(self, vocab, unk_token, max_input_chars_per_word=100):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
def tokenize(self, text):
"""
Tokenizes a piece of text into its word pieces. This uses a greedy longest-match-first algorithm to perform
tokenization using the given vocabulary.
For example, :obj:`input = "unaffable"` wil return as output :obj:`["un", "##aff", "##able"]`.
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BasicTokenizer`.
Returns:
A list of wordpiece tokens.
"""
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokens
再来看BertTokenizer类下的method。
def _tokenize(self, text):
split_tokens = []
if self.do_basic_tokenize:
for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens):
# If the token is part of the never_split set
if token in self.basic_tokenizer.never_split:
split_tokens.append(token)
else:
split_tokens += self.wordpiece_tokenizer.tokenize(token)
else:
split_tokens = self.wordpiece_tokenizer.tokenize(text)
return split_tokens
部分摘自:
https://blog.csdn.net/u010099080/article/details/102587954

 浙公网安备 33010602011771号
浙公网安备 33010602011771号