sklearn分类
小编最近学习了运用sklearn进行分类。写篇博客用来记录一下,加深印象。 参考Robert Layton得数据挖掘。
sklearn主要通过欧式距离来对数据进行分类。 描述距离得大致有三种,欧式距离,曼哈顿距离,余弦距离。
首先,对数据得处理,就需要先进行训练,之后再用一部分数据进行检验。
估计器通常用来训练 测试数据集。scikit-learn将分类得功能封装在估计器中。
小编 参考教材得K近邻估计器。首先导入模块,创建一个实例(参数默认就行)。
from sklearn.neighbors import KNeighborsClassifier estimator = KNeighborsClassifier()
估计器有两种主要功能,训练和预测分别是 estimator.fit() 和 estimator.predict()。
estimator.fit(X_train, y_train) X_train 和 y_train 分别表示训练数据集,训练数据值集。
y_predicted = estimator.predict(X_test) X_test 表示预测集。
仅仅两行就可以实现预测。 当然,这次我们仅仅将原始数据分为了两部分,有很大得偶然性。
sklearn提供了一个模块,帮助我们分割数据集,便于多次预测,交叉检验算法。
from sklearn.cross_validation import cross_val_score
下面是从官网 截取得关于分类得参数。
cross_val_score默认使用Stratified K Fold方法切分数据集,它大体上保
证切分后得到的子数据集中类别分布相同,以避免某些子数据集出现类别分布失
衡的情况。
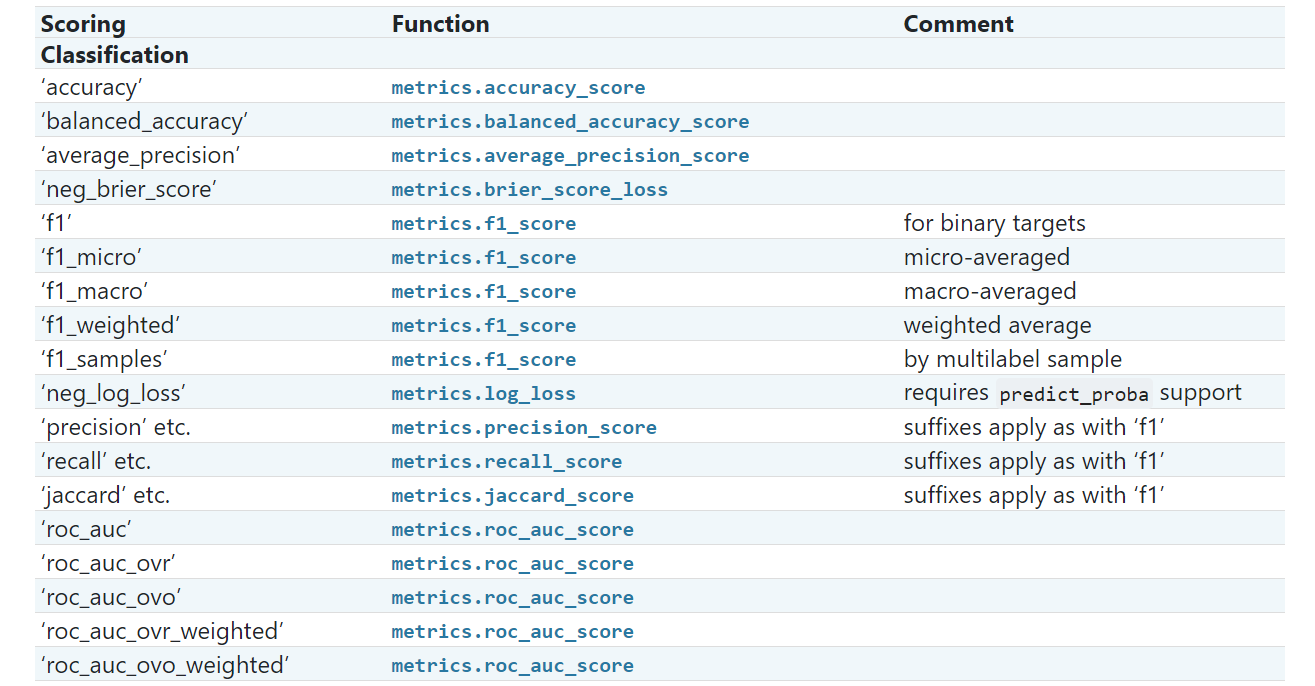
scores = cross_val_score(estimator, X, y, scoring='accuracy')
接受参数如此,estimator代表估计器,X,y分别代表原始数据,和结果。
由于数据可能存在误差,或者多个特征,他们得值相差特别大,但他们得权重一样,只是量纲不同,如果不做数据的预处理,最终的预测效果可能误差比较大。
from sklearn.preprocessing import MinMaxScaler
这个类可以把每个特征的值域规范化为0到1之间。最小值用0代替,最大值用1代替,其余值
介于两者之间。
接下来,对数据集X进行预处理。我们在预处理器MinMaxScaler上调用转换函数。有些转
换器要求像训练分类器那样先进行训练,但是 MinMaxScaler 不需要,直接调用
fit_transform()函数,即可完成训练和转换。
X_transformed = MinMaxScaler().fit_transform(X)
用这种方法进行处理,矩阵X都会介于0到1之间,大大减小了误差。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号