

URL编码与XSS
0x00 背景
最近遇到一个双重编码绕过过滤的xss漏洞,成功在大佬的指点下弹出成功之后记录一下学习。
0x01 URL编码
一个URL的形式如下:
foo://example.com:8042/over/there?name=ferret#nose
协议 域名 端口 路径 search参数 hash参数
通常来说,如果某种文本需要编码,说明他并不适合传输。原因多种多样,或压缩尺寸,或隐藏隐私数据……
对于URL来说,之所以要进行编码,一方面是因为URL中有些字符会引起歧义。例如,URL参数字符串中使用key=value键值对这样的形式来传参,键值对之间以&符号分隔,如/s?name=chen&city=beijing。但是这个时候如果value字符串包含了=或者&,那么服务器解析肯定会出错,因此必须将引起歧义的&和=符号进行编码。
另一方面,因此URL编码采用的是ASCII码,这也就是说你不能在Url中包含任何非ASCII字符,例如中文。否则如果客户端浏览器和服务端浏览器支持的字符集不同的情况下,中文可能会造成问题。
Javascript中对于URL编码主要有以下几个函数:
escape(string):该方法不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: * @ - _ + . / 。其他所有的字符都会被转义序列替换。
escape("http://www.xxx.com/My first/a?name=chen&city=beijing")======>>>>>> http%3A//www.xxx.com/My%20first/a%3Fname%3Dchen%26city%3Dbeijing
encodeURI(string):该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ' ( ) 。该方法的目的是对 URI 进行完整的编码,因此对以下在 URI 中具有特殊含义的 ASCII 标点符号,encodeURI() 函数是不会进行转义的:;/?:@&=+$,#
encodeURI("http://www.xxx.com/My first/a?name=chen&city=beijing")========>>>>>> http://www.xxx.com/My%20first/a?name=chen&city=beijing
encodeURIComponent(string):该方法不会对 ASCII 字母和数字进行编码,也不会对这些 ASCII 标点符号进行编码: - _ . ! ~ * ' ( ) 。其他字符(比如 :;/?:@&=+$,# 这些用于分隔 URI 组件的标点符号),都是由一个或多个十六进制的转义序列替换的。
encodeURIComponent("http://www.xxx.com/My first/a?name=chen&city=beijing")=======>>>>>> http%3A%2F%2Fwww.xxx.com%2FMy%20first%2Fa%3Fname%3Dchen%26city%3Dbeijin
0x02 URL双重编码
那么为什么需要双重编码呢?因为以上未讨论value为中文的情况。
首先,在前端页面准备参数的时候,需要对中文参数进行encode处理:
var url = '/?page_name='+encodeURI(encodeURI("测试")); window.open(url);
后端处理:String starName = java.net.URLDecoder.decode(request.getParameter("page_name"),"UTF-8");
<Connector port="80" protocol="HTTP/1.1" redirectPort="8449" connectionTimeout="20000"/>
<Connector port="80" protocol="HTTP/1.1" redirectPort="8449" connectionTimeout="20000" URIEncoding="UTF-8"/>
0x03 URL编码与XSS
XSS原理这里就不讲了。这里直接使用自己遇到的一个反射性xss的例子,问题参数出在url的search参数上。
首先是是在搜索框中插入尖括号,可以看到这是在黑名单之中的:
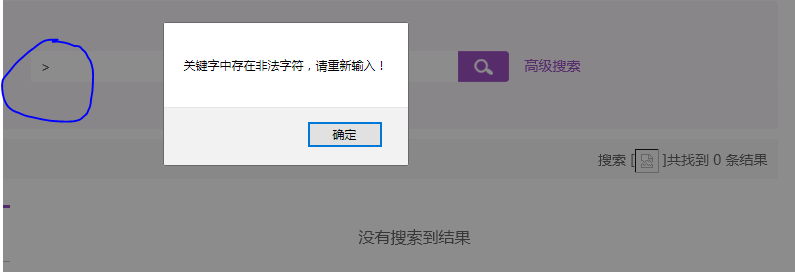
然后输入正常的查询字段发现会被编码并使用get方式进行提交,所以就在对应的参数后面进行提交,还是首先测试尖括号的url编码是否被过滤,经过测试发现经过一次URL编码的%3c依旧会被过滤,但是经过二次URL编码的%253c就能够在搜索框与页面正常显示:

这里就通过查看源代码和查看元素发现都被正常解析了,这也意味着可以出发XSS了,一个触发点时搜索框中,一个触发点时搜索[<]的中括号里面。
这里继续尝试在搜索的中括号进行XSS,将payload <img src=1 onerror=alert(1)>进行2次URL编码如下:%253Cimg%2520src%253D1%2520onerror%253Dalert%25281%2529%253E
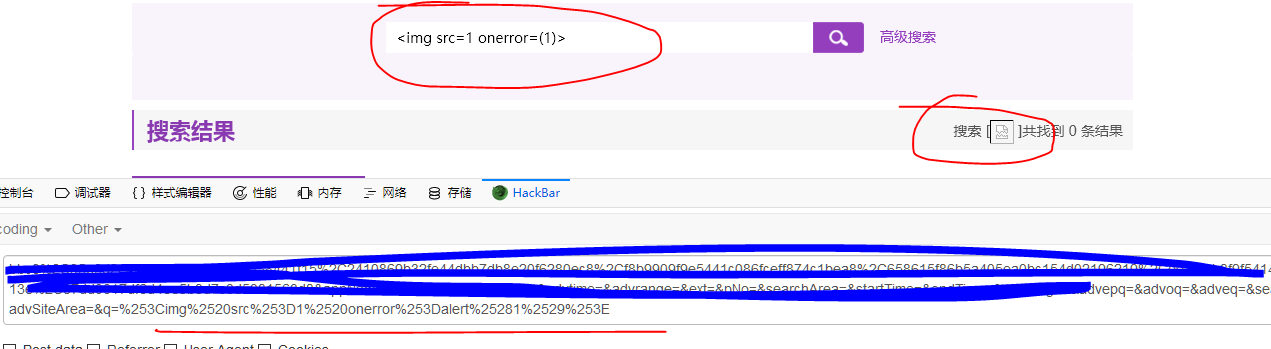
可以看到<img>标签被正确解析了,但是onerror 的alert却没有被触发,所以后台对于alert应该是有防护的,这里尝试双写绕过即可触发:
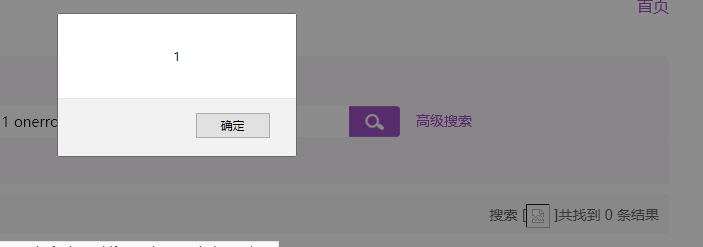
还有一个触发点就是在输入框利用引号闭合,增加onclick或者onmouseover等事件进行触发。
0x04 绕过原理
首先就是浏览器在前端与后端都有过滤措施。
首先前端在输入框对于输入的参数校验是很严格的,对于未经编码与经过编码的特殊符号都能够做到完整过滤,但是却使用了get进行提交,导致攻击者可以任意修改url参数进行绕过前端验证。
其次后端的验证对于非法字符的检测与过滤机制就太不严格了,当我们传输只经过一次URL编码的payload时,后台可以经过解码可以检测出敏感输入,但是在经过2次URL编码的时候就无法检测出恶意的符号内容。
参考链接:
https://blog.csdn.net/zmx729618/article/details/51381655
https://www.cnblogs.com/longling2344/p/5476785.html
https://blog.csdn.net/zhxtpray/article/details/52440076

