
Elasticsearch自定义分析器analyzer分词实践
基础知识回顾
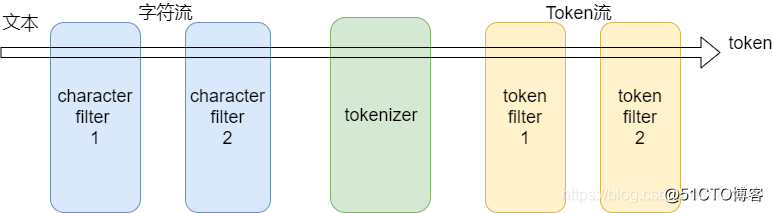
分析器的组成结构:
分析器(analyzer) - Character filters (字符过滤器)0个或多个 - Tokenizer (分词器)有且只有一个 - Token filters (token过滤器)0个或多个
内置分析器
1、whitespace 空白符分词
POST _analyze
{
"analyzer": "whitespace",
"text": "你好 世界"
}
{
"tokens": [
{
"token": "你好",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "世界",
"start_offset": 3,
"end_offset": 5,
"type": "word",
"position": 1
}
]
}
2、pattern正则表达式分词,默认表达式是\w+(非单词字符)
配置参数
pattern : 一个Java正则表达式,默认 \W+ flags : Java正则表达式flags。比如:CASE_INSENSITIVE 、COMMENTS lowercase : 是否将terms全部转成小写。默认true stopwords : 一个预定义的停止词列表,或者包含停止词的一个列表。默认是 _none_ stopwords_path : 停止词文件路径
// 拆分中文不正常
POST _analyze
{
"analyzer": "pattern",
"text": "你好世界"
}
{
"tokens": []
}
// 拆分英文正常
POST _analyze
{
"analyzer": "pattern",
"text": "hello world"
}
{
"tokens": [
{
"token": "hello",
"start_offset": 0,
"end_offset": 5,
"type": "word",
"position": 0
},
{
"token": "world",
"start_offset": 6,
"end_offset": 11,
"type": "word",
"position": 1
}
]
}
// 在索引上自定义分析器-竖线分隔
PUT my-blog
{
"settings": {
"analysis": {
"analyzer": {
"vertical_line": {
"type": "pattern",
"pattern": "\\|"
}
}
}
},
"mappings": {
"doc": {
"properties": {
"content": {
"type": "text",
"analyzer": "vertical_line"
}
}
}
}
}
// 测试索引分析器
POST /blog-v4/_analyze
{
"analyzer": "vertical_line",
"text": "你好|世界"
}
POST /blog-v4/_analyze
{
"field": "content",
"text": "你好|世界"
}
// 两者结果都是
{
"tokens": [
{
"token": "你好",
"start_offset": 0,
"end_offset": 2,
"type": "word",
"position": 0
},
{
"token": "世界",
"start_offset": 3,
"end_offset": 5,
"type": "word",
"position": 1
}
]
}
我的网站 http://www.a-du.net

 浙公网安备 33010602011771号
浙公网安备 33010602011771号