python中------decode解码出现的0xca问题解决方法
一。错误:
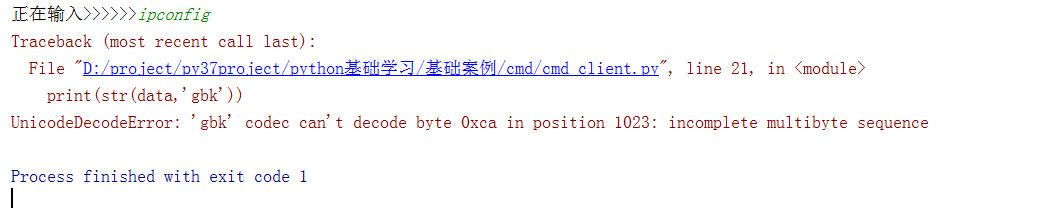
解决方法:
#源代码 data = sk.recv(1024) print(str(data,'gbk')) #修改代码 data = sk.recv(1024) print(str(data,'gbk',‘ignore’))
二。常见错误整理
0x00 问题引出:
result = res.decode('utf-8') #当执行该语句的时候,会造成异常:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe5 in position 103339: invalid continuation byte
0x01 问题分析
该情况是由于出现了无法进行转换的 二进制数据 造成的,可以写一个小的脚本来判断下,是整体的字符集参数选择上出现了问题,还是出现了部分的无法转换的二进制块:
#python3 #以读入文件为例: f = open("data.txt","rb")#二进制格式读文件 while True: line = f.readline() if not line: break else: try: #print(line.decode('utf8')) line.decode('utf8') #为了暴露出错误,最好此处不print except: print(str(line))
0x03 解决方法
修改字符集参数,一般这种情况出现得较多是在国标码(GBK)和utf8之间选择出现了问题。 出现异常报错是由于设置了decode()方法的第二个参数errors为严格(strict)形式造成的,因为默认就是这个参数,将其更改为ignore等即可。例如: line.decode("utf8","ignore")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号