

ConcurrentHashMap底层实现
1、ConcurrentHashMap和HashTable区别
ConcurrentHashMap融合了hashtable和hashMap二者的优势;
hashTable是做了同步的,hashMap没有同步,所以hashMap在单线程情况下效率高,hashTable在多线程情况下,同步操作能保证程序执行的正确性;
但是hashTable每次同步执行都要锁住整个结构;
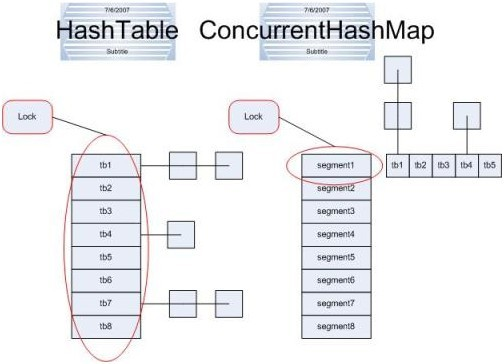
ConcurrentHashMap锁的方式是稍微细粒度的(分段锁机制),ConcurrentHashMap将hash表分为16个桶(默认值);
2、JDK1.7和JDK1.8底层实现的区别
(1)底层数据结构
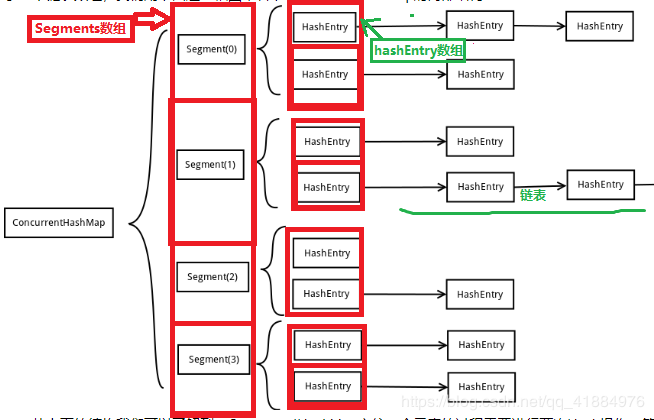
<jdk1.7>:
数组(Segment) + 数组(HashEntry) + 链表(HashEntry节点)
底层一个Segments数组,存储一个Segments对象,一个Segments中储存一个Entry数组,存储的每个Entry对象又是一个链表头结点。
<jdk1.8>:
Node数组+链表 / 红黑树: 类似hashMap<jdk1.8>
Node数组使用来存放树或者链表的头结点,当一个链表中的数量到达一个数目时,会使查询速率降低,所以到达一定阈值时,会将一个链表转换为一个红黑二叉树,通告查询的速率。
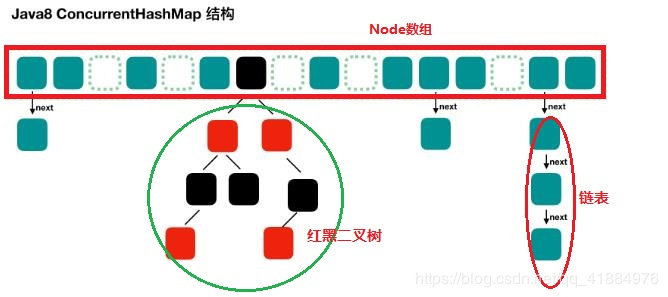
ConcurrentHashMap取消了Segment分段锁的机制,从而实现一段数据进行加锁,减少了并发,CAS(读)+synchronized(写)
(2)主要属性
<jdk1.7>:
两个主要的内部类:
HashEntry 定义的节点,里面存储的数据和下一个节点,在此不分析
class Segment内部类,继承ReentrantLock,有一个HashEntry数组,用来存储链表头结点
int count ; //此对象中存放的HashEntry个数 int threshold ; //扩容阈值 volatile HashEntry<K,V>[] table; //储存entry的数组,每一个entry都是链表的头部 float loadFactor; //加载因子
v get(Object key, int hash); 获取相应元素 //注意:此方法并不加锁,因为只是读操作, V put(K key, int hash, V value, boolean onlyIfAbsent) //注意:此方法加锁
<jdk1.8>:
//外部类的基本属性 volatile Node<K,V>[] table; // Node数组用于存放链表或者树的头结点 static final int TREEIFY_THRESHOLD = 8; // 链表转红黑树的阈值 > 8 时 static final int UNTREEIFY_THRESHOLD = 6; // 红黑树转链表的阈值 <= 6 时 static final int TREEBIN = -2; // 树根节点的hash值 static final float LOAD_FACTOR = 0.75f; // 负载因子 static final int DEFAULT_CAPACITY = 16; // 默认大小为16 //内部类 class Node<K,V> implements Map.Entry<K,V> { int hash; final K key; volatile V val; volatile Node<K,V> next; } //jdk1.8中虽然不在使用分段锁,但是仍然有Segment这个类,但是没有实际作用
更详细可以参照:https://blog.csdn.net/qq_41884976/article/details/89532816
3、ConcurrentHashMap底层put方法实现的核心逻辑
public V put(K key, V value) { return putVal(key, value, false); }
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode());// 得到 hash 值 int binCount = 0; // 用于记录相应链表的长度 for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 如果数组"空",进行数组初始化 if (tab == null || (n = tab.length) == 0) // 初始化数组 tab = initTable(); // 找该 hash 值对应的数组下标,得到第一个节点 f else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { // 如果数组该位置为空, // 用一次 CAS 操作将新new出来的 Node节点放入数组i下标位置 // 如果 CAS 失败,那就是有并发操作,进到下一个循环 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // hash 居然可以等于 MOVED,这个需要到后面才能看明白,不过从名字上也能猜到,肯定是因为在扩容 else if ((fh = f.hash) == MOVED) // 帮助数据迁移,这个等到看完数据迁移部分的介绍后,再理解这个就很简单了 tab = helpTransfer(tab, f); else { // 到这里就是说,f 是该位置的头结点,而且不为空 V oldVal = null; // 获取链表头结点监视器对象 synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // 头结点的 hash 值大于 0,说明是链表 // 用于累加,记录链表的长度 binCount = 1; // 遍历链表 for (Node<K,V> e = f;; ++binCount) { K ek; // 如果发现了"相等"的 key,判断是否要进行值覆盖,然后也就可以 break 了 if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } // 到了链表的最末端,将这个新值放到链表的最后面 Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { // 红黑树 Node<K,V> p; binCount = 2; // 调用红黑树的插值方法插入新节点 if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } // binCount != 0 说明上面在做链表操作 if (binCount != 0) { // 判断是否要将链表转换为红黑树,临界值: 8 if (binCount >= TREEIFY_THRESHOLD) // 如果当前数组的长度小于 64,那么会进行数组扩容,而不是转换为红黑树 treeifyBin(tab, i); // 如果超过64,会转成红黑树 if (oldVal != null) return oldVal; break; } } } // addCount(1L, binCount); return null; }
对于putVal函数的流程大体如下:
①判断存储的key,value是否为空,若为空,则抛出异常;
②计算key的hash值,随后进入无限循环,该无限循环可以确保成功插入数据,若table表为空或者长度为0,则初始化table表;
③根据key的hash值取出table表中的结点元素,若取出的结点元素为空(该桶为空),则使用CAS将key,value,hash值生成的结点放入桶中;
④若该节点的hash值为MOVED,则对该桶中的结点进行转移;
⑤对桶中的第一个结点进行加锁,对该桶进行遍历,桶中的结点的hash值与key值与给定的hash值和key值相等,则根据标识选择是否进行更新操作(用给定的value值替换该结点的value值),若遍历完桶仍没有找到hash值与key值和指定的hash值与key值相等的结点,则直接新生一个结点并赋值为之前最后一个结点的下一个结点;
⑥若binCount值达到红黑树转化的阈值,则将桶中的结构转化为红黑树存储,最后,增加binCount的值;
4、ConcurrentHashMap底层get方法实现的核心逻辑
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; //计算key的hash值 int h = spread(key.hashCode()); //表不为空并且表的长度大于0并且key所在的桶不为空 if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) { //表中的元素的hash值与key的hash相等 if ((eh = e.hash) == h) { //键相等 if ((ek = e.key) == key || (ek != null && key.equals(ek))) return e.val; } //结点hash值小于0 else if (eh < 0) //在桶中查找 return (p = e.find(h, key)) != null ? p.val : null; //对于结点hash值大于0的情况 while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek)))) return e.val; } } return null; }
get函数根据key的hash值来计算在哪个桶中,再遍历桶,查找元素,若找到则返回该结点,否则,返回null;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号