润生商团出行打车模块(环境安装)1
系统需求java jdk15.2 cpu 7代以后 node16 以上吧.他们要求安装jdk15.2
idea 要求插件 中文语言包 myBatisx Restful Fast Request
maven 配置好的可以使用,本次maven 3.6.3 和我们其它项目一样,配置就略,本来可以在conf 配置中加下路径,但是我们这儿可以不用

idea 中设置,工具那儿,这儿要配共享索引为不下载,
注册小程序 微信公众平台 略 一个邮箱只能开发一个帐号,拿 到小程序的appid 和 密钥
下载二个前端工具( hbuidex 开发者工具)
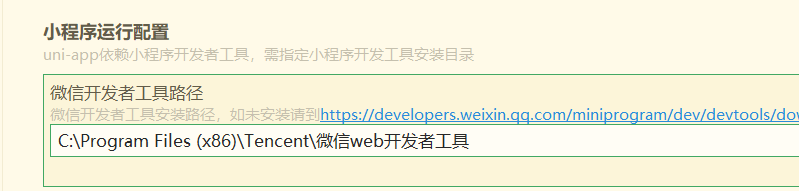
微信开发者工具可能需要配置一下,(1安装路径不要修改,2菜单,安全 改开启端口,这个端口是随机的 ,3外观主题色,)
node安装,文档上是17.3.1 如果版本不对安装不了vue3
配置cnpm 工具,安装依赖方便一些
npm install -g cnpm --registry=https://registry.npm.taobao.org
安装HBuiderx 不要在官方下载,是因为我们这个也经帮下载了好多插件。然后配置 字体
HBdudel要配置路径,
环境安装
虚拟机需要6g 内存 30g 硬盘 NAT 网络 安装ctentos 7 关且闭seliunx 服务
SELINUX是Cent0s自带的安全服务,因为晦涩难用,并且跟很多程序冲突,所以强烈建议大家关闭这个服务。找到 /etc/sysconfig/selinux 文件,把其中的 SELINUX 设置为 disabled ,保存文件之后重启CentOs系统。


在 CentOS 系统中,关闭 SELinux 服务可以通过以下方法: 临时关闭 SELinux: 你可以通过运行以下命令临时关闭 SELinux: sudo setenforce 0 请注意,这种方法仅在当前会话有效。重启系统后,SELinux 将再次启用。 永久关闭 SELinux: 要永久关闭 SELinux,你需要编辑 /etc/selinux/config 文件。请按照以下步骤操作: a. 使用文本编辑器打开 /etc/selinux/config 文件,例如使用 vi 编辑器: sudo vi /etc/selinux/config b. 在文件中找到以下行: SELINUX=enforcing c. 将其更改为: SELINUX=disabled d. 保存并关闭文件。 重启系统以使更改生效: sudo reboot 重启后,SELinux 服务将被永久禁用。你可以通过运行以下命令验证 SELinux 是否已关闭: getenforce 如果输出显示 Disabled,则表示 SELinux 已成功关闭。
打开这个路径 可以修改配置,/etc/sysconfig/selinux

如果是新环境安装docker 可能会出现yum 的仓库不可用,需要更新yum
其二就是如果是新环境网络可能需要给cento7配网卡,
cd /etc/sysconfig/network-scripts/
里面有一个叫ifcfg-enp0s3 的网络
vim ifcfg-enp0s3
需要改BOOTPROTO = “static” 大致内容如下
TYPE=Ethernet PROXY_METHOD=none BROWSER_ONLY=no BOOTPROTO=static IPADDR=192.168.99.101 NETMASK=255.255.255.0 GATEWAY=192.168.99.1 DNS1=114.114.114.114 DEFROUTE=yes IPV4_FAILURE_FATAL=no IPV6INIT=yes IPV6_AUTOCONF=yes IPV6_DEFROUTE=yes IPV6_FAILURE_FATAL=no IPV6_ADDR_GEN_MODE=stable-privacy NAME=enpOs3
安装doker
yum install docker -y:这个命令用于从YUM仓库中安装Docker。yum 是一个包管理器,用于在Red Hat及其衍生版(如CentOS)上管理软件包。install 是告诉YUM要安装的软件包,docker 是我们要安装的软件包,-y 参数表示自动接受安装过程中的提示,无需人工干预。
service docker start:这个命令用于启动Docker服务。service 是一个用于管理系统服务的命令行工具。docker 是我们要启动的服务,start 是告诉 service 要启动该服务。启动Docker服务后,你就可以使用Docker命令来管理容器了。
查看docder 是否启动 。systemctl status docker 查看也启用的容器可以用 sudo docker ps -a
部署程序
包括mysql 集群,(4个MYSQL ShardingSphere(集群) )mongoDB Redis RabbtMQ Minio Nacos Sentinel
微服务方案 Nacos 远程调用 Tx-LCN 分布式事务 鉴权
安装虚拟机 这儿要安装多个sql 所以这儿要用虚拟机。用了NAT 网络就没有ip了 代用了windows 的网络
端口映射:
vbox的网络 端口转发,点击加上,主机端口改为5022 了服务端口为22
存诸 光盘中指定ios 就可以指定安装文件 健盘的右cltr可以移出鼠标
远程工具MobaXterm 这个是免费的,当然我们用啥 都行,比如xshell

docker 介结
docker
比如说我们现在想要在Linux系统上搭建MySQL集群,想要在一个Linux系统上面同时运行多个MySQL,你要做跟多事情,例如定义繁复的配置文件和目录,然后还要写复杂的启动脚本,
每个MySQL节点还要单独执行初始化等等,特别麻烦。有了Docker之后,我们只需要运行几条命令,MySQL节点就创建好了,特别节省时间,而且Docker隔离性做的很好,你也不用担心MySQL节点之间的冲突。
再比如说,你们公司开发了很多项目。去年开发的Java项目用的是JDK1.8和MariaDB数据库,已经部署在Linux上面了。今年开发的项目用的是JDK15和MySQL数据库,现在要把这个项目也部署在同一个Linux系统之上
,那就非常困难。因为MySQL和MariaDB的程序包有冲突,在同一个Linux系统中只能安装其中一个数据库,要么是MySQL要么是MariaDB。还有JDK1.8和JDK15,你怎么给系统设置两个!ava环境变量?所以我们就需要引入Docker环境,
Docker中的镜像与容器
为了最大化地共享资源和减少浪费,Docker引入了镜像技术。镜像可以被看作是沙箱之间的共享部分,而它们之间的差异化部分则被称为容器。以Java镜像为例,假设其中已经安装了JDK 1.8。基于这个镜像,我们可以创建两个容器。这两个容器都将共享使用该Java镜像中的Java环境,但每个容器内都可以安装和运行不同的Java程序。
如果没有镜像技术,我们可能需要在两个容器中分别安装JDK环境,这将导致不必要的重复工作和资源浪费。
Docker镜像的创建方式
创建Docker镜像有多种方法:
- 通过Dockerfile创建:你可以编写Dockerfile文件,其中指定了要安装的程序和脚本。然后,执行特定的Docker命令,Docker会根据你的要求自动创建镜像。
- 基于现有容器创建:你也可以选择一个现有的容器,在其中安装额外的程序或配置,然后将其逆向创建为新的镜像。
- 从Docker Hub下载:如果你不想自己创建镜像,可以从Docker Hub网站下载其他人创建的镜像。例如,你可以找到MySQL镜像、HBase镜像、JDK镜像、Python镜像等。下载后,将这些镜像导入到你的Docker环境中,并基于它们创建容器,从而快速使用MySQL、HBase等功能,大大节省了时间。
docker 性能
3.程序运行在容器中,性能有没有损失?
Docker创建的沙箱是轻量级的,只给容器创建了虚拟网卡,所以对Linux系统开销非常小。在容器中运行程序跟在Linux同直接运行程序没有差别,性能也没有任何损失,所以你可以放心使用Docker环境。现实中,一台硬件服务器同时运行几百个容器也没有问题。即便2GB内存的低端云主机,运行十几个容器也能撑得下来。
以下是常用命令
安装docker
yum update -y
yum install docker -y
开 service docker start
关 service docker stop
查看容器 docker images
删除镜向 docker rmi 镜像名字
第三章 布署mysql 节点
文档上说,找到别人安装好配置好的mysql 上传到iunx 执行导入
docker load < MYSQL.tar.gz
设置虚拟机端口转发 ,这儿我本身就是另一台主机我不转发。但是笔记还得记,如果宿主机和虚拟机共一个主机需要配转发
先传上文档中需要的中间健,放到一个服务器中,然后,docker load < MySQL.tar.gz

使用命令查看,
[root@95ca3fdc90aa rsTools]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
gitlab/gitlab-ce 14.0.0-ce.0 db71bbad3cdc 3 years ago 2.21GB
mysql 8.0.23 8457e9155715 3 years ago 546MB
文档中有搞端口转发,我这儿不需要,因为我不是nat 网络模式

创建网段 docker network create --subnet=172.18.0.0/18 mynet 创建容器 docker run -it -d --name mysql1 \ -p 12001:3306 \ --net mynet \ --ip 172.18.0.2 \ -m 400m \ -v /root/mysql1/data:/var/lib/mysql \ -v /root/mysql1/config:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --privileged=true \ mysql:8.0.23 \ --lower-case-table-names=1

这儿一个有4个集群数据库都要配置
docker run -it -d --name mysql2 \ -p 12002:3306 \ --net mynet \ --ip 172.18.0.3 \ -m 400m \ -v /root/mysql2/data:/var/lib/mysql \ -v /root/mysql2/config:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --privileged=true \ mysql:8.0.23 \ --lower-case-table-names=1
docker run -it -d --name mysql3 \ -p 12003:3306 \ --net mynet \ --ip 172.18.0.4 \ -m 400m \ -v /root/mysql3/data:/var/lib/mysql \ -v /root/mysql3/config:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --privileged=true \ mysql:8.0.23 \ --lower-case-table-names=1
最后再加一个
docker run -it -d --name mysql4 \ -p 12004:3306 \ --net mynet \ --ip 172.18.0.5 \ -m 400m \ -v /root/mysql4/data:/var/lib/mysql \ -v /root/mysql4/config:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --privileged=true \ mysql:8.0.23 \ --lower-case-table-names=1
以上是命令,以下是执行结果

经过以上操作集群数据库存也建好。

如果创建失败,需要用docker rm 删除一个容器 然后检查创建容器是不是有错,我们再创造一个事务用的中间健数据库,并不存储数据,所以这个不算是节点
docker run -it -d --name mysql5 \ -p 12005:3306 \ --net mynet \ --ip 172.18.0.6 \ -m 400m \ -v /root/mysql5/data:/var/lib/mysql \ -v /root/mysql5/config:/etc/mysql/conf.d \ -e MYSQL_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --privileged=true \ mysql:8.0.23 \ --lower-case-table-names=1
现在开始布署 ShardingSphere
Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由JDBC、Proxy和 Sidecar(规划中)这3款既能够独立部署,又支持混合部罗配合使用的产品组成,它们均提供标准化的数据水平扩展、分布式事务和分布式治理等功能,可适用于如Java 同构、异构语言、云原生等各种多样化的应用场景,
Apache ShardingSphere 旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。关系型数据库当今依然占有巨大市场份额,是企业核心系统的基石,未来也难于撼动,我们更加注重在原有基础上提供增量,而非颠覆。
Apache ShardingSphere 5.x版本开始致力于可插拔架构,项目的功能组件能够灵活的以可插拔的方式进行扩展。目前,数据分片、读写分离、数据加密、影子库压测等功能,以及 MySQL、PostgreSQL、SQLServer、Oracle 等 SQL 与协议的支持,均通过插件的方式织入项目。开发者能够像使用积木一样定制属于自己的独特系统。Apache ShardingSphere 目前已提供数十个 SPI 作为系统的扩展点,仍在不断增加中。
ShardingSphere 已于2020年4月16日成为 Apache 软件基金会的顶级项目。
ShardingSphere默认使用3307端口,稍后我会把容器的3307端口映射到Linux的3307端口上,现在我们要把Linux
的3307端口映射到Windows的3307端口上。
如果是NAT 网络模式要配映射端口。以下示例:但是我这是独立主机所以不用配

正式使用ShardingSphere 前需要安装jdk15 由于我之前装过1.5 所以这个容器用docker 来装
[root@95ca3fdc90aa rsTools]# docker load < JDK.tar.gz 2dc759e04e34: Loading layer 138.3MB/138.3MB 31d49e12312e: Loading layer 42.5MB/42.5MB 0baa06748a3a: Loading layer 336.1MB/336.1MB
以下是整理后的Docker命令语法:
docker run -it -d --name ss -p 3307:3307 --net mynet --ip 172.18.0.7 -m 400m -v /root/ss:/root/ss -e TZ=Asia/Shanghai --privileged=true jdk bash
这个命令将执行以下操作:
使用名为jdk的镜像创建一个新的容器。
将容器的3307端口映射到主机的3307端口。
将容器连接到名为mynet的网络,并为其分配IP地址172.18.0.7。
为容器分配400MB的内存。
将主机上的/root/ss目录挂载到容器的/root/ss目录。
设置容器时区为Asia/Shanghai。
以特权模式运行容器。
在容器内启动bash shell。
请注意,您需要确保已经存在名为jdk的Docker镜像。如果没有,请使用相应的Dockerfile构建该镜像,或者使用现有的JDK镜像,我们在这儿操作前有用docket 拉过

以下加了jdk bash 是防止自动退出

通上面的操作,也经在root/ss 目录和docker 下的目录对应了,我们可以过入容器去启运这个容器的东西
现在我们上传ShardingSphere 文件上去,但这个文件是zip 格式,解压需要安装 yum install unzip -y 支持,不过我是win 上面解压上传的。
#进入bin目录 cd ShardingSphere/bin #给脚本文件赋权限 chmod -R 777 /* #进入容器 docker exec -it ss bash #进入bin目录cd /root/ss/ShardingSphere/bin #启动 ShardingSphere./start.sh
启动这个东西要入容器启动,否则找不到数据库
root@95ca3fdc90aa logs]# cd /
[root@95ca3fdc90aa /]# docker exec -it ss bash
bash-4.2# cd /root/ss/ShardingSphere/bin/
bash-4.2# ./st
start.bat start.sh stop.sh
bash-4.2# ./st
start.bat start.sh stop.sh
bash-4.2# ./start.sh
Starting the ShardingSphere-Proxy ...
The classpath is /root/ss/ShardingSphere/conf:.:/root/ss/ShardingSphere/lib/*:/root/ss/ShardingSphere/ext-lib/*
Please check the STDOUT file: /root/ss/ShardingSphere/logs/stdout.log
bash-4.2# ll
bash: ll: command not found
bash-4.2# cd /root/ss/ShardingSphere/logs/
bash-4.2# ll
bash: ll: command not found
bash-4.2# ll
bash: ll: command not found
bash-4.2# cd /root/ss/
bash-4.2# tail -f /root/ss/ShardingSphere/logs/stdout.log
at com.zaxxer.hikari.pool.HikariPool.checkFailFast(HikariPool.java:554)
... 21 more
[0.008s][warning][gc,ergo] NewSize was set larger than initial heap size, will use initial heap size.
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.codehaus.groovy.reflection.CachedClass (file:/root/ss/ShardingSphere/lib/groovy-2.4.19-indy.jar) to method java.lang.Object.finalize()
WARNING: Please consider reporting this to the maintainers of org.codehaus.groovy.reflection.CachedClass
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Thanks for using Atomikos! Evaluate http://www.a
体验集群
项目中的微服务模块划分:
我们的项目包含十几个微服务模块,为了实现彻底解耦,各个模块使用独立的逻辑库。若每个MySQL分片对应一个逻辑库,则至少需要十几个分片,每个分片至少有6个MySQL节点。总计需要超过60个MySQL节点,这在个人电脑上难以运行。因此,我们需在四个MySQL分片上创建不同逻辑库,为不同微服务模块提供服务。
逻辑库划分:
| 分片 | 逻辑库 | 备注 | 具体用途 |
|---|---|---|---|
| 分片1 | hxds_cst | 客户逻辑库 | 客户信息、罚款等 |
| 分片1 | hxds_dr | 司机逻辑库 | 司机信息、实名认证、罚款、钱包等 |
| 分片1 | hxds_mis | MI5系统逻辑库 | 后台管理用的数据表 |
| 分片1 | hxds_rule | 规则逻辑库 | 代驾费计算规则,分账规则、取消规则等 |
| 分片2 | hxds_cst | 客户逻辑库 | 客户信息、罚款等 |
| 分片2 | hxds_dr | 司机逻辑库 | 司机信息、实名认证、罚款、钱包等 |
| 分片2 | hxds_mis | MI5系统逻辑库 | 后台管理用的数据表 |
| 分片2 | hxds_rule | 规则逻辑库 | 代驾费计算规则,分账规则、取消规则等 |
通过以上划分,我们可以在四个MySQL分片上实现不同微服务模块的逻辑库隔离。
ShardingSphere 使用介绍
ShardingSphere主要由以下几个模块组成:
-
Sharding-JDBC:Sharding-JDBC是ShardingSphere的第一个模块,它是一个轻量级的Java框架,用于在Java应用程序中实现数据库的水平分片。Sharding-JDBC通过SQL解析引擎将SQL请求转换为针对每个数据分片的SQL请求,然后将结果合并并返回给应用程序。这使得开发者无需修改应用程序代码即可实现数据库的水平扩展。
-
Sharding-Proxy:Sharding-Proxy是ShardingSphere的第二个模块,它是一个高性能的数据库代理服务器,支持MySQL协议。Sharding-Proxy可以将来自应用程序的SQL请求分发到不同的数据分片,并将结果合并后返回给应用程序。这使得应用程序无需知道底层数据库的分片细节,从而简化了数据库的管理和维护。
-
Sharding-Sidecar(实验性功能):Sharding-Sidecar是ShardingSphere的第三个模块,它是一个Kubernetes的 sidecar 容器,用于在Kubernetes环境中自动配置和管理数据库分片。Sharding-Sidecar可以自动检测应用程序的数据库连接信息,并根据预设的分片策略将请求分发到不同的数据分片。
-
Elastic-Job-Sharding:Elastic-Job-Sharding是ShardingSphere的一个可选模块,它是一个分布式任务调度框架,可以与Sharding-JDBC或Sharding-Proxy结合使用,实现数据库分片的动态扩容和缩容。Elastic-Job-Sharding可以根据应用程序的负载情况自动调整数据库分片的数量,从而提高数据库的性能和可用性。
-
Sharding-UI:Sharding-UI是ShardingSphere的Web界面,用于管理和监控ShardingSphere集群的状态。通过Sharding-UI,用户可以查看数据库分片的详细信息,监控数据库的性能指标,以及执行诸如添加、删除、修改分片等操作。
![]() 参考配置
参考配置//显示在虚拟数据库存的名字 schemaName: hxds //连接以 dataSources: rep_s1_mis: url: jdbc:mysql://172.18.0.2:3306/hxds_mis?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true username: root password: abc123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 rep_s1_cst: url: jdbc:mysql://172.18.0.2:3306/hxds_cst?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true username: root password: abc123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 rep_s2_cst: url: jdbc:mysql://172.18.0.3:3306/hxds_cst?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true username: root password: abc123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 rep_s1_dr: url: jdbc:mysql://172.18.0.2:3306/hxds_dr?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true username: root password: abc123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 rep_s2_dr: url: jdbc:mysql://172.18.0.3:3306/hxds_dr?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true username: root password: abc123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 minPoolSize: 1 以下是配置,只是没有规则而己 rules: - !SHARDING tables: tb_action: actualDataNodes: rep_s1_mis.tb_action tb_dept: actualDataNodes: rep_s1_mis.tb_dept tb_feedback: actualDataNodes: rep_s1_mis.tb_feedback tb_module: actualDataNodes: rep_s1_mis.tb_module tb_permission: actualDataNodes: rep_s1_mis.tb_permission tb_role: actualDataNodes: rep_s1_mis.tb_role tb_user: actualDataNodes: rep_s1_mis.tb_user 以下是不规则的配置 tb_customer: actualDataNodes: rep_s${1..2}_cst.tb_customer databaseStrategy: standard: shardingColumn: id shardingAlgorithmName: cst-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_customer_fine: actualDataNodes: rep_s${1..2}_cst.tb_customer_fine databaseStrategy: standard: shardingColumn: customer_id shardingAlgorithmName: cst-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_customer_car: actualDataNodes: rep_s${1..2}_cst.tb_customer_car databaseStrategy: standard: shardingColumn: customer_id shardingAlgorithmName: cst-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_driver: actualDataNodes: rep_s${1..2}_dr.tb_driver databaseStrategy: standard: shardingColumn: id shardingAlgorithmName: dr-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_driver_fine: actualDataNodes: rep_s${1..2}_dr.tb_driver_fine databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_driver_recognition: actualDataNodes: rep_s${1..2}_dr.tb_driver_recognition databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_driver_settings: actualDataNodes: rep_s${1..2}_dr.tb_driver_settings databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_driver_lockdown: actualDataNodes: rep_s${1..2}_dr.tb_driver_lockdown databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_wallet: actualDataNodes: rep_s${1..2}_dr.tb_wallet databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_wallet_income: actualDataNodes: rep_s${1..2}_dr.tb_wallet_income databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_wallet_payment: actualDataNodes: rep_s${1..2}_dr.tb_wallet_payment databaseStrategy: standard: shardingColumn: driver_id shardingAlgorithmName: dr-children-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_charge_rule: actualDataNodes: rep_s${1..2}_rule.tb_charge_rule databaseStrategy: standard: shardingColumn: id shardingAlgorithmName: rule-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_cancel_rule: actualDataNodes: rep_s${1..2}_rule.tb_cancel_rule databaseStrategy: standard: shardingColumn: id shardingAlgorithmName: rule-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake tb_award_rule: actualDataNodes: rep_s${1..2}_rule.tb_award_rule databaseStrategy: standard: shardingColumn: id shardingAlgorithmName: rule-inline keyGenerateStrategy: column: id keyGeneratorName: snowflake dr-children-inline: type: INLINE props: algorithm-expression: rep_s${(driver_id % 2)+1}_dr rule-inline: type: INLINE props: algorithm-expression: rep_s${(id % 2)+1}_rule odr-inline: type: INLINE props: algorithm-expression: rep_s${(id % 2)+3}_odr odr-children-inline: type: INLINE props: algorithm-expression: rep_s${(order_id % 2)+3}_odr vhr-inline: type: INLINE props: algorithm-expression: rep_s${(id % 2)+3}_vhr vhr-children-inline: type: INLINE props: algorithm-expression: rep_s${(voucher_id % 2)+3}_vhr keyGenerators: snowflake: type: SNOWFLAKE props: worker-id: 123
2.7 安装NoSQL数据库
本课程还需要用除了MySQL之外的一些其他NōSQL数据库,这节课我们就在Docker中把这些数据库给安装上。
-、安装MongoDB
在本项目中,MongoDB是用来存储系统消息的。在Docker中安装MongoDB步稍微有点,大家注意一下。
1.导入镜像文件。你在GIT上找到 MongopB.tar.gz 的镜像文件,然后把它导入Docker里面。
docker load < MongoDB.tar.gz
2.创建容器
创建 /root/mongo/mongod.conf 文件,步骤如下:
使用 cd 命令切换到 /root/mongo 目录。如果该目录不存在,请先创建它:
mkdir -p /root/mongo
cd /root/mongo- 使用文本编辑器创建
mongod.conf文件。这里我们使用vi编辑器作为示例:
vi mongod.conf
net: port: 27017 bindIp: "0.0.0.0" storage: dbPath: "/data/db" security: authorization: enabled
创建容器,
docker run -it -d --name mongo -p 27017:27017 \ --net mynet --ip 172.18.0.8 \ -v /root/mongo:/etc/mongo \ -v /root/mongo/data/db:/data/db \ -m 400m --privileged=true \ -e MONGO_INITDB_ROOT_USERNAME=admin \ -e MONGO_INITDB_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ --entrypoint mongod \ docker.io/mongo --config /etc/mongo/mongod.conf
如果是nta 网格还要配映射端口
正确配置
docker run -it -d --name mongo \ -p 27017:27017 \ --net mynet --ip 172.18.0.8 \ -v /root/mongo:/etc/mongo \ -v /root/mongo/data/db:/data/db \ -m 400m --privileged=true \ -e MONGO_INITDB_ROOT_USERNAME=admin \ -e MONGO_INITDB_ROOT_PASSWORD=abc123456 \ -e TZ=Asia/Shanghai \ docker.io/mongo --config /etc/mongo/mongod.conf
安装好后,远程连接不能上面操作,总是说没有权限,需要用以下方式授权


安装排错
根据您提供的错误信息,当您尝试在 'emos' 数据库上为 'admin' 用户分配 'dbOwner' 角色时,出现了错误,提示无法找到 'admin' 用户。这可能是因为您需要在 'admin' 数据库上为 'admin' 用户分配角色,而不是在 'emos' 数据库上。
请按照以下步骤操作:
-
连接到 MongoDB 容器:
使用docker exec命令再次连接到 MongoDB 容器并启动 MongoDB shell。docker exec -it mongo mongo -
进行身份验证:
在 MongoDB shell 中,使用 'admin' 用户名和密码进行身份验证。use admin db.auth('admin', 'abc123456') -
分配权限:
为 'admin' 用户在 'emos' 数据库上分配 'dbOwner' 角色。您需要在 'admin' 数据库上执行此操作,而不是在 'emos' 数据库上。use admin db.grantRolesToUser('admin', [{ role: 'dbOwner', db: 'emos' }] -
尝试再次插入数据:
分配权限后,尝试再次在 MongoDB shell 中插入数据:use emos db.mycollection.insertOne({name: "John Doe"}) -
退出 MongoDB shell:
完成操作后,您可以使用exit命令退出 MongoDB shell。exit
安装redis
1.创建容器 导入镜向 docker load < Redis.tar.gz
2 创建 /root/redis/conf/redis.conf 文件,然后添加如下内容:
bind 0.0.0.0 protected-mode yes port 6379 tcp-backlog 511 timeout 0 tcp-keepalive 0 loglevel notice logfile "" databases 12 save 900 1 save 300 10 save 60 10000 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir ./ requirepass abc123456
使用Redis 容器并分配内存。
docker run -it -d \ --name redis \ -m 200m \ -p 6379:6379 \ --privileged=true \ --net mynet \ --ip 172.18.0.9 \ -v /root/redis/conf:/usr/local/etc/redis \ -e TZ=Asia/Shanghai \ redis:6.0.10 \ redis-server /usr/local/etc/redis/redis.conf
老规则NAT 网络也要映射一下端口,

启动界面如下

远程连接

2-7安装私有云 Minio
本课程一共用上了两种私有云存储:腾讯云对象存储服务、Minio对象存储服务。这两种对象存储服务都可以用来存储文件。那么为什么不只用其中的一种呢?毕竟腾讯云的对象存储服务是需要我们掏钱的,用Minio不能替代腾讯的对象存储服务吗?
其实完全可以只用Minio对象存储服务的。但是为了加强网络传输文件的安全性,需要给Minio配置HTTPS,这就需要用到数字证书和域名。我们本地电脑没有静态IP,所以就没办法绑定域名,从而无法设置数字证书开启HTTPS。如果司机在小程序上做实名认证的时候,上传的身份证和驾驶证照片通过HTTP协议传输,你觉得安全吗?好在腾讯云对象存储服务默认开启了HTTPS,所以我们把身份证和驾驶证的照片存储在腾讯云上面就很安全
我们开发中好多端口都和9有关,我的代码不会用9开头的端口
先找到教程中Minio.tar.gz 镜像文件,然后用命令导入Docker环境。 docker load< Minio.tar.gz 2.创建容器 我们首先创建 /root/minio/data 文件史,然后给这个文件夹设置权限,否则Minio将无法使用该文件夹保存文件。 中复制代码Bash chmod -R 777/root/minio/data 接下来我们创建容器,运行Minio程序。 docker run -it -d --name minio \ -m 400m \ -p 9000:9000 \ -p 9001:9001 \ --net mynet \ --ip 172.18.0.10 \ -v /root/minio/data:/data \ -e TZ=Asia/Shanghai \ --privileged=true \ -e MINIO_ROOT_USER="root" \ -e MINIO_ROOT_PASSWORD="abc123456" \ bitnami/minio:latest

127.0.0.1:9001/login

安装其它容器。RabbitMQ、Nacos、Sentinel,
2-9 安装其余中间件
本课程用到的中间件还有RabbitMQ、Nacos、Sentinel,所以这节课我们就去安装一下。至于存储代驾行驶线路的实时GPS定位记录,我们需要用HBase和Phoenix,等到讲到相应章节的时候,我们再安装HBase和Phoenix也不令
、安装RabbitMQ
本课程用RabbitMQ缓存系统发出的通知消息,每个用户都有自己的消息队列,而且我们还可以设置消息队列缓存消息的过期时间。这么做就比把消息直接存储到数据库更好。毕竟有很多用户长期不臂录,那么他的消息队列缓存的消息过期也就自动销毁了,可以节省很多存储空间。
.RabbitMO
为什么不使用Kafka,而选用RabbitMQ呢?
因为RabbitMQ和Kafka的读写速度都很快,相差不大,但是RabbitMQ的收发消息更为灵活,支持同步和异步两种收发模式。而且RabbitMQ支持复杂的路由规则,我们可以灵活配置一个消息的广播模式,所以能适配更多的业务场显。你只有多使用RabbitMQ才能体会到它的各种优点。
docker load < RabbitMQ.tar.gz
创建容器
docker run -it -d --name mg \ --net mynet \ --ip 172.18.0.11 \ -p 5672:5672 \ -m 200m \ -e TZ=Asia/Shanghai \ --privileged=true \ rabbitmq
然后docker ps -a 查看容器 。这儿不包括有图形界面
二、安装Nacos
本课程采用了Alibaba SpringCloud微服务架构,所以需要用Nacos作为注册中心:Nacos的作用类似Zookeeper,只不过微服务更加依赖于Nacos服务
1.导入镜像
你在GIT上面找到 Nacos.tar.gz 镜像文件,把它导入Docker之中
中复制代码Bash
docker load< Nacos.tar.gz
2.创建容器
docker run -it -d -p 8848:8848 \ -e MODE=standalone \ --net mynet \ --ip 172.18.0.12 \ -e TIME_ZONE=Asia/Shanghai \ --name nacos nacos/hacos-server
NAT 网络的话需要配置开放端口映射
3.开放端口
我们需要把Linux的8848端口,映射到Windows的8848端口上面。

打开浏览器访问http://localhost:8848/nacos/,在登陆画面填写默认帐户信息:用户名和密码都是 nacos
最后安装限流
三、安装Sentinel
在微服务体系中,我们需要用到Sentinel做限流。Sentinel会监控应用的QPS或并发线程数等指标,当达到指定阈值时对流量进行控制,避免系统被瞬时的流量高峰冲垮,保障应用高可用性。
- 导入镜像
在GIT上面找到 sentinel.tar.gz 镜像文件,然后导入Docker里面。
P复制代码 - docker load<Sentinel.tar.gz
docker run -it -d --name sentinel \ -p 8719:8719 \ -p 8858:8858 \ -net mynet \ --ip 172.18.0.13 \ -e TZ=Asia/Shanghai \ -m 200m \ bladex/sentinel-dashboard

 浙公网安备 33010602011771号
浙公网安备 33010602011771号