Spring源码学习-容器BeanFactory(三) BeanDefinition的创建-解析Spring的默认标签
写在前面
上文Spring源码学习-容器BeanFactory(二) BeanDefinition的创建-解析前BeanDefinition的前置操作中Spring对XML解析后创建了对应的Document对象,处理完profile后终于到了标签的解析,这篇文章主要来探究Spring默认标签的解析。
1.4 BeanDefinition的创建 - 处理Spring默认标签
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
//判断是否是默认的命名标签
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//处理默认的标签
parseDefaultElement(ele, delegate);
}
else {
//处理自定义的标签
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
接上文,进入默认标签的处理,parseDefaultElement()方法
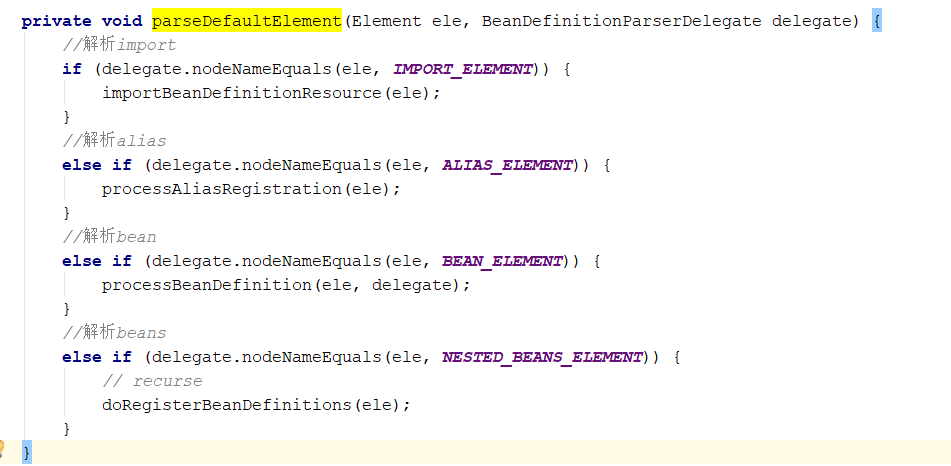
1.4.1 解析import标签
上面都是我们非常熟悉的标签,首先是import标签。其具体功能无需多言,直接进入方法。
protected void importBeanDefinitionResource(Element ele) {
//1.获取resource资源位置,判断是绝对路径还是相对路径
String location = ele.getAttribute(RESOURCE_ATTRIBUTE);
if (!StringUtils.hasText(location)) {
getReaderContext().error("Resource location must not be empty", ele);
return;
}
//获取环境变量,定位资源文件位置
location = getReaderContext().getEnvironment().resolveRequiredPlaceholders(location);
//划重点,创建Hash集合时初始化容器的大小
Set<Resource> actualResources = new LinkedHashSet<Resource>(4);
boolean absoluteLocation = false;
try {
//判断是绝对路径还是相对路径,前者对location进行了classpath开头的判断、尝试性创建java.net.url对象,后者则是转换为URI判断scheme是否存在
absoluteLocation = ResourcePatternUtils.isUrl(location) || ResourceUtils.toURI(location).isAbsolute();
}
catch (URISyntaxException ex) {
}
//2.根据资源位置的不同,创建资源文件,加载对应的BeanDefition
if (absoluteLocation) {
try {
//使用绝对路径直接加载BeanDefinition
int importCount = getReaderContext().getReader().loadBeanDefinitions(location, actualResources);
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from URL location [" + location + "]");
}
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error(
"Failed to import bean definitions from URL location [" + location + "]", ele, ex);
}
}
else {
try {
int importCount;
//使用相对路径创建资源文件,然后加载BeanDefinition
Resource relativeResource = getReaderContext().getResource().createRelative(location);
if (relativeResource.exists()) {
importCount = getReaderContext().getReader().loadBeanDefinitions(relativeResource);
actualResources.add(relativeResource);
}
else {
String baseLocation = getReaderContext().getResource().getURL().toString();
importCount = getReaderContext().getReader().loadBeanDefinitions(
StringUtils.applyRelativePath(baseLocation, location), actualResources);
}
if (logger.isDebugEnabled()) {
logger.debug("Imported " + importCount + " bean definitions from relative location [" + location + "]");
}
}
catch (IOException ex) {
getReaderContext().error("Failed to resolve current resource location", ele, ex);
}
catch (BeanDefinitionStoreException ex) {
getReaderContext().error("Failed to import bean definitions from relative location [" + location + "]",
ele, ex);
}
}
//3.处理完毕后,通知监听器
Resource[] actResArray = actualResources.toArray(new Resource[actualResources.size()]);
getReaderContext().fireImportProcessed(location, actResArray, extractSource(ele));
}
-
Spring首先会判断import标签中,resouce指定的路径是相对路径还是绝对路径,即使用
ResourcePatternUtils.isUrl(location)和ResourceUtils.toURI(location).isAbsolute()两个方法,前者对location进行了classpath开头的判断、尝试性创建java.net.url对象,后者则是转换为URI判断scheme是否存在,针对URL和URI的不同,可以尝试阅读文章URI与URL区别里面讲解的很清楚。 -
第二步很容易理解,根据绝对和相对路径创建Resource对象,递归调用BeanDefinition方法,进行二次解析(从这里也可以得出,如果配置xmlA中import了另一个xmlB,则B中的元素会先被解析,不过知道这点似乎也没什么用...)
-
第三步是一个为用户提供的接口,如果用户想监控某个import标签加载过程的话,可以创建一个
ReaderEventListener接口实现其importProcessed()方法并将其注册进ReaderContext中,而ReaderContext的实现类XmlReaderContext在上篇文章中一处其实就有见到。![]()
当时我还专门说了不再关心范围内,跳过,很是尴尬,但如今从这里来看。创建一个ReaderContext对象就是再次给外部自定义实现的机会,而再看一下上述的监听器'ReaderEventListener'其内部对alisa标签也有监控。这就是Spring被人称为设计精巧、严谨的一处体现吧,处处抽象、封装一环扣一环,令人感叹。
上述只是本人感叹Spring设计的一小段废话,实际上这种设计在Spring中处处可见...就感叹这一次吧
1.4.2 解析alias标签
接下来是alias标签,别名标签我也只是了解,在工作中似乎不是很常用(也可能是我工作时间较短吧)。
protected void processAliasRegistration(Element ele) {
//获取 name alias别名值
String name = ele.getAttribute(NAME_ATTRIBUTE);
String alias = ele.getAttribute(ALIAS_ATTRIBUTE);
boolean valid = true;
if (!StringUtils.hasText(name)) {
getReaderContext().error("Name must not be empty", ele);
valid = false;
}
if (!StringUtils.hasText(alias)) {
getReaderContext().error("Alias must not be empty", ele);
valid = false;
}
if (valid) {
try {
//注册别名
getReaderContext().getRegistry().registerAlias(name, alias);
}
catch (Exception ex) {
getReaderContext().error("Failed to register alias '" + alias +
"' for bean with name '" + name + "'", ele, ex);
}
//激活alias监听器,alias标签解析完毕
getReaderContext().fireAliasRegistered(name, alias, extractSource(ele));
}
}
代码很简单,其实唯一值得一说的就是注册别名的方法。
public void registerAlias(String name, String alias) {
Assert.hasText(name, "'name' must not be empty");
Assert.hasText(alias, "'alias' must not be empty");
//1.如果别名与原名相同,尝试移除已经注册过的别名
if (alias.equals(name)) {
this.aliasMap.remove(alias);
}
else {
String registeredName = this.aliasMap.get(alias);
if (registeredName != null) {
//2.如果该别名已经注册过了,判断上次注册的原名和现在是否一样,如果不一样,抛出异常
if (registeredName.equals(name)) {
// An existing alias - no need to re-register
return;
}
if (!allowAliasOverriding()) {
throw new IllegalStateException("Cannot register alias '" + alias + "' for name '" +
name + "': It is already registered for name '" + registeredName + "'.");
}
}
//3.校验别名与原名称是否有循环依赖
checkForAliasCircle(name, alias);
this.aliasMap.put(alias, name);
}
}
- 如果原名与别名相同,无其他额外的判断,直接移除别名集合中的原别名(一劳永逸,名称相同不需要注册,顺便取消前面其他名字用过此别名)
- 如果别名已经被注册,且原名与现在的不同,报错。接上面对比一下
<alias name='huang.xudong' alias='dunai' />
<alias name='xia.yike' alias='dunai'/>
上述会报错,而
<alias name='huang.xudong' alias='dunai' />
<alias name='dunai' alias='dunai'/>
则不会报错,只是'huang.xudong'的别名配置会失效,'dunai'变为一个独立的bean
3. 校验别名与原名称是否有循环依赖,很简单,具体的方法不再粘贴,就是下面的这种情况。
<alias name='huang.xudong' alias='dunai' />
<alias name='dunai' alias='huang.xudong' />
1.4.3 解析bean标签
接着是重头戏,bean标签的解析,这个标签是我们最常见,且最熟悉的。
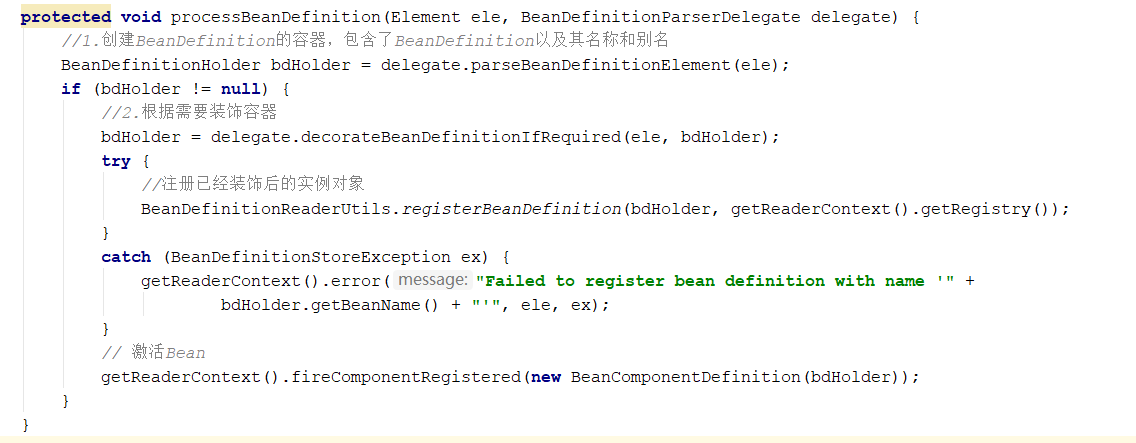
- 解析Bean标签内的核心参数,并返回对应的BeanDefinition的容器
- 根据需要对初解析的Bean标签容器进行二次装饰
- 解析Bean标签完毕,注册BeanDefinition,激活监听器
Bean元素的解析,就不像import和alias那么简单了,我们分三步一点一点的去分析。
1.4.3.1 首先是Bean标签的核心参数解析:
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
//1.获取id和name属性
String id = ele.getAttribute(ID_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//分割name,将其放入集合中。如果无name属性,使用id作为BeanName,否则将集合中第一个作为beanName
List<String> aliases = new ArrayList<String>();
if (StringUtils.hasLength(nameAttr)) {
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
aliases.addAll(Arrays.asList(nameArr));
}
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
if (logger.isDebugEnabled()) {
logger.debug("No XML 'id' specified - using '" + beanName +
"' as bean name and " + aliases + " as aliases");
}
}
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
//2.初步创建BeanDefinition,基本完成大部分属性的解析
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
//处理BeanName和别名信息
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(
beanDefinition, this.readerContext.getRegistry(), true);
}
else {
//如果Bean没有定义名称用默认方式生成BeanName
beanName = this.readerContext.generateBeanName(beanDefinition);
String beanClassName = beanDefinition.getBeanClassName();
if (beanClassName != null &&
beanName.startsWith(beanClassName) && beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
if (logger.isDebugEnabled()) {
logger.debug("Neither XML 'id' nor 'name' specified - " +
"using generated bean name [" + beanName + "]");
}
}
catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
String[] aliasesArray = StringUtils.toStringArray(aliases);
//3.返回BeanDefinition的容器
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
方法参数中的containingBean实际就是父类BeanDefinition,初次创建时为null。方法比较清晰,首先解析id、name,然后将其他的参数解析交给了parseBeanDefinitionElement(),随后封装id、name、BeanDefintion封装至容器中返回。
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));
String className = null;
//获取class属性
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
//parent属性
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
//根据类名创建通用的bean对象
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
//解析bean标签中的各个属性,核心
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
//描述属性
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
//meta标签
parseMetaElements(ele, bd);
//look-up
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
//replaced-method
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
//构造函数
parseConstructorArgElements(ele, bd);
//属性
parsePropertyElements(ele, bd);
//qualifier
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}
catch (ClassNotFoundException ex) {
error("Bean class [" + className + "] not found", ele, ex);
}
catch (NoClassDefFoundError err) {
error("Class that bean class [" + className + "] depends on not found", ele, err);
}
catch (Throwable ex) {
error("Unexpected failure during bean definition parsing", ele, ex);
}
finally {
this.parseState.pop();
}
return null;
}
上述中,常见的Bean标签的属性已经陆续出现了,再继续往下之前,引用书中一段话。

接着回来分析的源码:
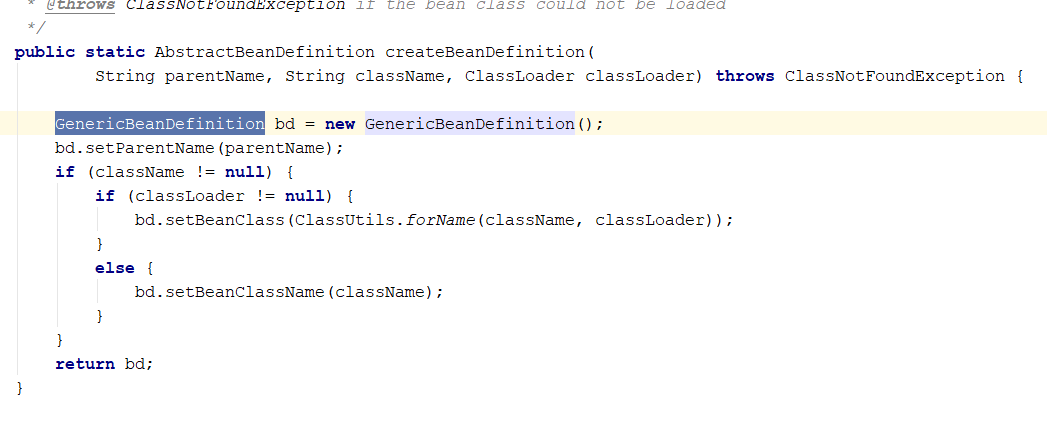
-
获取class信息,创建承载BeanDefinition信息的容器,顺着代码追下去的话就能看到,实例对象的类型是GenericBeanDefinition
![]()
-
解析Bean的行内元素
public AbstractBeanDefinition parseBeanDefinitionAttributes(Element ele, String beanName,
BeanDefinition containingBean, AbstractBeanDefinition bd) {
//singleton 属性
if (ele.hasAttribute(SINGLETON_ATTRIBUTE)) {
error("Old 1.x 'singleton' attribute in use - upgrade to 'scope' declaration", ele);
}
// scope属性
else if (ele.hasAttribute(SCOPE_ATTRIBUTE)) {
bd.setScope(ele.getAttribute(SCOPE_ATTRIBUTE));
}
// 否则使用父BeanDefition的值
else if (containingBean != null) {
bd.setScope(containingBean.getScope());
}
// abstract属性
if (ele.hasAttribute(ABSTRACT_ATTRIBUTE)) {
bd.setAbstract(TRUE_VALUE.equals(ele.getAttribute(ABSTRACT_ATTRIBUTE)));
}
//懒加载 lazy-init属性
String lazyInit = ele.getAttribute(LAZY_INIT_ATTRIBUTE);
if (DEFAULT_VALUE.equals(lazyInit)) {
lazyInit = this.defaults.getLazyInit();
}
bd.setLazyInit(TRUE_VALUE.equals(lazyInit));
// autowire属性
String autowire = ele.getAttribute(AUTOWIRE_ATTRIBUTE);
bd.setAutowireMode(getAutowireMode(autowire));
// depency-check属性
String dependencyCheck = ele.getAttribute(DEPENDENCY_CHECK_ATTRIBUTE);
bd.setDependencyCheck(getDependencyCheck(dependencyCheck));
// depends-on属性
if (ele.hasAttribute(DEPENDS_ON_ATTRIBUTE)) {
String dependsOn = ele.getAttribute(DEPENDS_ON_ATTRIBUTE);
bd.setDependsOn(StringUtils.tokenizeToStringArray(dependsOn, MULTI_VALUE_ATTRIBUTE_DELIMITERS));
}
//autowire-candidate
String autowireCandidate = ele.getAttribute(AUTOWIRE_CANDIDATE_ATTRIBUTE);
if ("".equals(autowireCandidate) || DEFAULT_VALUE.equals(autowireCandidate)) {
String candidatePattern = this.defaults.getAutowireCandidates();
if (candidatePattern != null) {
String[] patterns = StringUtils.commaDelimitedListToStringArray(candidatePattern);
bd.setAutowireCandidate(PatternMatchUtils.simpleMatch(patterns, beanName));
}
}
else {
bd.setAutowireCandidate(TRUE_VALUE.equals(autowireCandidate));
}
// primary属性
if (ele.hasAttribute(PRIMARY_ATTRIBUTE)) {
bd.setPrimary(TRUE_VALUE.equals(ele.getAttribute(PRIMARY_ATTRIBUTE)));
}
//init-method
if (ele.hasAttribute(INIT_METHOD_ATTRIBUTE)) {
String initMethodName = ele.getAttribute(INIT_METHOD_ATTRIBUTE);
if (!"".equals(initMethodName)) {
bd.setInitMethodName(initMethodName);
}
}
else {
if (this.defaults.getInitMethod() != null) {
bd.setInitMethodName(this.defaults.getInitMethod());
bd.setEnforceInitMethod(false);
}
}
// destory-method
if (ele.hasAttribute(DESTROY_METHOD_ATTRIBUTE)) {
String destroyMethodName = ele.getAttribute(DESTROY_METHOD_ATTRIBUTE);
bd.setDestroyMethodName(destroyMethodName);
}
else {
if (this.defaults.getDestroyMethod() != null) {
bd.setDestroyMethodName(this.defaults.getDestroyMethod());
bd.setEnforceDestroyMethod(false);
}
}
// factory-method
if (ele.hasAttribute(FACTORY_METHOD_ATTRIBUTE)) {
bd.setFactoryMethodName(ele.getAttribute(FACTORY_METHOD_ATTRIBUTE));
}
// factory-bean
if (ele.hasAttribute(FACTORY_BEAN_ATTRIBUTE)) {
bd.setFactoryBeanName(ele.getAttribute(FACTORY_BEAN_ATTRIBUTE));
}
return bd;
}
Bean标签内的所有属性在这里全部被注册进去了,到了Bean元素创建时,这些属性我会根据情况再去详解,各位可以百度一下了解。
-
解析Bean标签的各个子标签,与上述差不多,这里选择构造和参数两个标签进行解析,其他的不是很常用只是百度了解一下,后续创建Bean实例对象时遇到再做记录。
3.1 构造函数解析
首先,先放一个简单的构造函数的配置。
<bean id="ThinkPadT_480" class="com.flash.springtest.tap1.Computer" /> <bean id="people" class="com.flash.springtest.People"> <constructor-arg index="0"> <value>流光</value> </constructor-arg> <constructor-arg index="1"> <ref>ThinkPadT_480</ref> </constructor-arg> </bean>上面创建了一个People对象,并调用其People(String name,Computer cpmputer)的构造函数
![构造函数]()
构造函数的单个标签交给了
parseConstructorArgElement()方法,进入此方法。public void parseConstructorArgElement(Element ele, BeanDefinition bd) { //1.获取index/type/name属性的值 String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE); String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE); String nameAttr = ele.getAttribute(NAME_ATTRIBUTE); // 如果设置了index,以index定位构造函数 if (StringUtils.hasLength(indexAttr)) { try { int index = Integer.parseInt(indexAttr); if (index < 0) { error("'index' cannot be lower than 0", ele); } else { try { this.parseState.push(new ConstructorArgumentEntry(index)); //2.解析子元素value、ref等标签 Object value = parsePropertyValue(ele, bd, null); ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value); if (StringUtils.hasLength(typeAttr)) { valueHolder.setType(typeAttr); } if (StringUtils.hasLength(nameAttr)) { valueHolder.setName(nameAttr); } valueHolder.setSource(extractSource(ele)); //3.将index和对应的值放入BeanDefinition中ConstructorArgumentValues下的indexedArgumentValues集合中 if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) { error("Ambiguous constructor-arg entries for index " + index, ele); } else { bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder); } } finally { this.parseState.pop(); } } } catch (NumberFormatException ex) { error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele); } } else { try { this.parseState.push(new ConstructorArgumentEntry()); //解析子元素value、ref Object value = parsePropertyValue(ele, bd, null); ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value); if (StringUtils.hasLength(typeAttr)) { valueHolder.setType(typeAttr); } if (StringUtils.hasLength(nameAttr)) { valueHolder.setName(nameAttr); } valueHolder.setSource(extractSource(ele)); //没有index则将ValueHoler放入BeanDefinition中ConstructorArgumentValues下的 genericArgumentValues 集合中 bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder); } finally { this.parseState.pop(); } } }正因为需要根据不同的参数类型、顺序来定位到具体的构造函数,因此构造函数的解析会稍微复杂一些,但是上面的代码仔细阅读以下还是很容易理解的。
- 获取index、type、name属性值
- 解析value/ref等子标签属性
- 根据是否传入index,将构造属性值放入不同的容器中,这个不同容器的后续处理将会在后面的Bean实例对象创建时看到,这里有个印象即可。
其中比较重要的就是第二部对value和ref子标签的解析。
public Object parsePropertyValue(Element ele, BeanDefinition bd, String propertyName) { String elementName = (propertyName != null) ? "<property> element for property '" + propertyName + "'" : "<constructor-arg> element"; NodeList nl = ele.getChildNodes(); Element subElement = null; //1.获取子元素标签,可能包含list等标签来构建构造函数值 for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); //跳过meta和description标签 if (node instanceof Element && !nodeNameEquals(node, DESCRIPTION_ELEMENT) && !nodeNameEquals(node, META_ELEMENT)) { if (subElement != null) { error(elementName + " must not contain more than one sub-element", ele); } else { subElement = (Element) node; } } } //判断是否包含ref和value属性 boolean hasRefAttribute = ele.hasAttribute(REF_ATTRIBUTE); boolean hasValueAttribute = ele.hasAttribute(VALUE_ATTRIBUTE); //ref和value标签不能同时存在,且如果ref和value存在则不能存在子属性了 if ((hasRefAttribute && hasValueAttribute) || ((hasRefAttribute || hasValueAttribute) && subElement != null)) { error(elementName + " is only allowed to contain either 'ref' attribute OR 'value' attribute OR sub-element", ele); } //2.三种可能出现的属性处理 //ref属性处理 if (hasRefAttribute) { String refName = ele.getAttribute(REF_ATTRIBUTE); if (!StringUtils.hasText(refName)) { error(elementName + " contains empty 'ref' attribute", ele); } RuntimeBeanReference ref = new RuntimeBeanReference(refName); ref.setSource(extractSource(ele)); return ref; } //value属性处理 else if (hasValueAttribute) { TypedStringValue valueHolder = new TypedStringValue(ele.getAttribute(VALUE_ATTRIBUTE)); valueHolder.setSource(extractSource(ele)); return valueHolder; } //子标签处理 else if (subElement != null) { return parsePropertySubElement(subElement, bd); } else { // Neither child element nor "ref" or "value" attribute found. error(elementName + " must specify a ref or value", ele); return null; } }上面代码总体可以理解为下面3点。
1. 判断构造函数的值的来源。Spring对构造函数value的支持主要有3种。value-->普通的String字符、ref-->引用已创建的Bean对象、还有第三种就是子标签(其实狭义上看就是list/map等标签)构造新的对象。上述三种来源只允许使用其中一种。 2. 解析ref和value的属性 ref使用了RuntimeBeanReference封装对象名称返回,思考一下就应该能知道后续在创建对象时从此对象中取出beanName从容器中获得对应的实例对象注入即可,后续可以再关注一下。 value则使用了TypedStringValue封装value属性值返回。 3. 解析子标签。 子标签的方法是一个通用性的功能方法,思考一下不难猜到接下来属性参数的解析应该也是离不开它的。其代码如下 ``` public Object parsePropertySubElement(Element ele, BeanDefinition bd, String defaultValueType) { //不是spring默认的标签,使用自定义标签解析,后续一起看 if (!isDefaultNamespace(ele)) { return parseNestedCustomElement(ele, bd); } //bean标签解析 else if (nodeNameEquals(ele, BEAN_ELEMENT)) { BeanDefinitionHolder nestedBd = parseBeanDefinitionElement(ele, bd); if (nestedBd != null) { nestedBd = decorateBeanDefinitionIfRequired(ele, nestedBd, bd); } return nestedBd; } //ref标签解析 else if (nodeNameEquals(ele, REF_ELEMENT)) { String refName = ele.getAttribute(BEAN_REF_ATTRIBUTE); boolean toParent = false; if (!StringUtils.hasLength(refName)) { refName = ele.getAttribute(LOCAL_REF_ATTRIBUTE); if (!StringUtils.hasLength(refName)) { refName = ele.getAttribute(PARENT_REF_ATTRIBUTE); toParent = true; if (!StringUtils.hasLength(refName)) { error("'bean', 'local' or 'parent' is required for <ref> element", ele); return null; } } } if (!StringUtils.hasText(refName)) { error("<ref> element contains empty target attribute", ele); return null; } RuntimeBeanReference ref = new RuntimeBeanReference(refName, toParent); ref.setSource(extractSource(ele)); return ref; } //idref标签 else if (nodeNameEquals(ele, IDREF_ELEMENT)) { return parseIdRefElement(ele); } //value标签 else if (nodeNameEquals(ele, VALUE_ELEMENT)) { return parseValueElement(ele, defaultValueType); } //null标签 else if (nodeNameEquals(ele, NULL_ELEMENT)) { TypedStringValue nullHolder = new TypedStringValue(null); nullHolder.setSource(extractSource(ele)); return nullHolder; } //array标签 else if (nodeNameEquals(ele, ARRAY_ELEMENT)) { return parseArrayElement(ele, bd); } //list标签 else if (nodeNameEquals(ele, LIST_ELEMENT)) { return parseListElement(ele, bd); } //set标签 else if (nodeNameEquals(ele, SET_ELEMENT)) { return parseSetElement(ele, bd); } //map标签 else if (nodeNameEquals(ele, MAP_ELEMENT)) { return parseMapElement(ele, bd); } //props标签 else if (nodeNameEquals(ele, PROPS_ELEMENT)) { return parsePropsElement(ele); } else { error("Unknown property sub-element: [" + ele.getNodeName() + "]", ele); return null; } } ``` 上面已经经历过很多标签的解析,到这里一切都变得简单明了,Spring中默认的常用标签都在此列了。 至此Spring构造函数的解析,经过几个方法的嵌套终于走完了,看起来很繁琐,初次阅读源码的人很容易感觉头大,但是如果能沉下心仔细跟读几次,其实还是很简单的(毕竟只是一个读取的过程,还有没开始真正的实例对象创建)。3.2 属性参数解析
跟构造函数解析一样,在看代码之前先贴一下Spring属性标签的例子。
<bean id="ThinkPadT_480" class="com.flash.springtest.tap1.Computer" /> <bean id="people" class="com.flash.springtest.tap1.People"> <property name="name" value="流光" /> <property name="computer" ref="ThinkPadT_480" /> <!-- 做白日梦呢... --> <property name="cars"> <list> <value>奔驰</value> <value>法拉利</value> </list> </property> </bean>上面的配置创建了一个People对象,并为其name、computer、cars以三种方式注入了值,具体源码里是怎么做的呢?
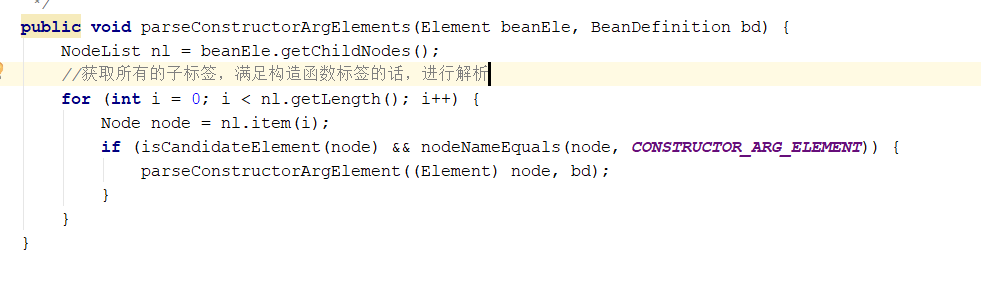
public void parsePropertyElements(Element beanEle, BeanDefinition bd) { NodeList nl = beanEle.getChildNodes(); for (int i = 0; i < nl.getLength(); i++) { Node node = nl.item(i); if (isCandidateElement(node) && nodeNameEquals(node, PROPERTY_ELEMENT)) { parsePropertyElement((Element) node, bd); } } } public void parsePropertyElement(Element ele, BeanDefinition bd) { //获取name属性 String propertyName = ele.getAttribute(NAME_ATTRIBUTE); if (!StringUtils.hasLength(propertyName)) { error("Tag 'property' must have a 'name' attribute", ele); return; } this.parseState.push(new PropertyEntry(propertyName)); try { if (bd.getPropertyValues().contains(propertyName)) { error("Multiple 'property' definitions for property '" + propertyName + "'", ele); return; } //解析属性参数值,与构造函数解析时一样的逻辑 Object val = parsePropertyValue(ele, bd, propertyName); PropertyValue pv = new PropertyValue(propertyName, val); parseMetaElements(ele, pv); pv.setSource(extractSource(ele)); bd.getPropertyValues().addPropertyValue(pv); } finally { this.parseState.pop(); } }属性值的解析与构造函数极其相似,不过是将解析后的Object放入PropertyValue中罢了。
至此Spring中默认的标签解析,至此就告一段落了。
1.4.3.2 根据需要装饰已经初步创建的BeanDefinitionHolder
读取完Bean标签Spring默认的属性后,我们再次回到Bean标签解析的起点。
在读取完Bean标签的属性和子标签后,Spring又执行了一个额外的“装饰”方法。在讲装饰方法之前我们先看一下下面的Bean的配置
<bean id="a" class="com.flash.test.A" flash="流光" >
<flash:stuednt key:com.flash.springtest.dto.Student/>
</bean>
大家思考一下,上面的bean标签经过解析后,id、class属性自然没问题,而flash这个属性以及下面的flash:student这个这个子标签怎么办呢?其实装饰方法就是为了bean标签下的自定义属性和自定义子标签使用的,代码如下:
在Bean子标签解析时,如果子标签类型也为Bean解析完默认标签后也会调用此方法进行子bean自定义标签的解析哦
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(Element ele, BeanDefinitionHolder definitionHolder) {
return decorateBeanDefinitionIfRequired(ele, definitionHolder, null);
}
public BeanDefinitionHolder decorateBeanDefinitionIfRequired(
Element ele, BeanDefinitionHolder definitionHolder, BeanDefinition containingBd) {
BeanDefinitionHolder finalDefinition = definitionHolder;
//用户自定义的属性装饰
NamedNodeMap attributes = ele.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node node = attributes.item(i);
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
//用户自定义子标签装饰
NodeList children = ele.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node node = children.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
finalDefinition = decorateIfRequired(node, finalDefinition, containingBd);
}
}
return finalDefinition;
}
代码很简单,再次循环所有的属性和子标签,统一使用decorateIfRequired()来解析。进入此方法:
public BeanDefinitionHolder decorateIfRequired(
Node node, BeanDefinitionHolder originalDef, BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(node);
if (!isDefaultNamespace(namespaceUri)) {
//如果不是Spring默认标签,获取用户自定义标签解析类,执行自定义标签解析
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler != null) {
return handler.decorate(node, originalDef, new ParserContext(this.readerContext, this, containingBd));
}
else if (namespaceUri != null && namespaceUri.startsWith("http://www.springframework.org/")) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", node);
}
else {
// A custom namespace, not to be handled by Spring - maybe "xml:...".
if (logger.isDebugEnabled()) {
logger.debug("No Spring NamespaceHandler found for XML schema namespace [" + namespaceUri + "]");
}
}
}
return originalDef;
}
至此,我们提前看到了Spring对自定义标签的解析方法,具体不再跟进,等到下篇文章我们走完Spring默认标签解析(本文开头可查看默认标签解析的入口方法),进入自定义标签时再详细分析。
1.4.3.3 注册BeanDefinition,激活监听器
public void registerBeanDefinition(String beanName, BeanDefinition beanDefinition)
throws BeanDefinitionStoreException {
Assert.hasText(beanName, "Bean name must not be empty");
Assert.notNull(beanDefinition, "BeanDefinition must not be null");
if (beanDefinition instanceof AbstractBeanDefinition) {
try {
((AbstractBeanDefinition) beanDefinition).validate();
}
catch (BeanDefinitionValidationException ex) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Validation of bean definition failed", ex);
}
}
BeanDefinition oldBeanDefinition;
//校验beanName是否已经被注册
oldBeanDefinition = this.beanDefinitionMap.get(beanName);
if (oldBeanDefinition != null) {
// 如果该BeanName已经被注册,且不允许覆盖,直接抛出异常
if (!isAllowBeanDefinitionOverriding()) {
throw new BeanDefinitionStoreException(beanDefinition.getResourceDescription(), beanName,
"Cannot register bean definition [" + beanDefinition + "] for bean '" + beanName +
"': There is already [" + oldBeanDefinition + "] bound.");
}
else if (oldBeanDefinition.getRole() < beanDefinition.getRole()) {
// e.g. was ROLE_APPLICATION, now overriding with ROLE_SUPPORT or ROLE_INFRASTRUCTURE
if (this.logger.isWarnEnabled()) {
this.logger.warn("Overriding user-defined bean definition for bean '" + beanName +
"' with a framework-generated bean definition: replacing [" +
oldBeanDefinition + "] with [" + beanDefinition + "]");
}
}
else if (!beanDefinition.equals(oldBeanDefinition)) {
if (this.logger.isInfoEnabled()) {
this.logger.info("Overriding bean definition for bean '" + beanName +
"' with a different definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
else {
if (this.logger.isDebugEnabled()) {
this.logger.debug("Overriding bean definition for bean '" + beanName +
"' with an equivalent definition: replacing [" + oldBeanDefinition +
"] with [" + beanDefinition + "]");
}
}
//以beanName为key放入集合中
this.beanDefinitionMap.put(beanName, beanDefinition);
}
else {
if (hasBeanCreationStarted()) {
// Cannot modify startup-time collection elements anymore (for stable iteration)
//如果容器已经处于创建bean实例对象环节,加上同步锁
synchronized (this.beanDefinitionMap) {
this.beanDefinitionMap.put(beanName, beanDefinition);
List<String> updatedDefinitions = new ArrayList<String>(this.beanDefinitionNames.size() + 1);
updatedDefinitions.addAll(this.beanDefinitionNames);
updatedDefinitions.add(beanName);
this.beanDefinitionNames = updatedDefinitions;
if (this.manualSingletonNames.contains(beanName)) {
Set<String> updatedSingletons = new LinkedHashSet<String>(this.manualSingletonNames);
updatedSingletons.remove(beanName);
this.manualSingletonNames = updatedSingletons;
}
}
}
else {
// Still in startup registration phase
//如果容器仍然在注册阶段
this.beanDefinitionMap.put(beanName, beanDefinition);
this.beanDefinitionNames.add(beanName);
this.manualSingletonNames.remove(beanName);
}
this.frozenBeanDefinitionNames = null;
}
//如果有已经注册的Bean或者已经创建的单例Bean实例对象,重置BeanDefinition(销毁前面的对象)
if (oldBeanDefinition != null || containsSingleton(beanName)) {
resetBeanDefinition(beanName);
}
}
Bean的注册代码相对来说比较绕一下,因为它涉及了Bean实例化时可能出现的情形。具体如下:
-
再次校验BeanDefinition的类型,并判断BeanName是否已经被注册,且从判断出的逻辑可知BeanDefinition其实就是放置在DefaultableBeanFatory中beanDefinitionMap集合中。
-
如果BeanDefinition没有注册。Spring会判断是否允许BeanDefinition的注册,默认为允许,并进行注册。如果用户手动改变,则会抛出异常。
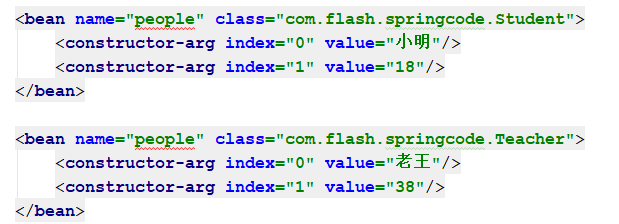
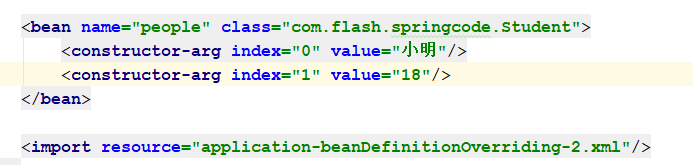
有的人在这里就会疑惑了,Spring不是不允许同名的Bean吗,为什么还有覆盖这一说。并且在前面XML文件解析的时候不是已经有判断同名的问题的问题了吗?其实两个还是有区别的,如果从XML作为配置文件狭义角度来讲的话,如下面两个配置:
![]()
![]()
图一是会报错的,而如果把第二个Bean的属性放入另一个xml并导入后就不会报错了,而是会用新的Bean替换掉老的Bean,正是满足了上面代码处的条件。他们到底有什么区别呢?如果仔细阅读过这篇文章并仔细思考一下,不难得到答案。
-
激活监听器,此处与import,alias标签一样不再多言。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号