python之collection模块
一、总览
在内置数据类型(int、float、complex、dict、list、set、tuple)的基础上, collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。 1.namedtuple: 生成可以使用名字来访问元素内容的tuple 2.deque: 双端队列,可以快速的从另外一侧追加和推出对象 3.OrderedDict: 有序字典 4.defaultdict: 带有默认值的字典 5.Counter: 计数器,主要用来计数
二、namedtuple:可命名元组
from collections import namedtuple time = namedtuple('My_time',['hour','minute','second']) t1 = time(17,50,30) print(t1) # My_time(hour=17, minute=50, second=30) print(t1.hour) # 17 print(t1.minute) # 50 print(t1.second) # 30 可命名元组非常类似一个只有属性没有方法的类, 这个类最大的特点就是一旦实例化不能修改属性的值, 可命名元组不能用索引取值了,只能用属性取值, ['hour','minute','second']是对象属性名, My_time是类的名字。
三、deque:双端队列
list的缺点:list在插入元素(insert)的时候是非常慢的,因为你插入一个元素,那么此元素后面的所有元素索引都得改变, 当数据量很大的时候,那么速度就很慢了。 双端队列:可以弥补List的这个缺点 双端队列:deque除了实现list的append()和pop()外, 还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。 (实际上双端队列等于是一个可以从左或者右新增删除的列表,列表所有的方法,它也全有) 需要注意的是:deque的pop只能删除最后一个元素,不支持列表的那种根据索引删除pop(index) from collections import deque dq = deque([1,2,3]) dq.append(4) dq.append(5) dq.appendleft(6) print(dq) # deque([6, 1, 2, 3, 4, 5]) print(dq.pop()) # 5 print(dq.popleft()) # 6 dq.extend("zxcv") dq.extendleft([6, 7, 8]) dq.insert(1, "zbj") del dq[2] dq.clear()
双端队列原理图:
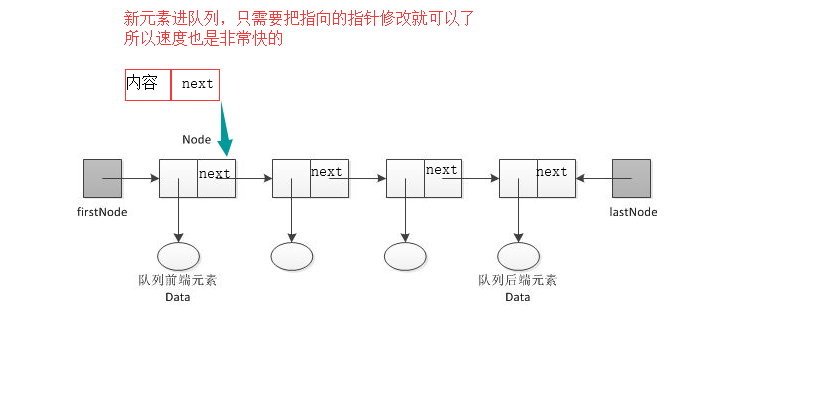
3-2、再了解一下正常的队列 队列是遵循先进先出的原则(单向的),应用场景:抢票系统 import queue q = queue.Queue() # 队列对象 q.put(1) # 往队列存元素 q.put(2) q.put('a') q.put([1,2,3]) print(q.get()) # 1 取元素 print(q.get()) # 2 print(q.get()) # a
四、OrderedDict:让字典有序
# python3.6之前,字典的Key是无序的(3.6之后字典默认有序,无需用此方法,但是很多公司未必都是在用3.6的版本), # 在对dict做迭代时,我们无法确定Key的顺序,如果要保持Key的顺序,可以用OrderedDict。 # 首先说明一下普通字典的创建,可以使用面向对象的方式创建: dic1 = dict({'a': 1, 'b': 2}) # 括号里面直接写字典 dic2 = dict([('c', 3), ('d', 4)]) # 括号里面写列表,列表每一个元素是二元组,每个元组是字典的键和值 print(dic1) # {'a': 1, 'b': 2} print(dic2) # {'c': 3, 'd': 4} from collections import OrderedDict order_dic = OrderedDict(a=1, b=2) # 也可以这样创建:order_dic = OrderedDict([('a', 1), ('b', 2)]) # 也可以这样创建:order_dic = OrderedDict({'a':1,'b':2}) print(order_dic) # OrderedDict([('a', 1), ('b', 2)]) for key in order_dic: print(key, order_dic[key]) order_dic['c'] = 3 print(order_dic) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
五、defaultdict:为字典设置默认值
from collections import defaultdict dic = defaultdict(list) # 为字典设置默认值为空列表(defaultdict里面的参数必须是可调用的) # dic = defaultdict(1) # 报错,因为数字 1 不可调用 print(dic['a']) # [] dic['b'].append(2) print(dic['b']) # [2] # 可与匿名函数结合使用,设置任何默认值 dic = defaultdict(lambda :'none') # lambda返回什么值都可以 print(dic['a']) # none print(dic) # {'a': 'none'} dic['b'] = 2 print(dic) # {'a': 'none', 'b': 2} 例子:有如下值集合 [11,22,33,44,55,66,77,88,99,90],将所有大于 66 的值保存至字典的第一个key中, 将小于 66 的值保存至第二个key的值中。 即: {'k1': 大于66 , 'k2': 小于66} 1、用正常的字典做 lst = [11, 22, 33,44,55,66,77,88,99,90] dic = {} for num in lst: if num > 66: if 'k1' not in dic: dic['k1'] = [num] else: dic['k1'].append(num) elif num < 66: if 'k2' not in dic: dic['k2'] = [num] else: dic['k2'].append(num) print(dic) 2、使用字典的默认值 from collections import defaultdict lst = [11, 22, 33,44,55,66,77,88,99,90] dic = defaultdict(list) for num in lst: if num > 66: dic['k1'].append(num) elif num < 66: dic['k2'].append(num) print(dic)
六、Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储, 其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。 from collections import Counter c = Counter('aaasasabssbba') print(c) # Counter({'a': 6, 's': 4, 'b': 3})

 浙公网安备 33010602011771号
浙公网安备 33010602011771号