python之动态参数 *args,**kwargs和命名空间
一、函数的动态参数 *args,**kwargs, 形参的顺序
1、你的函数,为了拓展,对于传入的实参数量应该是不固定,
所以就需要用到万能参数,动态参数,*args, **kwargs
1,*args 将所有实参的位置参数聚合到一个元组,并将这个元组赋值给args
(起作用的是* 并不是args,但是约定俗成动态接收实参的所有位置参数就用args)
def sum1(*args): print(args) sum1(1, 2, ['hello']) # 是一个元组(1, 2, ['hello'])
2,**kwargs 将所有实参的关键字参数聚合到一个字典,并将这个字典赋值给kwargs
(起作用的是** 并不是kwargs,但是约定俗成动态接收实参的所有关键字参数就用kwargs)
def fun(*args, **kwargs): print(args) print(kwargs) fun(1, 2, ['a', 'b'], name='xiaobai', age=18) # 结果: # (1, 2, ['a', 'b']) # 位置参数,元组 # {'name': 'xiaobai', 'age': 18} # 关键字参数,字典
2、*的用法
在函数的定义时,*位置参数,**关键字参数--->聚合。
在函数的调用(执行)时,*位置参数,**关键字参数--->打散。
实参--->*位置参数--->把位置参数打散成最小的元素,然后一个个添加到args里组成一个元组
l1 = [1, 2, 3] l2 = [111, 22, 33, 'xiaobai'] # 如果要将l1,l2通过函数整合到一起 # 方法一(实参不用*): def func1(*args): return args[0] + args[1] print(func1(l1, l2)) # [1, 2, 3, 111, 22, 33, 'xiaobai'] # 方法二(实参用*):实参使用*打散 def func1(*args): return args print(func1(*l1, *l2)) # (1, 2, 3, 111, 22, 33, 'xiaobai')
实参--->**关键字参数--->把关键字参数打散成最小的元素,然后一个个添加到kwargs里组成一个字典
def func1(**kwargs): print(kwargs) # func1(name='xiaobai',age=18,job=None,hobby='girl') func1(**{'name': 'xiaobai', 'age': 18}, **{'job': None, 'hobby': 'girl'}) # 结果: # {'name': 'xiaobai', 'age': 18, 'job': None, 'hobby': 'girl'}
3、形参的顺序(a--->b,代表的顺序是写参数时,要先写a再写b)
位置参数--->默认参数
def func(a, b, sex='男'): print(sex) func(100, 200)
位置参数--->*args--->默认参数
def func(a, b, *args, sex='男'): print(a, b) print(args) print(sex) func(100, 200, 1, 2, 34, 5, '女', 6) # 结果: # 100 200 # a,b # (1, 2, 34, 5,'女',6) # args # 男 # 默认参数
位置参数--->*args--->默认参数--->**kwargs
def func(a, b, *args, sex='男', **kwargs): print(a, b) print(args) print(sex) print(kwargs) func(100, 200, 1, 2, 34, 5, 6, sex='女', name='xiaobai', age=1000) func(100, 200, 1, 2, 34, 5, 6, name='xiaobai', age=1000, sex='女') # 两个的结果都是: # 100 200 # a,b # (1, 2, 34, 5, 6) # args # 女 # 默认参数修改后的值 # {'name': 'xiaobai', 'age': 1000} # kwargs # 若是形参这样写: def func(a, b, *args, **kwargs, sex='男'): print(a, b) print(args) print(sex) print(kwargs) func(100, 200, 1, 2, 34, 5, 6, name='xiaobai', age=1000, sex='女') # 结果:会报错,默认参数一定要写在kwargs前面
二、命名空间
''' 我们首先回忆一下Python代码运行的时候遇到函数是怎么做的,从Python解释器开始执行之后,就在内存中开辟里一个空间,每当遇到一个变量的时候, 就把变量名和值之间对应的关系记录下来,但是当遇到函数定义的时候,解释器只是象征性的将函数名读入内存,表示知道这个函数存在了,至于函数内部的变量和逻辑,解释器根本不关心。 等执行到函数调用的时候,Python解释器会再开辟一块内存来储存这个函数里面的内容,这个时候,才关注函数里面有哪些变量,而函数中的变量会储存在新开辟出来的内存中, 函数中的变量只能在函数内部使用,因为随着函数执行完毕,这块内存中的所有内容也会被清空。 我们给这个‘存放名字与值的关系’的空间起了一个名字-------命名空间。 代码在运行开始,创建的存储“变量名与值的关系”的空间叫做全局命名空间; 在函数的运行中开辟的临时的空间叫做局部命名空间。 '''
1、python中,命名空间分三种:
- 全局命名空间
- 局部命名空间(临时)
- 内置命名空间
*内置命名空间中存放了python解释器为我们提供的名字:input,print,str,list,tuple...它们都是我们熟悉的,拿过来就可以用的方法。
2、作用域:
- 全局作用域:全局命名空间 内置命名空间
- 局部作用域:局部命名空间(临时)
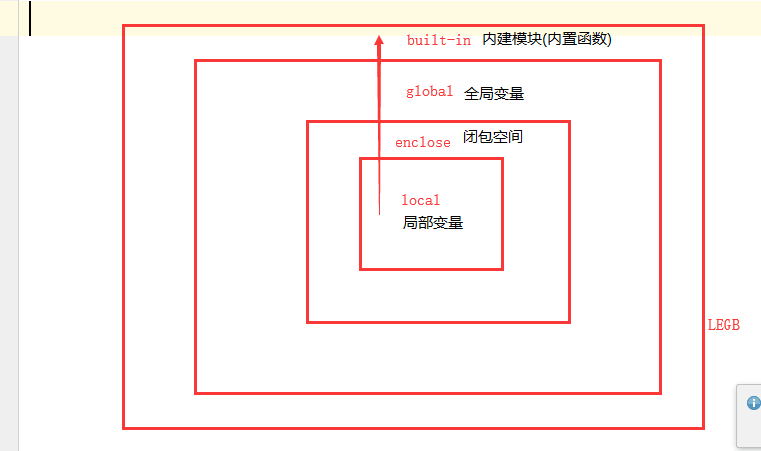
3、取值顺序: 就近原则(LEGB)
局部命名空间 ----> 全局命名空间 ----->内置命名空间 单向 从小到大范围
也就是说:
在局部调用时取值顺序是:局部命名空间->全局命名空间->内置命名空间
在全局调用时取值顺序是:全局命名空间->内置命名空间
len = 6 # 设置全局变量 而且len也在内置命名空间中 def func1(): len = 3 # 设置局部变量 return len print(func1()) # 返回的len值是局部命名空间的值:3
4、加载顺序
内置命名空间(程序运行前加载) ----> 全局命名空间(程序运行中:从上到下加载) --- > 局部命名空间(当函数调用的时候)
三、global,nonlocal
1、在局部命名空间 可以引用全局命名空间的变量,但是不能改变它的值
count = 1 def func1(): print(count) func1() # 引用全局命名空间的变量,结果为:1 count2 = 1 def func1(): count2 += 1 print(count2) func1() # 会报错,因为在局部命名空间中不能直接修改全局命名空间的变量 # 如果你在局部名称空间对一个变量进行修改,那么解释器会认为你的这个变量在局部中已经定义了, # 但是对于上面的例题,局部中没有定义,所以就会报错。
2、global
- 在局部命名空间声明一个全局变量。
- 在局部作用域想要对全局作用域的全局变量进行修改时,需要用到global(限于字符串,数字)。
def fun(): global a # 声明了一个全局变量a。 a = 3 fun() # 调用函数后,就生成了全局变量a,不会因为函数的结束而释放掉。 print(a) # 3 count = 1 # 全局变量count def fun(): global count # 在局部作用域想要对全局作用域的全局变量进行修改时,用global声明。 count += 1 fun() print(count) # 2
ps:对于在全局命名空间的可变数据类型(list,dict,set)可以直接引用并修改不用通过global。
但是函数内部(局部命名空间)的可变数据类型在没有global的声明下,全局命名空间也是不可以调用的。
li = [1, 2, 3] # 全局命名空间的可变数据类型 dic = {'name': 'sb'} def change(): li.append('hello') # 在局部命名空间直接引用并修改 dic['age'] = 18 change() print(li) # [1, 2, 3, 'hello'] print(dic) # {'name': 'sb', 'age': 18} def fun(): l1 = [1, 2, 3] # 局部名称空间的可变数据类型 fun() l1.append(4) print(l1) # 报错,name 'l1' is not defined def fun2(): global l2 # 局部名称空间用global声明可变数据类型 l1 l2 = [1, 2, 3] fun2() l2.append(4) print(l2) # [1, 2, 3, 4]
3、nonlocal
- 此变量声明的变量不能是全局变量,它不能修改全局变量。
- 子函数对父函数的变量进行修改。(在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的是哪一层,就从那一层及以下此变量全部发生改变。)
例子:
def func1(): count = 666 def inner(): print(count) # 666 def func2(): nonlocal count # 这里如果不声明nonlocal,那么可以引用父函数的conut值,但是不能修改否则就会报错 count += 1 print('func2', count) # func2 667 func2() print('inner', count) # inner 667 inner() print('func1', count) # func1 667 func1()
四、函数的嵌套
1、函数的嵌套定义
def f1(): print("in f1") def f2(): print("in f2") f2() f1() # in f1 # in f2 def f1(): def f2(): def f3(): print("in f3") print("in f2") f3() print("in f1") f2() f1() # in f1 # in f2 # in f3
2、函数的嵌套调用
def max1(x, y): m = x if x > y else y return m def max2(a, b, c, d): res1 = max1(a, b) res2 = max1(res1, c) res3 = max1(res2, d) return res3 print(max2(23, -7, 31, 11)) # 31

 浙公网安备 33010602011771号
浙公网安备 33010602011771号