python之数据类型补充、集合、深浅copy
一、编码补充
代码块: 一个函数,一个模块,一个类,一个文件,交互模式下,每一行就是一个代码块。 id()查询对象的内存地址 == 比较的是两边的数值。 is 比较的是两边的内存地址。 小数据池: 前提:int,str,bool 1,节省内存。 2,提高性能和效率。 小数据池是什么? 在内存中,创建一个'池',提前存放了 -5 ~256 的整数,一定规则的字符串和bool值。 后续程序中,如果设置的变量指向的是小数据池的内容,那么就不会再内存中重新创建。 小数据池与代码块的关系。 同一个代码块:python在执行时,遇到了初始化对象命令,他会将这个变量名和数值放到一个字典中, 再次遇到他会从这字典中寻找。 不同代码块:python在执行时,直接从小数据池中寻找,满足条件id相同。 编码: python3x: 英文: str: 表现形式:s1 = 'hello' 内部编码方式: unicode bytes:表现形式:s1 = b'hello' 内部编码方式: 非unicode 中文: str: 表现形式:s1 = '小白' 内部编码方式: unicode bytes:表现形式:s1 = b'\xe2\xe2\xe2\xe2\xe2\xe2' 内部编码方式: 非unicode 只有当你想要存储一些内容到文件中,或者通过网络传输时,才要用的bytes类型 str --->bytes: encode bytes--->str: decode
补充:
s1 = '小黑' b1 = s1.encode('gbk') print(b1) # gbk的bytes类型 # gbk的bytes类型 -----> utf-8的bytes类型,正常情况是这样转换: s2 = b1.decode('gbk') # 先按照对应的编码方式 解码成字符串(unicode) b2 = s2.encode('utf-8') # 再编码成utf-8的bytes print(b2)
非中文的字符串还可以这样解码:
s1 = 'xiaoming' b1 = s1.encode('gbk') #gbk的bytes类型 s2 = b1.decode('utf-8') #可以按照utf-8的形式解码 print(s2) # 上面代码能成立:因为utf-8 gbk,unicode等编码的英文字母,数字,特殊字符都是映射的ASCII码。
二、基础数据类型补充
1、元组
如果元组中只有一个数据,且没有逗号,那么该"元组"的数据类型与里面的数据类型一致
否则,该数据类型就是元组
tu1 = (1) print(tu1,type(tu1)) # 1 <class 'int'> tu1 = (1,) print(tu1,type(tu1)) # (1,) <class 'tuple'> tu2 = ('hello') print(tu2,type(tu2)) # hello <class 'str'> tu2 = ('hello',) print(tu2,type(tu2)) # ('hello',) <class 'tuple'>
2、列表
列表与列表可以相加(就是拼接)
l1 = [1,2,3]
l2 = ['aa','bb']
l3 = l1 + l2
print(l3) --->[1, 2, 3, 'aa', 'bb']
li = [11, 22, 33, 44, 55, 66, 77, 88]
将列表中索引为奇数的元素,全部删除.
也许刚接触的时候会有人这么写:
li = [11, 22, 33, 44, 55, 66, 77, 88] # 问题代码1: for i in li: if li.index(i) % 2 == 1: li.remove(i) print(li) # 问题代码2: for i in range(len(li)): if i % 2 == 1: li.pop(i) print(li)
但是你会发现这样做并不能实现结果,要么报错,要么实现不了预想的结果,为什么呢?
这是因为:在循环一个列表时,如果对列表中的某些元素进行删除,
那么此元素后面的所有元素就会向前进一位,他们的索引和长度就会发生变化。
所以正确的方法可以这样写:
li = [11, 22, 33, 44, 55, 66, 77, 88] # 方法一:切片+步长删除 del li[1::2] print(li) # 方法二: l2 = [] for i in range(len(li)): if i % 2 == 0: l2.append(li[i]) li = l2 print(li) # 方法三:倒着删除 for index in range(len(li)-1, -1, -1): if index % 2 == 1: li.pop(index) print(li)
总结:在循环一个列表时,最好不要对此列表进行改变大小(增删)的操作。
3、字典
1.创建字典的几种方式
dic1 = {'name': 'hello', 'age': 18} # {'name': 'hello', 'age': 18}
dic2 = dict({'home': 'huizhou'}) # {'home': 'huizhou'}
dic3 = dict([('higth', 183), ('long', 18)]) # {'higth': 183, 'long': 18}
dic4 = dict((('weight', 140), ('good', 'yes'))) # {'weight': 140, 'good': 'yes'}
# 迭代创建(第一个参数是可迭代对象,str list dict等)
dic5 = dict.fromkeys([1, 2, 3], 'hi') # {1: 'hi', 2: 'hi', 3: 'hi'}
2.fromkeys的陷阱
dict.fromkeys()方法迭代创建的字典,迭代的键都是指向同一个内存地址(值相同),即键不同,但值是同一个值
(1) dic = dict.fromkeys([1, 2, 3], 'hello') print(dic) print(id(dic[1])) print(id(dic[2])) print(id(dic[3])) 结果: {1: 'hello', 2: 'hello', 3: 'hello'} 1604999043984 1604999043984 1604999043984 (2) dic = dict.fromkeys([1, 2, 3], []) print(dic) 这样创建的是值为空列表的字典: {1: [], 2: [], 3: []} dic[1].append('nihao') print(dic) print(id(dic[1])) print(id(dic[2])) print(id(dic[3])) 结果: {1: ['nihao'], 2: ['nihao'], 3: ['nihao']} 2347486287880 2347486287880 2347486287880 dic[2].append('I am fine') print(dic) print(id(dic[1])) print(id(dic[2])) print(id(dic[3])) 结果: {1: ['nihao', 'I am fine'], 2: ['nihao', 'I am fine'], 3: ['nihao', 'I am fine']} 2347486287880 2347486287880 2347486287880
3.循环字典的时候,不能删除字典的键值对
dic = {'key1': 'value1', 'key2': 'value2', 'k3': 'v3', 'name': 'aaa'}
# 将dic的键中含有k元素的所有键值对删除。
# 错误代码:
for key in dic:
if 'k' in key:
dic.pop(key)
print(dic)
# 这样写会报错dictionarychangedsizeduringiteration
# 这是因为在循环一个字典时,不能改变字典的大小,否则就会报错。
# 正确方法可以:
l1 = []
for key in dic:
if 'k' in key:
l1.append(key)
for key in l1: # 第二次循环的是含有'k'的所有键组成的一个列表,并在循环列表的时候删除字典里的键值对
dic.pop(key)
print(dic)
三、数据类型的转换
''' int str bool 三者转换 str <---> bytes str <---> list dict.keys() dict.values() dict.items() list() tuple <---> list dict ---> list ''' # str ---> list: str.split() s1 = 'aa bb cc' l1 = s1.split() print(l1) # ['aa', 'bb', 'cc'] # list ---> str: "xx".join(list) 此list中的元素全部是str类型才可以转换 l1 = ['aa', 'bb', 'cc'] s2 = ' '.join(l1) print(s2) # aa bb cc # list ---> tuple l1 = [1, 2, 3] tu1 = tuple(l1) print(tu1) # (1, 2, 3) # tuple ---> list tu2 = (0, 2, 3) l1 = list(tu2) print(l1) # [0, 2, 3] # dict ---> list dic1 = {'name': 'Xai', 'age': 1000} l1 = list(dic1) # ['name', 'age'] l2 = list(dic1.keys()) # ['name', 'age'] l3 = list(dic1.values()) # ['Xai', 1000] l4 = list(dic1.items()) # [('name', 'Xai'), ('age', 1000)]
四、集合set
1、集合介绍
set: {'aa', 'bb', 1, 2, 3}
集合要求里面的元素必须是不可变的数据类型,但是集合本身是可变的数据类型。
集合里面的元素不重复(天然去重),无序。
主要用途:
1,去重。
2,关系测试。
set1 = {'abc', [1,2], 1,2,3} # 这个是错误的,因为集合要求里面的元素必须是不可变的数据类型,因此这里会报错(列表是可变的数据类型)
set2 = {'aa', 'bb'} # 直接定义
set3 = set({'aa', 'bb'}) # set()方法
2、集合去重
list可以利用set的特性达到去重效果 l1 = [1, 1, 2, 3, 4, 4, 3, 2, 1, 5, 5] set1 = set(l1) # 先把列表转换成集合,自动去重 l2 = list(set1) # 再把集合转换成列表 print(l2) # [1, 2, 3, 4, 5]
3、集合的增删
set1 = {'hello', 'handsome', 'boy', 'you', 'good'}
3.1 增
set1.add('女神') # add: 增加单个元素,类似列表的append
print(set1) # {'you', 'good', 'hello', 'boy', 'handsome', '女神'}
set1.update('abc') # update:迭代着增加(类似列表的extend)
print(set1) # {'you', 'good', 'hello', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
3.2 删
set1.remove('hello') # 删除一个元素
print(set1) # {'you', 'good', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
set1.pop() # 随机删除一个元素
print(set1) # {'good', 'boy', 'handsome', '女神', 'c', 'b', 'a'}
set1.clear() # 清空集合
print(set1) # set()
del set1 # 删除集合
4、关系测试
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
# 交集(& 或者 intersection):同时存在set1和set2中
print(set1 & set2) # {4, 5}
print(set1.intersection(set2)) # {4, 5}
# 并集(| 或者 union)
print(set1 | set2) # {1, 2, 3, 4, 5, 6, 7, 8}
print(set1.union(set2))
# 反交集(^ 或者 symmetric_difference): 不同时存在set1和set2中
print(set1 ^ set2) # {1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2))
# 差集(- 或者 difference):set1-set2 代表在set1中,但不在set2中
print(set1 - set2) # {1, 2, 3}
print(set1.difference(set2))
print(set2 - set1) # {8, 6, 7}
# 子集
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5, 6}
print(set1 < set2) # True
print(set1.issubset(set2)) # True
# 超集
print(set2 > set1) # True
print(set2.issuperset(set1)) # True
# frozenset不可变集合,让集合变成不可变类型。
set1 = {1, 2, 3}
set2 = frozenset(set1)
print(set2) # 不可变的数据类型。 ***
5、frozenset
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
语法:frozenset(iterable)
参数:iterable -- 可迭代的对象,比如列表、字典、元组等等。
a = frozenset(range(10)) # 生成一个新的不可变集合 b = frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) c = frozenset('abcde') print(a) # frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}) print(b) # frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9}) print(c) # frozenset({'a', 'd', 'c', 'e', 'b'}) f = frozenset({1, 2, 3}) print(f) # frozenset({1, 2, 3}) # f.add(4) f.remove(3) f.pop() 等方法都会报错,因为集合冻结后是不可变类型 # 不过需要注意的是,冻结后的集合仍然可以进行关系测试 f |= {4} print(f) # frozenset({1, 2, 3, 4}) f = f | {5} print(f) # frozenset({1, 2, 3, 4, 5})
为什么需要冻结的集合(即不可变的集合)呢?
因为在集合的关系中,有集合的中的元素是另一个集合的情况,但是普通集合(set)本身是可变的,那么它的实例就不能放在另一个集合中(set中的元素必须是不可变类型)。
所以,frozenset提供了不可变的集合的功能,当集合不可变时,它就满足了作为集合中的元素的要求,就可以放在另一个集合中了。
五、列表的赋值和深浅copy
- 直接赋值:其实就是对象的引用(别名)。
- 浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。
- 深拷贝(deepcopy): copy 模块的 deepcopy 方法,完全拷贝了父对象及其子对象。
1、赋值运算
l1 = [1, 2, 3] l2 = l1 l1.append(666) print(l1) # [1, 2, 3, 666] print(l2) # [1, 2, 3, 666] print(id(l1)) # 34857448 print(id(l2)) # 34857448, 是同一个地址,l2 = l1只是把l2指向了l1的地址,l1改变,l2也改变
2、浅copy
浅copy(只针对列表,字典,集合):数据(列表)第二层开始可以与原数据进行公用
# 浅copy l1 = [1, 2, 3] l2 = l1.copy() l1.append(666) print(l1) # [1, 2, 3, 666] print(l2) # [1, 2, 3],第一层是独立的 l1 = [1, 2, 3, [22, ]] l2 = l1.copy() l1[-1].append(666) print(l1) # [1, 2, 3, [22, 666]] print(l2) # [1, 2, 3, [22, 666]],第二层开始与原数据公用 print(id(l1)) # 2357463048008 print(id(l2)) # 2357463013767 print(id(l1[-1])) # 2357463047816 print(id(l2[-1])) # 2357463047816 # 注意:切片属于浅copy l1 = [1, 2, 3, [22, 33]] l2 = l1[:] l1[-1].append(666) print(l2) # [1, 2, 3, [22, 33, 666]]
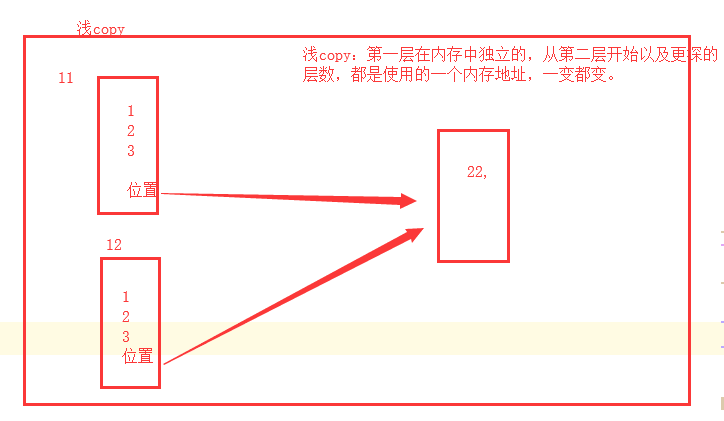
3、深copy
深copy(引用copy模块,任意数据类型都可深copy):完全独立的copy一份数据,与原数据没有关系
# 深copy import copy l1 = [1, 2, 3, [22, ]] l2 = copy.deepcopy(l1) print(l1, l2) # [1, 2, 3, [22]] [1, 2, 3, [22]] l1[-1].append(666) print(l1) # [1, 2, 3, [22, 666]] print(l2) # [1, 2, 3, [22]]

六、字典的赋值和深浅copy
字典的跟列表的相似
1、赋值运算
d1 = {"a": 1, "b": 2}
d2 = d1
print(d1) # {'a': 1, 'b': 2}
print(d2) # {'a': 1, 'b': 2}
print(id(d1)) # 1742085883944
print(id(d2)) # 1742085883944, 是同一个地址,d2 = d1只是把d2指向了d1的地址,d1改变,d2也改变
2、浅copy
浅copy(只针对列表,字典,集合):数据(列表)第二层开始可以与原数据进行公用
d1 = {"a": 1, "b": 2}
d2 = d1.copy()
d1["c"] = 3
print(d1) # {'a': 1, 'b': 2, 'c': 3}
print(d2) # {'a': 1, 'b': 2}, 第一层是独立的
d1 = {"a": 1, "b": [2, 3]}
d2 = d1.copy()
d1["b"].append(4)
print(d1) # {'a': 1, 'b': [2, 3, 4]}
print(d2) # {'a': 1, 'b': [2, 3, 4]}, 第二层开始与原数据公用
3、深copy
深copy(引用copy模块,任意数据类型都可深copy):完全独立的copy一份数据,与原数据没有关系
import copy d1 = {"a": 1, "b": [2, 3]} d2 = copy.deepcopy(d1) d1["b"].append(4) print(d1) # {'a': 1, 'b': [2, 3, 4]} print(d2) # {'a': 1, 'b': [2, 3]}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号