爬虫数据解析的三种方式
一、正则表达式解析
https://www.cnblogs.com/Zzbj/p/9622310.html
https://www.cnblogs.com/Zzbj/p/9629299.html
https://www.cnblogs.com/Zzbj/p/9630218.html
1、简单介绍
单字符: . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \d 匹配数字 \s 匹配任意的空白符 \W 匹配非字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 \n 匹配一个换行符 \t 匹配一个制表符(Tab) \b 匹配一个边界(其前后必须是不同类型的字符, 可以组成单词的字符为一种类型, 不可组成单词的字符(包括字符串的开始和结束)为另一种类型) a|b 匹配字符a或字符b () 匹配括号内的表达式,一个组表示一个整体 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符 数量修饰: * : 任意多次 >=0 + : 至少1次 >=1 ? : 可有可无 0次或者1次 {m} :固定m次 hello{3,} {m,} :至少m次 {m,n} :m到n次 边界: $ : 以某某结尾 ^ : 以某某开头 贪婪模式: .* 非贪婪(惰性)模式: .*? re模块: 1.匹配方法 re.findall(正则, 字符串) # 返回一个匹配到所有结果的列表 re.search(正则, 字符串) # 返回一个对象,用group()取值,只匹配一个结果 re.match(正则, 字符串) # 返回一个对象,用group()取值,只匹配一个结果,且默认正则有 ^ 以什么开头 re.finditer(正则, 字符串) # 返回一个存放匹配结果的迭代器(节省内存) 例如: ret = re.finditer('\d+','qwe123abc456') print(ret) # <callable_iterator object at 0x000001CA560DF860> print(ret.__next__().group()) # 123 print(next(ret).group()) # 456 # 或者单独使用for for i in ret: print(i.group()) # 123 456 compile:将正则表达式编译成为一个正则表达式对象 com = re.compile('\d+') print(com) # re.compile('\\d+') ret = com.search('qwe123abc456') print(ret.group()) # 123 ret = com.findall('qwe123abc456') print(ret) # ['123', '456'] ret = com.finditer('qwe123abc456') for i in ret: print(i.group()) # 123 456 2.其他内容 优先显示分组内容() ?的应用 ? 表示量词,零次或者一次 (?:正则表达式) 表示取消优先显示功能 (?P<组名>正则表达式) 表示给这个组起一个名字 (?P=组名) 表示引用之前组的名字,引用部分匹配到的内容必须和之前那个组中的内容一模一样 re.I : 忽略大小写 re.M :多行匹配 re.S :单行匹配 re.sub(正则表达式, 替换内容, 字符串) re.split(正则表达式, 字符串)
二、Xpath解析
1、什么是Xpath
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航。
XPath 使用路径表达式在 XML 文档中进行导航
XPath 包含一个标准函数库
XPath 是 XSLT 中的主要元素
XPath 是一个 W3C 标准
2、Xpath的使用
1.下载:pip install lxml 2.导包:from lxml import etree 3.将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定的节点 3.1 本地文件:tree = etree.parse(文件名) tree.xpath("xpath表达式") 3.2 网络数据:tree = etree.HTML(网页内容字符串) tree.xpath("xpath表达式")
三、Xpath的语法
摘抄自w3school教程:http://www.w3school.com.cn/xpath/xpath_syntax.asp
1、xpath语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
以下面这个xml为例子
<?xml version="1.0" encoding="ISO-8859-1"?> <bookstore> <book> <title lang="eng">Harry Potter</title> <price>29.99</price> </book> <book> <title lang="eng">Learning XML</title> <price>39.95</price> </book> </bookstore>
xml.xpath(“bookstore”) 表示选取 bookstore 元素的所有子节点
xml.xpath(“/bookstore”) 表示选取根元素 bookstore。
xml.xpath(“bookstore/book”) 选取属于 bookstore 的子元素的所有 book 元素。
xml.xpath(“//book”) 选取所有 book 子元素,而不管它们在文档中的位置。
xml.xpath(“bookstore//book”) 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。
xml.xpath(“//@lang”) 选取名为 lang 的所有属性。
2、谓语
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
3、选取未知节点
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
| node() | 匹配任何类型的节点。 |
例子:
| 路径表达式 | 结果 |
|---|---|
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
4、选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
5、轴
轴可定义相对于当前节点的节点集。
| 轴名称 | 结果 |
|---|---|
| ancestor | 选取当前节点的所有先辈(父、祖父等)。 |
| ancestor-or-self | 选取当前节点的所有先辈(父、祖父等)以及当前节点本身。 |
| attribute | 选取当前节点的所有属性。 |
| child | 选取当前节点的所有子元素。 |
| descendant | 选取当前节点的所有后代元素(子、孙等)。 |
| descendant-or-self | 选取当前节点的所有后代元素(子、孙等)以及当前节点本身。 |
| following | 选取文档中当前节点的结束标签之后的所有节点。 |
| namespace | 选取当前节点的所有命名空间节点。 |
| parent | 选取当前节点的父节点。 |
| preceding | 选取文档中当前节点的开始标签之前的所有节点。 |
| preceding-sibling | 选取当前节点之前的所有同级节点。 |
| self | 选取当前节点。 |
步的语法:
轴名称::节点测试[谓语]
例1:
| 例子 | 结果 |
|---|---|
| child::book | 选取所有属于当前节点的子元素的 book 节点。 |
| attribute::lang | 选取当前节点的 lang 属性。 |
| child::* | 选取当前节点的所有子元素。 |
| attribute::* | 选取当前节点的所有属性。 |
| child::text() | 选取当前节点的所有文本子节点。 |
| child::node() | 选取当前节点的所有子节点。 |
| descendant::book | 选取当前节点的所有 book 后代。 |
| ancestor::book | 选择当前节点的所有 book 先辈。 |
| ancestor-or-self::book | 选取当前节点的所有 book 先辈以及当前节点(如果此节点是 book 节点) |
| child::*/child::price | 选取当前节点的所有 price 孙节点。 |
例2:
原文:https://blog.csdn.net/qq_37059367/article/details/83819828
<div> <a id="1" href="www.baidu.com">我是第1个a标签</a> <p>我是p标签</p> <a id="2" href="www.baidu.com">我是第2个a标签</a> <a id="3" href="www.baidu.com">我是第3个a标签</a> <a id="4" href="www.baidu.com">我是第4个a标签</a> <p>我是p标签</p> <a id="5" href="www.baidu.com">我是第5个a标签</a> </div>
获取第三个a标签的下一个a标签:"//a[@id='3']/following-sibling::a[1]" 获取第三个a标签后面的第N个标签:"//a[@id='3']/following-sibling::*[N]" 获取第三个a标签的上一个a标签:"//a[@id='3']/preceding-sibling::a[1]" 获取第三个a标签的前面的第N个标签:"//a[@id='3']/preceding-sibling::*[N]" 获取第三个a标签的父标签:"//a[@id=='3']/.."
6、功能函数
使用功能函数能够更好的进行模糊搜索
函数 用法 解释 starts-with xpath('//div[starts-with(@id,"ma")]') 选取id值以ma开头的div节点 contains xpath('//div[contains(@id,"ma")]') 选取id值包含ma的div节点 and xpath('//div[contains(@id,"ma") and contains(@id,"in")]') 选取id值包含ma和in的div节点 text() xpath('//div[contains(text(),"ma")]') 选取节点文本包含ma的div节点
7、Element对象
from lxml.etree import _Element for obj in ret: print(obj) print(type(obj)) # from lxml.etree import _Element # 用xpath语法查询出来的列表,里面的对象都是Element对象 Element对象的内置方法如下: class xml.etree.ElementTree.Element(tag, attrib={}, **extra) tag:string,元素代表的数据种类。 text:string,元素的内容。 tail:string,元素的尾形。 attrib:dictionary,元素的属性字典。 #针对属性的操作 clear():清空元素的后代、属性、text和tail也设置为None。 get(key, default=None):获取key对应的属性值,如该属性不存在则返回default值。 items():根据属性字典返回一个列表,列表元素为(key, value)。 keys():返回包含所有元素属性键的列表。 set(key, value):设置新的属性键与值。 #针对后代的操作 append(subelement):添加直系子元素。 extend(subelements):增加一串元素对象作为子元素。#python2.7新特性 find(match):寻找第一个匹配子元素,匹配对象可以为tag或path。 findall(match):寻找所有匹配子元素,匹配对象可以为tag或path。 findtext(match):寻找第一个匹配子元素,返回其text值。匹配对象可以为tag或path。 insert(index, element):在指定位置插入子元素。 iter(tag=None):生成遍历当前元素所有后代或者给定tag的后代的迭代器。#python2.7新特性 iterfind(match):根据tag或path查找所有的后代。 itertext():遍历所有后代并返回text值。 remove(subelement):删除子元素。
8、常用xpath查询示例


html_document = ''' <html lang="en"> <head> <meta charset="UTF-8" /> <title>测试bs4</title> </head> <body> <div> <p>百里守约</p> </div> <div class="song"> <p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a href="http://www.song.com/" title="赵匡胤" target="_self"> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a href="" class="du">总为浮云能蔽日,长安不见使人愁</a> <img src="http://www.baidu.com/meinv.jpg" alt="" /> </div> <div class="tang"> <ul> <li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li> <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li> <li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li> <li><a href="http://www.sina.com" class="du">杜甫</a></li> <li><a href="http://www.dudu.com" class="du">杜牧</a></li> <li><b>杜小月</b></li> <li><i>度蜜月</i></li> <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li> </ul> </div> </body> </html> '''
from lxml import etree tree = etree.HTML(html_document) # 找到class属性值为song的div标签 ret = tree.xpath("//div[@class='song']") # 找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a ret = tree.xpath("//div[@class='tang']/ul/li[2]/a") # 找到href属性值为空且class属性值为du的a标签 ret = tree.xpath("//a[@class='du' and @href='']") # 模糊匹配,找到class属性包含'ng'的div标签 ret = tree.xpath("//div[contains(@class,'ng')]") # 模糊匹配,找到class属性以'ta'开头的div标签 ret = tree.xpath("//div[starts-with(@class,'ta')]") print(ret) # ret是所有符合的Element对象组成的列表 for ele in ret: print(ele) print(ele.tag) print(ele.text) # 还可以直接在找到的Element对象后面使用一些方法 ret = tree.xpath("//div[starts-with(@class,'ta')]/ul/li[1]/a/text()") ret = tree.xpath("//div[starts-with(@class,'ta')]/ul/li[1]/a/@href") for i in ret: print(i)
小结:
// 是不管节点在哪,都会去全局找
/ 是在当节点向下找一层,就是只在当前节点的儿子里面找
四、BeautifulSoup
1、简介
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。
它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
总而言之,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据
它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup能为我们节省工作时间
需要注意的是Beautiful Soup 3 目前已经停止开发,官网推荐在现在的项目中使用Beautiful Soup 4。
2、安装
1. 安装beautifulsoup模块
pip3 install beautifulsoup4
2. 安装解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
pip3 install lxml
另一个可供选择的解析器是纯Python实现的 html5lib , html5lib的解析方式与浏览器相同
pip install html5lib
3. 解析器性能对比
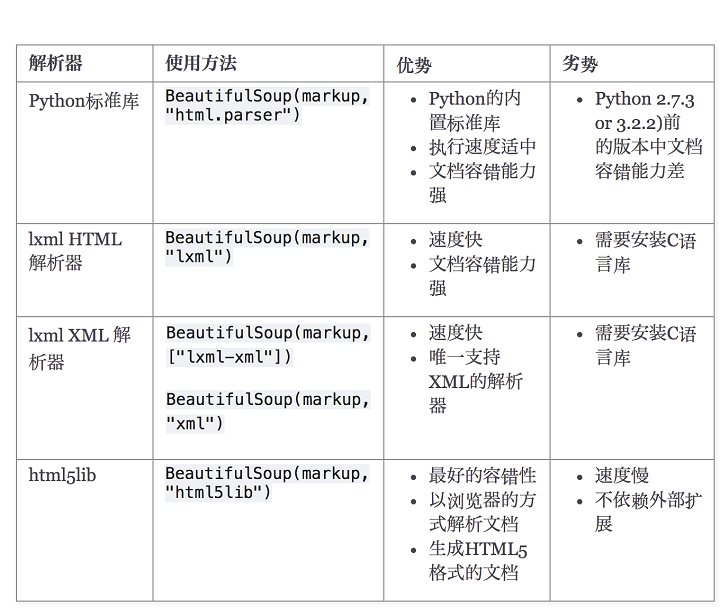
4. 官方文档
https://beautifulsoup.readthedocs.io/zh_CN/latest/
3、BS使用流程
导包:from bs4 import BeautifulSoup 使用方式:可以将一个html文档,转化为BeautifulSoup对象,然后通过对象的方法或者属性去查找指定的节点内容 1. 转化本地文件: soup = BeautifulSoup(open('本地文件'), 'lxml') 2. 转化网络文件: soup = BeautifulSoup('字符串类型或者字节类型', 'lxml') 3. soup对象即为html文件中的内容
五、BeautifulSoup的使用方法
html文档:下面的例子都以这个文档作为查询的根本
html_doc =""" <html> <head> <title> The Dormouse's story </title> </head> <body> <p class="title" id="myp"> <b class="boldest" id="bbb">The Dormouse's story</b> <span><a href="" class="ming">xiaoming</a></span> <a href="">wanglin</a> </p> <p class="story"> Once upon a time there were three little sisters; and their names were <a class="sister brother" href="http://example.com/elsie" id="link1">Elsie</a> <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a> and they lived at the bottom of a well. </p> <p class="story"> .... </p> </body> </html> """
from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc, 'lxml') BeautifulSoup找到的都是标签对象
print(soup.prettify()) # 自动帮我们格式化补全改错文档
1、通过Tag(标签名)找对象
soup.a # 找到第一个a标签 soup.body.b # 找到第一个body标签里面的b标签 soup.find_all('a') # 找到所有a标签
2、attrs获取tag的属性
tag的属性操作方法与字典一样 soup.a.attrs # 获取第一个a标签的所有属性,返回一个字典 soup.a.attrs['class'] # 获取第一个a标签的class属性 soup.a.attrs.get('class') # 获取第一个a标签的class属性 soup.a['class'] # 也可简写为这种形式 soup.a.name # 获取第一个a标签的标签名
3、添加/删除/修改tag的属性
soup.a['href'] = 'www.baidu.com' # 修改属性 print(soup.a['href']) # www.baidu.com soup.a['id'] = 1 # 增加属性 print(soup.a.attrs['id']) # 1 del soup.a['class'] # 删除属性 print(soup.a.attrs.get('class')) # None
4、获取标签的内容
# 当p标签下只有一个文本时(不嵌套其他标签),可以取到内容,否则为None print(soup.p.string) # 拿到一个生成器对象, 取到p下所有的文本内容,有嵌套标签也可以取 print(soup.p.strings) for item in soup.p.strings: print(item) # 取到p下所有的文本内容,有嵌套标签也可以取 print(soup.p.text) # 跟上面的text一样 print(soup.p.get_text()) # 取到文档的所有文本内容,且去掉空白 for line in soup.stripped_strings: print(line)
5、遍历文档树
# 1、嵌套选择 print(soup.head.title.string) print(soup.body.a.string) # 2、子节点、子孙节点 print(soup.p.contents) # p下所有子节点 print(soup.p.children) # 得到一个迭代器,包含p下所有子节点 for i, child in enumerate(soup.p.children): print(i, child) print(soup.p.descendants) # 获取子孙节点,p下所有的标签都会选择出来 for i, child in enumerate(soup.p.descendants): print(i, child) # 3、父节点、祖先节点 print(soup.a.parent) # 获取a标签的父节点 print(soup.a.parents) # 找到a标签所有的祖先节点,父亲的父亲,父亲的父亲的父亲... # 4、兄弟节点 print(soup.a.next_sibling) # 下一个兄弟 print(soup.a.previous_sibling) # 上一个兄弟 print(soup.a.next_siblings) # 下面的兄弟们=>生成器对象 print(soup.a.previous_siblings) # 上面的兄弟们=>生成器对象
6、5种过滤器
五种过滤器: 字符串、正则表达式、列表、True、方法 # 1、字符串:即标签名 print(soup.find_all('b')) # 2、正则表达式 import re print(soup.find_all(re.compile('^b'))) #找出b开头的标签,结果有body和b标签 # 3、列表:如果传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有<a>标签和<b>标签: print(soup.find_all(['a','b'])) # 4、True:可以匹配任何值,下面代码查找到所有的tag,但是不会返回字符串节点 print(soup.find_all(True)) for tag in soup.find_all(True): print(tag.name) # 5、方法:如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 ,如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False def has_class_but_no_id(tag): return tag.has_attr('class') and not tag.has_attr('id') print(soup.find_all(has_class_but_no_id))
7、find_all()
find_all()是查找所有符合的标签 # 1、按照属性去查找 print(soup.find_all("a", href="http://example.com/lacie")) print(soup.find_all("a", id="link3")) # 1-2、特殊的属性class:因为class是python的关键字,因此这里要查找class属性要写成:class_ # 注意关键字是class_,class_=value,value可以是五种选择器之一 print(soup.find_all('a', class_='sister')) # 查找类为sister的a标签 print(soup.find_all('a',class_='sister brother')) # 查找类为sister和brother的a标签,顺序错误也匹配不成功 print(soup.find_all(class_=re.compile('^sis'))) # 查找类为sis开头的所有标签 # 2、attrs print(soup.find_all('p', attrs={'class': 'story'})) # 3、text: 值可以是:字符,列表,True,正则 print(soup.find_all(text='Elsie')) print(soup.find_all('a', text='Elsie')) # 4、limit参数:如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与SQL中的limit关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果 print(soup.find_all('a', limit=2)) # 5、recursive:调用tag的find_all()方法时,Beautiful Soup会检索当前tag的所有子孙节点,如果只想搜索tag的直接子节点,可以使用参数 recursive=False . print(soup.html.find_all('a')) print(soup.html.find_all('a', recursive=False)) ''' 像调用 find_all() 一样调用tag find_all() 几乎是Beautiful Soup中最常用的搜索方法,所以我们定义了它的简写方法. BeautifulSoup 对象和 tag 对象可以被当作一个方法来使用, 这个方法的执行结果与调用这个对象的 find_all() 方法相同,下面两行代码是等价的: soup.find_all("a") soup("a") 这两行代码也是等价的: soup.title.find_all(text=True) soup.title(text=True) '''
8、find()
find()是查找第一个符合的标签,find_all的所有方法find也有一模一样的。
print(soup.find("a", id="link1")) find_all() 方法将返回文档中符合条件的所有tag,尽管有时候我们只想得到一个结果.比如文档中只有一个<body>标签,那么使用 find_all() 方法来查找<body>标签就不太合适, 使用 find_all 方法并设置 limit=1 参数不如直接使用 find() 方法.下面两行代码是等价的: soup.find_all('title', limit=1) soup.find('title') 唯一的区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果. find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None . print(soup.find("abcdefg")) # None soup.head.title 是 tag的名字方法的简写.这个简写的原理就是多次调用当前tag的 find() 方法: print(soup.head.title) # <title>The Dormouse's story</title> soup.find("head").find("title") # <title>The Dormouse's story</title> find和find_all的简写方式: soup.find("a") 等价于 soup.a soup.find_all("a") 等价于 soup("a") 特别需要注意的是,支持链式查找 soup.find("p").find_all("a") 等价于 soup.p("a")
9、css选择器
CSS筛选器的语法是:标签名不加任何修饰,类名前加点,id名前加 # BS也给我们提供了跟CSS筛选器一模一样的语法,用到的方法是 soup.select(),返回类型是 list 1.通过标签名查找 print(soup.select("title")) print(soup.select("b")) 2.通过类名查找 print(soup.select(".sister")) 3.通过 id 名查找 print(soup.select("#myp")) 4.组合查找 print(soup.select("p #bbb")) # 在p的子孙里面找id为bbb的标签 print(soup.select("p>#bbb")) # 只在p的儿子里面找id为bbb的标签 print(soup.select("p.story")) # 找到class为story的p标签 5.属性查找 print(soup.select("a[href='http://example.com/tillie']")) # 找到href属性值为http://example.com/tillie的a标签

 浙公网安备 33010602011771号
浙公网安备 33010602011771号