爬虫与request模块
一、爬虫简介
1、介绍
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
实际上就是一段自动抓取互联网信息的程序,它会从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止,然后把数据解析成对我们有价值的信息。
2、爬虫的价值
互联网中最有价值的便是数据,比如天猫、京东、淘宝等电商网站超越咨询顾问的算力,在用户理解和维护,抓取各大电商的评论及销量数据,对各种商品(颗粒度可到款式)沿时间序列的销量以及用户的消费场景进行分析,
又或者58同城的房产、安居客、Q房网、搜房等房产网站下半年深圳房价将如何发展 ,抓取房产买卖及租售信息,对热热闹闹的房价问题进行分析。
大众点评、美团网等餐饮及消费类网站黄焖鸡米饭是怎么火起来的?抓取各种店面的开业情况以及用户消费和评价,了解周边变化的口味,所谓是“舌尖上的爬虫”。以及各种变化的口味,比如:啤酒在衰退,重庆小面在崛起。
拉勾网、中华英才网等招聘网站互联网行业哪个职位比较有前途?抓取各类职位信息,分析最热门的职位以及薪水。
这些数据都代表了各个行业的重点方向,可以说,谁掌握了行业内的第一手数据,谁就拥有比别人更大的机会成为主宰。
3、robots.txt协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt 是网站和搜索引擎的协议的纯文本文件。当一个搜索引擎蜘蛛来访问站点时,它首先爬行来检查该站点根目录下是否存在robots.txt,如果存在,根据文件内容来确定访问范围,如果没有,蜘蛛就沿着链接抓取。robots.txt 放在项目的根目录下。
但值得注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,如果你不想遵守,有这个协议也没用的,
为了防止被爬,只能在自己的网站上进行相关的反爬技术。
4、爬虫的基本流程

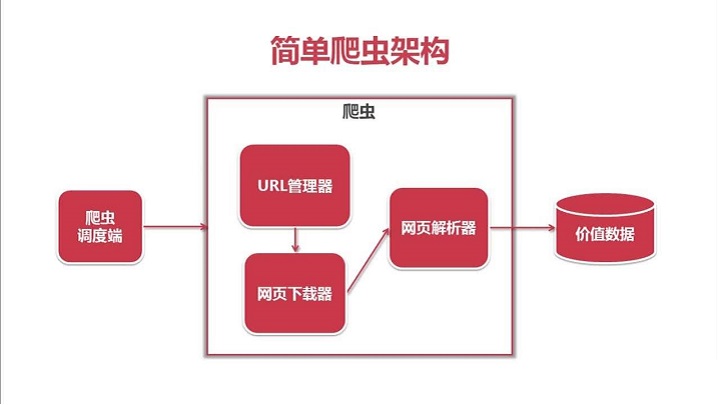
5、http协议
https://www.cnblogs.com/Zzbj/p/9844520.html
二、requests模块
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,可以节约我们大量的工作。
requests本质就是封装了urllib3,requests是python实现的最简单易用的HTTP库,建议爬虫使用requests库。
1、requests模块支持的请求
import requests requests.get("http://httpbin.org/get") requests.post("http://httpbin.org/post") requests.put("http://httpbin.org/put") requests.delete("http://httpbin.org/delete") requests.head("http://httpbin.org/get") requests.options("http://httpbin.org/get")
2、get请求
1. 基本请求 import requests response = requests.get('https://www.jd.com/') # 发送一个get请求 with open("jd.html", "wb") as f: f.write(response.content) # 把响应体(response.content)保存到一个文件中 2. 含参数请求 import requests # 通过params给请求添加参数 response = requests.get( 'https://s.taobao.com/search', params={ "q": "手机", # URL后面的 ? 参数 }) with open("shouji.html", "w", encoding="utf8") as f: f.write(response.text) # 把响应体保存到一个文件中(w模式用text,wb模式用content) 3. 含请求头请求 import requests response = requests.get( 'https://dig.chouti.com/', headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', }) with open("ct.html", "wb") as f: f.write(response.content) # 把响应体(response.content)保存到一个文件中 通过headers给请求添加请求头,有些网站为了反爬会设置一些"障碍",如果你User-Agent这个请求头为空,他们就认为你是机器人, 就不接受你的请求,简单地实现反爬。 4. 含cookies请求 import uuid import requests url = 'http://httpbin.org/cookies' cookies = dict(sbid=str(uuid.uuid4())) response = requests.get(url, cookies=cookies) print(response.text) 5. requests.session() import requests res = requests.get("https://github.com/login") # 请求登录页面 print(res.cookies.get_dict()) # 获取到服务器传过来的cookies res = requests.post("https://github.com/session", cookies=res.cookies.get_dict()) # 爬取需要登录的页面,带上cookies session = requests.session() # 使用requests.session()方法 # 下面在使用requests的地方,直接使用session即可,session就会保存服务器发送过来的cookie信息 res2 = session.get("https://github.com/login") print(session.cookies.get_dict()) # 这里用了session后,不需要再提交cookies,默认已经带着cookies了,等同于上面的requests.post带上cookies res3 = session.post("https://github.com/session")
3、post请求
1. data参数 requests.post()用法与requests.get()完全一致,不同的是requests.post()多了一个data参数,用来存放请求体数据, 请求体数据使用data,没有指定请求头,默认的请求头的contentType=application/x-www-form-urlencoed import requests response = requests.post( "http://httpbin.org/post", params={ "pag": 1 }, data={ "user": "zzz", "pwd": '123' }) print(response.text)


{ "args": { "pag": "1" }, "data": "", "files": {}, "form": { "pwd": "123", "user": "zzz" }, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "16", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5eea1f3d-2cbb812687b79547036f3cb5", "X-B3-Parentspanid": "1c2cd168325fd1de", "X-B3-Sampled": "0", "X-B3-Spanid": "28f15cc5e8251b64", "X-B3-Traceid": "686f4a58747877b71c2cd168325fd1de", "X-Envoy-External-Address": "10.100.91.201", "X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/httpbin-istio/sa/httpbin;Hash=2d7a8267507b31e321542600ae41de5a4bb0f3c7a83b1286365a185b39e11622;Subject=\"\";URI=spiffe://cluster.local/ns/istio-system/sa/istio-ingressgateway-service-account" }, "json": null, "origin": "121.35.183.91,10.100.91.201", "url": "http://httpbin.org/post?pag=1" }
2. 发送json数据 import requests response = requests.post( "http://httpbin.org/post", params={ "pag": 1 }, json={ "user": "zzz", "pwd": '123' }) print(response.text)
{ "args": { "pag": "1" }, "data": "{\"user\": \"zzz\", \"pwd\": \"123\"}", "files": {}, "form": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Content-Length": "29", "Content-Type": "application/json", "Host": "httpbin.org", "User-Agent": "python-requests/2.23.0", "X-Amzn-Trace-Id": "Root=1-5eea1f3e-08cf655111f59ecfd06a05e3", "X-B3-Parentspanid": "4b395b4ae3786d94", "X-B3-Sampled": "0", "X-B3-Spanid": "450af3e10f8c8c0f", "X-B3-Traceid": "d9b74e62214febd34b395b4ae3786d94", "X-Envoy-External-Address": "10.100.91.201", "X-Forwarded-Client-Cert": "By=spiffe://cluster.local/ns/httpbin-istio/sa/httpbin;Hash=32f97e2cb8d1b773f1bb4e7f790221737659867d349dfba04f979a13846bb3a8;Subject=\"\";URI=spiffe://cluster.local/ns/istio-system/sa/istio-ingressgateway-service-account" }, "json": { "pwd": "123", "user": "zzz" }, "origin": "121.35.183.91,10.100.91.201", "url": "http://httpbin.org/post?pag=1" }
请求体数据指定时使用json,请求头的contentType=application/json 3. x-www-form-urlencoed和json格式的区别 urlencoed是浏览器默认的格式,格式是: a=1&b=2 json的格式是: xxx = { "a" = "1", "b" = "2" }
4、response对象
1. 常用属性
import requests response = requests.get('https://sh.lianjia.com') # response属性 print(response.text) # 获取响应的内容(字符串) print(response.content) # 获取响应的内容(字节) print(response.status_code) # 获取响应的状态码 print(response.headers) # 获取响应头的信息 print(response.cookies) # 获取服务器传过来的cookies print(response.cookies.get_dict()) # 把cookies转换成字典格式 print(response.cookies.items()) # 跟字典的items方法一样 print(response.url) # 获取请求的url print(response.history) # 获取请求的重定向历史 print(response.encoding) # 获取响应的编码
2.response.text和response.content
response.text拿到的是响应的字符串
response.content拿到的是响应的字节串
text(字符串)就是把content(字节)默认用utf8给解码了而已,但是如果爬到的内容编码模式不是utf8,那么用text拿到的内容就会有乱码了。
3. 编码问题
方法一:指定响应的编码 import requests response = requests.get('http://www.autohome.com/news') response.encoding = 'gbk' # 汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码 with open("qczj.html", "w") as f: f.write(response.text) # 把解码后的文本写入文件中 方法二:直接使用wb模式写入 import requests response = requests.get('http://www.autohome.com/news') with open("qczj2.html", "wb") as f: f.write(response.content) # 以字节形式写入文件中
4. history重定向
默认情况下,除了HEAD, Requests会自动处理所有重定向。可以使用响应对象的 history 方法来追踪重定向。 Response.history 是一个 Response 对象的列表,为了完成请求而创建了这些对象。这个对象列表按照从最老到最近的请求进行排序。 import requests response = requests.get("https://www.autohome.com.cn/huizhou/") print(response.status_code) # 200 print(response.history) # 没有重定向为空列表:[] # allow_redirects默认为True,当网站是https协议,而你输入了http协议,就会自动重定向到https # 把allow_redirects设置了False,请求http,可以看到response响应就是重定向 response = requests.get("http://www.autohome.com.cn/huizhou/", allow_redirects=False) print(response.status_code) # 302 print(response) # 重定向的对象:<Response [302]> # 也可以让allow_redirects为True,查看响应体的history,看是否有重定向 response = requests.get("http://www.autohome.com.cn/huizhou/", allow_redirects=True) print(response.status_code) # 200 print(response.history) # [<Response [302]>]
5. 下载二进制文件
import requests response = requests.get('https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1548171900434&di=04e4eb6ee17c081556947ebb1ceb161e&imgtype=0&src=http%3A%2F%2Fhbimg.b0.upaiyun.com%2F039e4e47e1a2a53f305a83a367b511570b8e96771d98d-wWPJMp_fw658') with open("wuming.png","wb") as f: # f.write(response.content) # 如果下载的是视频,而且有100G,用response.content会把内容一下全部写到文件中,是不合理的 for line in response.iter_content(): # response.iter_content()方法是把响应内容转换成迭代器 f.write(line)
6.解析json数据
import requests import json response = requests.get('http://httpbin.org/get') res1 = json.loads(response.text) # 太麻烦 res2 = response.json() # 直接获取json数据
7. 代理
一些网站会有相应的反爬虫措施,例如很多网站会检测某一段时间某个IP的访问次数,如果访问频率太快以至于看起来不像正常访客, 它可能就会会禁止这个IP的访问。所以我们需要设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。 import requests proxies = { "http": "http://117.70.39.242:9999", } response = requests.get("http://httpbin.org/ip",proxies=proxies) print(response.text)
三、爬虫案例
1、爬取豆瓣top250
import requests import re import json import time from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor(5) # 线程池 # 获取豆瓣top250所有电影的名称,url,评分,评论数 # 1.发送请求,获取响应 def getPage(url): response = requests.get(url) return response.text # 2.解析数据 def parsePage(res): com = re.compile('<div class="item">.*?<a href="(?P<url>.*?)">.*?<span class="title">(?P<title>.*?)</span>.*?<span class="rating_num".*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)人评价</span>',re.S) iter_result = com.finditer(res) return iter_result # 3. 存储数据 def stored(iter_result): # 存储文件中 movie_info = {} for i in iter_result: print("OK") print(i.group("url")) print(i.group("title")) print(i.group("rating_num")) print(i.group("comment_num")) movie_info["url"] = i.group("url") movie_info["title"] = i.group("title") movie_info["rating_num"] = i.group("rating_num") movie_info["comment_num"] = i.group("comment_num") with open("doubanTop250.txt", 'a', encoding="utf8") as f: f.write(json.dumps(movie_info, ensure_ascii=False)+"\n") def spider_movie(url): res = getPage(url) iter_result = parsePage(res) stored(iter_result) def main(): for i in range(10): url = "https://movie.douban.com/top250?start=%s&filter=" % (i*25) pool.submit(spider_movie, url) if __name__ == '__main__': start = time.time() main() end = time.time() print("cost time:", end - start)
import requests import re import json import time from concurrent.futures import ThreadPoolExecutor pool = ThreadPoolExecutor(5) # 线程池 # 获取豆瓣top250所有电影的名称,url,评分,评论数 # 1.发送请求,获取响应 def getPage(url): response = requests.get(url) return response.text # 2.解析数据 def parsePage(res): com = re.compile('<div class="item">.*?<a href="(?P<url>.*?)">.*?<span class="title">(?P<title>.*?)</span>.*?<span class="rating_num".*?>(?P<rating_num>.*?)</span>.*?<span>(?P<comment_num>.*?)人评价</span>',re.S) iter_result = com.finditer(res) return iter_result # 使用生成器处理数据 def movieInfo(iter_result): for i in iter_result: yield { "url": i.group("url"), "title": i.group("title"), "rating_num": i.group("rating_num"), "comment_num": i.group("comment_num"), } # 3. 存储数据 def stored(info): with open("doubanTop250.txt", 'a', encoding="utf8") as f: for i in info: data = json.dumps(i, ensure_ascii=False) f.write(data+"\n") def spider_movie(url): res = getPage(url) iter_result = parsePage(res) info = movieInfo(iter_result) stored(info) def main(): for i in range(10): url = "https://movie.douban.com/top250?start=%s&filter=" % (i*25) pool.submit(spider_movie, url) if __name__ == '__main__': start = time.time() main() end = time.time() print("cost time:", end - start)
2、爬取GitHub登录后的home页面
''' github的反爬策略是,必须带登录界面github给你的authenticity_token 必须带cookies 必须带上登录的数据 ''' import requests import re # 第一步: 请求登录页面,获取token,以便通过post请求校验 session = requests.session() # 用requests.session保存cookies,下面post请求就不需要再指定cookies了 res = session.get("https://github.com/login") # res = requests.get("https://github.com/login") # cookies = res.cookies.get_dict() authenticity_token = re.findall('name="authenticity_token" value="(.*?)"', res.text)[0] print(authenticity_token) # 第二步:构建post请求数据 data = { "commit": "Sign in", "utf8": "✓", "authenticity_token": authenticity_token, "login": "your name", # 你github的账号 "password": "your password" # 你github的密码 } headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', } # 如果没有使用requests.session,需要带上cookies=cookies # res = requests.post("https://github.com/session", data=data, headers=headers, cookies=cookies) res = session.post("https://github.com/session", data=data, headers=headers) with open("github.html", "wb") as f: f.write(res.content)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号