Django之缓存、信号和图片验证码、ORM性能
一、 缓存
1、 介绍
缓存通俗来说:就是把数据先保存在某个地方,下次再读取的时候不用再去原位置读取,让访问速度更快。
缓存机制图解
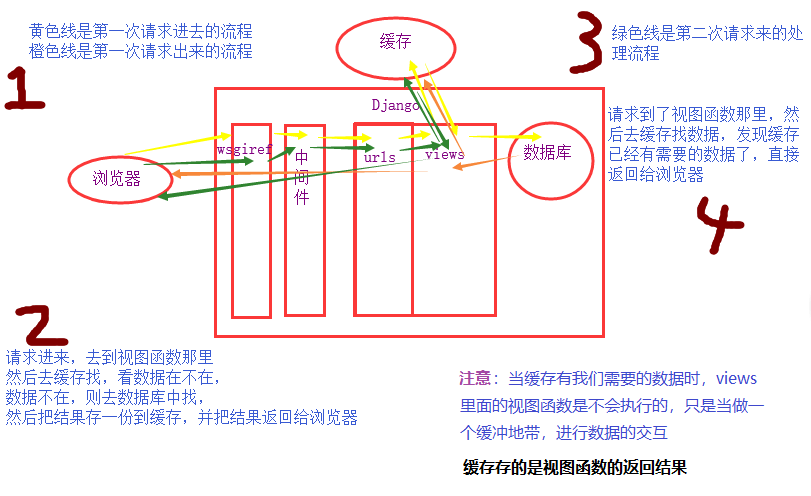
2、Django中提供了6种缓存方式
1. 开发调试
2. 内存
3. 文件
4. 数据库
5. Memcache缓存(python-memcached模块)
6. Memcache缓存(pylibmc模块)
注意:下面对缓存进行配置,其实就是设置了缓存方式,是为了设置缓存的存放位置,如果没有设置缓存方式,那么就默认使用的是本地内存缓存的方式。
3、 配置缓存(在setting中配置)
配置缓存的方式 1. 开发调试 # 此为开始调试用,实际内部不做任何操作 CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.dummy.DummyCache', # 引擎 'TIMEOUT': 300, # 缓存超时时间(默认300,None表示永不过期,0表示立即过期) 'OPTIONS':{ 'MAX_ENTRIES': 300, # 最大缓存个数(默认300) 'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3) }, 'KEY_PREFIX': '', # 缓存key的前缀(默认空) 'VERSION': 1, # 缓存key的版本(默认1) 'KEY_FUNCTION' 函数名 # 生成key的函数(默认函数会生成为:【前缀:版本:key】) } } # 自定义key def default_key_func(key, key_prefix, version): """ Default function to generate keys. Constructs the key used by all other methods. By default it prepends the `key_prefix'. KEY_FUNCTION can be used to specify an alternate function with custom key making behavior. """ return '%s:%s:%s' % (key_prefix, version, key) def get_key_func(key_func): """ Function to decide which key function to use. Defaults to ``default_key_func``. """ if key_func is not None: if callable(key_func): return key_func else: return import_string(key_func) return default_key_func 2. 内存 # 此缓存将内容保存至内存的变量中 CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.locmem.LocMemCache', 'LOCATION': 'unique-snowflake', 'TIMEOUT': 300, # 缓存超时时间(默认300,None表示永不过期,0表示立即过期) 'OPTIONS': { 'MAX_ENTRIES': 300, # 最大缓存个数(默认300) 'CULL_FREQUENCY': 3, # 缓存到达最大个数之后,剔除缓存个数的比例,即:1/CULL_FREQUENCY(默认3) }, } } 3. 文件 # 此缓存将内容保存至文件 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache', 'LOCATION': '/var/tmp/django_cache', # 文件路径 } } # 注:其他配置同开发调试版本 4. 数据库 # 此缓存将内容保存至数据库 # 配置: CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.db.DatabaseCache', 'LOCATION': 'my_cache_table', # 数据库表 } } # 注:执行创建表命令 python manage.py createcachetable 5. Memcache缓存(python-memcached模块) # 此缓存使用python-memcached模块连接memcache CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': '127.0.0.1:11211', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': 'unix:/tmp/memcached.sock', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache', 'LOCATION': [ '172.19.26.240:11211', '172.19.26.242:11211', ] } } 6. Memcache缓存(pylibmc模块) # 此缓存使用pylibmc模块连接memcache CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': '127.0.0.1:11211', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': '/tmp/memcached.sock', } } CACHES = { 'default': { 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache', 'LOCATION': [ '172.19.26.240:11211', '172.19.26.242:11211', ] } }
4、 简单的应用
配置好了缓存的方式之后,我们使用缓存机制也是非常简单的
1. 给单独的视图应用缓存: 粒度适中 方式一:直接给视图函数添加装饰器 # views.py import datetime from django.views.decorators.cache import cache_page @cache_page(15) # 缓存15秒后失效 def test_cache(request): now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') return HttpResponse(now) 方式二:给路由添加 # urls.py from myapp.views import test_cache from django.views.decorators.cache import cache_page urlpatterns = [ url(r'^testcache/$', cache_page(15)(test_cache)), ] 方式一和二选择一种即可 2. 全站应用: 粒度最大(settings.py) 使用中间件,经过一系列的认证等操作,如果内容在缓存中存在,则使用FetchFromCacheMiddleware获取内容并返回给用户, 当返回给用户之前,判断缓存中是否已经存在,如果不存在则UpdateCacheMiddleware会将缓存保存至缓存,从而实现全站缓存(所有视图都进行缓存) MIDDLEWARE = [ # 站点缓存 , 注意必须在第一个位置 'django.middleware.cache.UpdateCacheMiddleware', # 其他中间件... # 站点缓存 , 注意必须在最后一个位置 'django.middleware.cache.FetchFromCacheMiddleware', ] CACHE_MIDDLEWARE_ALIAS = "" CACHE_MIDDLEWARE_SECONDS = 300 # 缓存有效时间 CACHE_MIDDLEWARE_KEY_PREFIX = "" 3. 局部视图(在HTML页面设置哪些需要缓存):粒度最细 a. 引入TemplateTag {% load cache %} b. 使用缓存 {% cache 300 '缓存key' %} # 缓存key的名字可以是随意的 缓存内容 {% endcache %}
二、 序列化
1、介绍
关于Django中的序列化主要应用在将数据库中检索的数据返回给客户端用户,特别的Ajax请求一般返回的为Json格式。
2、serializers
from django.core import serializers def get_value(request): users = models.User.objects.all() ret = serializers.serialize('json', users) return HttpResponse(ret)
3、自定义序列化
由于json模块并不能转换时间类型的数据,因此需要我们自定义一个类来处理时间类型的数据 import json from datetime import datetime, date data = [ # data数据中有datetime类型的值, json不能直接序列化 {"pk": 1, "name": "\u83b9\u83b9", "age": 18, 'birth': datetime.now()}, {"pk": 2, "name": "\u5c0f\u5fae", "age": 16, 'birth': datetime.now()}, {"pk": 3, "name": "\u5c0f\u9a6c\u54e5", "age": 8, 'birth': datetime.now()}, {"pk": 4, "name": "qqq", "age": 5, 'birth': datetime.now()}, {"pk": 5, "name": "www", "age": 5, 'birth': datetime.now()} ] # json序列化的时候是调用JSONEncoder这个类的default方法进行序列化的 class JsonCustomEncoder(json.JSONEncoder): # 自定义一个类,重新json.dumps的default方法 def default(self, field): # 循环每个字段的值 if isinstance(field, datetime): # 如果这个值是datetime类型,我们自己把它转成字符串类型的时间 return field.strftime('%Y-%m-%d %H:%M:%S') elif isinstance(field, date): # 如果这个值是date类型,我们自己把它转成字符串类型的时间 return field.strftime('%Y-%m-%d') else: return json.JSONEncoder.default(self, field) # 如果这个值不是时间类型,调用其父类原本的default方法进行序列化 print(json.dumps(data,cls=JsonCustomEncoder)) # cls指定序列化的时候去执行这个类
三、 信号
1、介绍
Django中提供了“信号调度”,用于在框架执行操作时解耦。通俗来讲,就是一些动作发生的时候,信号允许特定的发送者去提醒一些接受者。
2、内置信号
Model signals pre_init # django的model执行其构造方法前,自动触发 post_init # django的model执行其构造方法后,自动触发 pre_save # django的model对象保存前,自动触发 post_save # django的model对象保存后,自动触发 pre_delete # django的model对象删除前,自动触发 post_delete # django的model对象删除后,自动触发 m2m_changed # django的model中使用m2m字段操作第三张表(add,remove,clear)前后,自动触发 class_prepared # 程序启动时,检测已注册的app中modal类,对于每一个类,自动触发 Management signals pre_migrate # 执行migrate命令前,自动触发 post_migrate # 执行migrate命令后,自动触发 Request/response signals request_started # 请求到来前,自动触发 request_finished # 请求结束后,自动触发 got_request_exception # 请求异常后,自动触发 Test signals setting_changed # 使用test测试修改配置文件时,自动触发 template_rendered # 使用test测试渲染模板时,自动触发 Database Wrappers connection_created # 创建数据库连接时,自动触发
3、使用
1. 场景:数据库增加一条数据时,就记录一条日志,若不使用信号,则需要在每个创建语句下面写记录日志的语句。 2. 介绍 对于Django内置的信号,仅需注册指定信号,当程序执行相应操作时,自动触发注册函数 注册信号,写入与project同名的文件夹下的_init_.py文件中,也是换数据库引擎的地方。 3. 注册信号步骤 1. 导入需要的信号模块(这里列出全部模块,实际开发的时候需要哪个就导入哪个) from django.core.signals import request_finished from django.core.signals import request_started from django.core.signals import got_request_exception from django.db.models.signals import class_prepared from django.db.models.signals import pre_init, post_init from django.db.models.signals import pre_save, post_save from django.db.models.signals import pre_delete, post_delete from django.db.models.signals import m2m_changed from django.db.models.signals import pre_migrate, post_migrate from django.test.signals import setting_changed from django.test.signals import template_rendered from django.db.backends.signals import connection_created 2. 定义函数来处理信号 # 方法一 from django.db.models.signals import post_save # 函数名可随意,但是参数(sender, **kwargs)是固定的,就这两个参数 def callback(sender, **kwargs): print("xxoo_callback") print(sender, kwargs) post_save.connect(callback) # 注册post_save信号:django的model对象保存后,自动触发callback函数 # post_save信号中,render就是触发信号的那一个ORM类(表) # kwargs就是这个类的一些参数:instance是这个类的实例,created:是否是创建操作 # 方法二 from django.db.models.signals import post_save from django.dispatch import receiver @receiver(post_save) def my_callback(sender, **kwargs): print("xxoo_callback") print(sender, kwargs) # 方法三:指定触发者 from django.db.models.signals import post_save from django.dispatch import receiver from myapp.models import MyModel # 指定只有MyModel这个类才能触发这个函数 @receiver(post_save, sender=MyModel) def my_callback(sender, **kwargs): print("xxoo_callback") print(sender, kwargs) # 或者 post_save.connect(callback, sender=MyModel)
4、自定义信号
a. 定义信号 在某py文件中定义信号。 import django.dispatch # pizza_done是信号名 # providing_args是传给信号绑定的函数的kwargs pizza_done = django.dispatch.Signal(providing_args=["toppings", "size"]) b. 注册信号 在_init_.py 中注册信号 from 路径 import pizza_done def callback(sender, **kwargs): print("callback") print(sender,kwargs) pizza_done.connect(callback) c. 触发信号 from 路径 import pizza_done pizza_done.send(sender='seven',toppings=123, size=456) 由于内置信号的触发者已经集成到Django中,所以其会自动调用,而对于自定义信号则需要开发者在任意位置触发。
四、 ORM性能相关
在ORM中,Queryset使用的是懒查询,就是当你没有使用这个结果的时候,它是不会去数据库帮你查询的,
只有在访问Queryset的内容的时候,Django才会真正进行数据库的访问,因此如果按照默认的查询方式去遍历取值,
那么会造成多次的数据库查询,效率非常低。
1.普通性能相关
表结构
class Role(models.Model): name = models.CharField(max_length=32) class User(models.Model): name = models.CharField(max_length=32) age = models.IntegerField() role = models.ForeignKey('Role', null=True, blank=True)
示例
1、 直接查询--> [ 对象 ] 用的时候注意,只拿自己表中的字段,别跨表,比如all_users有3条数据,user表通过外键关联role表, 如果要跨表拿到role表的name字段: all_users = models.User.objects.all() for user in all_users: print(user.name, user.age, user.role.name) 其实一个进行了四次查询,第一次查询出all_users,然后每次的user.role.name都去role表查 2、 要用到跨表字段的时候,使用values或values_list查询速度更快,只需一次查询即可--> [{}] all_users = models.User.objects.all().values('name','age','role__name') for user in all_users: print(user['name'], user['age'], user['role__name']) 3、 only:将指定的字段查询加载出来,后续再访问指定的字段就不需要再查询数据库 # 用的时候注意,只拿自己指定的字段 all_users = models.User.objects.all().only('name') for user in all_users: print(user.name) # 访问指定的字段name不需要再去查询数据库 for user in all_users: print(user.age) # 访问不是指定的字段,每一次都去查一次数据库 4、 defer:将除了指定的字段查询加载出来,后续再访问指定的字段就不需要再查询数据库(only的反义词) all_users = models.User.objects.all().defer('name') for user in all_users: print(user.name) # 访问指定的字段name,每一次都需要去查询数据库 for user in all_users: print(user.age) # 访问不是指定的字段,不需要再查询数据库
2.连表性能相关
表结构
from django.db import models CHOICES = ((1, "python"), (2, "linux"), (3, "go")) class Publisher(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=20) def __str__(self): return self.name class Book(models.Model): title = models.CharField(max_length=20) publisher = models.ForeignKey(to='Publisher', on_delete=models.CASCADE, null=True) category = models.IntegerField(choices=CHOICES, default=1) authors = models.ManyToManyField('Author', related_name='books') def __str__(self): return self.title class Author(models.Model): name = models.CharField(max_length=12) # 姓名 gender = models.SmallIntegerField(choices=((1, '男'), (2, '女'), (3, '保密')), default=3) # 性别 info = models.OneToOneField(to='AuthorInfo') # 详细信息 def __str__(self): return self.name # 作者详细信息表 class AuthorInfo(models.Model): city = models.CharField(max_length=12) # 住址
示例
1、select_related 优点:使用连表查询方式(join),从而减少查询次数,最终达到优化和提高性能效果。 缺点:如果关联的表太多,join得到的表太长,会严重影响数据库性能。 应用场景:连表较少的时候使用,如:外键(ForeignKey)、一对一字段(OneToOneField)的正向查询时使用, 反向查询时,如果查询的是多条数据(ForeignKey、ManyToManyField),不能使用select_related, OneToOneField查询的还是单条数据,因此还是可以使用 2、prefetch_related 优点:首先分别查询每个表,获取各个表的数据,存放在内存中,然后通过Python处理他们之间的关联。 应用场景:连表较多的时候使用,如:一对多字段(其实也是ForeignKey),多对多字段(ManyToManyField), 无论是正向查询还是反向查询,都可以使用。 """一对一字段的正向查询""" ret = Author.objects.filter(id=1).select_related('info') for i in ret: print(i.info.city) # select_related:只进行了一次查询 (0.001) SELECT "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id", "myapp_authorinfo"."id", "myapp_authorinfo"."city" FROM "myapp_author" INNER JOIN "myapp_authorinfo" ON ("myapp_author"."info_id" = "myapp_authorinfo"."id") WHERE "myapp_author"."id" >= 1; args=(1,) # prefetch_related:两个表分别查询,进行了两次查询 ret = Author.objects.filter(id=1).prefetch_related('info') for i in ret: print(i.info.city) (0.001) SELECT "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id" FROM "myapp_author" WHERE "myapp_author"."id" >= 1; args=(1,) (0.000) SELECT "myapp_authorinfo"."id", "myapp_authorinfo"."city" FROM "myapp_authorinfo" WHERE "myapp_authorinfo"."id" IN (1, 2); args=(1, 2) """一对一字段的反向查询""" ret = AuthorInfo.objects.filter(id=1).select_related('author') for i in ret: print(i.author.name) (0.000) SELECT "myapp_authorinfo"."id", "myapp_authorinfo"."city", "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id" FROM "myapp_authorinfo" LEFT OUTER JOIN "myapp_author" ON ("myapp_authorinfo"."id" = "myapp_author"."info_id") WHERE "myapp_authorinfo"."id" >= 1; args=(1,) ret = AuthorInfo.objects.filter(id=1).prefetch_related('author') for i in ret: print(i.author.name) (0.000) SELECT "myapp_authorinfo"."id", "myapp_authorinfo"."city" FROM "myapp_authorinfo" WHERE "myapp_authorinfo"."id" >= 1; args=(1,) (0.000) SELECT "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id" FROM "myapp_author" WHERE "myapp_author"."info_id" IN (1, 2); args=(1, 2) """一对多字段的正向查询""" # select_related:只进行了一次查询 ret = Book.objects.filter(id=1).select_related('publisher') for i in ret: print(i.publisher.name) (0.000) SELECT "myapp_book"."id", "myapp_book"."title", "myapp_book"."publisher_id", "myapp_book"."category", "myapp_publisher"."id", "myapp_publisher"."name" FROM "myapp_book" LEFT OUTER JOIN "myapp_publisher" ON ("myapp_book"."publisher_id" = "myapp_publisher"."id") WHERE "myapp_book"."id" >= 1; args=(1,) # prefetch_related:两个表分别查询,进行了两次查询 ret = Book.objects.filter(id=1).prefetch_related('publisher') for i in ret: print(i.publisher.name) (0.001) SELECT "myapp_book"."id", "myapp_book"."title", "myapp_book"."publisher_id", "myapp_book"."category" FROM "myapp_book" WHERE "myapp_book"."id" = 1; args=(1,) (0.000) SELECT "myapp_publisher"."id", "myapp_publisher"."name" FROM "myapp_publisher" WHERE "myapp_publisher"."id" IN (1); args=(1,) """一对多字段的反向查询""" # 查询的是多条数据时,不能使用select_related # prefetch_related:两个表分别查询,进行了两次查询 ret = Publisher.objects.filter(id=1).prefetch_related('book_set') for i in ret: print(i.book_set.all()) (0.000) SELECT "myapp_publisher"."id", "myapp_publisher"."name" FROM "myapp_publisher" WHERE "myapp_publisher"."id" = 1; args=(1,) (0.000) SELECT "myapp_book"."id", "myapp_book"."title", "myapp_book"."publisher_id", "myapp_book"."category" FROM "myapp_book" WHERE "myapp_book"."publisher_id" IN (1); args=(1,) """多对多字段的正向查询""" # 反向查询的是多条数据时,不能使用select_related # prefetch_related:两个表分别查询,进行了两次查询 ret = Book.objects.filter(id=1).prefetch_related('authors') for i in ret: print(i.authors.all()) (0.001) SELECT "myapp_book"."id", "myapp_book"."title", "myapp_book"."publisher_id", "myapp_book"."category" FROM "myapp_book" WHERE "myapp_book"."id" = 1; args=(1,) (0.002) SELECT ("myapp_book_authors"."book_id") AS "_prefetch_related_val_book_id", "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id" FROM "myapp_author" INNER JOIN "myapp_book_authors" ON ("myapp_author"."id" = "myapp_book_authors"."author_id") WHERE "myapp_book_authors"."book_id" IN (1); args=(1,) """多对多字段的反向查询""" ret = Author.objects.filter(id=1).prefetch_related('books') # 设置了related_name for i in ret: print(i.books.all()) (0.000) SELECT "myapp_author"."id", "myapp_author"."name", "myapp_author"."gender", "myapp_author"."info_id" FROM "myapp_author" WHERE "myapp_author"."id" = 1; args=(1,) (0.000) SELECT ("myapp_book_authors"."author_id") AS "_prefetch_related_val_author_id", "myapp_book"."id", "myapp_book"."title", "myapp_book"."publisher_id", "myapp_book"."category" FROM "myapp_book" INNER JOIN "myapp_book_authors" ON ("myapp_book"."id" = "myapp_book_authors"."book_id") WHERE "myapp_book_authors"."author_id" IN (1); args=(1,) 总结: select_related使用的是join查询,但是当连接的表过多时,会导致性能下降, 适用于 "一" 这张表的查询 prefetch_related 是分别对每个表进行查询,然后通过Python处理去处理查询的数据, 无论是 "一" 还是 "多" 这张表,都能使用
五、 验证码
1、随机验证码python代码
import random def get_code(): code = '' for i in range(6): num = str(random.randint(0, 9)) # 数字 lower = chr(random.randint(97, 122)) # 小写字母 upper = chr(random.randint(65, 90)) # 大写字母 c = random.choice([num, lower, upper]) # 随机选取一个 code += str(c) return code
2、如何生成图片
1. 验证码的形式 回想一下,平时我们输入验证码的时候,是不是都是看着一张图片,图片上显示验证码,我们看着图片输入验证码。 当然现在还有滑动的,点击等等,这里我们先学习图片的形式。 2. 实现步骤 1, 准备一张没有任何内容的图片 2, 安装python专门处理图片的第三方包 pip install Pillow 3, 包的导入 from PIL import Image, ImageDraw, ImageFont 4, Image:生成一张图片 ImageDraw:生成一个画笔,用于在图片上画验证码 ImageFont:字体的格式和大小 5,示例 from PIL import Image, ImageDraw, ImageFont # 返回随机的RGB数字 def random_color(): return random.randint(0, 255), random.randint(0, 255), random.randint(0, 255) def get_code(): with open('1.png', 'wb') as f: # 第一步:生成一张图片(画布) # 创建一个随机颜色的图片对象 # 参数:颜色模式,图片大小,图片颜色 img_obj = Image.new('RGB', (250, 35), random_color()) # 第二步:在该图片对象上生成一个画笔对象 draw_obj = ImageDraw.Draw(img_obj) # 使用什么字体,字体大小,kumo.ttf是我本地下载好的字体文件(sc.chinaz.com)可下载 font_obj = ImageFont.truetype('static/font/kumo.ttf', 28) # 生成验证码 code = '' for i in range(6): num = str(random.randint(0, 9)) # 数字 lower = chr(random.randint(97, 122)) # 小写字母 upper = chr(random.randint(65, 90)) # 大写字母 c = random.choice([num, lower, upper]) # 随机选取一个 code += str(c) # 用画笔把验证码画到图片上 # 参数:xy:坐标,画在哪个位置;text:画的内容;fill:画什么颜色;font:字体格式 draw_obj.text((35 + i*30, 0), c, fill=random_color(), font=font_obj) # 保存图片 img_obj.save(f) get_code() 6,缺点 上面的代码是在你的硬盘上存了一张图片,如果要在页面上展示,你还得进行文件的读, 这样的话不仅浪费硬盘空间,效率还不够高,因此我们应该把图片写到内存,从内存中取,效率就快很多了, 然后把图片的验证码数据存到session,这样登录的时候就可以校验了。
3、在视图中使用验证码
1. urls urlpatterns = [ # 获取图片的路由 url(r'^login/', views.login), url(r'^v_code/', views.v_code), ] 2. 在页面中点击验证码图片,刷新验证码 <!DOCTYPE html> <html lang="zh-CN"> <head> <meta http-equiv="content-Type" charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Title</title> </head> <body> <form action='' method='POST'> {% csrf_token %} <input type='text' name='username'>用户名 <input type='password' name='password'>密码 <img src="/v_code/" alt="图片加载失败" id="v_code"> <button type="submit">登录</button> </form> <script> img = document.getElementById('v_code'); img.onclick = function () { img.src += '?' } </script> </body> </html> 3. 验证码视图函数 from PIL import Image, ImageDraw, ImageFont import random def random_color(): return random.randint(0, 255), random.randint(0, 255), random.randint(0, 255) def v_code(request): # 第一步:生成一张图片(画布) # 创建一个随机颜色的图片对象 # 参数:颜色模式,图片大小,图片颜色 img_obj = Image.new('RGB', (250, 35), random_color()) # 第二步:在该图片对象上生成一个画笔对象 draw_obj = ImageDraw.Draw(img_obj) # 使用什么字体,字体大小 font_obj = ImageFont.truetype('static/font/kumo.ttf', 28) # 生成验证码 code = '' for i in range(6): num = str(random.randint(0, 9)) # 数字 lower = chr(random.randint(97, 122)) # 小写字母 upper = chr(random.randint(65, 90)) # 大写字母 c = random.choice([num, lower, upper]) # 随机选取一个 code += str(c) # 用画笔把验证码画到图片上 # 参数:xy:坐标,画在哪个位置;text:画的内容;fill:画什么颜色;font:字体格式 draw_obj.text((35 + i*30, 0), c, fill=random_color(), font=font_obj) # 把图片里面的验证码的内容写到session,且忽略大小写 request.session['v_code'] = code.upper() # 把图片写到内存 from io import BytesIO f1 = BytesIO() # 类似于文件的文件句柄:f1 = open() # 把图片保存到内存 img_obj.save(f1, format="PNG") # 从内存中取数据 img_data = f1.getvalue() return HttpResponse(img_data, content_type='image/png') 4. 登录视图函数 def login(request): err_msg = '' if request.method == 'POST': username = request.POST.get('username') password = request.POST.get('password') v_code = request.POST.get('v_code', '').upper() if v_code == request.session.get('v_code'): obj = auth.authenticate(request, username=username, password=password) if obj: auth.login(request, obj) # 认证成功 初始化权限信息 ret = init_permission(request, obj) if ret: return ret return redirect(reverse('my_customer')) err_msg = '用户名或密码错误' else: err_msg = '验证码错误' return render(request, 'login.html', {'err_msg': err_msg})
4、验证码的额外小知识
画完验证码后,可以添加一些干扰 就是在 draw_obj.text((35 + i*30, 0), c, fill=random_color(), font=font_obj)之后加 1. 加干扰线 width = 250 # 图片宽度(防止越界) height = 35 for i in range(5): x1 = random.randint(0, width) x2 = random.randint(0, width) y1 = random.randint(0, height) y2 = random.randint(0, height) draw_obj.line((x1, y1, x2, y2), fill=random_color()) 2. 加干扰点 for i in range(40): draw_obj.point([random.randint(0, width), random.randint(0, height)], fill=random_color()) x = random.randint(0, width) y = random.randint(0, height) draw_obj.arc((x, y, x+4, y+4), 0, 90, fill=random_color())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号